


포토부스의 사진을 공유하고, 만남을 연결하는 서비스 축팅입니다.
축팅은 네컷사진을 중심으로 한 만남의 플랫폼입니다.
남성 사용자가 많은 데이팅 앱 시장의 문제점을 해결하기 위해 여성 사용자가 많은 네컷사진 시장을 접목시켰습니다.
사용자는 네컷사진을 게시하고, 축팅의 재화인 폭죽을 사용하여 마음에 드는 상대의 인스타그램에 방문할 수 있습니다.
- FE 배포 주소에 방문해보세요!
- BE 배포 주소
- Sample : 홈 피드 조회 API - 로그인 안 된 경우
프론트엔드 3인, 백엔드 4인으로 이루어진 7인 팀 SPARK 입니다.
| BE | FE | |||||
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
| 고범수 | 김유선 | 송가은 | 황대선 | 김민주 | 박건형 | 서완석 |
| 테크리더 | 타임키퍼 | 리마인더 | 조장 | 리액셔너 | 기획리더 | 테크리더 |
개발 기간 : 2023년 8월 25일 ~ 2023년 11월 11일
카카오 테크 캠퍼스(이하 카테캠) 3단계 과제 수행 프로젝트 중 BE 개발을 다루고 있습니다.
기획부터 배포까지 서비스 개발에 필요한 전반적인 과정을 경험했습니다.

프로젝트 진행하며 각자 고민한 부분들은 고범수,황대선, 김유선, 송가은을 누르시면 바로 보실 수 있습니다 :)
 |
 |
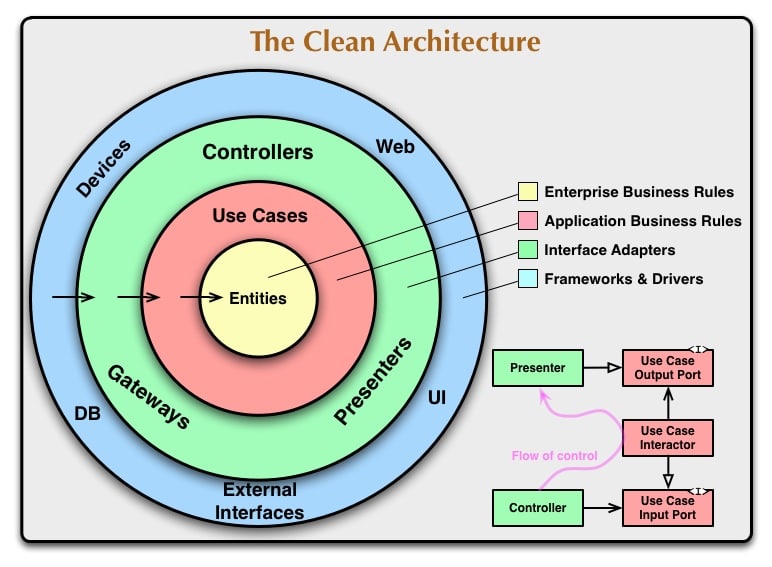
| 클린 아키텍처 | 버티컬 슬라이싱 아키텍처 |
적용 사례를 "행동 - 문제인식 - 해결"의 순서로 정리해보겠습니다.
- 시도한 행동: 프로젝트 초기에는 클린 아키텍처를 적용하려고 시도했습니다. 이는 코드의 유지보수성과 확장성을 높이기 위한 목적이었습니다
문제 발생 프로젝트의 크기와 복잡성을 고려했을 때, 클린 아키텍처의 적용은 불필요한 계층을 만들어내고, 인터페이스의 역할만 강조되는 문제를 발생시켰습니다.
인식된 문제 클린 아키텍처는 이론적으로는 이상적이지만, 프로젝트의 실제 요구사항과 규모에 비해 과도한 구조적 복잡성을 초래했습니다. 이는 팀내의 인지 과부화를 발생시키고, 학습 곡선을 가파르게 만들었습니다.
왜 이 방법을 선택했는가:
- 결합도 낮춤
- 전체 시스템의 결합도를 낮추기 위해 각 기능을 독립적인 단위로 나누어, 모듈 간의 강한 결합을 피하고 유연한 구조를 만들고 싶었습니다
- 인지 과부화 방지
- 불필요한 복잡성을 제거하고,개발자가 각 모듈의 기능과 역할을 더 명확하게 이해할 수 있게 하기 위함입니다
Controller에서는 사용자의 행위 단위를 반영하여 각 엔드포인트에 usecase를 할당했습니다.
