multi-chain bottom-up consensus model prototype #2457
Comments
|
The idea of merging shares some similarities as the GHS MST algorithm. But unlike the GHS algorithm, bottom-up consensus needs to work in a dynamic environment (multichain is always changing) and also under churn, so that is a challenge. |
|
Please read some related work:
My advise would be to do a boring incremental steps approach, learn what you need to solve :
|
|
Currently the closest related work to Delft blockchain (MultiChain,TruchtChain): "THE SWIRLDS HASHGRAPH CONSENSUS ALGORITHM: FAIR, FAST, BYZANTINE FAULT TOLERANCE" It is also graph-based, instead of a single chain. They provide an amazing polished description of the idea we call "offline voting", they describe as gossip-about-gossip. Their patented technology uses a graph-based blockchain and mentions a HashDAG. Uses proof-of-stake and single-party signed messages. Corda is also transaction focussed. However, they lack a gossip mechanism. Transactions are listed on a chain, but stored in "vaults": http://r3cev.com/s/corda-introductory-whitepaper-final.pdf |
|
Brainstorm outcome, detailing the three algorithm phases per round:
Using a commitment scheme we can generate guesses, winner becomes temporary elected leader for coordinating group consensus. Drawback: we don't like leader dependancies, DDoS vunerabilities, and failure/resume problems. Kelong: proof-of-luck |

|
Just came across this consensus algorithm, might be interesting to read: https://www.stellar.org/papers/stellar-consensus-protocol.pdf |
|
The main disadvantage, also mentioned in the paper, is that the quorum intersection cannot only contain faulty nodes. This requirement depends on the assumption that the individual nodes to choose good quorum slices. In the application of Stellar it is reasonable, because nodes represent banks or other organisations. But the same isn't true for Tribler. Nevertheless, the idea of Federated Byzantine Agreement is very interesting. |
|
I will spend some time on this in the coming months. |
|
I'm currently writing up my idea, expect something by the end of the week. |
|
First write-up by Kelong: bottom-up.pdf |
|
Updated my write-up with some negative results and my reasoning, see "2.5.1. Merging consensus groups does not guarantee BFT with a probability of 1" |
|
Create a repository for my thesis work, which contains the pdf. It'll be a bit unstructured in the beginning, just me writing ideas and results down. Hopefully it'll converge into a proper thesis by summer. New section since last time - "2.5.2 Tail bounding the number of Byzantine nodes in a consensus group" |
|
Some remarks:
|
|
@pimotte thanks for the remarks
|
|
Ideas:
|
|
I can't take all the credit, a lot of it resulted from the fruitful discussions with Zhejie. |
|
Consensus Protocol.pdf |
|
Starting reading the PDF. In the Transaction Block, I'm assuming it should also have a number of outputs (probably 2). I'm thinking in terms of Bitcoin where one of the output is "spare change" which the sender can re-use later. |
|
The spare change are used so that the receiver of a transaction doesn't need to track all the way back to the root to make sure if the sender has enough for this transaction. In this sense, we should to add this spare change for the sake of simplicity and storage requirement. However, we still need the track to the root for the validation. |
|
Yeah, we need to traverse to the root to validate a Tx regardless of spare change. But I was just thinking it'll be useful to freely set the transaction amount. For example if I only have 1 unit from 1 source, but I want to send 0.1 unit, then I can set 0.9 as UTXO (the spare change) and 0.1 as the actual output. |
|
I see what you mean. Yes we should do that as well. It will eventually save the storage. |
|
Just spoke to @synctext. He suggested that we should focus on something that's more generic. Probably no Bitcoin style transaction, just arbitrary data in the block (at least for my thesis). I guess we need to re-think the validation protocol in this case. My initial feel is that there will be more overhead in the validation protocol. |
|
The validation protocol I think can be done using a BFS or DFS. On every step check that the checkpoints that surrounds the node (transaction) is in some consensus result and the node is not a fork of previously traversed nodes. We can prune branches if they've been validated previously. This should guarantee validity, still thinking about a way to prove it. |
|
idea by Pim. Keep the scalability, use checkpoints. Prove that you have a time-bounded worst case detection time of double spend, if a certain fraction of network is non-malicious. |
|
as a harmed party you can detect a double spend by agents you interacted with. Just check once after doing a transaction if it made it into the consensus, as reported by your counterparty |
|
Made a lot of changes since last time - pdf. Defined a few things formally, i.e. the basic mode, what is a fork, etc. The consensus part should work if we assume the 2n/3 promoters (the nodes that execute the consensus algorithm) are honest. I also provide some proof sketch. OTOH a lot of it will change if we use an invitation system. Personally I'm not a fan because that's using humans as a part of the protocol so it won't be possible to prove useful results. Unless the invitation is based on some of reputation score. I also wrote down a few things about fraud detection. Basically it's quite simple to detect fork (the way I defined it) if one of the party in the transaction is honest. The hard part is to detect fork when both parties are malicious. The more forks there are, the harder it is to detect them all. |
|
Implemented a simplified version (no erasure coding, no threshold signatures) of HoneybadgerBFT using Twisted - code is here. The algorithm described in the papers are of synchronous (blocking) style, so they don't fit nicely with the asynchronous (event loop + futures/promises) style in Twisted. So the algorithms are implemented using state machines. Every time a message comes in, I call a |
|
As of 1336bb5, true halves and compact blocks are implemented. Initial experiments show better results than 6 days ago. That is higher (verified) transaction rate and the graph looks a bit more reasonable.
|


