Implementation Status and planned TODOs #4
Comments
|
Just putting some notes about the last commit (7e67d8b) to explain the motivation behind such major changes and to verify with the rest of us that I didn't make any silly mistakes ( as usual.. ) This commit mainly had 3 goals: (other changes are minor)
I also want to bring attention to these few points (in case someone want to argue them):
|
|
Hi @Rayhane-mamah, using 7e67d8b I got an error that (in the end). You change he call -parameter name from Was that on purpose? AttentionWrapper from TF requires the parameter to be named Changing that back to
Any ideas? |
|
Hi @imdatsolak, thanks for reaching out. I encountered this problem on one of my machines, updating tensorflow to latest version solved the problem. (I changed the parameter to state according to latest tensorflow attention wrapper source code, I also want to point out that I am using TF 1.5 and confirm that attention wrapper works with "state" for this version and later). Try updating tensorflow and keep me notified, I'll look into it if the problem persists. |
|
@Rayhane-mamah, I tried with TF 1.5, which didn't work. Looking into TF 1.5, the parameter was still called |
|
Upgrading to TF1.6 (was 1.5) solved issue (TypeError: call() got an unexpected keyword argument 'previous_alignments') for me. |
|
@imdatsolak, yes my bad. @danshirron is perfectly right. I checked that my version is 1.6 too (i don't remember updating it Oo) |
|
Quick notes about the latest commit (7393fd5):
Side notes:
If there are any problems, please feel free to report them, I'll get to it as fast as possible |
|
Quick review of the latest changes (919c96a):
Side Notes:
If anyone tries to train the model, please think about providing us with some feedback. (especially if the model needs improvement) |
|
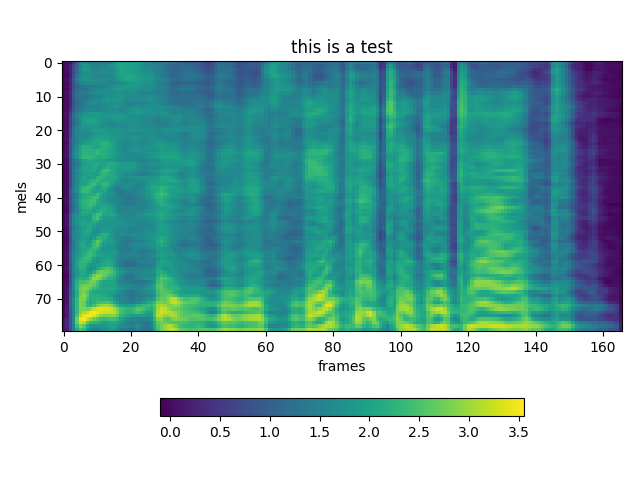
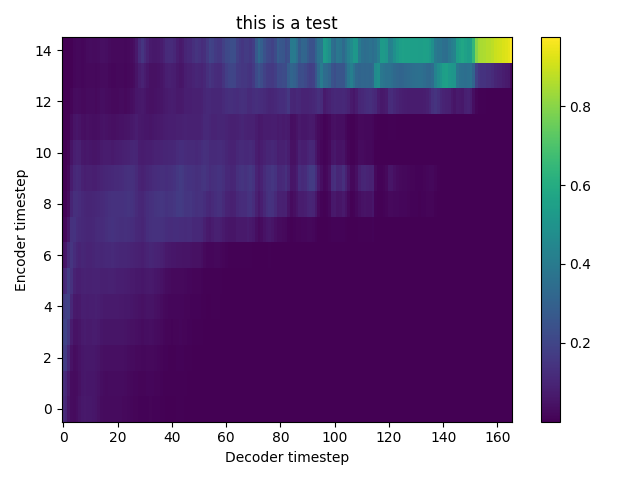
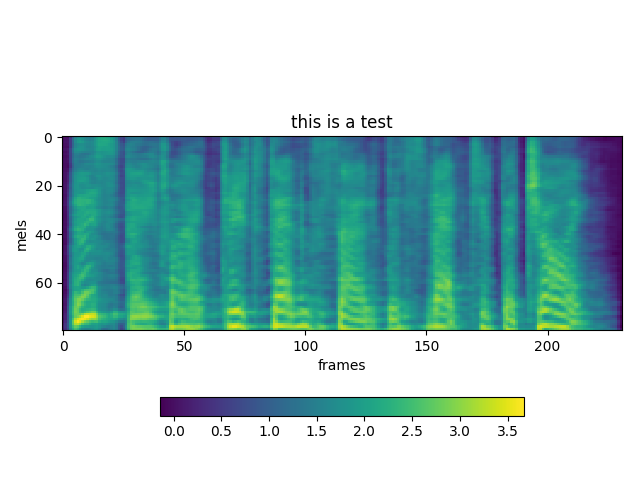
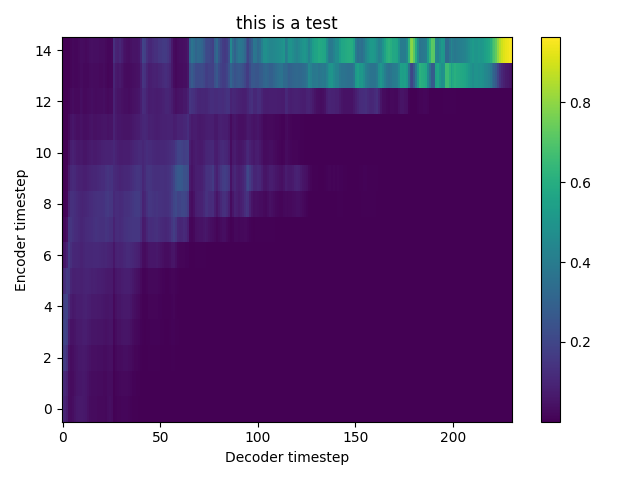
Hi @Rayhane-mamah, thanks for sharing your work. I cannot get a proper mel-spectrogram prediction and audible wave by Evaluation or Natural synthesis(No GTA) at step 50k. Is it works in your experiments? I attached some Mel-spectrogram plot samples with following sentences. 1 : “In Dallas, one of the nine agents was assigned to assist in security measures at Love Field, and four had protective assignments at the Trade Mart." Ground Truth GTA Natural(Eval) 2 : ”The remaining four had key responsibilities as members of the complement of the follow-up car in the motorcade." Ground Truth GTA Natural(Eval) 3 : “Three of these agents occupied positions on the running boards of the car, and the fourth was seated in the car." Ground Truth GTA Natural(Eval) |









|
Hello @ohleo, thank you for trying our work and especially for sharing your results with us. The problem you're reporting seems the same as the one @imdatsolak mentionned here. There are two possible reasons I can think of right now:
The fact that GTA is working fine highly supposes the problem is in the helper.. I will report back to you later tonight. In all cases, thanks a lot for your contribution, and hopefully we get around this issue soon. |
|
Hello, @Rayhane-mamah , do you get any further information running using the latest code? |
|
Hello @unwritten, thanks for reaching out. GTA stands for Ground Truth Aligned. Synthesizing audio using GTA is basically using teacher forcing to help the model predict Mel-spectrograms. If you aim to use the generated spectrograms to train some vocoder like Wavenet or else, then this is probably how you want to generate your spectrograms for now. It is important to note however that in a fully end-to-end test case, you won't be given the ground truth, so you will have to use the "natural" synthesis where the model will simply look at its last predicted frame to output the next one. (i.e: with no teacher forcing) Until my last commit, the model wasn't able to use natural synthesis properly and I was mainly suspecting the attention mechanism because, well, how is the model supposed to generate correct frames if it doesn't attend to the input sequence correctly.. Which brings us to your question. So after a long week end of debugging, it turned out that the attention mechanism is just fine, and that the problem might have been with some Tensorflow scopes or w/e.. (I'm not really quite sure what was the problem). Anyway, after going back through the entire architecture, trying some different preprocessing steps and replacing zoneout LSTMs with vanilla LSTMs, the problem seems to be solved (Now I am not entirely 100% sure as I have not yet trained the model too far, but things seem as they should be in early stages of training). I will update the repository in a bit (right after doing some cleaning), and there will be several references to papers used that the implementation was based on. These papers will be in pdf format in the "papers" folder, like that it's easier to find if you want to have an in depth look of the model. I will post some results (plots and griffin lim reconstructed audio) as soon as possible. Until then, if there is anything else I can assist you with, please let me know. Notes:
|
|
Hello again @unwritten. As promised I pushed the commit that contains the rectifications (c5e48a0). Results, samples and pretrained model will be coming shortly. |
