A carefully-designed OCR pipeline for universal boarded table recognition and reconstruction.
This pipeline covers image preprocessing, table detection(optional), text OCR, table cell extraction, table reconstruction.
Are you seeking ideas for your own work? Visit my blog post on Hyper-Table-OCR to see more!
Update on 2021-08-20: Happy to see that Baidu has released their PP-Structure, which provides higher robustness due to its DL-driven structure prediction feature, instead of simple matching in our work.
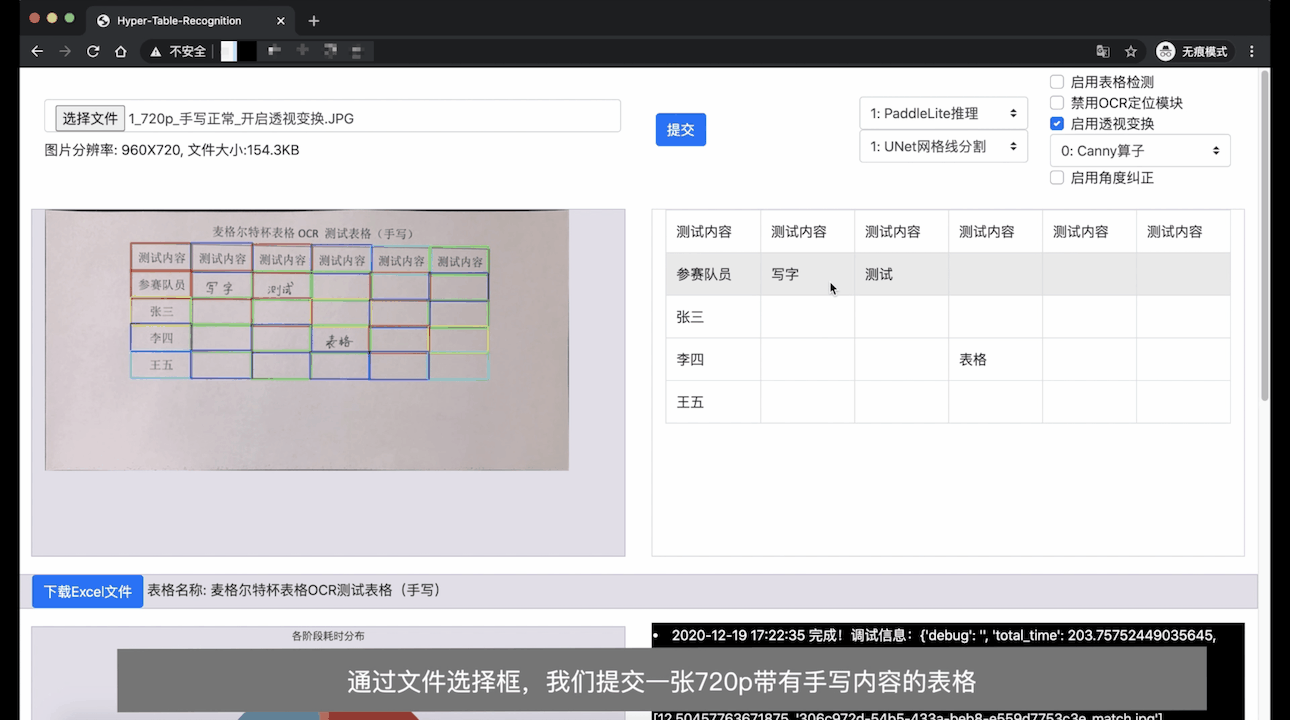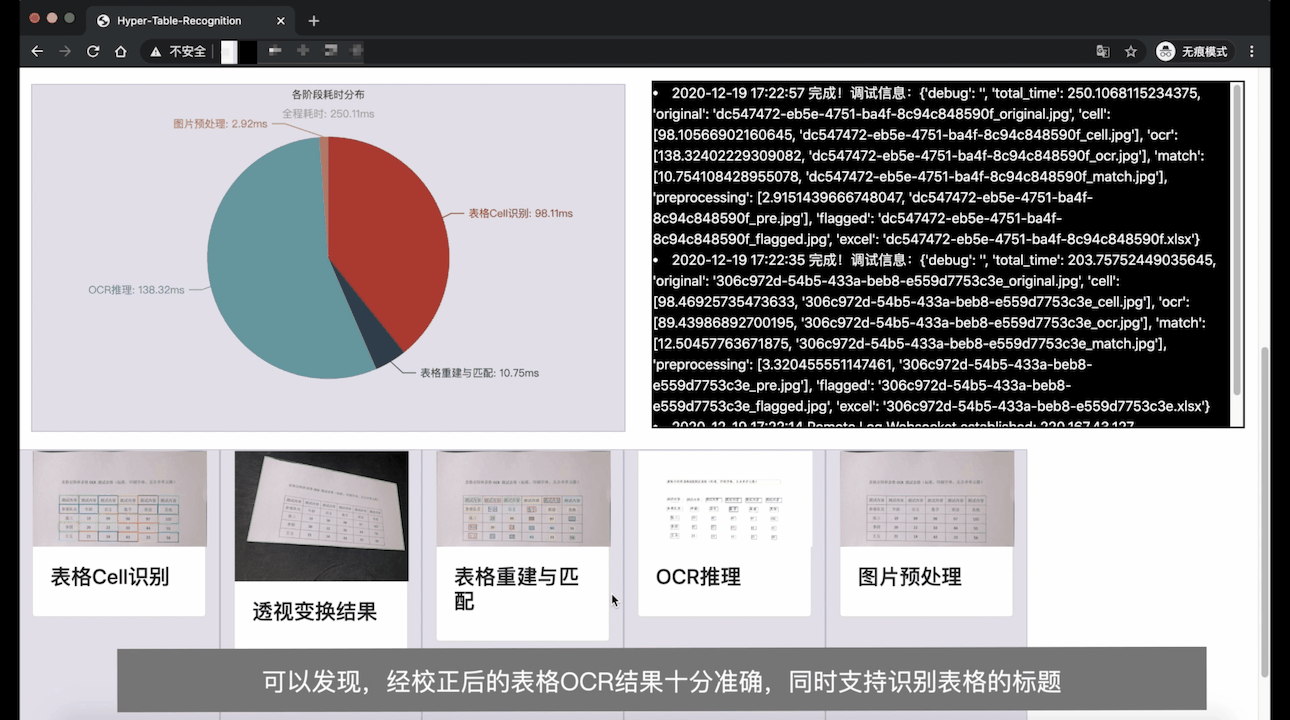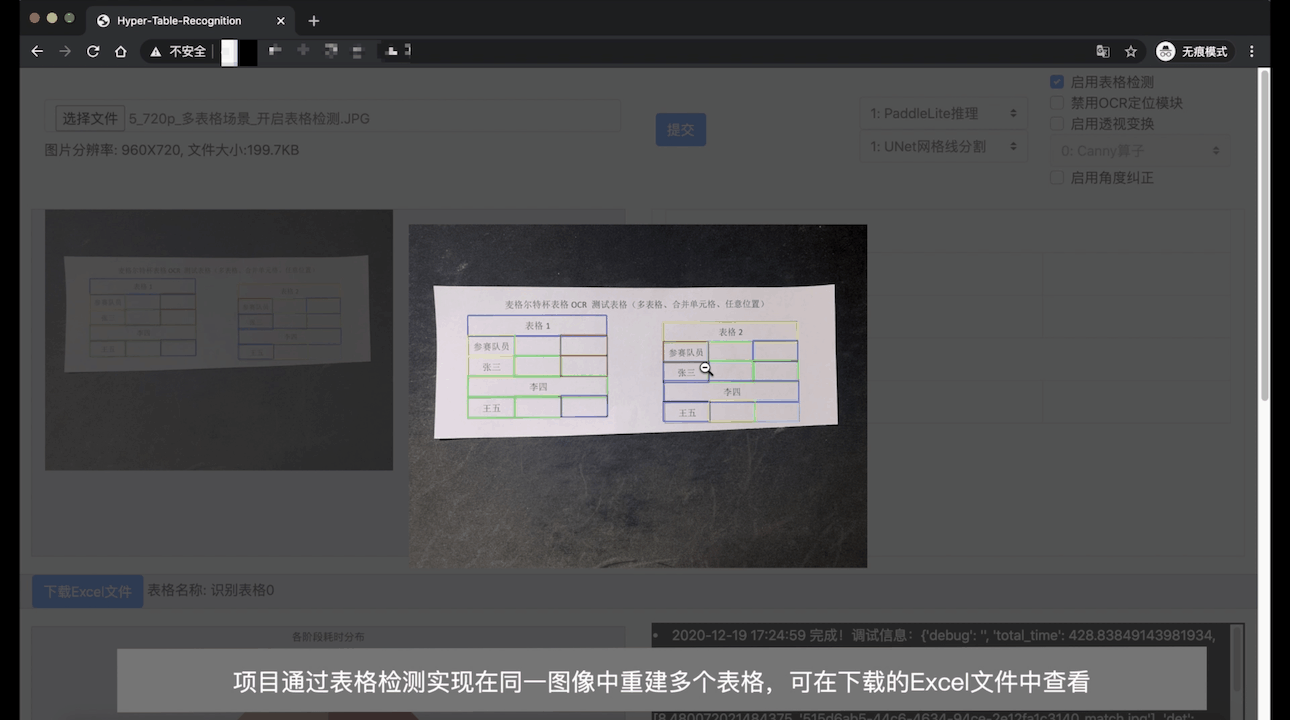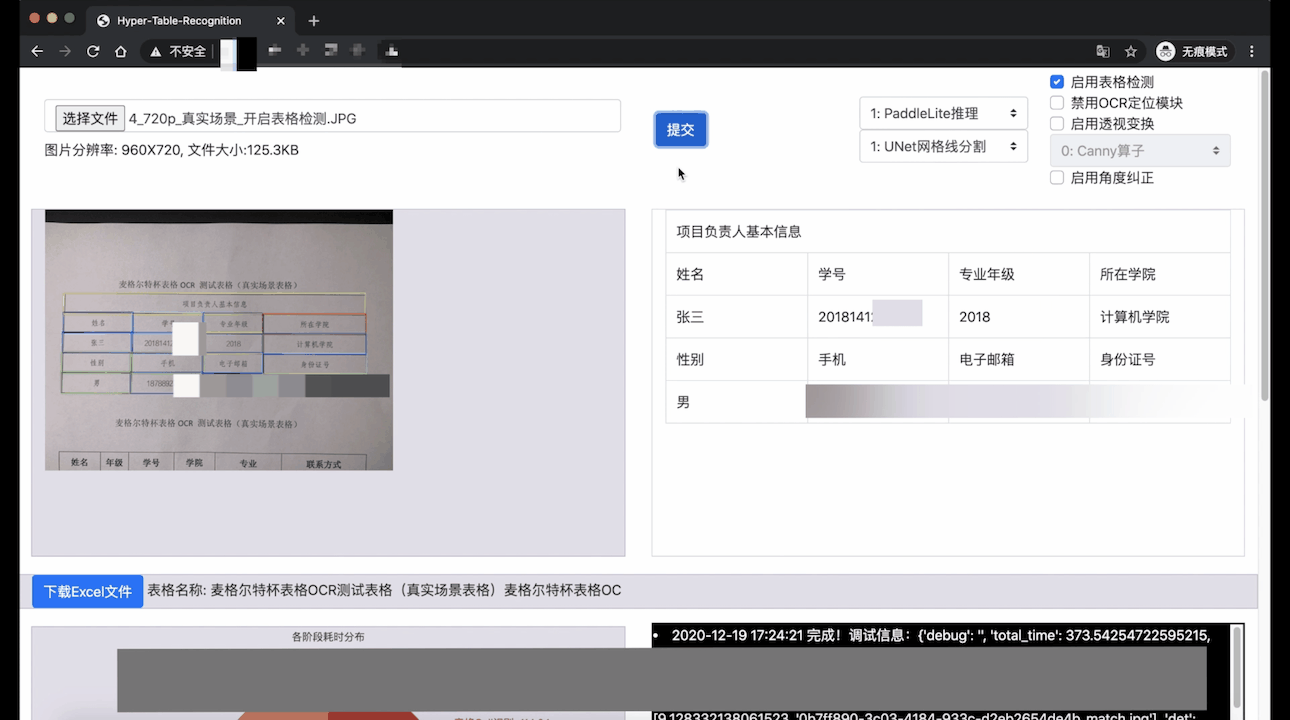
Demo Video (In English): YouTube
Demo Video (In Chinese): Bilibili
- Flexible modular architecture: by deriving from predefined abstract class, any module of this pipeline can be easily swapped to your preferred one. See the following
Want to contribute?part! - A simple yet highly legible web interface.
- A table reconstruction strategy based simply on coordinates of each cell, including identifying merged cell row & building table structure.
- More to explore...
git clone https://github.com/MrZilinXiao/Hyper-Table-Recognition
cd Hyper-Table-RecognitionDownload from here: GoogleDrive
MD5: (004fabb8f6112d6d43457c681b435631 models.zip)
Unzip it and make sure the directory layout matchs:
# ~/Hyper-Table-Recognition$ tree -L 1
.
├── models
├── app.py
├── config.yml
├── ...This project is developed and tested on:
- Ubuntu 18.04
- RTX 3070 with Driver 455.45.01 & CUDA 11.1 & cuDNN 8.0.4
- Python 3.8.3
- PyTorch 1.7.0+cu110
- Tensorflow 2.5.0
- PaddlePaddle 2.0.0-rc1
- mmdetection 2.7.0
- onnxruntime-gpu 1.6.0
An NVIDIA GPU device is compulsory for reasonable inference duration, while GPU with less than 6GB VRAM may experience Out of Memory exception when loading multiple models. You may comment some models in web/__init__.py if experiencing such situation.
No version-specific framework feature is used in this project, so this means you could still enjoy it with lower versions of these frameworks. However, at this time(19th Dec, 2020), users with RTX 3000 Series device may have no access to compiled binary of Tensorflow, onnxruntime-gpu, mmdetection, PaddlePaddle via
piporconda.Some building tutorials for Ubuntu are as follows:
- Tensorflow: https://gist.github.com/kmhofmann/e368a2ebba05f807fa1a90b3bf9a1e03
- PaddlePaddle: https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/2.0-rc1/install/compile/linux-compile.html
- mmdetection: https://mmdetection.readthedocs.io/en/latest/get_started.html#installation
- onnxruntime-gpu: https://github.com/microsoft/onnxruntime/blob/master/BUILD.md
Confirm all deep learning frameworks installation via:
python -c "import tensorflow as tf; print(tf.__version__); import torch; print(torch.__version__); import paddle; print(paddle.__version__); import onnxruntime as rt; print(rt.__version__); import mmdet; print(mmdet.__version__)"Then install other necessary libraries via:
pip install -r requirements.txtpython app.pyVisit http://127.0.0.1:5000 to see the main page!
Inference time consumption is highly related with following factors:
- Complexity of table structure
- Number of OCR blocks
- Resolution of selected image
A typical inference time consumption is shown in Demo Video.
In boardered/extractor.py, we define a TraditionalExtractor based on traditional computer vision techniques and a UNetExtractor based on UNet pixel-level sematic segmentation model. Feel free to derive from the following abstract class:
class CellExtractor(ABC):
"""
A unified interface for boardered extractor.
OpenCV & UNet Extractor can derive from this interface.
"""
def __init__(self):
pass
def get_cells(self, ori_img, table_coords) -> List[np.ndarray]:
"""
:param ori_img: original image
:param table_coords: List[np.ndarray], xyxy coord of each table
:return: List[np.ndarray], [[xyxyxyxy(cell1), xyxyxyxy(cell2)](table1), ...]
"""
passLocated in ocr/__init__.py, you should build a custom OCR handler deriving from OCRHandler.
class OCRHandler(metaclass=abc.ABCMeta):
"""
Handler for OCR Support
An abstract class, any OCR implementations may derive from it
"""
def __init__(self, *kw, **kwargs):
pass
def get_result(self, ori_img):
"""
Interface for OCR inference
:param ori_img: np.ndarray
:return: dict, in following format:
{'sentences': [['麦格尔特杯表格OCR测试表格2', [[85.0, 10.0], [573.0, 30.0], [572.0, 54.0], [84.0, 33.0]], 0.9],...]}
"""
passWebHandler.pipeline() in web/__init__.py
- Speed up inference via async-processing on dual GPUs.
Congratulations! This project earns a GRAND PRIZE(2 out of 72 participators) of the aforementioned competition!
- PaddleOCR: Multilingual, awesome, leading, and practical OCR tools supported by Baidu.
- ChineseOCR_lite: Super light OCR inference tool kit.
- CascadeTabNet: An automatic table recognition method for interpretation of tabular data in document images.
- pytorch-hed: An unofficial implementation of Holistically-Nested Edge Detection using PyTorch.
- table-detect: Excellent work providing us with the U-Net code and pretrained weight.