How it Works
 (Click for larger view)
(Click for larger view)
(1) Construct HystrixCommand Command Object
On each dependency invocation its HystrixCommand object will be constructed with the arguments necessary to make the call to the server.
For example:
HystrixCommand command = new HystrixCommand(arg1, arg2)(2) Execution Synchronously or Asynchronously
Execution of the command can then be performed synchronously or asychronously:
K value = command.execute()Future<K> value = command.queue()The synchronous call [execute()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#execute(\)) invokes [queue().get()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#queue(\)) unless the command is specified to not run in a thread.
(3) Is Circuit Open?
Upon execution of the command it first checks with the circuit-breaker to ask, "Is the circuit open?"
If the circuit is open (tripped) then the command will not be executed and flow routed to (8) [HystrixCommand.getFallback()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#getFallback(\)).
If the circuit is closed then the command will proceed to (4) to check if there is capacity available to run the command.
(4) Is Thread Pool/Queue/Semaphore Full?
If the thread-pool and queue (or semaphore if not running in a thread) associated with the command are full then the execution will be rejected and immediately routed through (8) [HystrixCommand.getFallback()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#getFallback(\)).
(5) HystrixCommand.run()
The concrete implementation of the [run()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#run(\)) method is executed.
(5a) Command Timeout
If the command is configured to run within a thread and the [run()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#run(\)) method exceeds the command's timeout value, the thread will throw a TimeoutException. In that case the response is routed through (8) [HystrixCommand.getFallback()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#getFallback(\)) and the return value of the [run()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#run(\)) method is discarded (if it does not cancel/interrupt).
If the command does not run within a thread then this logic will not be applicable.
(6) Is Command Successful?
Application flow is routed based on the response from the _(5) [HystrixCommand.run()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#run(\)) method.
(6a) Successful Response
If no exceptions are thrown and a response is returned then the command returns the response after some logging and metrics reporting.
(6b) Failed Response
When a response throws an exception Hystrix will mark it as "failed" - which will contribute to potentially tripping the circuit - and will route application flow to (8) [HystrixCommand.getFallback()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#getFallback(\)).
(7) Calculate Circuit Health
Successes, failures, rejections and timeouts are all reported to the circuit breaker to maintain a rolling set of counters that calculate statistics.
These stats are used to determine when the circuit should "trip", at which point subsequent requests are short-circuited until a recovery period elapses and then the circuit is closed again after health checks succeed.
(8) HystrixCommand.getFallback()
The fallback is performed whenever a command execution fails - when an exception is thrown by (5) HystrixCommand.run(), when the command is (3) short-circuited because the circuit is open, or when the command's (4) thread pool and queue or semaphore are at capacity.
The intent of the fallback is to provide a generic response without any network dependency from an in-memory cache or other static logic.
If a network call is wanted in a fallback it should forward to another HystrixCommand.
(8a) Fallback Not Implemented
If [HystrixCommand.getFallback()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#getFallback(\)) is not implemented then an exception will be thrown and the caller left to deal with it.
(8b) Fallback Successful
If the fallback returns a response then it will be returned to the caller.
(8c) Fallback Failed
If [HystrixCommand.getFallback()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#getFallback(\)) fails and throws an exception then the caller is left to deal with it.
This is considered a poor practice to have a fallback implementation that can fail. A fallback should be implemented such that it is not performing any logic that would fail.
(9) Return Successful Response
If a (6a) successful response was received it will be returned to the caller.
## Circuit BreakerThe following diagram shows how a HystrixCommand interacts with a HystrixCircuitBreaker and its flow of logic and decision making including how the counters behave in the circuit breaker.
 (Click for larger view)
(Click for larger view)
Hystrix employs the bulkhead pattern to isolate dependencies from each other and limit concurrent access to any one of them.
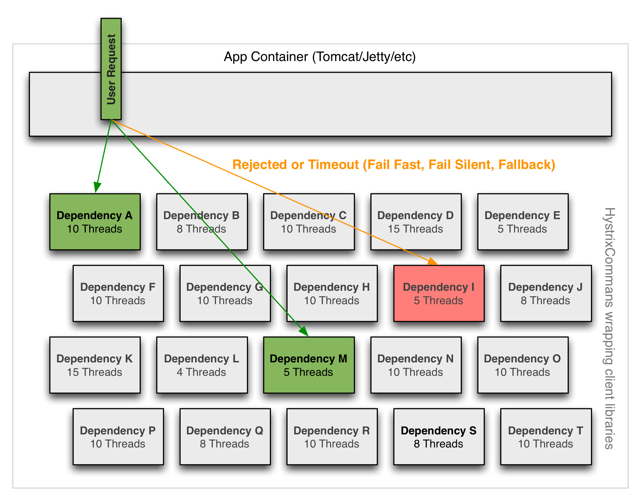
Executing clients (libraries, network calls, etc) on separate threads is used to isolate from the calling thread (Tomcat thread pool) so that a user request can "walk away" from a dependency call that is taking too long.
