getting_started
It is best to create your Cassandra Jmeter experiment on a laptop or desktop. As a 100% Java application Jmeter runs on OS X, Windows and Linux. Having created the Cassandra Jmeter jar, copy it to directory lib/ext on your laptop. From the Jmeter home directory run bin/jmeter. This will bring up the initial screen
Once you have created your experiment the jmx file (in XML format) can be copied to another server for load testing if required.
The first step is to add a Thread Group. This will determine how much load is applied to Cassandra. Load is adjusted by increasing or decreasing the number of threads in the thread group.
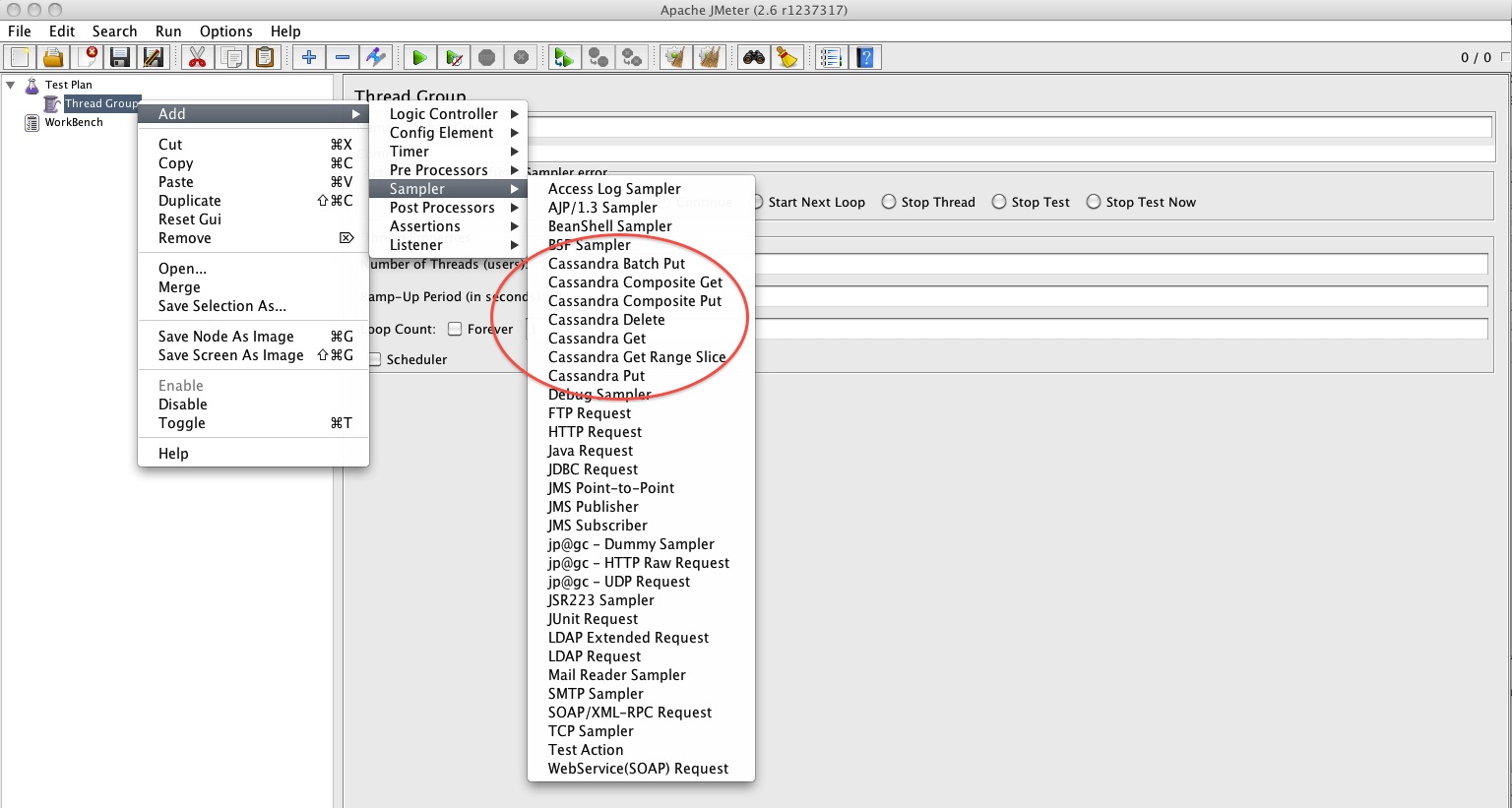
After creating the thread group you can confirm that the Cassandra JMeter plugin has been loaded correctly. Select the Thread Group, right click and a pull down menu will appear. Select Add, then Sampler. The 7 Cassandra Samplers should be included in the list. See the screenshot below.
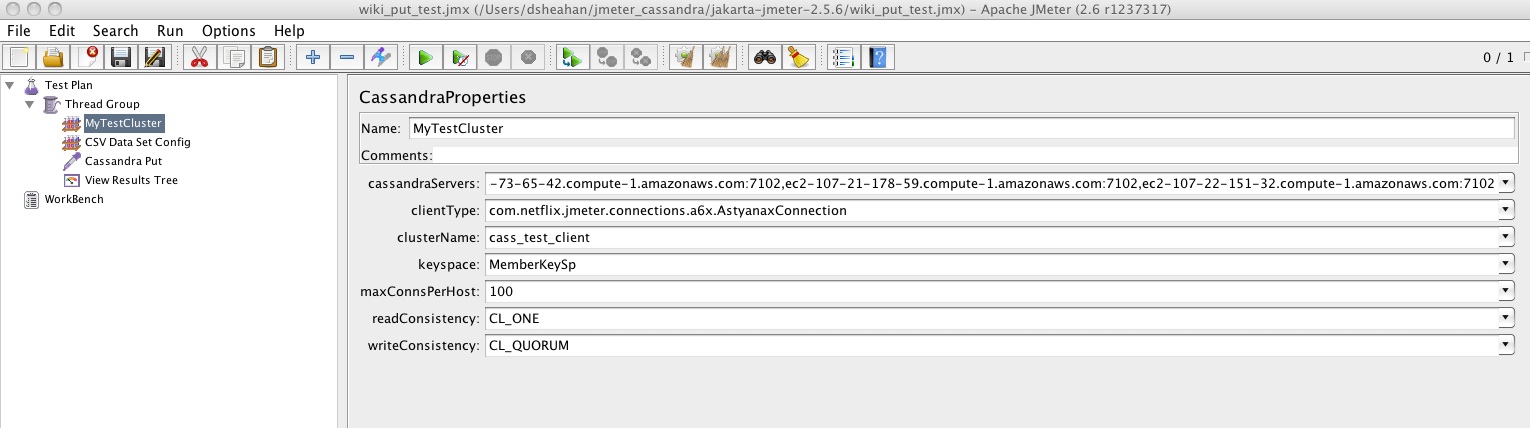
The fist step in a Cassandra JMeter experiment is selecting the CassandraProperties. This defines how Jmeter will communicate with the Cassandra cluster. Again right click the Thread Group -> Add -> Config Element -> CassandraProperties. Lets walk through an example screenshot
Important note - when changing the values in these fields click the downarrow button on the left and select Edit. You can then enter the required value. You cannot enter the value directly.
-
cassandraServers defines the Cassandra server names JMeter will communicate with, these can be IP addresses or fully qualified names. You need to also include the rpc_port (as defined in cassandra.yaml) on which Cassandra is listening for Thrift clients - in this example 7102. Format is server_name:port. You do not have to list all the servers in the cluster, one is the minimum requirement. This list is essentially the Cassandra co-ordinator nodes that will be used.
-
clientType defines the communication protocol, this can be Astyanax or Thrift. For Astyanax as in the example below enter com.netflix.jmeter.connections.a6x.AstyanaxConnection. For Thrift use com.netflix.jmeter.connections.thrift.ThriftConnection.
-
clusterName is the cluster name as defined by field cluster_name in the cassandra.yaml file
-
keyspace is the keyspace in the cluster to send all requests. Note this means that each thread group can only send load to a single keyspace. It can, however, send load to different Column Families within a keyspace.
-
maxConnsPerHost - for each server listed in the cassandraServers field JMeter will establish this number of connections. For example if there are 6 servers in the list and maxConnsPerHost is set to 10 then a maximum of 60 connections will be established. You can test how many have actually been established using netstat -a
-
readConsistency / writeConsistency This determines what consistency level to use for reads abd writes to the cluster.
If Astyanax is selected then Consistencies must be one of
CL_ONE Get confirmation from a single node (fastest)
CL_TWO Get confirmation from 2 nodes
CL_THREE Get confirmation from 3 nodes
CL_QUORUM Get confirmation from the majority of nodes (don't use in multiregion)
CL_EACH_QUORUM In multiregional get confirmation from quarum in each region
CL_LOCAL_QUORUM In multiregional get confirmation from quarum in current region only
CL_ALL Get confirmation from all replicas
If Thrift is selected the equivalent options are ONE, TWO, THREE, QUORUM, EACH_QUORUM, LOCAL_QUORUM, ALL
The Cassandra schema for the Keyspace can be created using the cassandra-cli tool e.g.
create keyspace Membership with placement_strategy = 'NetworkTopologyStrategy' and strategy_options = {us-east : 3} and durable_writes = true;
Alternatively the keyspace can be created as a side effect of a SchemaProperties Config element which creates a Column Family. The plugin will create the keyspace if it doesnt exist or use an already existing one.
Select Thread Group -> Config Element -> Schema Properties. Note SchemaProperties must be after CassandraProperties. The screen shot of SchemaProperties is below:

The following options are available for the schema creation:
-
column_family The name of the column family to create
-
comparator_type Validator to use to validate and compare column names in the column family. Options here are AsciiType,BytesType,CounterColumnType,Int32Type,IntegerType,LexicalUUIDType,LongType,UTF8Type
-
default_validation_class Validator to use for values in columns which are not listed in the column_metadata. Options are the same as comparator_type
-
key_validation_class Validator to use for keys. Options here are AsciiType,BytesType,Int32Type,IntegerType,LexicalUUIDType,LongType,UTF8Type
-
keys_cached Maximum number of keys to cache in memory. Valid values are either a double between 0 and 1 denoting what fraction should be cached. Or an absolute number of rows to cache
-
read_repair_chance Probability (0.0-1.0) with which to perform read repairs for any read operation
-
row_cache_provider Serializer to serialise the contents of the row and store it in native memory, i.e. off the JVM Heap
-
rows_cached Maximum number of rows whose entire contents we cache in memory. Either a double between 0 and 1 denoting what fraction should be cached. Or an absolute number of rows to cache
-
strategy_options Optional additional options for placement_strategy. Options have the form {key:value}
-
validator Validator to use for values for this column. Options are the same as comparator_type
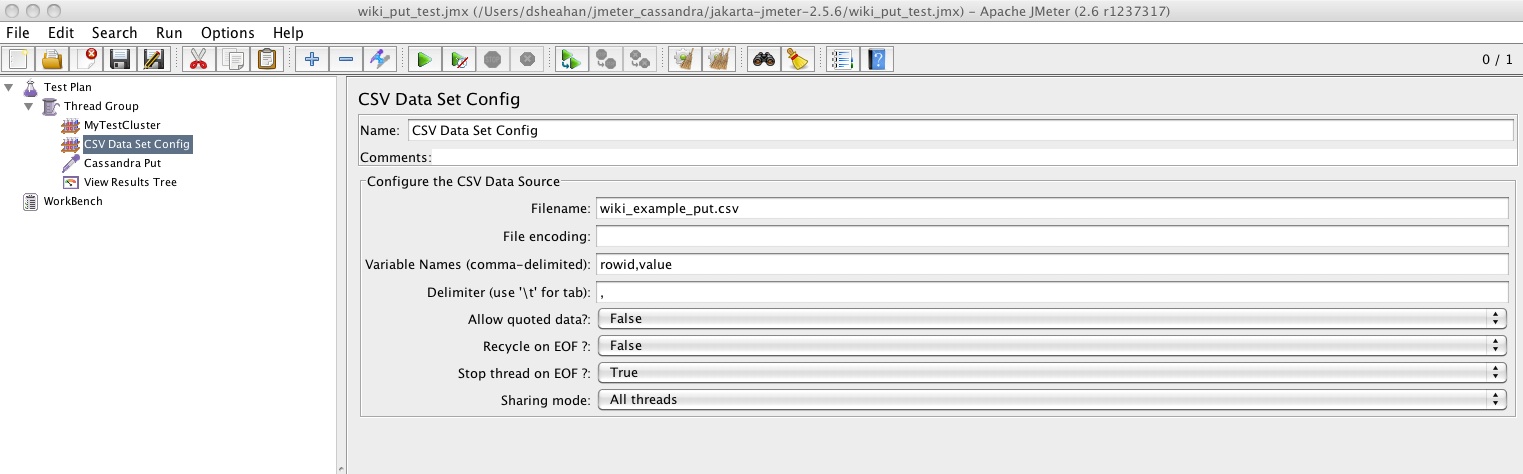
Often we want to load specific data into or get a specific row from cluster. This is achieved using a CSV file. As usual right click on Thread Group -> Add -> Config Element -> CSV Data Set Config.
See the screenshot below for an example. First we specify the filename of the data. Next the layout of this file is specified. By default fields are seperated by a comma but this can be tab, space etc. In the example each line of the file wiki_example.csv contains a rowid and the value to place in this row.
The file wiki_example.csv must exist in the JMeter home directory. Its format would be something like
1,my_data_aaa
2,my_data_bbb
3,my_data_ccc
...
Each time the CSV Data Set is encountered in the experiment by a thread a single line will be read and two variables, ${rowid} and ${value} will be loaded. Each thread gets its own copy of these variables.
The sharing mode determines how the file is shared between threads. Recycle on EOF and Stop thread on EOF determine what to do when the file is exhausted.
Once the CassandraProperties and any potential CSV data have been setup, we are ready to start reading and writing from/to the Cassandra cluster. Let's start with Puts as these are needed to populate the cluster with data.
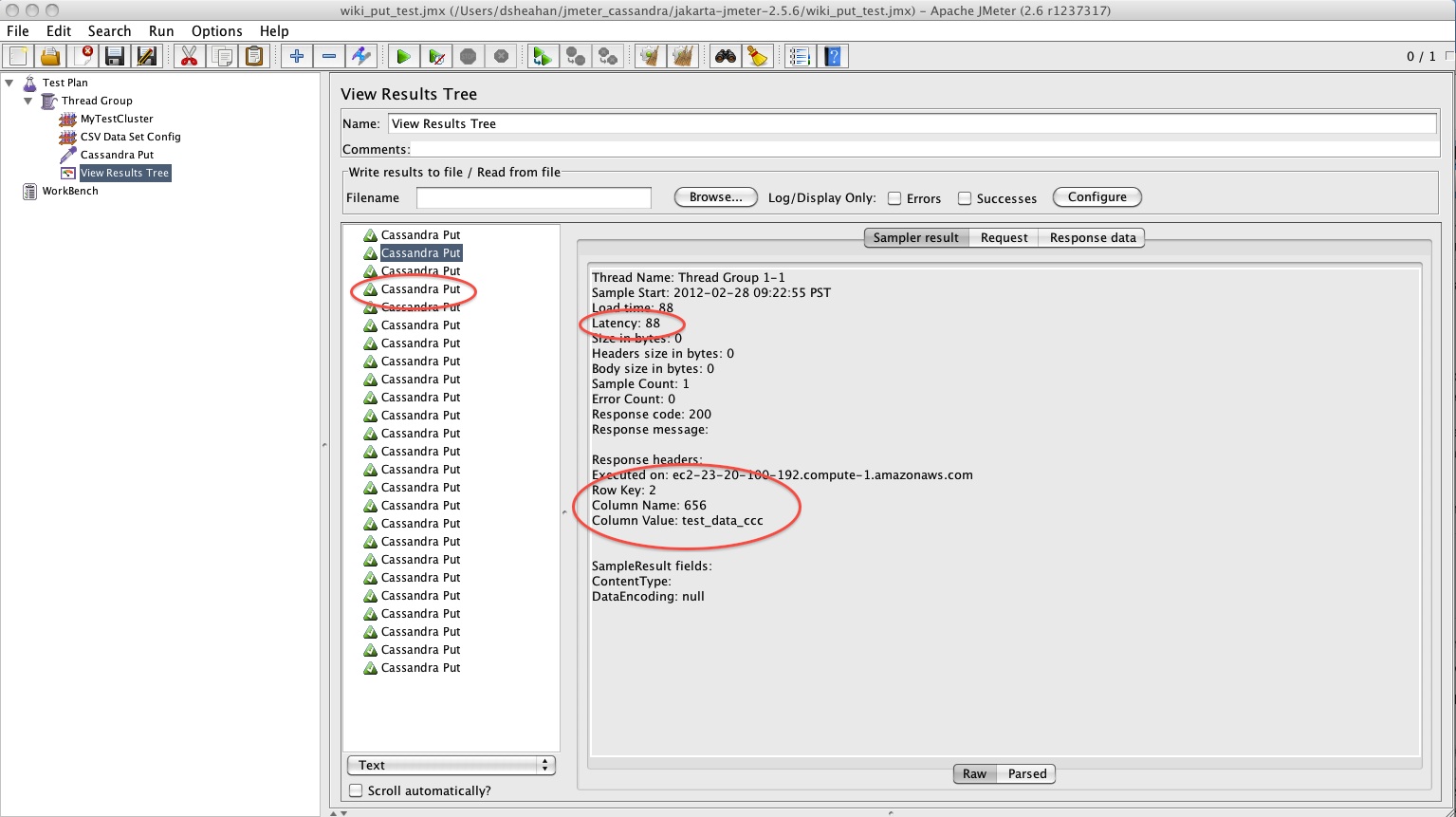
The best way to determine if your Cassandra Put has succeeded is to add a View Results Tree listener. As always right click Thread Group -> Add -> Listener -> View Results Tree
The View Results tree shows if each transaction suceeded, displayed in Green, or had an Error, displayed in Red. The result of running our Cassandra Put for a csv file with 25 entries is shown below. On the left I have highlighted the success and in the sampler result I have highlighted the Row key used for the mutation, its column name and value. Also highlighted is the latency in miliseconds for the transaction.
The results can also be dumped to a file for post processing if necessary