![]()
Cache conscious hash map and hash set for strings based on the "Cache-conscious collision resolution in string hash tables." (Askitis Nikolas and Justin Zobel, 2005) paper. You can find some details regarding the structure here.
Thanks to its cache friendliness, the structure provides fast lookups while keeping a low memory usage. The main drawback is the rehash process which is a bit slow and need some spare memory to copy the strings from the old hash table to the new hash table (it can’t use std::move as the other hash tables using std::string as key).
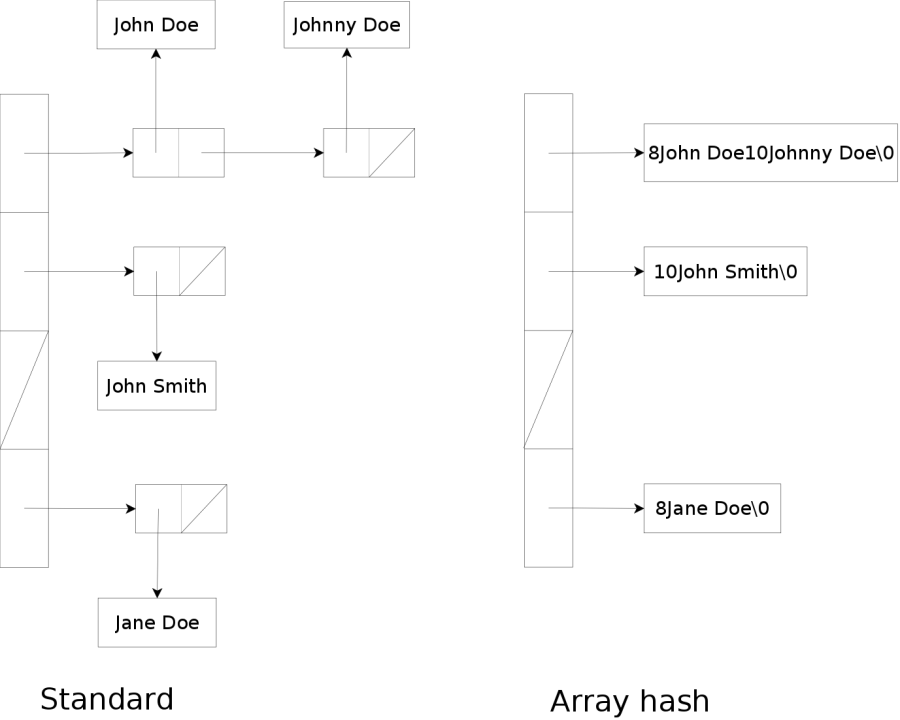
Four classes are provided: tsl::array_map, tsl::array_set, tsl::array_pg_map and tsl::array_pg_set. The first two are faster and use a power of two growth policy, the last two use a prime growth policy instead and are able to cope better with a poor hash function. Use the prime version if there is a chance of repeating patterns in the lower bits of your hash (e.g. you are storing pointers with an identity hash function). See GrowthPolicy for details.
A benchmark of tsl::array_map against other hash maps can be found here. This page also gives some advices on which hash table structure you should try for your use case (useful if you are a bit lost with the multiple hash tables implementations in the tsl namespace). You can also find another benchmark on the tsl::hat-trie page.
- Header-only library, just add the include directory to your include path and you are ready to go. If you use CMake, you can also use the
tsl::array_hashexported target from the CMakeLists.txt. - Low memory usage with good performances, see the benchmark for some numbers.
- Support for move-only and non-default constructible values.
- Strings with null characters inside them are supported (you can thus store binary data as key).
- If the hash is known before a lookup, it is possible to pass it as parameter to speed-up the lookup (see
precalculated_hashparameter in API). - Support for efficient serialization and deserialization (see example and the
serialize/deserializemethods in the API for details). - By default the maximum allowed size for a key is set to 65 535. This can be raised through the
KeySizeTtemplate parameter (see API for details). - By default the maximum size of the map is limited to 4 294 967 296 elements. This can be raised through the
IndexSizeTtemplate parameter (see API for details).
tsl::array_map tries to have an interface similar to std::unordered_map, but some differences exist:
- Iterator invalidation doesn't behave in the same way, any operation modifying the hash table invalidate them (see API for details).
