
利用计算机将大量的文本进行处理,产生简洁、精炼内容的过程就是文本摘要,人们可通过阅读摘要来把握文本主要内容,这不仅大大节省时间,更提高阅读效率。但人工摘要耗时又耗力,已不能满足日益增长的信息需求,因此借助计算机进行文本处理的自动文摘应运而生。近年来,自动文摘、信息检索、信息过滤、机器识别、等研究已成为了人们关注的热点。
自动文摘(Automatic Summarization)的方法主要有两种:Extraction和Abstraction。
其中Extraction是抽取式自动文摘方法,通过提取文档中已存在的关键词,句子形成摘要;Abstraction是生成式自动文摘方法,通过建立抽象的语意表示,使用自然语言生成技术,形成摘要。由于生成式自动摘要方法需要复杂的自然语言理解和生成技术支持,应用领域受限。所以本人学习的也是抽取式的自动文摘方法。
目前主要方法有:
-
基于统计: 统计词频,位置等信息,计算句子权值,再简选取权值高的句子作为文摘,特点:简单易用,但对词句的使用大多仅停留在表面信息。
-
基于图模型: 构建拓扑结构图,对词句进行排序。例如,TextRank/LexRank
-
基于潜在语义: 使用主题模型,挖掘词句隐藏信息。例如,采用LDA,HMM
-
基于整数规划: 将文摘问题转为整数线性规划,求全局最优解。
要了解TextRank的基本原理, 我们先从要知道PageRank的计算过程。
PageRank最开始用来计算网页的重要性。整个www可以看作一张有向图图,节点是网页。如果网页A存在到网页B的链接,那么有一条从网页A指向网页B的有向边。
构造完图后,使用下面的公式:

 = (1-d) + d* \sum_{j\in (V_i)} \frac{1}{|Out(V_j)|}S(V_j))
- S(Vi)是网页i的中重要性(PR值)。
- d是阻尼系数,一般设置为0.85。
- In(Vi)是存在指向网页i的链接的网页集合。
- Out(Vj)是网页j中的链接存在的链接指向的网页的集合。|Out(Vj)|是集合中元素的个数。
PageRank需要使用上面的公式多次迭代才能得到结果。初始时,可以设置每个网页的重要性为1。上面公式等号左边计算的结果是迭代后网页i的PR值,等号右边用到的PR值全是迭代前的。
TextRank 算法是一种用于文本的基于图的排序算法。其基本思想来源于谷歌的 PageRank算法, 通过把文本分割成若干组成单元(单词、句子)并建立图模型, 利用投票机制对文本中的重要成分进行排序, 仅利用单篇文档本身的信息即可实现关键词提取、文摘。和 LDA、HMM 等模型不同, TextRank不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。
最早提出TextRank的论文是: Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]. Association for Computational Linguistics, 2004.
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。将原文本拆分为句子,在每个句子中过滤掉停用词(可选),并只保留指定词性的单词(可选)。由此可以得到句子的集合和单词的集合。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
- 1、把给定的文本T按照完整句子进行分割,即

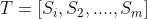
- 2、对于每个句子
 ,
,

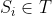
进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即

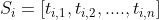
,其中

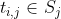
是保留后的候选关键词。
-
3、构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
-
4、根据上面公式,迭代传播各节点的权重,直至收敛。
-
5、对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
-
6、由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
文章1
记者,国家电网公司,获悉,9月23日,河北丰宁,二期,山东文登,重庆,蟠龙,抽水蓄能电站,工程,以下简称,丰宁,二期,文登,蟠龙,抽,蓄,座,抽,蓄,电站,正式,开工,总投资,244.4亿,元,总装机容量,480万,千瓦,计划,2022年,竣工,投产,项目,预计,增加,发电,装备制造业,产值,111亿,元,推动,相关,装备制造业,发展,开工,动员大会,国家电网公司,董事长,党组书记,刘振亚,丰宁,二期,文登,蟠龙,抽,蓄,国家电网公司,推进,特高压电网,建设,服务,清洁能源,发展,重大工程,继,2015年6月,安徽金寨,山东沂蒙,河南,天池,座,抽水蓄能电站,第二批,开工,电站,标志,我国,抽水蓄能电站,加快,发展,新,阶段,介绍,河北丰宁,二期,抽水蓄能电站,项目,位于,河北省承德市,丰宁县,装机容量,180万,千瓦,安装,台,30万,千瓦,可逆,式,水轮发电机组,500,千伏,电压,接,入,华北电网,工程投资,87.5亿,元,丰宁抽水蓄能电站,一期,二期,装机容量,360万,千瓦,世界上,装机容量,抽水蓄能电站,山东,文登抽水蓄能电站,位于,山东省,威海市文登区,装机容量,180万,千瓦,安装,台,30万,千瓦,可逆,式,水轮发电机组,500,千伏,电压,接,入,山东电网,工程投资,85.7亿,元,重庆,蟠龙,抽水蓄能电站,位于,重庆市綦江区,装机容量,120万,千瓦,安装,台,30万,千瓦,可逆,式,水轮发电机组,500,千伏,电压,接,入,重庆电网,工程投资,71.2亿,元,国网,座,受,端,电网,地区,抽水蓄能电站,建成,更好地,接纳,区,外,来电,优化,电源,结构,提高,北,西南,地区,清洁能源,消纳,能力,提高,特高压电网,系统安全,可靠性,综合,煤电,机组,消纳,清洁能源,效果,建设,丰宁,二期,文登,蟠龙,抽,蓄,年,节约,原煤,消耗,291万,吨,减排,烟尘,0.3万,吨,二氧化硫,1.4万,吨,氮氧化物,1.3万,吨,二氧化碳,485万,吨,节能减排,大气污染防治,国家电网公司,经营,区域,内在,运,抽水蓄能电站,装机容量,1674.5万,千瓦,建,规模,1880万,千瓦,预计,2017年,我国,抽水蓄能,装机,3300万,千瓦,超过,美国,世界上,抽水蓄能电站,第一,大国
第1篇文章的关键词
抽水蓄能电站 千瓦 二期 装机容量 国家电网公司 蟠龙 发展 开工 清洁能源 工程投资
参照“使用TextRank提取关键词”提取出若干关键词。若原文本中存在若干个关键词相邻的情况,那么这些关键词可以构成一个关键短语。
例如,在一篇介绍“支持向量机”的文章中,可以找到三个关键词 支持、向量、机,通过关键短语提取,可以得到支持向量机这样的短语.
方法一、
IBM公司科学家 H.P. Luhn 博士认为,文章的信息都包含在句子中,有些句子包含的信息多,有些句子包含的信息少。”自动摘要”就是要找出那些包含信息最多的句子。句子的信息量用”关键词”来衡量。如果包含的关键词越多,就说明这个句子越重要。Luhn提出用”簇”(cluster)表示关键词的聚集。所谓”簇”就是包含多个关键词的句子片段。Luhn的这种算法后来被简化,不再区分”簇”,只考虑句子包含的关键词。下面就是一个例子(采用伪码表示),只考虑关键词首先出现的句子。
TextTeaser开源的代码一共有三个class, TextTeaser, Parser, Summarizer。
TextTeaser ,程序入口类。给定待摘要的文本和文本题目,输出文本摘要,默认是原文中最重要的5句话。 Summarizer ,生成摘要类。计算出每句话的分数,并按照得分做排序,然后按照原文中句子的顺序依次输出得分最高的5句话作为摘要。 Parser ,文本解析类。对文本进行去除停用词、去除标点符号、分词、统计词频等一些预处理操作。
其中打分模型分为四部分:
***句子长度,***长度为20的句子为最理想的长度,依照距离这个长度来打分。 ***句子位置,***根据句子在全文中的位置,给出分数。(巴尔宾认为一篇文章的第二句比第一句更重要,因为很多作家都习惯到第二句话引入关键点)备注:用段落效果会怎样? ***文章标题与文章内容的关系,***句子是否包含标题词,根据句子中包含标题词的多少来打分。 ***句子关键词打分,***文本进行预处理之后,按照词频统计出排名前10的关键词,通过比较句子中包含关键词的情况,以及关键词分布的情况来打分(sbs,dbs两个函数)。
方法二、基于TextRank的自动文摘
基于TextRank的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘,其主要步骤如下:
***1、预处理:***将输入的文本或文本集的内容分割成句子得,构建图G =(V,E),其中V为句子集,对句子进行分词、去除停止词,得,其中是保留后的候选关键词。
***2、句子相似度计算:***构建图G中的边集E,基于句子间的内容覆盖率,给定两个句子,采用如下公式进行计算:

 = \frac{|{t_k}|}{log(|S_i|)+log(|S_j|)})
若两个句子之间的相似度大于给定的阈值,就认为这两个句子语义相关并将它们连接起来,即边的权值:
3、句子权重计算:根据公式

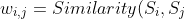)
,迭代传播权重计算各句子的得分;
***4、抽取文摘句:***将3得到的句子得分进行倒序排序,抽取重要度最高的T个句子作为候选文摘句。
***5、形成文摘:***根据字数或句子数要求,从候选文摘句中抽取句子组成文摘。
文章样例:
最近 有些 朋友 让 我 谈 读书 的 技术 问题 。 我 其实 并 没有 读过 很多 书 , 更 不是 什么 牛人 , 只是 硬着 头皮 谈谈 自己 的 心得体会 , 以下 如有 狂悖之处 , 还望 读者 谅解 。 为了 能在 较短 的 篇幅 内 把 事情 说完 , 我们 不 谈 怎么 读 论文 , 课本 及 其他 任何 学术 著作 , 只 谈 思想 类 的 “闲书” 。 这 可能 也是 最多人 关心 的 问题 。 读 这种 书 显然 不是 为了 涨工资 , 而是 为了 长见识 。 获得 见识 的 最好 办法 其实 不是 读书 , 而是 自己 去 身体 力行 : 你 想 了解 或者 批评 警察 , 最好 的 办法 是 自己 先去 当 六个月 警察 。但 读书 是 获得 见识 最快 的 办法 。
摘要:
为了能在较短的篇幅内把事情说完,我们不谈怎么读论文,课本及其他任何学术著作,只谈思想类的“闲书”获得见识的最好办法其实不是读书,而是自己去身体力行:你想了解或者批评警察,最好的办法是自己先去当六个月警察
ps 文章预先已经提前分词完毕。
1、文章分词: 对每一篇文章进行分词,分词系统主要由坤雁分词系统、ansj分词,结巴分词等。
2、分词结果数据清洗: 主要包括去停用词、去除符号字母数字等。
3、构建候选关键词图: 根据设定的词语选择窗口截取文本的分词结果,将每个词语作为候选关键词图的节点,截取的每一段文本中的词语作为相邻的边,以此构建候选关键词图。
4、关键词提取: 利用pagerank思想循环迭代候选关键词图,
1、文章分词,切句: 对每一篇文章进行分词,分词系统主要由坤雁分词系统、ansj分词,结巴分词等。
2、分词结果数据清洗: 主要包括去停用词、去除符号字母数字等。
3、构建候选关键词图: 根据短句的相似度构建句子的边,将每个句子作为候选关键词图的节点,截取的每一段文本中的词语作为相邻的边,以此构建候选关键词图。
4、关键词提取: 利用pagerank思想循环迭代候选关键词图,
PageRank本身非常巧妙了, TextRank更是巧妙的将PageRank应用到NLP中的词排序或句子排序上面, 比如关键词抽取, 文本摘要等.
- David Adamo: TextRank
- The Automatic Creation of Literature Abstracts
- Automatic Summarization
- TextRank
- PageRank
大家如果有疑问或者不同的看法可以在讨论区一起讨论。