Migration Guide: Simon Fraser University Library Editorial Cartoons Collection
This guide describes using MIK to migrate content from a legacy database application to Islandora. At the time of migration, the database contained 11, 600 editorial cartoons collected and digitized by the Simon Fraser University Library since 2000. This is a sample entry in the public interface of the legacy database:
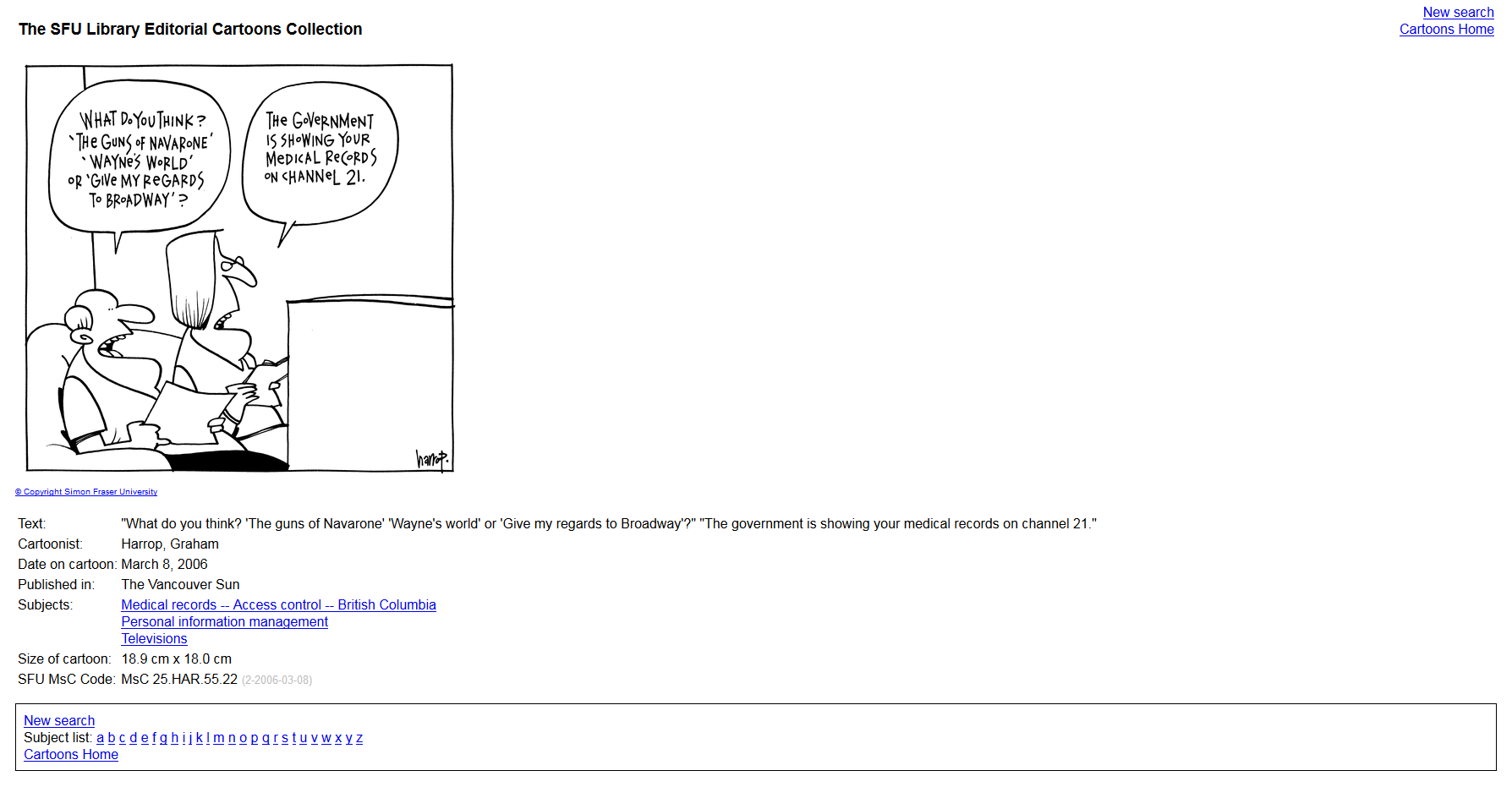
The migration involved:
- extracting data from the source database
- ensuring that the master TIFFs for the cartoons were organized such that MIK could access them
- using MIK's CSV Single File toolchain to generate Islandora ingest packages.
The goal of this migration guide is to document how we transformed the source data into CSV suitable for using as input for MIK, and also to document our workflow during the migration. Since the source platform was a one-off, some of the specific details described in this guide will not apply to other platforms. However, the tasks outlined in the previous paragraph can be generalized to any migration.
The source database was a fairly simple, mutlitable MySQL database. Below is an SQL file showing the structure of the tables from which we extracted data for the migration:
--
-- Table structure for table `Cartoonists`
--
CREATE TABLE `Cartoonists` (
`CartoonistID` int(5) unsigned NOT NULL AUTO_INCREMENT,
`Name` varchar(100) DEFAULT NULL,
`LastUpdatedBy` varchar(10) DEFAULT NULL,
`ModifiedOn` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
PRIMARY KEY (`CartoonistID`)
)
--
-- Table structure for table `Cartoons`
--
CREATE TABLE `Cartoons` (
`CartoonID` int(5) unsigned NOT NULL AUTO_INCREMENT,
`CartoonKey` varchar(20) NOT NULL DEFAULT '',
`CartoonistID` int(5) unsigned NOT NULL DEFAULT '0',
`DateOnCartoon` date NOT NULL DEFAULT '0000-00-00',
`CartoonText` text,
`PhysicalDescription` text,
`CitedIn` text,
`ProcessingNotes` text,
`ShowOnPublicPage` enum('Y','N') DEFAULT NULL,
`LastUpdatedBy` varchar(10) DEFAULT NULL,
`ModifiedOn` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
`DisplayNotes` text,
`PublicationInfo` text,
`MsCCode` text,
`ImageType` text,
`ImageResolution` text,
`Checksum` text,
PRIMARY KEY (`CartoonID`)
);
--
-- Table structure for table `CartoonsPlusSubjects`
--
CREATE TABLE `CartoonsPlusSubjects` (
`CartoonID` int(5) unsigned NOT NULL DEFAULT '0',
`SubjectID` int(5) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`CartoonID`,`SubjectID`)
);
--
-- Table structure for table `Subjects`
--
CREATE TABLE `Subjects` (
`SubjectID` int(5) unsigned NOT NULL AUTO_INCREMENT,
`Subject` varchar(255) NOT NULL DEFAULT '',
`Source` varchar(30) DEFAULT NULL,
`Notes` text,
`LastUpdatedBy` varchar(10) DEFAULT NULL,
`ModifiedOn` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
`UseSubjectID` int(5) unsigned NOT NULL DEFAULT '0',
PRIMARY KEY (`SubjectID`)
);The Cartoons table describes the principle entity in this database, and the Cartoonists and Subjects tables are linked to the Cartoons table using basic relational database one-to-many and many-to-many techniques. In order to flatten the relational structure of our source data into CSV records, we wrote a custom script to export one normalized row per cartoon, with columns containing the linked subjects and cartoonist names. Our script also performed some cleanup of the original data on the way out. For example, it replaced "smart quotes" with non-evil quotation marks, removed hard line breaks from field values, and removed some HTML markup (e.g., <br/>) that had been introduced into the source data.
The output of the script was CSV records like these:
CartoonID,CartoonKey,Cartoonist,Date,CartoonText,PhysicalDescription,PublicationInfo,DisplayNotes,MsCCode,MD5Checksum,Subjects,Subjects_TGM1,Subjects_LCSH,File
15,1-1983-04-09,"Norris, Len",1983-04-09,"""Show me humble citizens with democratic rights to freely elect their leaders and I'll show you a land without potholes.""","30.1 x 21.3 cm","Vancouver Sun",,,59958a3de2780deda8db69c105f52281,"Bennett, W. R. (William Richards), 1932-;Social Credit Party -- British Columbia;Fraser, Alex","Road construction;Democracy",,1-1983-04-09.tif
8925,6-2002-09-02,"Rice, Ingrid",2002-09-02,"""The Clark trial is over and the verdict is in: Guilty of stupidity, He's complaining the $5 to $6 mil spent on the police investigation could have gone to finding missing east-side women"" ""After wasting $460 mil on 3 fast ferries no one wants? Good verdict.""","26.2 cm x 18.2 cm",,,"MsC 25.RIC.8.90",11a29d23748b964f9f013d4b048b7d75,"Clark, Glen David, 1957-;Pacificat (Ferry);Finance, Public -- British Columbia","Newspaper headlines;Trials, litigation, etc.",,6-2002-09-02.tif
5040,4-2005-03-08,"Peterson, Roy",2005-03-08,"In preparation for his visit to President Bush's Crawford, Texas ranch, Prime Minister Martin takes a crash course in executive decision making, in an attempt to cure his post-traumatic dithering disorder. ""What'll it be, dude? Soup or salad? ""…oh.. er.. um… soup! No… salad! No… uh… is there any… sovereignty involved in this… uh… decision?""","26.9 cm x 26.0 cm","Vancouver Sun",,"MsC 25.PET.17.37",32b6645b3d5cc689b0b802ff723114d0,"Martin, Paul, 1938-;Bush, George W. (George Walker), 1946-;Decision making","Prime ministers -- Canada;Restaurants;Presidents -- United States",,4-2005-03-08.tif
Our source platform supported repeated subjects headings, which were in a many-to-many relationship with cartoons. To represent these repeated subjects headings in the CSV file, our export script delimited multiple subjects within each column with semicolons. Here is a 2-column excerpt from a record in the CSV file that illustrates this:
Subjects,Subjects_TGM1
Bowlers,"Bowling;Bowling balls"
To generate MODS that separated each subject heading into its own element, we applied MIK's SplitRepeatedValues metadata manipulator. In fact, our export script separated out uncontrolled subjects, LCSH subject headings, and TGM terms into their own CSV columns so we could create MODS markup for each type of subject heading in the MIK mappings file, each with a specific authority attribute value, resulting in MODS that contained subject elements like this:
<subject>
<topic>Bowlers</topic>
</subject>
<subject authority="lctgm">
<topic>Bowling</topic>
<topic>Bowling balls</topic>
</subject>Getting data out of our legacy database and into a CSV file was the most important task in this migration. The script used to extract our data will not work for migrations from other back ends, but this transformation task is necessary for all similar migrations, regardless of whether the data is stored in a relational database, XML files, or even another CSV file. In other words, the source of the data being migrated may differ, but the required output, a CSV file that contains one record per object and that adheres to MIK's requirements, will not.
For objects like our cartoons, which have one master TIFF per cartoon, those requirements are documented in the wiki entry for the MIK CSV Single File toolchain. Speficically, each CSV record must contain:
- a unique identifier for each record/object, which corresponds to the MIK
[FETCHER] record_keyfield - the name of the file to add to the Islandora ingest package (which corresponds to the MIK
[FILE_GETTER] file_name_fieldfield).
The other columns in the CSV file contain descriptive metadata such title, description, and publication date, which are mapped to MODS elements as illustrated in Step 3 below.
Turns out that Fedora enforces a maximum length of 255 characters on its object labels. In Islandora, the label comes from the MODS <title> element. This posed a problem for us because we consider the cartoon's transcribed text to be its "title" for display purposes, and of the 11,600 or so cartoons in our collection, about 450 had titles that exceeded 255 characters.
To work around this, we decided to truncate the length of the value that we used in the MODS <title> element using the MIK InsertXmlFromTemplate metadata manipulator and to add a MODS note field that contained the entire transcribed text (<note type="text">). The Twig template that we used to populate the truncated <title> element was:
{% if CartoonText|length < 256 %}
<titleInfo>
<title>{{ CartoonText|trim }}</title>
</titleInfo>
{% elseif not CartoonText|length %}
<titleInfo>
<title>[no text]</title>
</titleInfo>
{% else %}
<titleInfo>
<title>{{ CartoonText|TwigTruncate(200) | trim }} [...]</title>
</titleInfo>
{% endif %}We registered this metadata manipulator in our .ini file like this:
[MANIPULATORS]
metadatamanipulators[] = "InsertXmlFromTemplate|null7|twigtemplates/longtitles.xml"
As is required by the InsertXmlFromTemplate, we also had to add a null mapping (in this case, null7) to our mappings file.
The public interface to the Cartoons Collection linked to GIF versions of master TIFF files, one per cartoon. During this migration, we wanted to have Islandora create all the standard derivatives defined by the Large Image content model. Therefore, we were only concerned with migrating the master TIFFs.
In our case, the TIFF files had names corresponding to values from a field in the database, CartoonKey. We populated the field in the CSV file that named each TIFF file (i.e., the field that was identified in the [FILE_GETTER] file_name_field setting in MIK's .ini file) by concatenating the cartoon key and the file extension .tif. If the full name of the file had been stored in the source database, exporting the filename verbatim into the CSV column identified in MIK's file_name_field would be sufficient.
We assembled all of the master TIFFs in a single directory, which we identified in the [FILE_GETTER] input_directory setting in our .ini file. Once we had our CSV dump, and all of the TIFF files arranged in a single directory, we were prepared to start using MIK to generate Islandora ingest packages.
The first step in configuring MIK was to create a mappings file. Our mappings file looked like this:
Cartoonist,<name type='personal'><namePart>%value%</namePart><role><roleTerm type='text' authority='marcrelator'>creator</roleTerm></role><role><roleTerm type='code' authority='marcrelator'>cre</roleTerm></role></name>
null3,null3
PublicationInfo,<originInfo><publisher>%value%</publisher></originInfo>
Date,<originInfo><dateIssued encoding='w3cdtf' keyDate='yes'>%value%</dateIssued></originInfo>
Subjects,<subject><topic>%value%</topic></subject>
Subjects_LCSH,<subject authority='lcsh'><topic>%value%</topic></subject>
Subjects_TGM1,<subject authority='lctgm'><topic>%value%</topic></subject>
PhysicalDescription,<physicalDescription><extent>%value%</extent></physicalDescription>
CartoonKey,<identifier type='local' displayLabel='Cartoon key'>%value%</identifier>
MsCCode,<identifier type='local' displayLabel='SFU MsCCode'>%value%</identifier>
CartoonID,<identifier type='uri' displayLabel='Migrated from' invalid='yes'>http://edocs.lib.sfu.ca/cgi-bin/Cartoons?CartoonID=%value%</identifier>
CartoonText,<note type='text'>%value%</note>
DisplayNotes,<note>%value%</note>
null0,<genre authority='gmgpc'>Editorial cartoons</genre>
null2,<typeOfResource>still image</typeOfResource>
null4,<identifier type='uuid'/>
null5,<extension><CSVData></CSVData></extension>
null6,<language><languageTerm type='text'>English</languageTerm><languageTerm type='code' authority='iso639-2b'>eng</languageTerm></language>
Once we had our mappings file, we then created our MIK .ini file, which looked like this:
; MIK configuration file for the SFU Editorial Cartoons Collection.
[CONFIG]
config_id = cartoons
last_updated_on = "2017-03-01"
last_update_by = "mj"
[FETCHER]
class = Csv
input_file = "mikconfigs/cartoons.csv"
temp_directory = "m:\test_loads\cartoons_final\temp"
field_delimiter = ","
record_key = "CartoonID"
[METADATA_PARSER]
class = mods\CsvToMods
mapping_csv_path = "extras/sfu/mappings_files/cartoons_mappings.csv"
[FILE_GETTER]
class = CsvSingleFile
input_directory = "m:\input\cartoons"
temp_directory = "m:\test_loads\cartoons_final\temp"
file_name_field = File
[WRITER]
class = CsvSingleFile
output_directory = "m:\test_loads\cartoons_final"
preserve_content_filenames = true
; During testing, we're just interested in MODS
datastreams[] = "MODS"
[MANIPULATORS]
; fetchermanipulators[] = "RandomSet|50"
; fetchermanipulators[] = "SpecificSet|cartoons_set.txt"
metadatamanipulators[] = "InsertXmlFromTemplate|null3|mikconfigs/cartoons_long_titles_twig_nottitle.xml"
metadatamanipulators[] = "SplitRepeatedValues|Subjects|/subject/topic|;"
metadatamanipulators[] = 'SplitRepeatedValues|Subjects_TGM1|/subject[@authority="lctgm"]/topic|;'
metadatamanipulators[] = 'SplitRepeatedValues|Subjects_LCSH|/subject[@authority="lcsh"]/topic|;'
metadatamanipulators[] = "AddUuidToMods"
metadatamanipulators[] = "AddCsvData"
metadatamanipulators[] = "SimpleReplace|/\x{FFFD}/u|"
[LOGGING]
path_to_log = "m:\test_loads\cartoons_final\mik.log"
path_to_manipulator_log = "m:\test_loads\cartoons_final\manipulator.log"Because we had a relatively large number of input objects, and because we wanted to make sure that our mappings and metadata manipulator configurations resulted in valid MODS XML files, we ran MIK a number of times configured so that it only generated the MODS for each object and did not copy the corresponding TIFF into the output directory. We did this by specifying datastreams[] = "MODS" in the [WRITER] section of the MIK configuration file, as illustrated above. Each time we generated the MODS files, we validated them to make sure that everything was working as expected and also opened a random sample of them in a text editor to do a visual inspection. During some of our test runs, we also generated smaller sets of test MODS XML files by uncommenting the fetchermanipulators[] = "RandomSet|50" option in the [MANIPULATORS] section, before generating all 11,000 files.
Our workflow leading up to generating the final version of our Islandora ingest packages was:
- run MIK to generate MODS only output
- validate the resulting MODS files
- visually inspect a random sample of the files to make sure that our mappings and metadata manipulators were working as intended
- open the MIK log files to see if they contained any warnings or errors
- refine/adjust the mappings and metadata manipulator configurations
- repeat from step 1
- optionally generate only a small random set of output by uncommenting
fetchermanipulators[] = "RandomSet|50"in the configuration file
- repeat steps 1-6 until happy with metadata
- produce complete output (including TIFFs) by uncommenting the
datastreams[] = "MODS"configuration option
We wanted a way to redirect users from the old URLs for the cartoons to the new ones in Islandora. To accomplish this, we included the old URL of each cartoon in a MODS <identifier> element as illustrated in the mapping for CartoonID (see the mapping file, above). A sample of the output from this mapping is:
<identifier type="uri" displayLabel="Migrated from" invalid="yes">http://edocs.lib.sfu.ca/cgi-bin/Cartoons?CartoonID=2288</identifier>We wrote a custom redirector script to intercept requests to the old URLs, look up the old URL in Solr, and redirect the user to the new Islandora URL. We wrote our redirector prior to the release of Brandon Weigel's Islandora URL Redirector module, which can handle a few different redirection use cases.
This migration guide documents the process Simon Fraser University Library undertook to migrate a collection of content from a custom legacy platform into Islandora. While some of the specifics our our process won't apply to other migrations, the general tasks will be similar:
- extracting data from the source database
- ensuring that the master TIFFs for the cartoons were organized such that MIK could access them
- using MIK's CSV Single File toolchain to generate Islandora ingest packages.
Migrating complex objects such as books or newspapers instead of single-file objects will still require the same general tasks. In general, once you prepare your data according to the requirements of the applicable MIK toolchains, using MIK to generate Islandora ingest packages is fairly straight forward.
Content on the Move to Islandora Kit wiki is licensed under a Creative Commons Attribution 4.0 International License.
