SubdomainFinder is a tool for collecting subdomains. It increases the range of information gathering during the penetration test.
The reason for writing this tool is that my computer can't use Sublist3r, I don't want to spend time configuring the environment for it.
Also, since I don't know enough about multithreading now, I didn't add the part of the brute subdomain, I believe I will add it in later versions.
When collecting the netcraft part, refer to Sublist3r. The rest is written by myself.
Auth: Threezh1
Blog: http://www.threezh1.com/
-
Python Version: 3.7
-
Dependencies:
pip3 install -r requirements.txt -
Channels for collecting subdomains:
crt, dnsdumpster, threatcrowd, virustotal, natcraft, google transparencyreport, ask, baidu, bing, so, google -
Have to be aware of is:
- Please make sure the network can access websites such as google
- A single part may report an error, but does not affect the overall use.
- If an error occurs, please wait a while and try again
-
Problems at the current stage:
- When the number of subdomains is very large, the program may have to wait for a long time and get stuck with a small probability.
- Some channels will be invalid due to network factors
- The speed of collection is not particularly fast
PS:In the windows, it is recommended to run with cmder.
usage: SubdomainFinder.py [-h] -d DOMAIN [-o] [-html]
| Short Form | Long Form | Description |
|---|---|---|
| -h | --help | show this help message and exit |
| -d | --domain | Domain name to enumerate subdomains of |
| -o | --output | Output file name ,the domain name is thefile_name.txt |
| -html | --html | Output html, the domain name is the file_name.html |
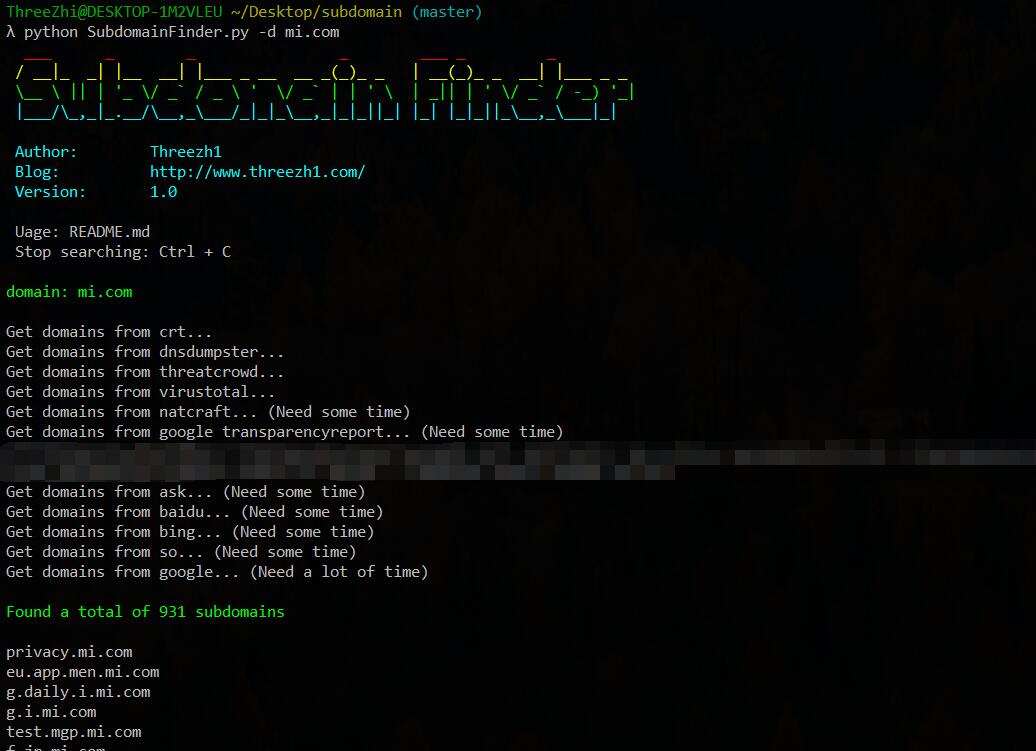
- Simple:
python3 SubdomainFinder.py -d mi.com
- Output to txt:
The output is a txt file, the default name is mi_com.txt
python3 SubdomainFinder.py -d mi.com -o
- Output to html:
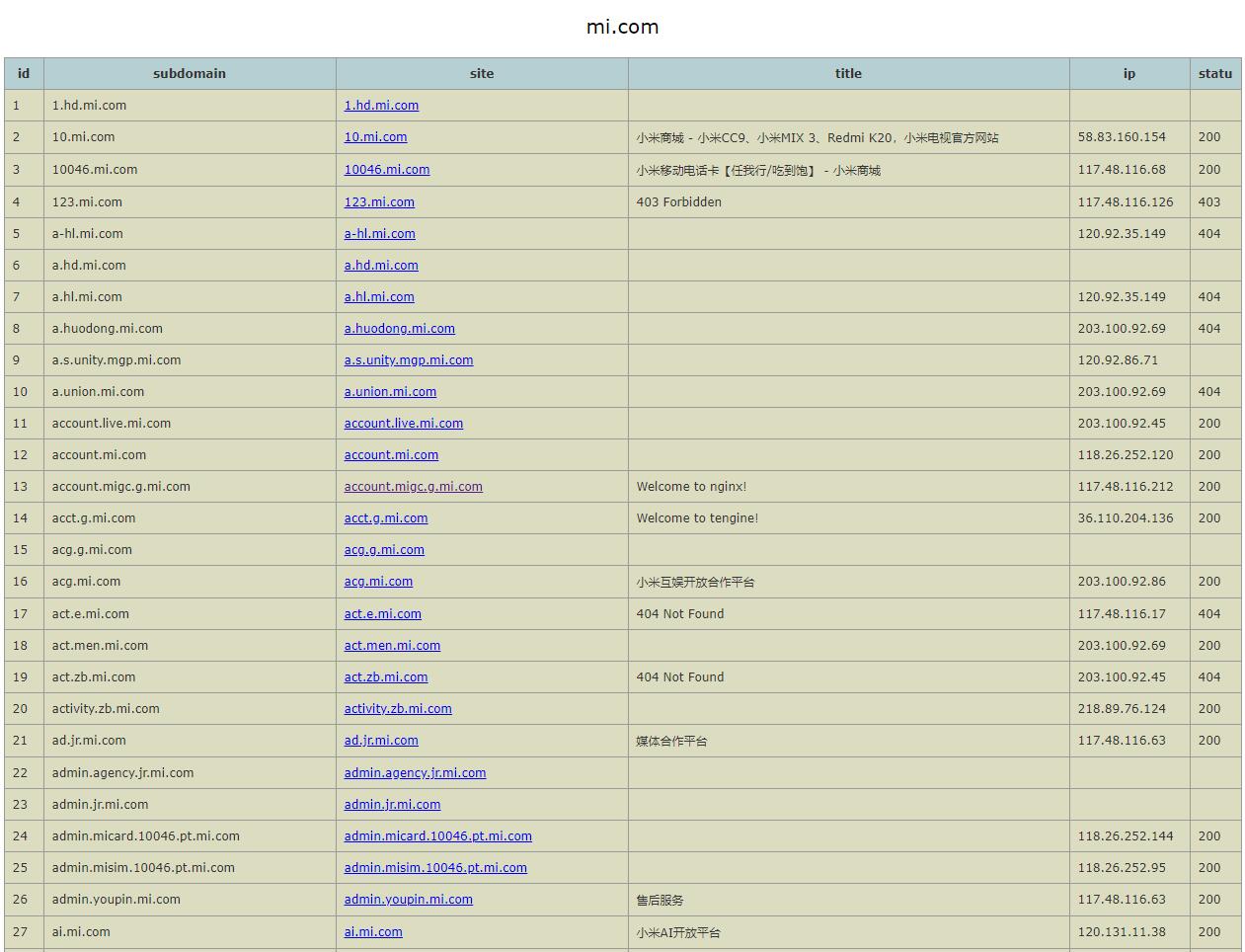
python3 SubdomainFinder.py -d mi.com -html
Get more information about the subdomain, including the page title, ip address, website status, and output it as an html file. The default name is mi_com.html