|
A lot of performance performances improvements were merged these couple of weeks, the most notable one is changing serialisation library from jsonpickle to protobuf (PR). I'm pleased to say the performance results improved significantly, previously we were just below 1000 tx/s, with the new code it can reach 5000 tx/s. Here is the same graph but with new code.
|


|
@kc1212 If you are still unhappy with performance, you can make protobuf another 12-20 times faster by using the C++ backend: os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION"] = "cpp"
os.environ["PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION_VERSION"] = "2"
import google.protobufOfficial doc: https://developers.google.com/protocol-buffers/docs/reference/python-generated |
|
@qstokkink Thanks for the suggestion, 12-20 times faster is hard to ignore. The document mentioned that "environment variable needs to be set before installing the protobuf library", is the protobuf on the TUD DAS5 a bit different from what you get by simply |
|
@kc1212 tl;dr Yes, that should work just fine on the DAS5. (I have a manual build script here for CentOS, but I think it is obsolete now) |
This work provides the scalable blockchain fabric. Our efficient consensus mechanism is generic and does not pose any restrictions on the Sybil defense mechanism. Within our architecture you can select a proof-of-work, proof-of-stake or our own preferred trust-based approach. ToDo:
|
|
My current model is fairly loose and fails to capture state transitions. I'm considering to model my system using Canetti's technique described in Universally Composable Security, if I can digest it. This appears to be the technique used in The Bitcoin Backbone Protocol and Hybrid Consensus. |
Current results : |

|
Related work from Sydney Consensus_Red_Belly_Blockchain.pdf, great blockchain course slides (including Red-Bellied blockchain): http://poseidon.it.usyd.edu.au/~gramoli/largescalenetworks/lectures/10-blockchains.pdf Fast byzantine consensus: https://www.cs.utexas.edu/~lorenzo/papers/Martin06Fast.pdf |
|
Solid progress: mathematical proof that transaction rate now scales linear with participants!
|

|
|

|
@kc1212 very related work, also quite new (credits for @synctext for finding this one): http://poseidon.it.usyd.edu.au/~concurrentsystems/doc/ConsensusRedBellyBlockchain.pdf |
|
I was unable to verify the claims in the "Red-Bellied blockchain" work. Especially the 250k transaction throughput for "CGLR" and "Boosted-MMR". I couldn't find any information on these keywords, the document also did not provide any reference. |
|
Title: Can the mathematical proof of linear scalability also be given without a global consistent reliable broadcast? How about diminishing return factors? Can a gossip-based approach also yield the same guaranteed performance and scale? It can be assumed that we have a 2D network model where nodes are aware of their lowest latency neighbors. DDoS and spam vulnerability analysis/considerations? Thesis: "Our consensus protocol runs on top of Extended TrustChain." More like: our key difference from related work is the independence of our transaction validation. Prior systems such a Bitcoin and Ethereum entangled the consensus algorithm with the transaction validation, restricting performance. By splitting this functionality we achieved mathematically proven horizontal scalability for the first time. typo: Attempt matters like: no-forks-possible proof ? Another proof? protocol will always terminate for any finite-sized input. (with minimal time assumptions) 4.2.4 Global "linear" throughput "then the network cannot keep up with the large number of fragments". Our default cautious policy is to download all their new blocks since the last checkpoint before transacting with a stranger. This causes a bottleneck which could be avoided if encounters are predictable and pre-fetching is employed. we dedicate this chapter on comparing our results with related work == What is the name of the thing your did in your thesis? |
|
@kc1212 is your 10k+ transaction graph with fixed or random neighbors? |
|
Fixed neighbours
…On 20 July 2017 10:39:05 CEST, Martijn de Vos ***@***.***> wrote:
@kc1212 is your 10k+ transaction graph with fixed or random neighbors?
--
You are receiving this because you were mentioned.
Reply to this email directly or view it on GitHub:
#2457 (comment)
--
Sent from my Android device with K-9 Mail. Please excuse my brevity.
|
|
@kc1212 thanks! I expected that already. You probably don't have time to do this but I was thinking, maybe it's helpful to make an interaction model (i.e. based on interactions in the Bitcoin or Ethereum blockchain) and run your consensus algorithm on top of that. This closely resembles real-world transactions. |
|
Fast AUS blockchain: http://poseidon.it.usyd.edu.au/~concurrentsystems/rbbc/Benchmark.html |
|
A 9-page paper version of my thesis is available: The thesis also went through many polishing rounds, it can be found at the usual place: |
|
The source code for 10k transactions per second: https://github.com/kc1212/checo |
|
Had a look at the new PARSEC Algorithm? https://github.com/maidsafe/rfcs/blob/master/text/0049-parsec/0049-parsec.md |
|
PARSEC Algorithm is certainly interesting, thnx! |
|
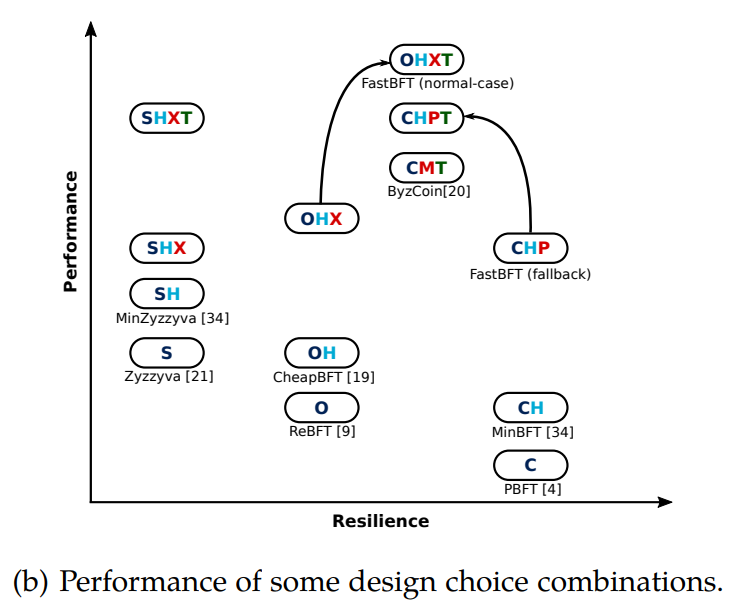
Excellent related BFT work overview, Scalable Byzantine Consensus via Hardware-assisted Secret Sharing |
|
This thesis finished successfully: https://repository.tudelft.nl/islandora/object/uuid%3A86b2d4d8-642e-4d0f-8fc7-d7a2e331e0e9 |
Research superior consensus models, resilient against 51% attacks.
Create an operational prototype of a mechanisms which spreads the last known record of all multi-chain.
The text was updated successfully, but these errors were encountered: