模拟器在线地址,推荐使用 chrome 浏览器。
- 在游玩「数码宝贝物语-骇客追忆」时,无法了解某数码兽的进化路线,无法了解想进化为特定数码兽时,应该从那个数码兽培养起,试错成本高
- 网络上的进化图鉴,要么只是各数码兽的截屏,要么是单个数码兽的信息,需要逐层级了解数码兽信息,才可以找到进化路线,学习成本大
- 故开发本数码兽进化模拟器,模拟各个数码兽的进化路线

- 数码兽名、编号搜索
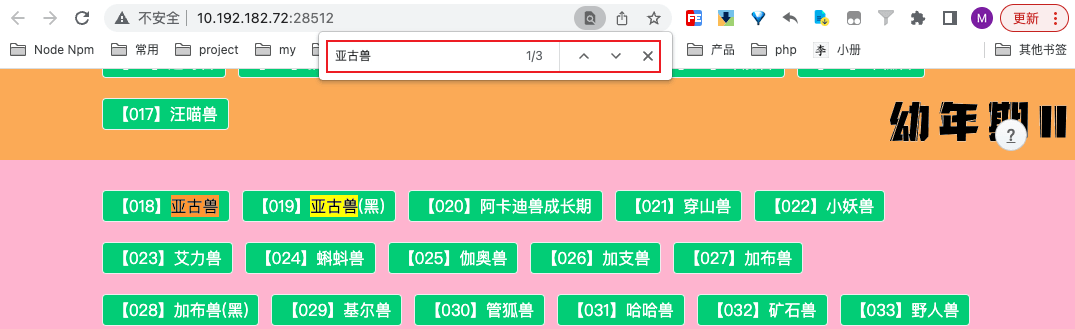
- 使用浏览器的 ctrl + f 搜索功能即可
- 向前推导
- 点击某数码兽的「名字」,即可选中特定数码兽,自动过滤并剩余该数码兽的各层级可进化的对象
- 向后推导
- 点击「名字」选中特定数码兽后,自动过滤并剩余该数码兽各层级的来源
- 任意层级选取并向前向后推导
- 可以在剩余数码兽中,再次选择中间进化态,得到明确的整个进化链
- 各数码兽详情信息展示
- 点击数码兽的 icon,可查看该数码兽的详情信息,包括「基础信息」「数码兽描述」「退化图鉴」 「进化图鉴」



仅下载特定文件夹,可使用GitHub 「特定」文件夹或文件下载工具
- 各数码兽进化视频(素材来源)
- 百度、Google 搜索寻找
- 视频下载(提取视频)
- 这里推荐两种视频提取方法
- m3u8 视频下载工具:针对使用常规 m3u8 视频格式的下载,安装插件一键下载并整合视频,适用于各大盗版视频网站的提取。
- 无差别视频提取工具:针对各大主流网站,使用底层技术绕过视频加密的过程,实现通用提取
- ”数码兽进化视频“进行了定制性视频加密,故这里使用了「无差别视频提取工具」完成了视频下载
- 这里推荐两种视频提取方法
- 自动截屏(从视频中提取图片)
- 需要从视频中截取各数码兽信息截图。两种方式,使用播放其快捷键截屏、使用自动截屏工具完成截屏过程
- 这里使用了ffmpeg工具对视频进行每秒截屏
ffmpeg -ss 00:00 -i 001.mp4 -r 1 -s 7840x4416 %03d.jpg - 再人工从截屏文件中过滤所需的素材截屏
- 图片裁剪(从整体图片中截取特定区域)
- 图片压缩
- 原始图片体积较大,这里使用到图片原地自动压缩工具进行图片压缩(工具方便易用,直接将单个文件放在目录中,即可完成文件夹及其子文件夹的图片压缩),节省近 60% 的图片体积
- OCR 文案识别(从图片中提取文字)
- 这里选中阿里的 OCR 技术,每个月有 200 次的免费提取次数。还有 0.1元/500次 的1分钱试用资源包
- 遇到的问题是,截屏数量超过 1000+,免费额度不足以全部截屏的 OCR 视频
- 再次使用 gm 图片处理库,将若干图片合并成单张图片再进行 OCR,核心命令为
gmInstance.append(imgPath1).append(imgPath2).append(imgPathN).write(outputPath); - 具体脚本
- 文件重命名
- 根据 OCR 的文字获取数码兽编码,重命名各个截屏的命名
- 从 ORC 文本中使用正则提取各个数码兽关键信息
- 错别字纠正
- OCR 并不能百分百正确识别文案,需要人为对文案进行纠正,也是最耗时的地方
- 交互页面开发
- 最花心思的地方,如何表现各个数码兽的进化关系。
- 主流的表现关系是使用树装图
- 优点:直观看到特定数码兽的所有进化可能
- 缺点:只适合单个数码兽的进化分支,多个数码兽的进化树状图合并时,无法识别各个数码兽的进化路线
- 「数码宝贝新世纪」
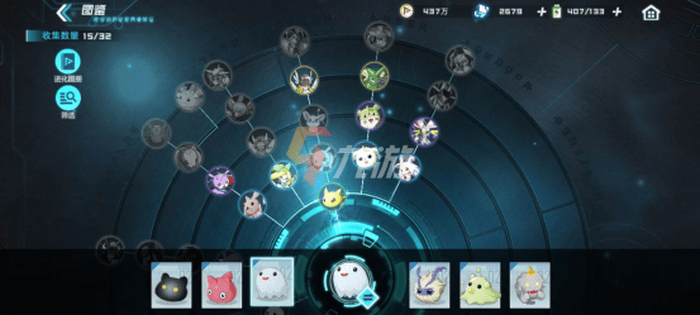
- 优点:使用齿轮进化树,可通过路线和 icon 高亮来区分单个数码兽的进化路线,解决进化路线重叠问题
- 缺点:仅能已幼年期为起点,查看其进化路线,只能看见未来。无法倒推,如无法以「钢铁暴龙兽」为基础点,倒推可进化为「钢铁暴龙兽」的数码兽有哪些。即无法通过「目标」倒推所需资源
- 回想项目的初衷,解决什么问题
- 【推导未来】这个数码兽的未来是什么,能有哪些进化分支
- 【推导过去】要成长为特定数码兽,我可以从哪些资源培养起
- 【选择中间节点】从特定数码兽,进化为特定数码兽的过程中,我希望能进化为某数码兽时,可以怎么选择进化路线
- 最终实现了现在的交互方式
- 可以任意阶段的任意数码兽为出发点,向前推导可进化的数码兽,向后推导可以从那个数码兽进化得来
- 再以推导后的剩余进化图鉴中,选取任意想经历的数码兽,再推导剩余数码兽的向前向后进化路线。
- 最终得到整个进化路线。