Trying to understand "shortly", do you think they'll be out today, next week or next month? |
|
@PetrochukM, I was thinking more like next year.. that still counts as "shortly" I guess.. Enough messing around, let's say it will take a couple of days.. or a couple of weeks :p But what's important, it will be here eventually. |
|
Hi everybody, here is a new dataset that you can use to train Speech Recognition and Speech Synthesis: M-AILABS Speech Dataset. Have fun... |
|
@Rayhane-mamah thanks for the work;
|



|
Hi @imdatsolak, thank you very much for the notification. I will make sure to try it out as soon as possible. @unwritten, I experienced the same issue with the commit you're reporting. If your really don't want to waste your time and computation power for failed tests, you could wait a couple of days (at best) or a couple of weeks (at worst) until I post a 100% sure to work model, semi-pretrained which you can train further for better quality (I don't have the luxury to train for many steps at the moment unfortunately). Thank you very much for your contribution. If there is anything I can help you with or if you notice any problems, feel free to report back. |
|
@Rayhane-mamah thanks for the work; |
|
Hello @maozhiqiang, thank you for reaching out. In comparison to Tacotron-1 which uses simple summed L1 loss function (or MAE), we use (in Tacotron-2) a summed L2 loss function (or MSE). (The sum is in both cases is of predictions before and after the postnet). I won't pay much attention to the average along batch here for simplicity. Let's take a look at both losses: (h(xi) stands for the model estimation) L1 = ∑i |yi−h(xi)| The L1 loss is typically computing the residual loss between your model's predictions and the ground truth and returning the absolute value as is. The L2 loss however squares this error for each sample instead of simply returning the difference loss. Note: Next the model will only have to improve the vocal patterns, which consist of small adjustments, which explains why the loss then starts decreasing very slowly. So mainly, what I'm trying to point out here is that we are not using the same loss function as in Tacotron-1 which I believe is the main reason for such difference. However, there are some other factors like the difference in the model architecture, or even the difference in target itself. (In Tacotron-1, we predict both Mel-spectrogram and Linear spectrograms using the post-processing net). I believe this answers your question? Thanks again for reaching out, if there is anything else I can assist you with, please let me know. |
|
hello @Rayhane-mamah thanks for your detailed reply, |



|
Here is empirical evidence for @Rayhane-mamah 's reasoning.
Yellow line uses loss function of tacotron1, brown line uses loss function of tacotron2. Loss of brown is about square of loss of yellow. (and they intersect at 1.0!) |

|
Hello. There is one fundamental difference between @Rayhane-mamah 's With my modified version of Keithito's impl can make proper alignment, but yours cannot (Or just your impl requires more steps to make good alignment). I suspect the above mentioned difference for this result. (One strange behavior of your implementation is that the quality of synthesized samples on test set is quite good, though their alignments are poor. With Keithito's implementation, without proper alignment, test loss is really huge.) Do you have any idea about this? (Which one is right, concatenating previous attention or not?) |
|
hello @maozhiqiang and @a3626a , Thank you for your contribution. @maozhiqiang, The loss you're reporting is perfectly normal, actually the smaller the loss the better, which explains why the further your train your model the better the predicted Mel-spectrograms become. The only apparent problem which is also reported by @a3626a, is that the actual state of the repository (the actual model) isn't able to capture a good alignment. @maozhiqiang, alignments are supposed to look something like this: Now, @a3626a, about that repository comparison, I made these few charts to make sure we're on the same page, and to make it easier to explain (I'm bad with words T_T). Please note that for simplicity purposes, the encoder outputs call, the <stop_token> prediction part and the recurrent call of previous alignments were not represented. Here's my understanding on how keithito's Decoder works: The way I see it, he is using an extra stateful RNN cell to generate the query vector at each decoding step (I'm assuming this is based on T1 where 256-GRU is used for this purpose). He's using a 128-LSTM for this RNN. As you stated, the last decoder step outputs are indeed concatenated with the previous context vector before feeding them to the prenet (this is automatically done inside Tensorflow's attention_wrapper). Now, here's what my decoder looks like: In this chart, the blue and red arrows (and terms in equations) represent two different implementations I tried separately for the context vector computation. Functions with the same name in both graphs represent the same layers (look at the end of the comment for a brief explanation about each symbol). The actual state of the repository is the one represented in blue. i.e: I use the last decoder RNN output as query vector for the context vector computation. I also concatenate the decoder RNN output and the computed context vector to form the projection layer input. Now, after reading your comments (and thank you for your loss plot by the way), Two possible versions came to mind when thinking of your modified version to keithito's tacotron: First and most likely one: here I am supposing that you are using the previous context vector in the concatenation operations. (c_{i-1}) and then update your context vector at the end of the decoding step. This is what naturally happens if you wrap the entire TacotronDecoderCell (without the alignments and attention part) with Tensorflow's attention_wrapper. Second but less likely one: This actually seems weird to me because we're using the prenet output as a query vector.. Let's say i'm used to provide RNN outputs as query vector for attention computation. Is any of these assumptions right? Or are you doing something I didn't think of? Please feel free to share your approach with us! (words should do, no need for charts x) ) So, to wrap things up (so many wrapping..), I am aware that generating the query vector using an additional LSTM gives a proper alignment, I am however trying to figure out a way that doesn't necessarily use an "Extra" recurrent layer since it wasn't explicitly mentioned in T2 paper. (and let's be honest, I don't want my hardware to come back haunting me when it gets tired of all this computation). Sorry for the long comment, below are the symbols explained:
Note: |





|
Most of all, thank you for your reply with nice diagrams.
|
|
Hello again and thank you for your answers. "Speaker embedding" sounds exciting. I'm looking forward to hearing some samples once you're done making it! About the attention, this is actually a nice interpretation! I can't test it out right now but I will definitely do! If you do try it out please feel free to share your results with us. Thanks again for your contributions! |
|
I'm testing feeding 'previous cell state of first decoder LSTM cell', I will share the result after 1-2 days. Thank you. |
|
Wow, nice thread;) I will follow the discussion here and would like to look into your code. Thank you for sharing your work! |
|
Hi @Rayhane-mama, |
|
Hey @Rayhane-mamah Amazing work with the repo! Thanks! |
|
hi, |
|
hi, @Rayhane-mamah Could you tell me why, or is there any keyword I could search via Google? Thank you so much. |
|
Hi @Rayhane-mamah. Having the an issue similar to @osungv , above. I ran I've made no changes to the (latest) code, and I've ensured that the GPU is used. I did change GPU: GTX 1080 Any ideas? |
|
We have trained 200.000 steps with a small corpus. Not good result, but the weird thing is that everytime we syntetize the result is slightly different.