- References and pointers to keys or values in the map are invalidated in the same way as iterators to these keys-values.
- Erase operations have an amortized runtime complexity of O(1) for
tsl::array_map. An erase operation will delete the key immediately but for the value part of the map, the deletion may be delayed. The destructor of the value is only called when the ratio between the size of the map and the size of the map + the number of deleted values still stored is low enough. The methodshrink_to_fitmay be called to force the deletion. - The key and the value are stored separately and not in a
std::pair<const Key, T>. Methods likeinsertoremplacetake the key and the value separately instead of astd::pair. The insert method looks likestd::pair<iterator, bool> insert(const CharT* key, const T& value)instead ofstd::pair<iterator, bool> insert(const std::pair<const Key, T>& value)(see API for details). - For iterators,
operator*()andoperator->()return a reference and a pointer to the valueTinstead ofstd::pair<const Key, T>. For an access to the key string, thekey()(which returns aconst CharT*) orkey_sv()(which returns astd::basic_string_view<CharT>) method of the iterator must be called. - No support for some bucket related methods (like
bucket_size,bucket, ...).
These differences also apply between std::unordered_set and tsl::array_set.
Thread-safety and exception guarantees are similar to the STL containers.
The default hash function used by the structure depends on the presence of std::string_view. If it is available, std::hash<std::string_view> is used, otherwise a simple FNV-1a hash function is used to avoid any dependency.
If you can't use C++17 or later, we recommend to replace the hash function with something like CityHash, MurmurHash, FarmHash, ... for better performances. On the tests we did, CityHash64 offers a ~40% improvement on reads compared to FNV-1a.
#include <city.h>
struct str_hash {
std::size_t operator()(const char* key, std::size_t key_size) const {
return CityHash64(key, key_size);
}
};
tsl::array_map<char, int, str_hash> map;The std::hash<std::string> can't be used efficiently as the structure doesn't store any std::string object. Any time a hash would be needed, a temporary std::string would have to be created.
The library supports multiple growth policies through the GrowthPolicy template parameter. Three policies are provided by the library but you can easily implement your own if needed.
- tsl::ah::power_of_two_growth_policy. Default policy used by
tsl::array_map/set. This policy keeps the size of the bucket array of the hash table to a power of two. This constraint allows the policy to avoid the usage of the slow modulo operation to map a hash to a bucket, instead ofhash % 2n, it useshash & (2n - 1)(see fast modulo). Fast but this may cause a lot of collisions with a poor hash function as the modulo with a power of two only masks the most significant bits in the end. - tsl::ah::prime_growth_policy. Default policy used by
tsl::array_pg_map/set. The policy keeps the size of the bucket array of the hash table to a prime number. When mapping a hash to a bucket, using a prime number as modulo will result in a better distribution of the hash across the buckets even with a poor hash function. To allow the compiler to optimize the modulo operation, the policy use a lookup table with constant primes modulos (see API for details). Slower thantsl::ah::power_of_two_growth_policybut more secure. - tsl::ah::mod_growth_policy. The policy grows the map by a customizable growth factor passed in parameter. It then just use the modulo operator to map a hash to a bucket. Slower but more flexible.
To implement your own policy, you have to implement the following interface.
struct custom_policy {
// Called on hash table construction and rehash, min_bucket_count_in_out is the minimum buckets
// that the hash table needs. The policy can change it to a higher number of buckets if needed
// and the hash table will use this value as bucket count. If 0 bucket is asked, then the value
// must stay at 0.
explicit custom_policy(std::size_t& min_bucket_count_in_out);
// Return the bucket [0, bucket_count()) to which the hash belongs.
// If bucket_count() is 0, it must always return 0.
std::size_t bucket_for_hash(std::size_t hash) const noexcept;
// Return the number of buckets that should be used on next growth
std::size_t next_bucket_count() const;
// Maximum number of buckets supported by the policy
std::size_t max_bucket_count() const;
// Reset the growth policy as if the policy was created with a bucket count of 0.
// After a clear, the policy must always return 0 when bucket_for_hash() is called.
void clear() noexcept;
}To use the library, just add the include directory to your include path. It is a header-only library.
If you use CMake, you can also use the tsl::array_hash exported target from the CMakeLists.txt with target_link_libraries.
# Example where the array-hash project is stored in a third-party directory
add_subdirectory(third-party/array-hash)
target_link_libraries(your_target PRIVATE tsl::array_hash) If the project has been installed through make install, you can also use find_package(tsl-array-hash REQUIRED) instead of add_subdirectory.
The code should work with any C++11 standard-compliant compiler and has been tested with GCC 4.8.4, Clang 3.5.0 and Visual Studio 2015.
To run the tests you will need the Boost Test library and CMake.
git clone https://github.com/Tessil/array-hash.git
cd array-hash/tests
mkdir build
cd build
cmake ..
cmake --build .
./tsl_array_hash_testsThe API can be found here. If std::string_view is available, the API changes slightly and can be found here.
#include <iostream>
#include <tsl/array_map.h>
#include <tsl/array_set.h>
int main() {
// Map of const char* to int
tsl::array_map<char, int> map = {{"one", 1}, {"two", 2}};
map["three"] = 3;
map["four"] = 4;
map.insert("five", 5);
map.insert_ks("six_with_extra_chars_we_ignore", 3, 6);
map.erase("two");
// When template parameter StoreNullTerminator is true (default) and there is no
// null character in the strings.
for(auto it = map.begin(); it != map.end(); ++it) {
std::cout << "{" << it.key() << ", " << it.value() << "}" << std::endl;
}
// If StoreNullTerminator is false for space efficiency or you are storing null characters,
// you can access to the size of the key.
for(auto it = map.begin(); it != map.end(); ++it) {
(std::cout << "{").write(it.key(), it.key_size()) << ", " << it.value() << "}" << std::endl;
}
// Better, use key_sv() if you compiler provides access to std::string_view.
for(auto it = map.begin(); it != map.end(); ++it) {
std::cout << "{" << it.key_sv() << ", " << it.value() << "}" << std::endl;
}
// Or if you just want the values.
for(int value: map) {
std::cout << "{" << value << "}" << std::endl;
}
// Map of const char32_t* to int
tsl::array_map<char32_t, int> map_char32 = {{U"one", 1}, {U"two", 2}};
map_char32[U"three"] = 3;
// Set of const char*
tsl::array_set<char> set = {"one", "two", "three"};
set.insert({"four", "five"});
for(auto it = set.begin(); it != set.end(); ++it) {
std::cout << "{" << it.key() << "}" << std::endl;
}
}The library provides an efficient way to serialize and deserialize a map or a set so that it can be saved to a file or send through the network. To do so, it requires the user to provide a function object for both serialization and deserialization.
struct serializer {
// Must support the following types for U: std::uint64_t, float and T if a map is used.
template<typename U>
void operator()(const U& value);
void operator()(const CharT* value, std::size_t value_size);
};struct deserializer {
// Must support the following types for U: std::uint64_t, float and T if a map is used.
template<typename U>
U operator()();
void operator()(CharT* value_out, std::size_t value_size);
};Note that the implementation leaves binary compatibility (endianness, float binary representation, size of int, ...) of the types it serializes/deserializes in the hands of the provided function objects if compatibility is required.
More details regarding the serialize and deserialize methods can be found in the API.
#include <cassert>
#include <cstdint>
#include <fstream>
#include <type_traits>
#include <tsl/array_map.h>
class serializer {
public:
serializer(const char* file_name) {
m_ostream.exceptions(m_ostream.badbit | m_ostream.failbit);
m_ostream.open(file_name);
}
template<class T,
typename std::enable_if<std::is_arithmetic<T>::value>::type* = nullptr>
void operator()(const T& value) {
m_ostream.write(reinterpret_cast<const char*>(&value), sizeof(T));
}
void operator()(const char32_t* value, std::size_t value_size) {
m_ostream.write(reinterpret_cast<const char*>(value), value_size*sizeof(char32_t));
}
private:
std::ofstream m_ostream;
};
class deserializer {
public:
deserializer(const char* file_name) {
m_istream.exceptions(m_istream.badbit | m_istream.failbit | m_istream.eofbit);
m_istream.open(file_name);
}
template<class T,
typename std::enable_if<std::is_arithmetic<T>::value>::type* = nullptr>
T operator()() {
T value;
m_istream.read(reinterpret_cast<char*>(&value), sizeof(T));
return value;
}
void operator()(char32_t* value_out, std::size_t value_size) {
m_istream.read(reinterpret_cast<char*>(value_out), value_size*sizeof(char32_t));
}
private:
std::ifstream m_istream;
};
int main() {
const tsl::array_map<char32_t, std::int64_t> map = {{U"one", 1}, {U"two", 2},
{U"three", 3}, {U"four", 4}};
const char* file_name = "array_map.data";
{
serializer serial(file_name);
map.serialize(serial);
}
{
deserializer dserial(file_name);
auto map_deserialized = tsl::array_map<char32_t, std::int64_t>::deserialize(dserial);
assert(map == map_deserialized);
}
{
deserializer dserial(file_name);
/**
* If the serialized and deserialized map are hash compatibles (see conditions in API),
* setting the argument to true speed-up the deserialization process as we don't have
* to recalculate the hash of each key. We also know how much space each bucket needs.
*/
const bool hash_compatible = true;
auto map_deserialized =
tsl::array_map<char32_t, std::int64_t>::deserialize(dserial, hash_compatible);
assert(map == map_deserialized);
}
}It's possible to use a serialization library to avoid some of the boilerplate if the types to serialize are more complex.
The following example uses Boost Serialization with the Boost zlib compression stream to reduce the size of the resulting serialized file.
#include <boost/archive/binary_iarchive.hpp>
#include <boost/archive/binary_oarchive.hpp>
#include <boost/iostreams/filter/zlib.hpp>
#include <boost/iostreams/filtering_stream.hpp>
#include <boost/serialization/split_free.hpp>
#include <boost/serialization/utility.hpp>
#include <cassert>
#include <cstdint>
#include <fstream>
#include <tsl/array_map.h>
template<typename Archive>
struct serializer {
Archive& ar;
template<typename T>
void operator()(const T& val) { ar & val; }
template<typename CharT>
void operator()(const CharT* val, std::size_t val_size) {
ar.save_binary(reinterpret_cast<const void*>(val), val_size*sizeof(CharT));
}
};
template<typename Archive>
struct deserializer {
Archive& ar;
template<typename T>
T operator()() { T val; ar & val; return val; }
template<typename CharT>
void operator()(CharT* val_out, std::size_t val_size) {
ar.load_binary(reinterpret_cast<void*>(val_out), val_size*sizeof(CharT));
}
};
namespace boost { namespace serialization {
template<class Archive, class CharT, class T>
void serialize(Archive & ar, tsl::array_map<CharT, T>& map, const unsigned int version) {
split_free(ar, map, version);
}
template<class Archive, class CharT, class T>
void save(Archive & ar, const tsl::array_map<CharT, T>& map, const unsigned int version) {
serializer<Archive> serial{ar};
map.serialize(serial);
}
template<class Archive, class CharT, class T>
void load(Archive & ar, tsl::array_map<CharT, T>& map, const unsigned int version) {
deserializer<Archive> deserial{ar};
map = tsl::array_map<CharT, T>::deserialize(deserial);
}
}}
int main() {
const tsl::array_map<char32_t, std::int64_t> map = {{U"one", 1}, {U"two", 2},
{U"three", 3}, {U"four", 4}};
const char* file_name = "array_map.data";
{
std::ofstream ofs;
ofs.exceptions(ofs.badbit | ofs.failbit);
ofs.open(file_name, std::ios::binary);
boost::iostreams::filtering_ostream fo;
fo.push(boost::iostreams::zlib_compressor());
fo.push(ofs);
boost::archive::binary_oarchive oa(fo);
oa << map;
}
{
std::ifstream ifs;
ifs.exceptions(ifs.badbit | ifs.failbit | ifs.eofbit);
ifs.open(file_name, std::ios::binary);
boost::iostreams::filtering_istream fi;
fi.push(boost::iostreams::zlib_decompressor());
fi.push(ifs);
boost::archive::binary_iarchive ia(fi);
tsl::array_map<char32_t, std::int64_t> map_deserialized;
ia >> map_deserialized;
assert(map == map_deserialized);
}
}The code is licensed under the MIT license, see the LICENSE file for details.