Project for CS 5412. Social Media for Cornell students.
1 of 32 projects selected to present at BOOM 2023.
https://cornell-meetup.azurewebsites.net/
(Azure credits remove so no longer running)
CS 5412: Course Project Final Report
95/100
"This was a meetup app. It used Azure effectively and was carefully tested, but a bunch of functionality they initially planned was halfway finished -- mostly due to GUI limitations, but you get the sense that deploying quite so much Azure "stuff" was harder than they expected. But they did a highly professional job, what they did build worked and was evaluated carefully, showed a LOT of cloud computing understanding."
-Course Staff
https://docs.google.com/presentation/d/1NvpO7OM1eySlyvmGFYd5nsCzMnCoXvrrvCDMqepIukI/edit?usp=sharing

Our application solves our problem by giving our users a platform for easily meeting up with other users, being able to better plan their days, and easily seeing where events are compared to where they are. This is important to us because people are extremely busy and being able to manage group chats, hangouts, times of events, and locations of friends/events can be very difficult when spare time is very limited. We want to do this because we would like to provide a convenient and useful solution for everyday people to solve this management problem. Somewhat similar products would be YikYak and Life360. Life 360 allows users to track their family members or friends. Premium users can also message other users. YikYak uses location to make a social media platform that allows users to interact with other users that are nearby. Ours is definitely very different and provides a unique experience.
The Project is a socialization app that allows users to create an account only they can log into, join and create groups, see all people in the groups on the map, and be able to talk to all people in their group via chat system. Previously we had a couple goals such as adding events on a per group basis and also being able to access the application from Ios and Android devices. These goals were not met purely because of time constraints, but both can be done with relatively small effort; however, we have finished unanticipated features. Some of these include: Authentication of users using obfuscation, changing profile data, filtering the map based on group, deleting accounts, and making a nicer frontend. Mitchell completed all of the frontend integration, set up the database, wrote template code for microservices, tested microservices, and worked with Azure Maps. Jacob used the template code to create the actual microservices that were more complex, created the Kafka chat system, put the frontend onto the cloud, and worked with the database. Below, we will provide some photos of the application.
First off is the login page where users can log into existing accounts. Failed logins change the page to a different one that displays what went wrong.

Then we have the registration page where users can create their account. Failed registrations change the page to a different one that displays what went wrong.

Next up is the actual application once a user is logged in.
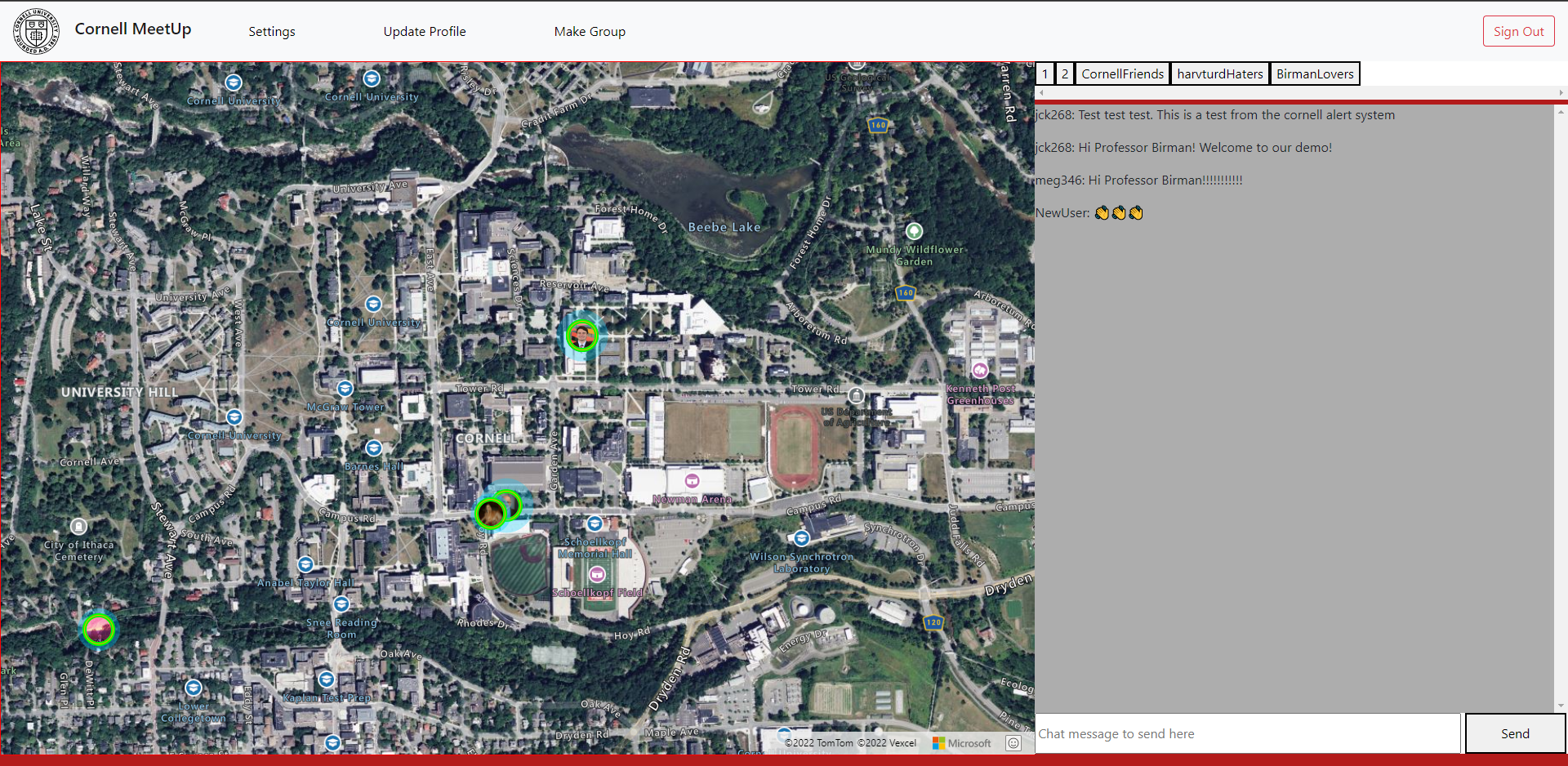
The map and chat change based on the currently selected group. By default, the group is the first group of the user. As you can see in the top right, group “1” is the first group. Below is what happens when group “2” is selected.

The map is bound to the Cornell campus. The following pictures show how far a user can zoom out since users don’t want to be tracked all day.

At the top of the application there are many options. Below are the corresponding pages to those options (zoomed in to save space in the report).

Users currently use the application through their desktop. We plan on using Electron to port our project to ios, or android. This will be relatively easy since the backend runs on Node.JS and already scales to mobile sizes using Bootstrap. Desktop users can access the application through our website running as a first tier microservice on Azure. Data flow goes from the user end to the microservices to the database and then goes back to the user in reverse order whenever users request information. Whenever data is sent to the database, the data goes from the user end to the microservices and then to the database and ends there. Microservices work together in multiple ways. The microservices will access the same database for the backend. Our tier one microservice, the frontend, will interact with the other microservices for getting information to display and allowing users to login. Our user microservice creates user-Obfuscation files for authentication by using the authentication microservice.
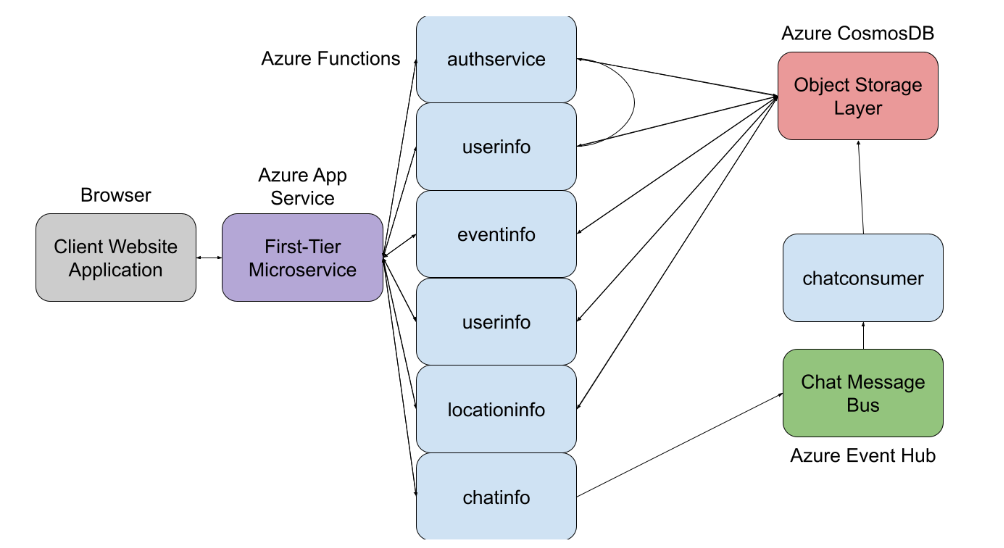
For our microservices, we used Azure Functions built in Python. These utilize the azure.functions library, which allows the Python functions to receive and respond to HTTP requests. To access CosmosDB, our main storage layer, we used the azure.cosmos library to access the CosmosDB REST API. We used our CosmosDB as a file system. To handle real time chat from different users to different group chats, we required a message queue with a producer and consumer model. To accomplish this, we used Azure Event Hub with Apache Kafka integration for an Apache Kafka-like message bus. We set up an Azure Function microservice to take HTTP requests for new chat messages. It connected to the Event Hub via the azure.eventinfo Python API. We then created another Azure Functions microservice that consumes the Kafka messages on the message bus. It runs on a timer every 3 seconds to pull a batch of new messages off of the queue and append them to the log of chat messages in CosmosDB. The previous microservice can then be requested to pull the newest messages for each group from the database. For our frontend, we used HTML, CSS, JavaScript, Bootstrap, Node.js, and Express to create a website application. We then hosted it as a web application on Azure using Azure App Services, which hosts both our front end application and our first tier microservices. We used a number of Azure products to develop and build our project. For storing user data, authentication data, chat data, location data, and group data, we used Azure CosmosDB, which makes it easy to store structured data. Our data for these kinds of profiling data is structured as a JSON document, which is how Azure stores data in CosmosDB. This makes flow of data easier to implement and manage. For our microservices, we use Azure Functions, which allow us to make lightweight microservices that receive and respond to HTTP requests without worrying about container design and load balancing. We used Azure Event Hub for a message bus for real-time processing and displaying sent chat messages to group chats. We used Azure maps to display map data such as user location. We also used Azure App Services to host our first-tier services and front end applications.
The application and microservice architecture making up Meetup is composed of several layers. At the bottom is an Azure CosmosDB storage layer used for all information storage. It contains user, group, and event information, user location information, authentication information, and logs of chats in each group. These are mostly stored as JSON documents and sharded based on their ids, with each id having a prefix that determines its use, such as “users” or “auth”. On top of CosmosDB sits the information layer. These microservices, such as userinfo, locationinfo, and groupinfo, act as a middleman between the first-tier microservices and CosmosDB. Clients can request certain information from the storage layer