Separate thread pools per dependency are used so that concurrent requests to any given dependency are constrained so latency on the underlying executions will saturate the available threads only in that pool.
 (Click for larger view)
(Click for larger view)
Protection from failure can be done without the use of thread pools, but it requires the client being trusted to fail very quickly (network connect/read timeouts and retry configuration) and always behaving well.
Netflix chose the use of threads and thread-pools to achieve isolation for many reasons including:
- Many applications execute dozens (and sometimes well over 100) different backend service calls against dozens of different services from as many different teams.
- Each service provides its own client library.
- Client libraries are changing all the time.
- Client library logic can change to add additional network calls inside their clients.
- Client libraries can contain logic such as retries, data parsing, caching (in-memory or across network) and other such behavior.
- Client libraries tend to be "black boxes" and are opaque to their users about implementation details, network access patterns, configuration defaults, etc.
- In several production outages the outcome was "oh, something changed and properties should be adjusted" or "the client library changed its behavior"
- Even if a client itself doesn't change, the service itself can change which can then impact performance characteristics which can then cause the client configuration to be invalid.
- Transitive dependencies can pull in other client libraries that are not expected and perhaps not correctly configured.
- Most network access is performed synchronously.
- Failure and latency can occur in the client-side code as well, not just the network call.
 (Click for larger view)
(Click for larger view)
The benefits of isolation via threads in their own thread pools are:
- The application is fully protected from runaway client libraries. The pool for a given dependency library can fill up without impacting the rest of the application.
- The application can accept new client libraries with far lower risk. If an issue occurs, it is isolated to the library and doesn't affect everything else.
- When a failed client becomes healthy again, the thread pool will clear up and the application immediately resumes healthy performance as opposed to a long recovery when the entire Tomcat container is overwhelmed.
- If a client library is misconfigured, the health of a thread pool will quickly show (via increased errors, latency, timeouts, rejections, etc) and can be handled (typically in realtime via dynamic properties), without affecting application functionality.
- If a client service changes performance characteristics (which happens often enough to be an issue) which in turn cause a need to tune properties (increasing/decreasing timeouts, changing retries etc) this again becomes visible through thread pool metrics (errors, latency, timeouts, rejections) and can be handled without impacting other clients, requests or users.
- Beyond the isolation benefits, having dedicated thread pools provides built in concurrency which can be leveraged to build asynchronous facades on top of synchronous client libraries (similar to how the Netflix API built a functional reactive fully asynchronous Java API on top of Hystrix commands).
In short, the isolation provided by thread pools allows for the always changing and dynamic combination of client libraries and subsystem performance characteristics to be handled gracefully without causing outages.
The primary drawback of thread pools is that they add computational overhead since each command execution involves the queueing, scheduling and context switching for running the command on a separate thread.
At Netflix this overhead has been accepted for the benefits it provides and deemed small enough to not have major cost or performance impact.
Hystrix measures the latency when executing the run() method on the child thread as well as the total end-to-end time on the parent thread so we are able to see the cost of Hystrix overhead (threading, metrics, logging, circuit breaker, etc).
The Netflix API processes 10+ billion HystrixCommand executions per day using thread isolation. Each API instance has 40+ thread-pools with 5-20 threads in each (most are set to 10).
The following diagram represents one HystrixCommand being executed at 60 requests-per-second on a single API instance (of about 350 total threaded executions per second per server):
 (Click for larger view)
(Click for larger view)
At the median (and lower) there is no cost to having a separate thread.
At the 90th percentile there is a cost of 3ms for having a separate thread.
At the 99th percentile there is a cost of 9ms for having a separate thread. Note however that the increase in cost is far smaller than the increase in execution time of the separate thread (network request) which jumped from 2 to 28 whereas the cost jumped from 0 to 9.
This overhead at the 90th percentile and higher for circuits such as these has been deemed acceptable for most Netflix use cases for the benefits of resilience achieved.
For circuits that wrap very low latency requests (such as those primarily hitting in-memory caches) the overhead can be too high and in those cases we choose to use tryable semaphores which do not allow for timeouts but provide most of the resilience benefits without the overhead. The overhead in general though is small enough that we prefer the isolation benefits of a separate thread.
Semaphores (or counters) can be used to limit the number of concurrent calls to any given dependency instead of thread pool/queue sizes.
This allows shedding load without using thread pools but does not allow timing out and walking away.
So, if a client is trusted and only load shedding is wanted, then this approach would be sufficient.
Semaphores are supported by HystrixCommand in 2 places:
- Fallback: When retrieving fallbacks this always occurs on the calling Tomcat thread.
- Execution: When property "execution.isolation.strategy"==SEMAPHORE then semaphores will be used instead of threads to limit the number of concurrent parent threads invoking the command.
Both uses of semaphores can be configured via dynamic properties to define how many concurrent threads can execute. They should be sized using similar calculations as used for sizing a threadpool (an in-memory call that returns in sub-millisecond times can perform well over 5000rps with a semaphore of only 1 or 2 ... but we have it set to 10).
The one thing to be aware of is that if a dependency is isolated with a semaphore and then becomes latent, the parent threads will remain blocked until the underlying network calls timeout.
Semaphore rejection will start once the limit is hit but the threads filling the semaphore can not walk away.
## Request CollapsingA HystrixCommand can be fronted by a request collapser (HystrixCollapser is the abstract parent) which can be used to collapse multiple requests into a single backend dependency call.
The following diagram demonstrates the number of threads and network connections first without and then with request collapsing (assuming all connections are 'concurrent' within a short time window, in this case 10ms).
 (Click for larger view)
(Click for larger view)
The primary driver of using request collapsing is to reduce the number of threads and network connections needed to perform concurrent HystrixCommand executions and do so in an automated manner without forcing all developers of a codebase to coordinate manually batching of requests.
The ideal type of collapsing is done at the global application level, meaning requests from any user on any Tomcat thread can be collapsed together.
For example, if a HystrixCommand supports batching requests from multiple users to get movie ratings, then any user thread in the same JVM who concurrently wants to retrieve movie ratings could be collapsed into the same network call.
If a HystrixCommand can only handle batch requests for a single user, then requests from within a single Tomcat thread (request) can be collapsed.
For example, a user wants to load bookmarks for 300 video objects. Instead of executing 300 network calls, they can all be combined into one. (This can obviously be done explicitly via a batch request, request collapsing can perform the batching automatically).
Sometimes creating an object model that makes logical sense for consumption does not match up well with efficient resource utilization.
For example, given a list of 300 video objects, iterating over them and calling getBookmark() on each is an obvious object model, but if implemented naively can result in 300 network calls all being made within milliseconds of each other (and very likely saturating resources).
There are manual ways of handling this, such as before allowing the user to call getBookmark(), require them to declare what video objects they want to get bookmarks on so that they can all be pre-fetched.
Or, the object model could be separated so a user has to get a list of videos from one place, then ask for the bookmarks for that list of videos from somewhere else.
These approaches can lead to awkward APIs and object models that don't match mental models and usage patterns. They can also lead to simple mistakes and inefficiencies as multiple developers work on a codebase, since an optimization done for one use case can be broken by the implementation of another use case and path through the code.
Thus, by pushing the collapsing logic down to the Hystrix layer, it doesn't matter how the object model is created, in what order the calls are made or whether different developers know about optimizations being done or even needing to be done.
The getBookmark() method can be put wherever it fits best and be called in whatever manner suits the usage pattern and the collapser will automatically batch calls into time windows.
The cost of enabling request collapsing is an increased latency before the actual command is executed. The maximum cost is the size of the batch window, for example 10ms.
Thus, if you have a command that takes 5ms on median to execute, it could become 15ms in a worst case (with 10ms as the batch window). Typically a request will not be submitted to the window at the very start and thus the median penalty is half the window time, in this case 5ms.
Obviously, the determination of whether this cost is worth it depends on the command being executed. If the duration of the call is 50ms then a 5ms penalty is not significant for the potential reduction in network traffic.
Also, the amount of concurrency on a given command is key. There is no point in paying the penalty if there are rarely more than 1 or 2 requests to be batched together. In fact, in a single-threaded sequential iteration collapsing would be a major performance bottleneck as each iteration will wait the 10ms batch window time.
If however a particular command is heavily utilized concurrently and can batch dozens or even hundreds of calls together, then the cost is typically far outweighed by the increased throughput achieved by reducing required threads and network connections to dependencies.
 (Click for larger view)
(Click for larger view)
HystrixCommand implementations can define a cache key which is then used to de-dupe calls within a request context in a concurrent-aware manner.
Here is an example flow involving an HTTP request lifecycle and 2 threads doing work within that request:
 (Click for larger view)
(Click for larger view)
The benefits of request caching are:
- Different code paths can execute HystrixCommands without concern of duplicate work.
This is particularly beneficial in large codebases where many developers are implementing different pieces of functionality.
For example, multiple paths through code all need to get a user's Account object can each request it like this:
Account account = new UserGetAccount(accountId).execute();The Hystrix RequestCache will ensure the underlying run() method is executed once-and-only-once and both threads executing the HystrixCommand will receive the same data despite having instantiated different instances.
- Data retrieval is consistent throughout a request.
Instead of each time the command is executed potentially returning a different value (or fallback) the first response is cached and returned for all subsequent calls within the same request.
- Eliminates duplicate thread executions.
Since the request cache sits in front of the [run()](http://netflix.github.com/Hystrix/javadoc/index.html?com/netflix/hystrix/HystrixCommand.html#run(\)) method invocation, Hystrix can de-dupe calls before they result in thread execution.
If Hystrix didn't implement the request cache functionality then each command would need to implement it themselves inside the run method which is after a thread is queued and executed.