and hparams Any ideas why this could be happening? |
|
Hi, Can anyone guide me how can I fix this error? |
|
@Rayhane-mamah |
|
@atreyas313 I met same error, do you have solve it? |
|
@jgarciadominguez results are different everytime because we keep decoder prenet dropout active even during synthesis. As for the quality, your batch size if very small during training which causes the model to not learn how to align, thus the bad quality. Don't use smaller batch size than 32, it's okey to use outputs_per_step=3 for that purpose. @atreyas313 and @v-yunbin this "Both" option is causing everyone problems it seems, I took it off so please make sure to train with "Tacotron-2" instead (it will train Tacotron+Wavenet) @hadaev8 I thought about using that for faster computation but didn't really spend much time trying to apply zoneout on it, if you get any success with it let me know :) This is a sample of the wavenet from last commit on M-AILABS mary_ann: Because all objectives of this repo are now done, I will close this issue and make a tour on all issues open to answer most of them this evening. The pretrained models and samples will be updated soon in the README.md. If any problems persist, feel free to open issues. |
|
Hi there, first of all, I'm thankful for this code. I'm a beginner and trying to run it. With the parallelization implemented in datasets/preprocessor.py, I'm getting this error: Can somebody please convert this code to serial implementation:
I understood that i. __process_utterance (out_dir, index, wav_path, text) needs to be called for every input. But I couldn't yet understand how to modify this statement:
|
|
Hi Rayhane, I am running this code for the first time. I am training the tacotron-2 model using the LJSpeech dataset. The model is training without any issues, but on the cpu and not the gpus (checked with nvidia-smi). Is there anything that needs to be specified explicitly so that training can be done on the gpus? |
|
Hello, @anushaprakash90
Our implementation automatically uses your GPUs if tensorflow detects them.
So your issue is most likely related to your tensorflow installation.
I would recommend removing all your installed tensorflow libraries, then
only reinstall the gpu version of it (tensorflow-gpu). That should fix it.
Please refer to other closed similar issues for more info, and feel free to
start a new one if your problem persists or if you believe your issue is
different.
Thanks
…On Mon, 1 Oct 2018, 07:20 anushaprakash90, ***@***.***> wrote:
Hi Rayhane,
I am running this code for the first time. I am training the tacotron-2
model using the LJSpeech dataset. The model is training without any issues,
but on the cpu and not the gpus (checked with nvidia-smi). Is there
anything that needs to be specified explicitly so that training can be done
on the gpus?
—
You are receiving this because you modified the open/close state.
Reply to this email directly, view it on GitHub
<#4 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AhFSwBaDfT6OvJz0m2kdATeX8z2Q0Pegks5ugbQhgaJpZM4SSQwC>
.
|
|
@Rayhane-mamah Is the pretrained model ready ? |
|
@Rayhane-mamah Does there any sample radios inference with trained model? Does that sounds well or not? |
|
@Rayhane-mamah Thank you very much for the great repository, I like it. I see the clarinet paper and some code change are committed to our repository on 10.7. Does it mean it support clarinet now? Or do you have plan to support clarinet? |
|
@Rayhane-mamah In addition, the wavenet_preprocess.py directly get mel spectrograms at tacotron_output/gta for training data. What is the difference of two mel spectrograms from following two commands? Thank you. |
|
@Rayhane-mamah Thanks. After installing only tensorflow-gpu, I am able to run the code on the GPUs. I am now using the the updated scripts of Tacotron. When I run the code, it is running on all the available GPUs, but gives a segmentation fault just before training. This is perhaps a memory issue. I am trying to run the code on a single GPU. As mentioned in the hparams.py file, I have set num_gpus=0 and tacotron_gpu_start_idx appropriately. However, I am getting the following error: ValueError: Attr 'num_split' of 'Split' Op passed 0 less than minimum 1. Traceback: This requires tacotron_num_gpus to be set to at least 1 so that it can recognize that a GPU is available. Should I modify any other parameter, etc.? Thanks |
Update preprocessor.py
@Rayhane-mamah: Do you mean 60000 steps or 6000 steps ? |
|
What is the last model compatible with master? |
|
Hi @Rayhane-mamah! Can we train using jsut data? `Traceback (most recent call last): File "train.py", line 138, in Can you help!! |
|
is this project dead? are there any pretrained models? |
I'm not an author of this repository but I would agree that this repo is inactive and outdated. TTS is a very active area of research and production and there are modern alternatives that are very active, e.g., NeMo. |
this umbrella issue tracks my current progress and discuss priority of planned TODOs. It has been closed since all objectives are hit.
Goal
Model
Feature Prediction Model (Done)
Wavenet vocoder conditioned on Mel-Spectrogram (Done)
Scripts
Extra (optional):
Notes:
All models in this repository will be implemented in Tensorflow on a first stage, so in case you want to use a Wavenet vocoder implemented in Pytorch you can refer to this repository that shows very promising results.
The text was updated successfully, but these errors were encountered: