-
Notifications
You must be signed in to change notification settings - Fork 146
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
feat: Added wiki on keyword spotting with TensorFlow Lite
- Loading branch information
1 parent
350c864
commit 6bf9518
Showing
1 changed file
with
221 additions
and
0 deletions.
There are no files selected for viewing
221 changes: 221 additions & 0 deletions
221
...sor/ReSpeaker_2-Mics_Pi_HAT/v2/ReSpeaker_2_Mics_Pi_Hat_v2_Speech_Recognition.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,221 @@ | ||
| --- | ||
| description: This wiki will demonstrate how you can use TensorFlow Lite for keyword spotting with ReSpeaker 2-Mics Pi HAT v2 and perform speech recognition. | ||
| title: Keyword Spotting with TensorFlow Lite | ||
| keywords: | ||
| - ReSpeaker_2-Mics_Pi_HAT | ||
| - Keyword_Spotting | ||
| - TensorFlow_Lite | ||
| image: https://files.seeedstudio.com/wiki/ReSpeaker_2_Mics_Pi_HAT/social-image.webp | ||
| slug: /respeaker_2_mics_pi_hat_v2_speech_recognition | ||
| last_update: | ||
| date: 12/23/2024 | ||
| author: Joshua Lee | ||
| --- | ||
|
|
||
| ## Introduction | ||
|
|
||
| This project demonstrates how to use TensorFlow Lite for keyword spotting on the ReSpeaker 2-Mics Pi HAT v2. Keyword spotting allows for real-time detection of predefined words from audio input, enabling applications such as voice-controlled devices and interactive systems. We will guide you through the steps to train a TensorFlow Lite model, deploy it on the ReSpeaker HAT, and run speech recognition locally. | ||
|
|
||
| ### Hardware and Software Requirements | ||
|
|
||
| - Hardware: Raspberry Pi with ReSpeaker 2-Mics Pi HAT v2 | ||
| - Software: TensorFlow Lite, Google Colab, Python, and supporting libraries | ||
|
|
||
| ### Applications | ||
|
|
||
| Keyword spotting can be applied in: | ||
|
|
||
| - Smart home devices | ||
| - Voice-controlled robots | ||
| - Interactive kiosks | ||
|
|
||
| ### What is TensorFlow Lite? | ||
|
|
||
| TensorFlow Lite is a lightweight version of TensorFlow designed for mobile and embedded devices. It enables machine learning inference with low latency and small binary sizes, making it ideal for running models on edge devices like Raspberry Pi. | ||
|
|
||
| ## Train and Get TensorFlow Lite Model | ||
|
|
||
| ### Dataset | ||
|
|
||
| We will use a subset of the Speech Commands dataset for training. The dataset contains WAV audio files of people saying different words, collected by Google and released under a CC BY license. The dataset can be downloaded from here. For more information on datasets, refer to this guide. | ||
|
|
||
| ### Why Use Google Colab? | ||
|
|
||
| Google Colab is a cloud-based platform for running Jupyter notebooks. It provides free access to GPU resources, making it an excellent choice for training machine learning models without requiring local computation power. | ||
|
|
||
| ### Steps | ||
|
|
||
| Now we will use a Google Colab Notebook to perform the data training and generate a TensorFlow Lite model in `.tflite` format. | ||
|
|
||
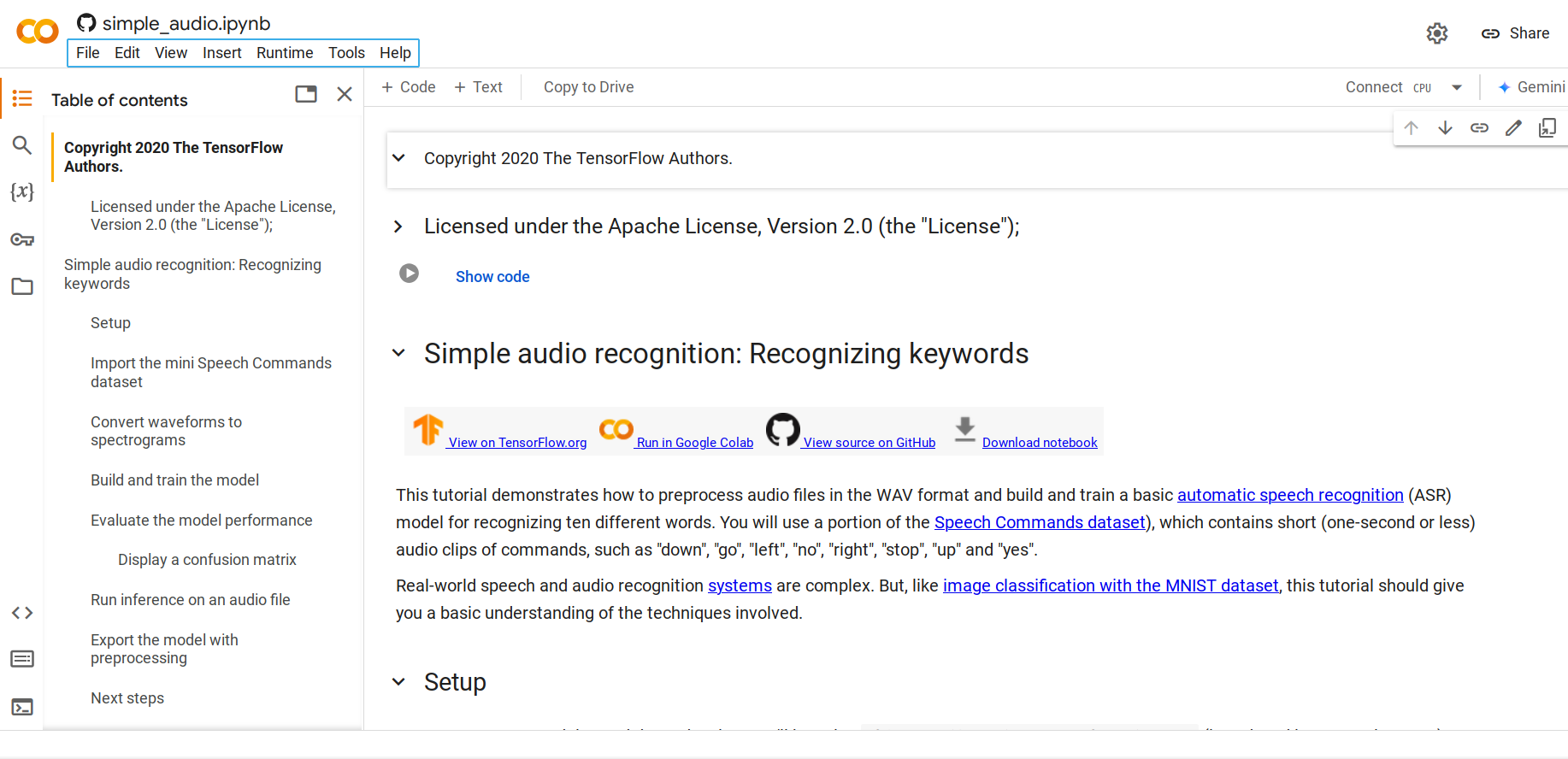
| - **Step 1.** Open [this Python Notebook](https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/audio/simple_audio.ipynb) | ||
|
|
||
|  | ||
|
|
||
| By default, it will load [the mini Speech Commands dataset](http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip) which is a smaller version of the Speech Commands dataset. The original dataset consists of over 105,000 audio files in the WAV (Waveform) audio file format of people saying 35 different words. This data was collected by Google and released under a CC BY license. | ||
|
|
||
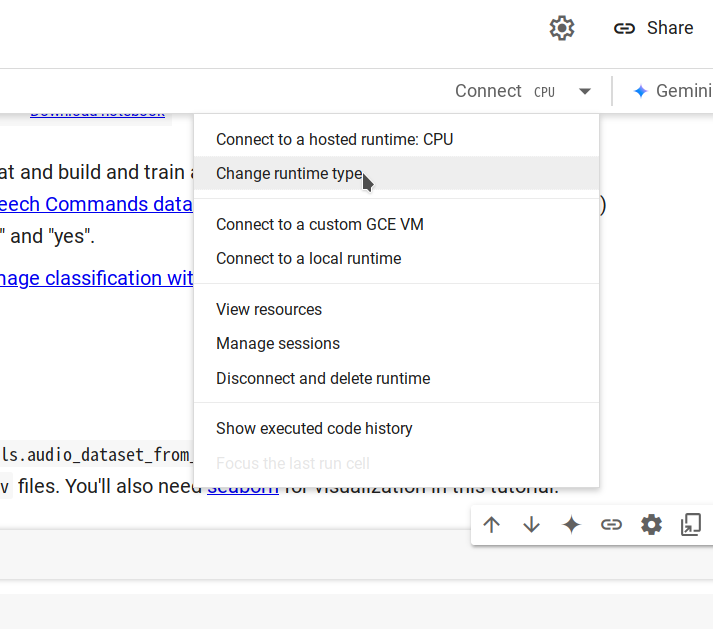
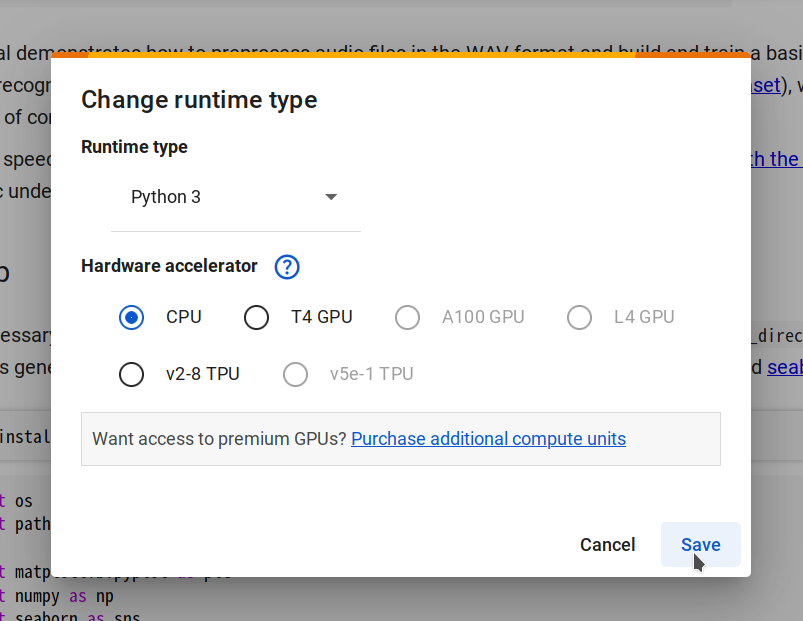
| - **Step 2.** Connect to a new runtime by selecting **Changing runtime type -> CPU -> Save**, then click **Connect**. | ||
|
|
||
|  | ||
|  | ||
|
|
||
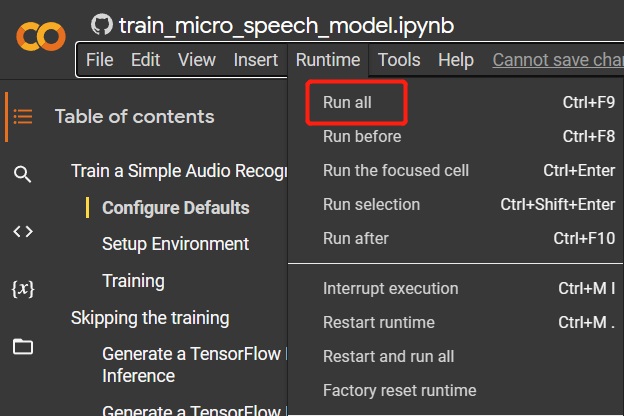
| - **Step 3.** Navigate to `Runtime > Run all` to run all the code cells. This process will take about 10 minutes to complete. | ||
|
|
||
|  | ||
|
|
||
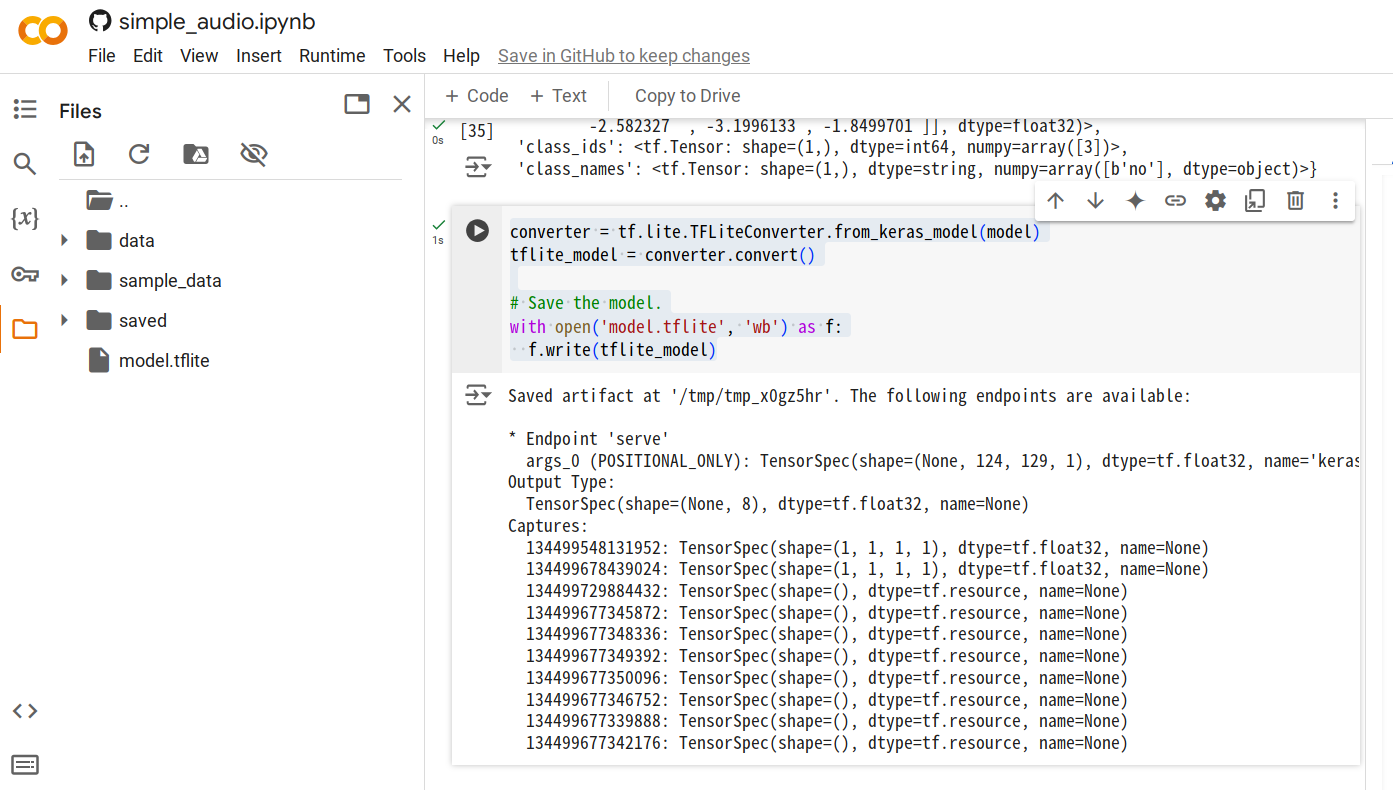
| - **Step 4.** Once all the code cells are executed, append a new cell and run the following code to generate the `.tflite` model file. | ||
|
|
||
| ```python | ||
| converter = tf.lite.TFLiteConverter.from_keras_model(model) | ||
| tflite_model = converter.convert() | ||
|
|
||
| with open('model.tflite', 'wb') as f: | ||
| f.write(tflite_model) | ||
| ``` | ||
|
|
||
|  | ||
|
|
||
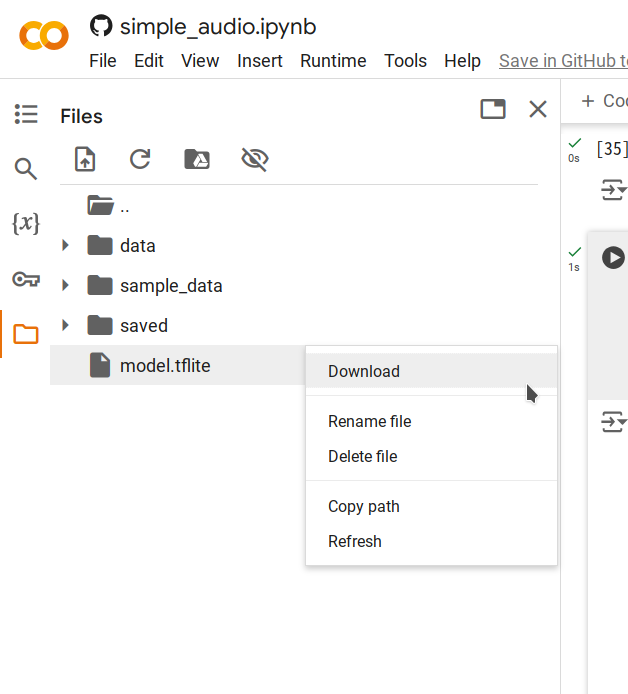
| - **Step 5.** Right click the generated `model.tflite` file and select **Download** to save the file to your computer. | ||
|
|
||
|  | ||
|
|
||
| ## Local Inference | ||
|
|
||
| ### Running the Inference Script | ||
|
|
||
| The script inference.py performs the following steps: | ||
|
|
||
| 1. Loads the trained TensorFlow Lite model. | ||
| 2. Processes input audio into a spectrogram suitable for inference. | ||
| 3. Runs the inference and outputs the detected keyword along with confidence scores for each label. | ||
|
|
||
| ### Steps to Run | ||
|
|
||
| 1. Upload the `model.tflite` model file to your Pi, in this example, we put it in `~/speech_recognition/model.tflite`. | ||
| 2. Save the following script as `~/speech_recognition/inference.py`: | ||
|
|
||
| ```python | ||
| import numpy as np | ||
| from scipy import signal | ||
| from tflite_runtime.interpreter import Interpreter | ||
| import soundfile as sf | ||
|
|
||
| MODEL_PATH = 'model.tflite' | ||
| LABELS = ['no', 'yes', 'down', 'go', 'left', 'up', 'right', 'stop'] | ||
|
|
||
|
|
||
| def get_spectrogram(waveform, expected_time_steps=124, expected_freq_bins=129): | ||
| _, _, Zxx = signal.stft( | ||
| waveform, | ||
| fs=16000, | ||
| nperseg=255, | ||
| noverlap=124, | ||
| nfft=256 | ||
| ) | ||
| spectrogram = np.abs(Zxx) | ||
|
|
||
| if spectrogram.shape[0] != expected_freq_bins: | ||
| spectrogram = np.pad(spectrogram, (( | ||
| 0, expected_freq_bins - spectrogram.shape[0]), (0, 0)), mode='constant') | ||
| if spectrogram.shape[1] != expected_time_steps: | ||
| spectrogram = np.pad(spectrogram, (( | ||
| 0, 0), (0, expected_time_steps - spectrogram.shape[1])), mode='constant') | ||
|
|
||
| if spectrogram.shape != (expected_freq_bins, expected_time_steps): | ||
| raise ValueError( | ||
| f"Invalid spectrogram shape. Got {spectrogram.shape}, expected ({expected_freq_bins}, {expected_time_steps})." | ||
| ) | ||
|
|
||
| spectrogram = np.transpose(spectrogram) | ||
|
|
||
| return spectrogram | ||
|
|
||
|
|
||
| def preprocess_audio(file_path): | ||
| waveform, sample_rate = sf.read(file_path) | ||
| if sample_rate != 16000: | ||
| raise ValueError("Expected sample rate is 16 kHz") | ||
|
|
||
| if len(waveform.shape) > 1: | ||
| waveform = waveform[:, 0] | ||
|
|
||
| spectrogram = get_spectrogram(waveform) | ||
| spectrogram = spectrogram[..., np.newaxis] | ||
| spectrogram = spectrogram[np.newaxis, ...] | ||
|
|
||
| return spectrogram | ||
|
|
||
|
|
||
| def run_inference(file_path): | ||
| spectrogram = preprocess_audio(file_path) | ||
|
|
||
| interpreter = Interpreter(MODEL_PATH) | ||
| interpreter.allocate_tensors() | ||
|
|
||
| input_details = interpreter.get_input_details() | ||
| output_details = interpreter.get_output_details() | ||
|
|
||
| input_shape = input_details[0]['shape'] | ||
| if spectrogram.shape != tuple(input_shape): | ||
| raise ValueError( | ||
| f"Expected input shape {input_shape}, got {spectrogram.shape}" | ||
| ) | ||
|
|
||
| interpreter.set_tensor( | ||
| input_details[0]['index'], spectrogram.astype(np.float32)) | ||
|
|
||
| interpreter.invoke() | ||
|
|
||
| output_data = interpreter.get_tensor(output_details[0]['index'])[0] | ||
| prediction = np.argmax(output_data) | ||
| confidence = np.exp(output_data) / \ | ||
| np.sum(np.exp(output_data)) | ||
|
|
||
| print(f"command: {LABELS[prediction].upper()}") | ||
| for label, conf in zip(LABELS, confidence): | ||
| print(f"{label}: {conf:.2%}") | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| audio_file_path = 'test_audio.wav' | ||
| run_inference(audio_file_path) | ||
| ``` | ||
|
|
||
| 3. Record a sound using the following command, available keywords are: `no`, `yes`, `down`, `go`, `left`, `up`, `right`, `stop`. | ||
|
|
||
| ``` | ||
| $ arecord -D "plughw:2,0" -f S16_LE -r 16000 -d 1 -t wav ~/speech_recognition/test_audio.wav | ||
| ``` | ||
|
|
||
| 4. Execute the script: | ||
|
|
||
| ``` | ||
| $ python3 inference.py | ||
| INFO: Created TensorFlow Lite XNNPACK delegate for CPU. | ||
| command: YES | ||
| no: 8.74% | ||
| yes: 21.10% | ||
| down: 5.85% | ||
| go: 14.57% | ||
| left: 11.02% | ||
| up: 8.25% | ||
| right: 10.53% | ||
| stop: 19.94% | ||
| ``` | ||
|
|
||
| ### Interpreting the Results | ||
|
|
||
| The script outputs the detected command (e.g., YES) and the confidence scores for all labels. This provides insights into the model’s predictions and allows you to evaluate its performance. | ||
|
|
||
| ## Tech Support & Product Discussion | ||
|
|
||
| Thank you for choosing our products! We are here to provide you with different support to ensure that your experience with our products is as smooth as possible. We offer several communication channels to cater to different preferences and needs. | ||
|
|
||
| <div class="button_tech_support_container"> | ||
| <a href="https://forum.seeedstudio.com/" class="button_forum"></a> | ||
| <a href="https://www.seeedstudio.com/contacts" class="button_email"></a> | ||
| </div> | ||
|
|
||
| <div class="button_tech_support_container"> | ||
| <a href="https://discord.gg/eWkprNDMU7" class="button_discord"></a> | ||
| <a href="https://github.com/Seeed-Studio/wiki-documents/discussions/69" class="button_discussion"></a> | ||
| </div> |