Keep your eyes on the stars and your feet on the ground!!!
1.1 YGC日志分析
包括内存担保机制 和 对象晋升到老年代的条件.
1.2 FULLGC日志分析
1.5.2 内存泄漏原因及解决办法
1.6.1 类的初始化时机及顺序
其余(双亲委派等)见有道云笔记.
详细流程及调优见有道云笔记。
总结:
1. 对象晋升到老年代的原因[3个]
# YGCLogAnalyze.java有答案.
2. JVM调优实际经验
2.1 MinorGC和FullGC都比较频繁
# 首先表明出于什么原因用的什么垃圾收集器, [处于低延迟选择了CMS]
# 然后表明现象, [Minor GC 100/4mins, Major GC 1/4mins]
# 然后分析可能出现的原因[2个], [1. 内存担保机制, Survivor区太小, 导致放不下, 对象直接晋升到OldGen. 2. 动态年龄计算]
# 然后通过GC日志查看对象在堆中分布, 查看原因, [1. 动态年龄计算后, 年龄仅为2, 导致分代模型失去意义. 2. 一次MajorGC后, 老年代的对象释放了接近90%]
# 最后给出解决方案, 在测试环境模拟线上环境进行测试. [解决方案: 扩大年轻代, -Xmn -XNewRation; 让对内存翻倍.]
# 达到效果: YGC降到每分钟40次, FullGC降到每小时6次. 优化结束.
2.2 FULL GC比较频繁导致CPU飙升: a. CMS的有效空间设置的太小(CMSInitiatingOcupancyFraction这是成了60, 默认为92) b. 内存泄漏导致FULL GC频繁, 最终OOM
2.3 CMS的final remark阶段时间过长[本身它也是4个阶段中最耗时的阶段]: a.在并发标记的过程中, 应用程序的老年代对象修改过快.
b. 由于final remark要扫描年轻代, 所以年轻代过大也会导致这个理由, 这个原因可以由GC日志看出来, 当final remark的时候, Young Gen占比比较大.
# 通过日志分析发现Remark耗时大于500ms的时候, 新生代使用率都在75%以上, 通过参数CMSScavengeBeforeRemark来解决, 在remark阶段进行一次Minor GC.
# 比如: 开启之前 Remark 0.7s; 开启之后 YGC 0.05s + Remark 0.4s
3. CardTable的作用? 采用位图实现, 是一个point-out的结构, 作用是为了:
a. 在MinorGC的时候扫描整个老年代.
b. 在并发标记过程中发生引用的table标记为Dirty, 这样final remark就可以以这些Dirty table做起点了.
3.1 三色标记算法:
4. 各个垃圾收集器的场景:
场景:
a. Serial 单线程+几十兆内存; -XX:+UseSerialGC = Serial New (DefNew) + Serial Old
b. ParallelNew/ParallelScanvage 多线程+几个G; -XX:+UseParallelGC, ParallScanvage + ParallelOld/标记-整理算法 (JDK1.8默认)
c. CMS 20G + 多线程(CMS对CPU比较敏感); -XX:+UseConcMarkSweepGC = ParNew + CMS + Serial Old(碎片太多的时候开启)
d. G1 上百G; -XX:+UseG1GC = G1 -XX:MaxGCPauseMillis=200
e. ZGC 4T-16T (JDK13)
5. CMS为什么低停顿[3个原因]及问题[2个问题]
# 问题: 1. 内存碎片, 因采用的标记清楚算法, 当内存碎片过多导致不能再分配对象时, Serial Old登场.
# 2. 容易产生浮动垃圾(Floating garbage),因为并发清除阶段和用户线程是同步进行的,所以CMS会预留一部分空间供YoungGen晋升上的对象使用【内存担保机制或大对象】,
# 当预留空间不足以容纳晋升对象时,就会触发一次Full GC, 使用Serial Old收集器候补。 预留空间可由-XX:CMSInitiatingOccupancyFraction=80来配置,
# 配置过小导致频繁的MajorGC, 过大导致很容易导致大量的Concurrent mode failure失败,产生STW停顿。
6. 如何排查内存泄漏的问题及注意事项?
注意事项: 当堆内存比较大的时候, jmap会导致整个JVM 不对外提供服务, 此时对于集群环境, 应该先让服务下线, 然后在下线的服务器上进行jmap. 完后使用jhat jvisualvm分析.
7. 线上JVM规划
> 1. 按每天1亿点击量算, 按日活用户500万来算, 则每个用户平均点击20 30次, 按付费转化率10%算的话, 将是日均50万单.
> 2.1 按照订单生成的时间来算, 50万订单在3个小时生成, 将是50单.
> 2.2 考虑大促的情况, 抢购会在几分钟产生, 假设为10分钟, 此时1秒将有将近1000单. [数据库配置8核16G, 可抗住1000-2000写请求, 加读写分离后4000请求.]
> 2.2.1 拆分为3台机器, 每台每秒产生400单, 假设每个订单1KB, 再算上订单查询和其他操作, 扩大200倍, 每秒将产生80MB的垃圾.
> 机器采取4核8G, 堆内存分配6个G内存. 其中老年代分2个G, 年轻代分4个G[Eden分配 3.2个G, 两个S区各0.4G]
> 这个配置也不会引起动态年龄判断, 导致年龄太小, 比如在依次Young GC之后, 95%的对象都被回收, 将留下160MB的对象, 此时小于Survivor区的一半[TargetSurvivorRatio, 默认为50%]
> 动态年龄计算机制见TenuringThreshold.java.
8. GC的暂停时间为什么可预测?
a. 将对内存分成了大小相同的n个片区, 年轻代和老年代分区逻辑上是连续的, 物理上是不连续的, 且每个片区的角色会在运行的时候发生变化.
b. 采取复制算法, 解决了内存碎片的问题.
c. 使用三色标记算法+SATB和Rset, 减少了垃圾回收时, 需要扫描的对象. 因为Rset即是一个point-in的结构, 也是一个point-out的结构, 这个Rset占用了1%的空间.
2.1.1 布隆过滤器, 用来处理海量数据的查重问题
归并排序, 包括Master公式-求递归函数的时间复杂度.
2.3 海量数据相关算法
2.4 Hash算法
2.5.1 搜索矩阵
2.6.1 判断链表是否有环, 且返回环的位置
2.6.2 峰值类相关题目
数组先从小到大, 再从大大小. 求峰值, 或找出目标值的index.

3.1 CAS和Java中的CAS实现
3.1.1 CAS引起的ABA问题
3.1.2 ABA解决方案-by AtomicStampedReference
3.1.3 自旋锁简单实现
总结: CAS是一种无锁并发算法(乐观锁), 在同步代码时间较短的时候(比上下文切换的时间小), 并发量比synchronized高, 因为CAS不会使获取锁失败的线程进入阻塞状态, 避免了上下文切换的开销.
3.2 锁的分类
对应图片: https://awps-assets.meituan.net/mit-x/blog-images-bundle-2018b/7f749fc8.png
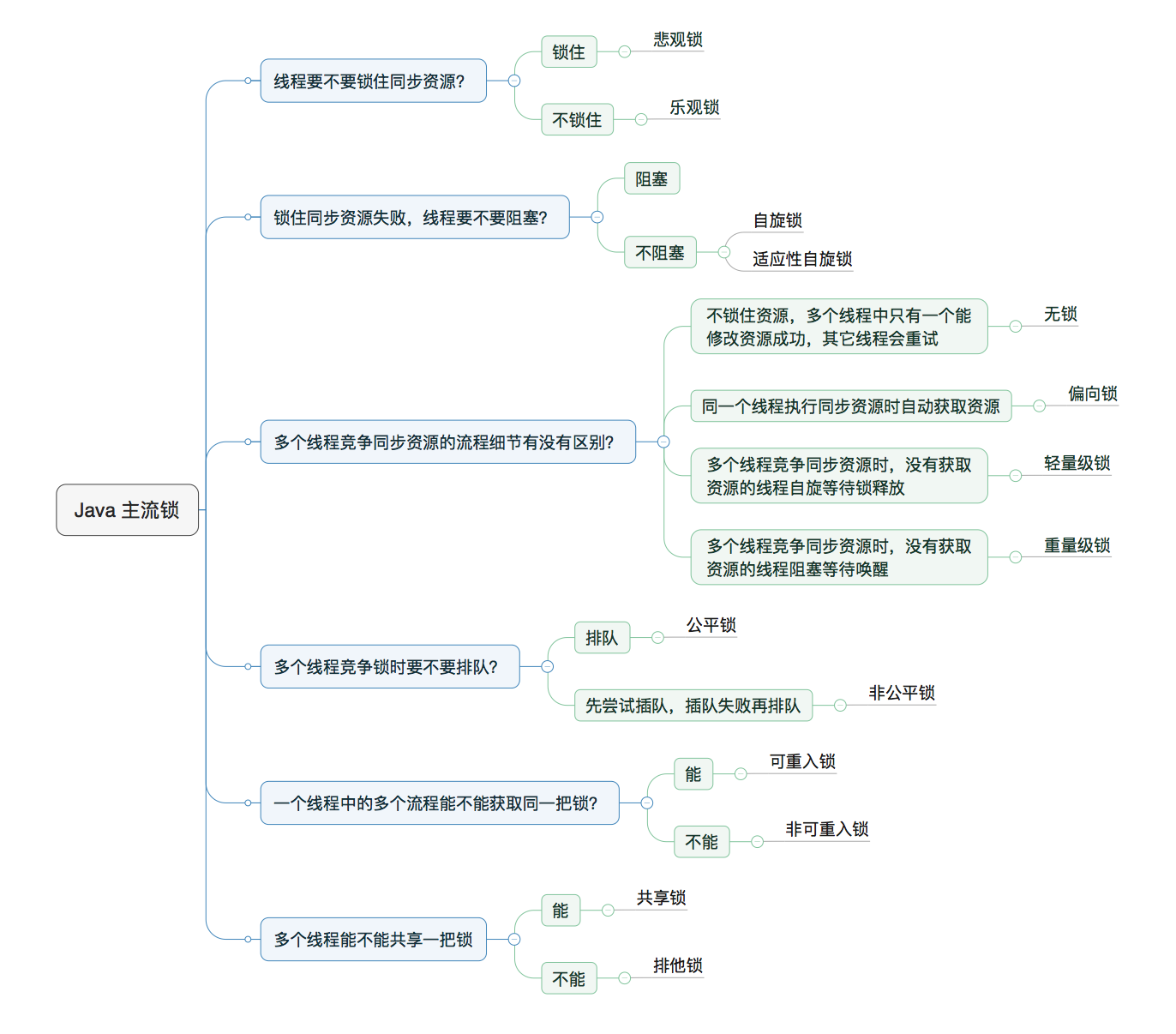{kind=link}
3.2.1 Synchronized和Lock的区别
3.2.2.1 Synchronized的原理及优化
TODO 锁消除 锁粗化
3.2.3.1 自己实现的ReentrantLock(公平+可重入版本锁版本)
3.2.3.2 ReentrantLock的Condition原理实现
3.2.3.3 ReentrantLock的可重入例子
3.2.3.4 NonReentrantLock的死锁例子
- 生产者消费者模式
- 三个线程交替打印字符串, Condition精准控制线程执行顺序。
3.3.2 延时队列的简单使用及原理
3.3.4 延时队列的使用场景
延时队列的其他实现:
- Redis: 使用sortSet实现, score放失效的时间, member放元素, 取元素的时候使用srangebyscore,获取过期时间大于当前时间的即可.
- RabbitMQ的延时队列.
- 时间轮算法, 还不了解.
查看有道云笔记
使用ReentrantLock让写写互斥;通常情况下效率比较低,但是当遍历操作远远大于写操作时,效率较高。
写操作实现:1.将原数组copy一份。 2.创建新数组。 3.将值写入新数组。 4. 将新数组赋给原数组。 这样读的时候也可以写,最大限度减少同步的时间。
体现的思想: 1. 读写分离. 2. 保证最终一致性(当需要实时读的时候, 如果写操作完成, 但是此时引用尚未执行新数组, 这时候读的还是原数组的数据). Collections.synchronizedList, 效率低下。 读读也会互斥。
3.5.1 根据AQS实现CountDownLatch
CountDownLatch, 在所有线程执行完毕后执行某些线程而非一个。 A synchronization aid that allows one or more threads to wait until a set of operations being performed in other threads completes.
士兵案例-CyclicBarrier的复用 CyclicBarrier, 所有线程之间相互等待, 直到到达一个同步点, 才一起继续往下执行. A synchronization aid that allows a set of threads to all wait for each other to reach a common barrier point.
TODO
AQS的核心思想: 如果请求(acquire)的共享资源(volatile state)空闲, 则将当前请求资源的线程设置为有效的工作线程(exclusiveOwnerThread), 并将资源设置为锁定状态. 如果共享资源被锁定(获取锁失败), 则需要一套线程阻塞等待机制及唤醒时锁分配机制, 这个机制通过CLH队列(FIFO)实现, 即将暂时获取不到锁的线程加入到队列中。 请求资源时, 用CAS(compareAndSetState方法)来原子设置state.
AQS定义了两种资源共享模式:
- Exclusive(独占):只有一个线程能运行,入ReentrantLock,又分为公平锁和非公平锁。
- Share(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock。
AQS底层使用模版方法模式:
使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放).
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。 tryAcquire(int)//独占方式。尝试获取资源,成功则返回true,失败则返回false。 tryRelease(int)//独占方式。尝试释放资源,成功则返回true,失败则返回false。 tryAcquireShared(int)//共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。 tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true,失败则返回false。将AQS组合在自定义同步组件的实现中,子类来调用其acquire/release的方法来获取/释放资源,这俩方法会调用使用者重写的方法。 查看案例对AQS的简单实现
3.6 ThreadLocal的原理
使用虚引用目的及使用不当会造成内存泄漏
TODO
3.8 线程间通信
详细查看有道云笔记, 简要: 主要要保存CPU寄存器和程序计数器的状态, 然后将 恢复线程的状态赋给CPU.
3.9.2 死锁代码示例及解决方案
包括JAVA本地线程和操作系统本地线程的对应关系.
3.9.2 Join的实现原理
自己实现的Join
为什么尽量不要用Thread对象的wait/notify来进行线程间通信
Join相关的多线程运行题
涉及快照读, 原理在有道云笔记.
4.3 MySql的锁
7.7 负载均衡算法
从各个角度描述了负载均衡的技术, 并实现了 随机 轮询 加权轮询三个简单的负载均衡算法.
- 包名较混乱。
7.12.1 连接池线上怎么配置, 连接池预热优化
7.12.2 RedisCluster连接方式
7.12.2 Codis连接方式
7.12.3 Sentinel连接方式
Servlet中责任链的实现, 造轮子. FilterChain实现
与AOP中责任链模式的实现大同小异.
- Sentinel的使用场景及解析.
- 限流算法. 理解漏桶算法和滑动时间窗口算法的原理
- 数据库间隙锁, undolog redolog及本地事务怎么实现的
undo记录事务之前的操作, redo记录事务执行之后的操作, log文件大小比数据文件要大.
-
G1垃圾收集器以及线上定位内存泄漏的问题.
-
动态代理的cglib实现及事务的实现原理.
-
设计模式-消息订阅模式的应用.
-
completableFuture的使用场景.
我们将商品模块作为开发的第一步,然后支付模块由于要对接第三方的接口,有人专门去负责处理,其他模块并行处理。