이는 비즈니스 로직을 usecase에 위임함으로써 효율적인 관리를 하기 위함이었습니다
복잡성이 낮은 경우 usecase가 바로 repository에 의존할 수 있으며, 복잡도가 높아질 경우 command라는 하위 모듈을 사용해 의존성을 낮추는 전략을 사용했습니다
이러한 접근 방식은 시스템의 각 부분이 효과적으로 상호 작용하면서도 필요에 따라 독립적으로 작동할 수 있도록 하여, 전체적인 시스템의 유연성과 확장성을 강화하려는 의도였습니다.
하이퍼 링크를 클릭하시면 해당 기능의 세부 사항을 확인 하실 수 있습니다
| 기능 | 설명 | 담당자 |
|---|---|---|
| 게시물 업로드 | 해시태그, 닉네임, 이미지를 포함한 게시글을 업로드하는 기능 구현. | 황대선, 고범수 |
| 인기 피드 조회 | 클라이언트가 level1, level2, level3 게시물을 각각 최대 10개까지 요청. MariaDB에 저장된 게시글들의 개수 확인 (30개 이상 여부). PostRandomFetcher 클래스를 통해 랜덤하게 게시물 선택. Redis의 SortedSet 자료구조를 이용하여 순위 조회. | 황대선 |
| 조회수 | Redis의 Set 자료구조를 사용하여 게시글 조회 시 회원의 Primary Key를 저장함으로써, 한 회원이 조회수를 악의적으로 조작하는 것을 방지합니다. 스케줄러를 활용하여 10분마다 Redis의 Set 자료구조에 저장된 데이터를 기반으로 MariaDB에 게시글의 조회수를 업데이트하고, 이후 Set 자료구조의 데이터를 초기화(롤백)합니다 |
황대선 |
| 인기 게시글 선정 | 인기도는 게시글의 연령, 조회수, 그리고 추천 수를 기반으로 하여 10분마다 갱신. Redis의 SortedSet 자료구조에 저장. | 황대선 |
| 폭죽 사용 | 해당 인기 게시글의 레벨을 검증한 후, 그에 해당하는 포인트를 사용. 사용자의 포인트가 충분할 경우, 해당 게시물의 소유자의 인스타그램 아이디 반환. | 황대선, 고범수 |
| 예외 처리 | RuntimeException 클래스 상속하여 커스텀 예외 생성. GlobalExceptionHander와 PostExceptionHandler 클래스를 이용한 예외 핸들링. MessageCode 클래스를 통해 오류 코드와 설명 제공. | 황대선 |
| API 응답 | ApiResponse 클래스와 ApiResponseGenerator 클래스를 생성하여 API 응답 표준화. | 황대선 |
| 아키텍처 설계 | Layred Architecture에 따른 설계. Presentation, Application, Infrastructure Layer 및 예외 처리 클래스 구성. | 황대선, 고범수 |
| 각종 컨벤션 | 네이밍 및 커밋 컨벤션 정의. | 황대선, 고범수 |
| 카카오 로그인 | 카카오 OAuth2 Rest API를 사용한 로그인 및 사용자 정보 조회 기능 구현. | 김유선 |
| 인스타그램 연동 | Instagram Graph OAuth2 Rest API를 사용한 로그인 및 사용자 정보 조회 기능 구현. | 김유선 |
| JWT 토큰 | 사용자 식별 UID 및 권한을 담은 토큰 발급 기능 구현. | 김유선 |
| 토큰 관리 | 엑세스토큰과 리프레시토큰 발급 기능 개발. | 김유선 |
| CORS 설정 | 프론트배포URL에서만 백엔드서버 API 요청 및 응답 가능하도록 CORS 설정. | 김유선 |
| 접근권한 설정 | API 별 접근권한 설정 및 사용자 ROLE 별 기능 제한. | 김유선 |
| 피드 조회 공통 클래스 구현 | PostFetchResponse 클래스는 홈피드와 마이피드 등 다양한 피드 조회 기능에서 사용되는 공통 구조를 정의합니다. 이 클래스를 사용함으로써 다양한 피드 조회 시나리오에서 코드 중복을 줄였습니다. | 고범수 |
| 홈 피드 | 사용자 인증 상태에 따라 다른 정보를 제공하는 홈 피드 구현. | 고범수 |
| 자신이 올린 게시물 조회 | 커서 기반 무한 스크롤 방식을 사용한 게시물 조회 기능. | 고범수, 송가은 |
| 토글 방식의 좋아요 기능 | 단일 엔드포인트를 통한 좋아요 토글 기능 구현. | 고범수 |
| 폭죽 사용 기록 추적 | 폭죽 사용 기록 추적 및 instacount 테이블 도입으로 데이터 처리 개선. |
고범수 |
| 유저 계정 정보 조회 | 도메인 중심 전략을 통한 유저 계정 정보 조회 기능 구현. | 고범수, 송가은 |
| 쿠버네티스 환경 배포 | 쿠버네티스 환경에서의 백엔드 프로젝트 배포 및 관리. | 고범수 |
-
Commit Convention Commit Convention · Issue #20 · Step3-kakao-tech-campus/Team14_BE
-
Branch Naming Convention Branch Naming Convention · Issue #9 · Step3-kakao-tech-campus/Team14_BE
-
Naming Convention Naming Convention · Issue #15 · Step3-kakao-tech-campus/Team14_BE
- JDK 17
- Springboot 2.7.15
- SpringSecurity
- MySQL : 8.0.33
- Redis 7.2
- java-jwt 4.3.0
| 섹션 | 상세 내용 | 설명 |
|---|---|---|
| 게시물 업로드 | 외부 images 폴더 | 해시태그, 닉네임, 이미지를 포함한 게시글을 업로드하는 기능을 구현하였습니다. |
| 인기 피드 조회 | PostRandomFetcher 클래스를 이용해, 조회할 등수 결정하고 해당 등수의 게시글들을 Redis에서 조회 | 클라이언트가 level1, level2, level3 게시물을 각각 최대 10개까지 요청하면, MariaDB에 저장된 게시글들의 개수가 30개 이상인지 여부를 확인합니다. 이후, PostRandomFetcher 클래스는 각 레벨에 맞는 게시물들을 랜덤하게 선택할 순위를 결정합니다. 이 순위들은 Redis의 SortedSet 자료구조를 통해 조회됩니다. level3 게시물은 1등부터 10등 사이의 게시물들 중에서 선택됩니다. level2 게시물은 11등부터 20등 사이의 게시물들 중에서 선택됩니다. level1 게시물은 21등부터 30등 사이의 게시물들 중에서 선택됩니다. |
| 조회수 기능 | 악의적인 조회수 증가 방지 | Redis의 Set 자료구조를 사용하여 게시글 조회 시 회원의 Primary Key를 저장함으로써, 한 회원이 조회수를 악의적으로 조작하는 것을 방지합니다. 스케줄러를 활용하여 10분마다 Redis의 Set 자료구조에 저장된 데이터를 기반으로 MariaDB에 게시글의 조회수를 업데이트하고, 이후 Set 자료구조의 데이터를 초기화(롤백)합니다. |
| 인기 게시글 선정 | 인기도를 기반을로한 인기 게시글 선정 | 인기도는 게시글의 연령, 조회수, 그리고 추천 수를 기반으로 하여 10분마다 갱신됩니다. 게시물의 고유 식별자인 Post의 Primary Key는 인기도를 기준으로 Redis의 SortedSet 자료구조에 저장되며, 이 데이터 역시 10분마다 갱신됩니다. |
| 폭죽 사용 | 인기 레벨에 따른 폭죽 사용 | 해당 인기 게시글의 레벨을 검증한 후, 그에 해당하는 포인트를 사용합니다. 사용자의 포인트가 충분할 경우, 해당 게시물의 소유자의 인스타그램 아이디를 반환합니다. 포인트가 부족하면, 아이디 반환은 이루어지지 않습니다. |
| 예외 처리 | 공통 예외 처리 및 특정 도메인 예외 처리 | RuntimeException 클래스를 상속하여 예외 클래스를 생성하여 비즈니스에 맞는 커스텀 예외를 생성하였습니다. 일관성을 위해 GlobalExceptionHander 클래스를 이용해 Post 도메인을 제외한 도메인들의 예외를 핸들링하였고, 확장성을 위해 PostExceptionHandler 클래스를 이용해 Post 관련 예외를 핸들링하였습니다. 유지보수의 용이성과 Http Status 와 Http Status Code 이외에도 클라이언트에게 상세한 정보 제공을 위해 MessageCode 클래스를 만들어 오류 코드와 오류에 대한 설명을 제공하였습니다. |
| API 응답 | 표준화된 API 응답 제공 | ApiResponse 클래스를 생성하여 응답을 정의 및 ApiResponseGenerator 클래스를 생성하여 ApiResponse 객체를 생성하는 정적 메서드를 제공하여 API 응답을 표준화하여 API 개발 시 일관된 응답 형식을 유지할 수 있도록 하였습니다. |
| 아키텍처 설계 | 전체적인 시스템의 결합도 낮춤, 개발자의 인지 과부화 방지, 적절한 학습 곡선과 코드 품질을 위해 Layred Architecture 선정 | 축팅의 Layred Architecture: 프레젠테이션 레이어 (Presentation Layer) - controller 애플리케이션 레이어 (Application Layer) - usecase는 하나의 기능 단위를 의미 - Get 또는 Set으로 시작하는 클래스명 사용 - command는 usecase에 물린 더 작은 기능 단위를 의미 - Find, FindAll, Save로 시작하는 클래스 명 사용 매퍼 - 데이터를 매핑 시켜주는 역할 인프라 레이어 (Infrastructure Layer) - repository 예외 - 각 도메인에 대한 특화된 예외 처리 클래스, 각 도메인의 예외 정의 |
| 각종 컨벤션 | 개발 관련 컨벤션 | 네이밍 컨벤션: 네이밍 컨벤션 커밋 컨벤션: 커밋 컨벤션 |
| 섹션 | 상세 내용 | 설명 |
|---|---|---|
| 피드 구현 | PostFetchResponse: 피드 조회 공통 클래스 구현 | PostFetchResponse 클래스는 홈피드와 마이피드 등 다양한 피드 조회 기능에서 사용되는 공통 구조를 정의합니다. 이 클래스를 사용함으로써 다양한 피드 조회 시나리오에서 코드 중복을 줄였습니다. |
| 홈 피드 | 1. 클린 코드 원칙의 적용 | AbstractHomePostList 클래스는 DRY 원칙을 적용하여 공통 피드 처리 로직을 중앙화하고, 코드 중복을 최소화합니다. 이 클래스를 활용하여 FindNonAuthPostList와 FindAuthPostList에서 중복되는 로직을 제거하고, 확장성, 다형성, 캡슐화, 책임 분리의 클린 코드 원칙을 따릅니다. 또한, shuffleAndTrimPosts 메소드를 통해 랜덤으로 다양한 콘텐츠를 제공함으로써 사용자 경험을 중심으로 설계되었습니다. |
| 2. 사용자 인증 상태에 따른 맞춤형 피드 제공 | 홈 피드 구현은 사용자의 인증 상태를 고려하여, 인증되지 않은 사용자에게는 기본 게시물 정보를, 인증된 사용자에게는 추가적으로 좋아요 상태 정보가 포함된 피드를 제공합니다. getHomePostList.execute 메소드는 사용자의 인증 상태를 파악하여 적절한 피드 조회 로직을 호출합니다. |
|
| 자신이 올린 게시물 조회 | 커서 기반 무한 스크롤 방식 사용 | 자신이 올린 게시물 조회 기능은 커서 기반의 무한 스크롤 방식을 사용합니다. fetchPosts 메소드는 마지막 게시물 ID와 페이지 크기를 인자로 받아, 특정 ID 이후의 데이터를 조회하는 커서 기반 페이징을 사용합니다. 이 방식은 대량의 데이터가 있는 경우 성능적으로 우수하며, 사용자가 무한 스크롤을 통해 게시물을 계속해서 탐색할 수 있도록 지원합니다. 또한, 파라미터로 size를 받아 한 번에 로드할 게시물의 수를 설정합니다. 클라이언트로부터 제공되는 lastPostId를 사용하여 새로운 컨텐츠를 로드하거나, 제공되지 않는 경우 첫 페이지의 게시물을 조회합니다. |
| 좋아요 기능 | 토글 방식의 좋아요 기능 구현 | 게시물 좋아요 기능의 구현은 사용자가 단일 엔드포인트를 통해 좋아요를 누르고 취소할 수 있도록 토글 방식을 채택합니다. 이 접근법에서, UpdatePostLike 유스케이스는 현재 좋아요상태를 파악하여 적절한 PostLike 인스턴스를 생성하거나 업데이트합니다. 사용자가 이미 좋아요를 누른 게시물에 대해서는 좋아요를 취소하고, 그렇지 않은 경우에는 좋아요를 설정합니다. 이러한 방식은 프론트엔드에서 하나의 API 요청으로 좋아요 상태를 쉽게 관리할 수 있게 해주며, 사용자 경험을 간소화하고 향상시킵니다. 또한, 이 구현 방식은 데이터베이스에 동일한 필드를 반복적으로 업데이트하는 대신, 새로운 좋아요 인스턴스를 생성하고 관리하는 방식을 채택했습니다. |
| 폭죽 사용 | 폭죽 사용 기록 추적 및 instacount 테이블 도입 | 프로젝트 초기 단계에서 폭죽 사용 기록을 추적하여, 사용자가 받은 폭죽을 기준으로 인스타 카운트를 집계하는 방식을 채택했으나, 시스템 개선을 위해 instacount 테이블을 새로이 도입하였습니다. 사용자가 포인트를 사용할 때, UsePoint 유스케이스는 해당 포인트 사용 내역을 PointHistory에 로그성 데이터로 저장합니다. setPostInstaCount.execute를 통해 instacount 테이블에 해당 게시물에 대한 포인트 사용 횟수를 자동으로 업데이트합니다. 이 구현 방식은 로그 데이터(PointHistory)와 핵심 비즈니스 데이터(instacount)를 명확히 분리함으로써 데이터 처리 및 추적의 용이성을 제공합니다. |
| 유저 계정 정보 조회 | 다양한 도메인 의존성 관리 | 유저 계정 정보 조회 기능은 다양한 도메인의 의존성을 가지며, 이를 관리하기 위해 명확한 도메인 중심 전략을 적용했습니다. 이 접근은 Member, InstagramInfo, PostInstaCount 등의 도메인 객체들을 통해 각각의 데이터와 로직을 명확히 분리하고 캡슐화합니다. 예를 들어, FindMemberInfoUsecase에서는 각 기능별로 책임을 분산시킨 메서드들을 통해, 사용자 정보를 계산하고 구성하는 과정을 직관적으로 설계했습니다. |
| 쿠버네티스 환경 배포 | Redis, Spring Project, MariaDB 오케스트레이션 | 카카오 클라우드 인프라인, 크램폴린에서 쿠버네티스(Kubernetes, k8s) 환경에서 Redis, Spring 기반의 백엔드 프로젝트, 그리고 MariaDB를 오케스트레이션했습니다. BE 프로젝트의 환경 변수들은 Config Map을 통해 주입 되어 외부에 드러나지 않도록 관리하였습니다. |
| 섹션 | 상세 내용 | 설명 |
|---|---|---|
| 로그인 | 카카오 OAuh2 사용 로직 구현 | 카카오 OAuth2 Rest API를 사용해 사용자가 카카오를 통해 로그인하고, 조회를 수락하면 클라이언트에서 발급받은 인가코드를 사용해 AccessToken을 받고, 이를 통해 카카오에서 제공해주는 사용자정보를 가져옵니다. |
| 인스타그램 연동 | 인스타그램 OAuh2 사용 로직 구현 | Instagram Graph OAuth2 Rest API를 사용해 사용자가 인스타그램을 통해 로그인하고, 조회를 수락하면 클라이언트에서 발급받은 인가코드를 사용해 AccessToken을 받고, 이를 통해 META API에서 제공해주는 사용자정보를 가져옵니다. |
| 상태관리 | JWT토큰을 사용한 상태관리 구현 | 카카오 로그인 혹은 인스타그램 연동을 할 시 사용자 식별 UID 및 권한을 담은 토큰을 발급하는 기능을 구현하였습니다. |
| 엑세스토큰 및 리프레시토큰 발급 및 관리 | 위에서 말한 JWT토큰 기능을 통해 사용자는 서비스를 이용할 때 엑세스토큰과 리프레시토큰을 발급 받는 기능을 개발하였습니다. 또한 리프레시토큰을 이용해 재발급 하는 과정에서, 빠른 응답을 위해서 Redis를 도입해 빠르게 사용자식별리프레시토큰을 찾아내 엑세스토큰을 재발급하도록 개발하였습니다. |
|
| CORS 설정 | CORS 설정 | SecurityConfig 의 corsConfigurationSource 메소드를 통해 프론트배포URL에서만 특정 정보에 관해서만 API 요청 및 응답이 가능하게 CORS 정책을 설정합니다. |
| 접근권한 | 접근권한 상세 설정 | SecurityConfig 의 securityFilterChain 메소드를 통해 API 별 접근권한을 설정하여, 사용자의 ROLE 별로 사용자가 사용할 수 있는 기능을 허용 및 제한합니다. <권한예시> 권한없음 : 카카오로그인을 하지 않은 사용자 ROLE_BEGINNER : 카카오 로그인만 한 사용자 ROLE_USER : 인스타연동까지 완료한 사용자 |
| 접근 불가 원인에 따른 에러 처리 | FilterResponseUtil 클래스를 통해 접근불가 원인에 따른 다양한 상황에 근거한 에러 응답 처리를 합니다. | |
| 인증 및 인가 | JWT 토큰을 통한 인증 및 인가 구현 | AuthenticationSuccessFilter 클래스는 사용자의 토큰이 Request Header의 Authorization 헤더에 담겨 요청될 시 이를 통해 토큰을 해독하여 올바른 사용자인지, 그렇다면 어떠한 정보를 담고 있는지에 대해 인증성공여부를 판단합니다. |
| 섹션 | 설명 |
|---|---|
| 이슈 정리 | FE와 협업하며 나오는 동시다발적 이슈들을 정리하였습니다. |
| 프로젝트 정리 | 10주간의 프로젝트를 되돌아보며 각 주차별 활동과 이슈, 회의록, 피드백 등을 정리하였습니다. |
| 이미지 파일 | 실제 서비스를 구현하기 위해 아이디어톤 사진들을 데이터로 정리하였습니다. |
| 자신이 올린 게시물 조회 | 유저가 올린 자신의 게시물을 사용자 ID, 마지막 게시물 ID, 페이지 크기를 파라미터로 받아 조회 기능을 구현하였습니다. |
| 유저 계정 정보 조회 | 유저 계정 정보 조회 기능은 다양한 도메인의 의존성을 가지며, 이를 관리하기 위해 명확한 도메인 중심 전략을 적용했습니다. 메인 객체들을 통해 각각의 데이터와 로직을 명확히 분리하고 캡슐화합니다. |
-
고민 및 어려움 : Redis의 SortedSet 자료구조에 PostResponseDTO를 저장하는 것과 Redis의 SortedSet 자료구조에 Post의 Primary Key만을 저장할지에 대한 것을 고민하였습니다. 첫 번째 방식은 인기 게시글 조회 시 필요한 모든 데이터를 Redis에서 한 번에 가져올 수 있는 장점이 있지만, 게시글의 레벨이 올바른지를 Post의 Primary Key를 통해 검증하기 어려운 문제가 있었습니다.
반면, 두 번째 방식은 Redis에서 해당 등수의 Primary Key를 조회한 후, MariaDB에서 해당 Primary Key로 Post를 다시 조회해야 하는 번거로움이 있었지만, 게시글의 레벨을 효과적으로 검증할 수 있는 장점이 있었습니다.
-
결과 : 후자인 Post의 Primary Key를 저장하는 방식을 선택했습니다. 이유는 MariaDB에서 Primary Key를 사용한 조회가 인덱스를 활용하기 때문에 성능상 문제가 없다고 판단했고, 게시글 레벨의 정확한 검증이 가능하다는 점에서 더 효율적이라고 판단했기 때문입니다. 또한, 추후 Spring의 Event를 사용하여 리팩토링 시 Redis의 SortedSet 자료구조를 더 잘 활용할 수 있는 방안이라고 생각하였습니다.
-
만약 MariaDB에 충분한 수의 게시글이 존재하지 않는 경우, 클라이언트의 요구사항 중에서 레벨이 높은 게시물을 우선적으로 조회합니다.
축팅의 인기 게시글 정책은 다음과 같습니다:
- level3 게시물은 1등부터 10등 사이의 게시물들 중에서 선택됩니다.
- level2 게시물은 11등부터 20등 사이의 게시물들 중에서 선택됩니다.
- level1 게시물은 21등부터 30등 사이의 게시물들 중에서 선택됩니다.
- 고민 및 어려움 : 클라이언트의 요구사항을 충족시키기 위해 MariaDB에 저장된 게시글 수와 인기 게시글 정책을 고려해야 했습니다. 이는 각 레벨별 게시물 선택의 기준이 되었으며, 충분한 게시글이 없을 경우의 처리 방안을 마련하는 데 어려움이 있었습니다.
- 해결방안 : MariaDB에 충분한 수의 게시글이 없는 경우, 클라이언트의 요구사항에 따라 레벨이 높은 게시물을 우선적으로 조회하는 방식으로 문제를 해결했습니다.
- 고민 및 어려움 : 멀티 스레드 환경에서 기존의 Random 클래스를 사용하면, 동시에 요청하는 스레드가 많을 경우 스레드 간의 경합이 발생하여 성능 저하가 일어납니다. 이는 동시성을 고려한 안정적인 시스템 설계에 큰 장애가 될 수 있습니다.
- 해결방안 : 멀티 스레드 환경에서의 성능 저하 문제를 해결하기 위해 ThreadLocalRandom 클래스를 도입했습니다. 이 클래스는 각 스레드에 독립적인 난수 생성기를 제공하여, 스레드 간 경합 없이 효율적으로 랜덤 숫자를 생성할 수 있게 함으로써, 전체 시스템의 성능과 안정성을 향상시켰습니다.
- 고민 및 어려움 : 효율적인 단위 테스트를 작성하기 위해서 고민하였습니다.
- 해결 방안 :
updateViewCount,calculatePopularity,updatePopularity메서드의 책임을 명확히 분리함으로써, 코드의 가독성과 유지보수성을 높였습니다. 이를 통해 각 기능의 역할이 명확해졌고, 코드의 이해와 관리가 용이해졌습니다.- 효과적인 단위 테스트 설계:
- 메서드 책임 분리:
updateViewCount,calculatePopularity,updatePopularity메서드의 책임을 명확히 분리함으로써, 코드의 가독성과 유지보수성을 높였습니다. 이를 통해 각 기능의 역할이 명확해졌고, 코드의 이해와 관리가 용이해졌습니다.
- 효과적인 단위 테스트 설계:
- 예상되는 다양한 시나리오에 대해 테스트 케이스를 세심하게 설계함으로써, 게시물 조회수와 인기도 계산 로직을 효과적으로 테스트할 수 있었습니다. 이는 로직의 정확성과 신뢰성을 보장하는 데 중요한 역할을 했습니다.
- POJO 활용:
- **
PostRandomFetcher**와 같은 클래스를 POJO로 설계함으로써, 의존성을 최소화하고 테스트 용이성을 높였습니다. 복잡한 프레임워크나 외부 시스템에 의존하지 않고 순수한 자바 객체의 로직을 검증함으로써, 더 간결하고 효율적인 코드를 구현할 수 있었습니다.
- **
- 메서드 책임 분리:
- 예상되는 다양한 시나리오에 대해 테스트 케이스를 세심하게 설계함으로써, 게시물 조회수와 인기도 계산 로직을 효과적으로 테스트할 수 있었습니다. 이는 로직의 정확성과 신뢰성을 보장하는 데 중요한 역할을 했습니다.
- 고민 및 어려움 : 인기 피드 기능에서 각 레벨별 인기 게시글들을 클라이언트가 요청한 개수에 맞게 랜덤으로 반환하는 과정에서 객체지향적 설계의 장점을 최대한 활용하는 것을 고민하였습니다..
특히, 랜덤으로 선택되는 인덱스들을 효율적으로 생성하고 관리하는 방법을 찾는 것이 어려웠습니다.- **해결 방안 :
RandomIndexes**클래스(일급 컬렉션)를 설계하여 비즈니스에 특화된 불변 자료구조를 통해 상태와 행위를 통합 관리함으로써, 랜덤 인덱스 생성 로직을 내장하여 필요한 인덱스들을 효과적으로 생성 및 관리하고, 이를 통해 객체지향적 설계 원칙을 따르며 비즈니스 로직의 명확성과 효율성을 크게 향상시켰습니다.
- **해결 방안 :
-
Nginx 이미지 제한 문제 해결
- 고민 및 어려움:
크램폴린(Krampoline)의 쿠버네티스(Kubernetes) 환경에서 발생한 nginx 이미지 제한 문제를 해결하기 위해 Ingress Controller 설정과 ConfigMap 수정을 시도했습니다.
그러나 nginx 로그에서 413 에러가 나타나지 않는 것을 보고 문제가 크램폴린의 내부 인프라 설정에서 발생한 것으로 판단했습니다. - 결과:
이 문제를 크램폴린 클라우드 관리자에게 제기하여 해결책을 모색했습니다. 관리자의 도움으로 문제가 해결되었으며, 이 과정에서 Ingress Controller와 ConfigMap 설정을 조정하는 데 필요한 기술적 이해와 문제 해결 능력을 향상시켰습니다.
- 고민 및 어려움:
-
간헐적으로 좋아요가 눌린 상태로 포스트가 오는 문제 해결
- 고민 및 어려움:
배포 후, 좋아요가 눌린 상태로 포스트가 반환되는 문제가 발생했습니다.
처음에는 좋아요 로직의 문제로 판단했으며, 특히 첫 좋아요의 경우 없으면 false를 반환하는 로직에서 문제가 발생했다고 생각했습니다.
이를 해결하기 위해 로그 분석과 디버깅을 시도했습니다. - 결과:
로거를 통해 좋아요 관련 엔드포인트 호출 로그가 없음을 확인했고, 이후 재배포 후 데이터베이스의 상태를 확인했습니다.
그 결과, 데이터베이스가 완전히 초기화되지 않아 좋아요 정보가 이미 저장되어 있었음을 발견했습니다.
이를 통해 문제의 원인을 정확히 파악하고, 쿠버네티스 환경에서 데이터베이스를 삭제하여 문제를 성공적으로 해결했습니다.
- 고민 및 어려움:
-
피드 조회 추상화 클래스를 통한 문제 해결
- 고민 및 어려움:
프론트엔드에서 사용자의 로그인 여부에 따라 다른 데이터를 보여주는 요청이 왔을 때, 사용자가 로그인했는지 여부에 따라 다른 결과를 반환하는 것이 필요했습니다.
이 경우, 반환 값이 달라지므로 구현이 복잡해질 수 있었습니다. 이를 해결하기 위해 추상화 클래스를 활용한 구현 방법을 고민했습니다. - 해결 방안:
PostFetchResponse라는 피드 조회 공통 클래스를 구현했습니다.
이 클래스는 홈피드와 마이피드 등 다양한 피드 조회 기능에 사용되는 공통 구조를 정의하며, 코드 중복을 줄이는 데 도움을 주었습니다.
또한, AbstractHomePostList 클래스를 통해 DRY(Don't Repeat Yourself) 원칙을 적용, 공통 피드 처리 로직을 중앙화하고 코드 중복을 최소화했습니다.
이를 통해 확장성, 다형성, 캡슐화, 책임 분리의 클린 코드 원칙을 준수할 수 있었습니다.
shuffleAndTrimPosts 메소드를 활용하여 랜덤하게 다양한 콘텐츠를 제공함으로써 사용자 경험을 향상시켰습니다. - 맞춤형 피드 제공:
FindNonAuthPostList와 FindAuthPostList 클래스를 통해 사용자 인증 상태에 따른 맞춤형 피드를 제공했습니다.
getHomePostList.execute 메소드를 활용해 사용자의 인증 상태에 따라 적절한 피드 조회 로직을 호출했으며, 인증되지 않은 사용자에게는 기본 게시물 정보를, 인증된 사용자에게는 좋아요 상태 정보가 포함된 피드를 제공함으로써 사용자 요구에 부응하는 솔루션을 제공했습니다.
- 고민 및 어려움:
-
외부 API 통합의 결정
- 문제 인식:
프로젝트에서 카카오 로그인과 인스타그램 연동 기능을 구현하면서 외부 API 통합에 대한 중요한 결정이 필요했습니다. 초기에는 OAuth2Client 라이브러리를 사용하는 방식을 고려했지만, 이 방식에서 프록시 설정의 복잡성과 제한적인 컨트롤이 문제로 드러났습니다. - 전략 변경:
이에 따라 REST API 기반으로 개발 전략을 전환하기로 결정했습니다. 이 방식은 OAuth2 인증 프로세스(인가코드, 엑세스토큰, 사용자 정보 추출)를 더 세밀하게 제어할 수 있게 해주어, 보안과 효율성을 두루 증진시켰습니다.
- 문제 인식:
-
토큰 관리의 개선
- 보안 문제 인식:
리프레시토큰을 활용한 엑세스토큰 재발급 방식에서 보안상의 취약점을 발견했습니다.
처음에는 리프레시토큰을 요청헤더에 포함시키는 방안을 고려했으나, 이는 보안상의 리스크가 될 수 있다는 것을 깨달았습니다. - 보안성 강화:
이를 해결하기 위해 엑세스토큰을 클라이언트의 로컬 스토리지에 저장하고, 리프레시토큰은 HttpOnly 쿠키에 저장하는 방식으로 전환했습니다.
이 변경으로 토큰을 더욱 안전하게 관리하고 사용할 수 있게 되었습니다.
- 보안 문제 인식:
-
프록시 설정의 최적화
- 고민:
프로젝트 초기에 전체 RestTemplate의 수정이 필요했던 상황에서, 이를 개선하기 위해 프록시 설정에 대한 새로운 접근법을 모색했습니다. - 해결책:
멘토의 조언을 받아, 프록시 설정을 위한 전용 proxyRestTemplate을 별도로 Bean으로 등록하는 방식을 채택했습니다.
이 접근법은 기존 코드의 큰 변경 없이도 프록시 설정을 관리할 수 있게 하여, 시스템의 유연성과 확장성을 크게 개선했습니다.
- 고민:
-
성능 최적화를 위한 Redis 도입
- 성능 고려:
리프레시토큰을 통한 엑세스 토큰 재발급 과정에서 성능 향상을 위해 Redis의 도입을 고려했습니다.
특히, 토큰 재발급 과정에서의 응답 속도가 큰 관심사였습니다. - Redis의 효과:
Redis를 활용하여 리프레시토큰과 관련된 사용자 정보를 빠르게 처리할 수 있게 되었습니다.
Redis에 리프레시토큰과 사용자 정보를 Key-Value 쌍으로 저장함으로써, 데이터베이스 조회 시간을 대폭 줄일 수 있었고, 이는 시스템 전반의 응답성을 크게 개선하는 결과를 가져왔습니다.
- 성능 고려:
- 기능 개발 이해도 부족
- 고민 및 어려움: 프로젝트를 시작하면서 초기에는 기능 개발에 대한 충분한 이해가 부족한 상태에서 진행되었습니다.
특히, 개발 구조에 대한 미숙함, 개발 범위와 업무 분담에 대한 명확한 이해가 부족하여 진전이 더딘 상황이었습니다. - 결과: 전반적인 플로우에 대한 공통된 이해를 형성하기 위해 테크리더와의 미팅을 진행하였습니다. 기능을 개발하는 과정에서 페어프로그래밍을 적극적으로 도입하여 실시간 소통과 지식 공유를 강화하면서 코드 품질을 향상시켰습니다. 이후 부가적인 기능들을 중점적으로 담당함으로써 업무의 효율성을 높일 수 있었습니다.
- 고민 및 어려움: 프로젝트를 시작하면서 초기에는 기능 개발에 대한 충분한 이해가 부족한 상태에서 진행되었습니다.