through this information layer to ensure invariants in the data are being kept. In addition to the information layer of microservices, there is also a computational layer. This layer is made up of services such as the chatinfo and chatconsumer services. chatinfo allows clients to send chats from a specific user to a specific group’s chat by adding the chat object, which includes the message, author, and group name, to a Azure Event Hub message queue responsible for chat messages. The chatconsumer service then runs every three seconds and processes the batch of chat messages by adding them to the end of the list of chats for each group in the storage layer, making them accessible to clients. This allows chat to be processed continuously without having to worry about consistency constraints that can arise due to competing microservices operating on CosmosDB. At the top of the application architecture is the first-tier microservice layer, which runs on Azure App Services. The first-tier microservice layer uses Express for routing and runs on Node.JS. Express stays stateless by sending data userdata only through HTTP requests, similar to how cookies would. The Express server renders HTML files requested by the frontend and communicates with some of the second tier micro services. The client side starts by loading the Azure Maps and adds the user to the map. The client side then grabs information needed such as the user’s groups, chat messages, and the location information of other users in the group. This data is grabbed by making Javascript REST calls. Since the data comes back as promises, they might not be fulfilled immediately which means the client side needs to continuously check for updates to the promises. Running continuous REST calls actually causes errors in browsers so the solution was to randomly check for information in an “eventual consistency” type of strategy. To reduce the slow-down effects of this on initial loading, we originally had a cache layer that would have multiple levels of probabilities that would disable the lower layers when hit. We were able to switch this system to an event listener system that instantly updates the UI as soon as there's a response to our REST calls.
- Azure App Service (First tier microservices) = 15,000 requests per second per instance (Express) * 30 instances = 450,000 requests per second (https://plainenglish.io/blog/how-many-requests-can-handle-a-real-world-nodejs-server-side-application)
- Azure Functions (Mid tier microservices) = ~725 requests per second per instance * 200 instances = 145,000 requests per second (https://codez.deedx.cz/projects/high-throughput-azure-functions-on-http/#results)
- Azure CosmosDB (Storage layer) = 10,000 requests per logical partition (each piece of data) per second (https://learn.microsoft.com/en-us/azure/cosmos-db/set-throughput)
- Azure Maps = No data, assume no bottle neck as it is Azure REST API service
- Azure Event Hub with Apache Kafka (Message queue for chat) = 1,000 requests per second per instance * 1 instance = 1,000 requests per second
- Summary: current bottleneck is the chat message queue (Azure Event Hub) with 1,000 chat messages per second but this can be easily scaled by adding more instances

The deliverable is in the form of a Node.JS application which will soon be platform agnostic. Users are able to access the service on a website in the form of a web application. We will demo the front end application by demonstrating how a user might interact with the service. We will show off creating a new user, joining and creating groups, deleting accounts, displaying all group members’ locations, and sending chat messages to groups. Our implementation can be evaluated by the usefulness of the application to an average end user. Since our current market is towards Cornell students, the product should be evaluated based on the utility it grants students on campus. For example, if the app is able to provide a good enough experience that it helps a certain group of students plan meeting up on campus more easily, the implementation can be considered a success. We will evaluate our project as successful if users on all platforms can have an account, join groups, send messages, see other users in their groups & events.