This repo contains code for our CVPR 2021 paper.
Abstract Spatial-Temporal Reasoning via Probabilistic Abduction and Execution
Chi Zhang*, Baoxiong Jia*, Song-Chun Zhu, Yixin Zhu
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
(* indicates equal contribution.)
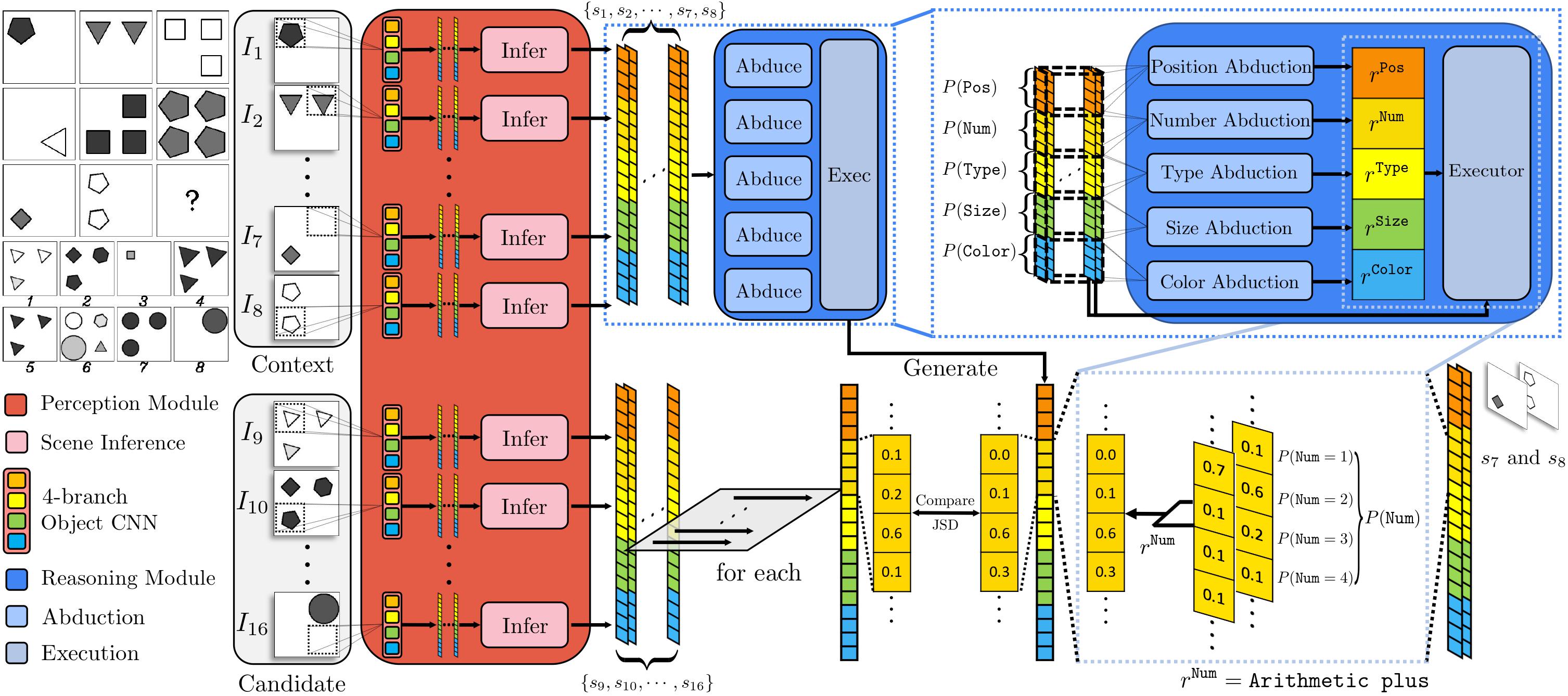
Spatial-temporal reasoning is a challenging task in Artificial Intelligence (AI) due to its demanding but unique nature: a theoretic requirement on representing and reasoning based on spatial-temporal knowledge in mind, and an applied requirement on a high-level cognitive system capable of navigating and acting in space and time. Recent works have focused on an abstract reasoning task of this kind -- Raven’s Progressive Matrices (RPM). Despite the encouraging progress on RPM that achieves human-level performance in terms of accuracy, modern approaches have neither a treatment of human-like reasoning on generalization, nor a potential to generate answers. To fill in this gap, we propose a neuro-symbolic Probabilistic Abduction and Execution (PrAE) learner; central to the PrAE learner is the process of probabilistic abduction and execution on a probabilistic scene representation, akin to the mental manipulation of objects. Specifically, we disentangle perception and reasoning from a monolithic model. The neural visual perception frontend predicts objects' attributes, later aggregated by a scene inference engine to produce a probabilistic scene representation. In the symbolic logical reasoning backend, the PrAE learner uses the representation to abduce the hidden rules. An answer is predicted by executing the rules on the probabilistic representation. The entire system is trained end-to-end in an analysis-by-synthesis manner without any visual attribute annotations. Extensive experiments demonstrate that the PrAE learner improves cross-configuration generalization and is capable of rendering an answer, in contrast to prior works that merely make a categorical choice from candidates.
The following table shows the performance of various methods on the RAVEN and I-RAVEN datasets. For details, please check our paper.
Performance on RAVEN / I-RAVEN:
| Method | Acc | Center | 2x2Grid | 3x3Grid | L-R | U-D | O-IC | O-IG |
|---|---|---|---|---|---|---|---|---|
| WReN | 9.86/14.87 | 8.65/14.25 | 29.60/20.50 | 9.75/15.70 | 4.40/13.75 | 5.00/13.50 | 5.70/14.15 | 5.90/12.25 |
| LSTM | 12.81/12.52 | 12.70/12.55 | 13.80/13.50 | 12.90/11.35 | 12.40/14.30 | 12.10/11.35 | 12.45/11.55 | 13.30/13.05 |
| LEN | 12.29/13.60 | 11.85/14.85 | 41.40/18.20 | 12.95/13.35 | 3.95/12.55 | 3.95/12.75 | 5.55/11.15 | 6.35/12.35 |
| CNN | 14.78/12.69 | 13.80/11.30 | 18.25/14.60 | 14.55/11.95 | 13.35/13.00 | 15.40/13.30 | 14.35/11.80 | 13.75/12.85 |
| MXGNet | 20.78/13.07 | 12.95/13.65 | 37.05/13.95 | 24.80/12.50 | 17.45/12.50 | 16.80/12.05 | 18.05/12.95 | 18.35/13.90 |
| ResNet | 24.79/13.19 | 24.30/14.50 | 25.05/14.30 | 25.80/12.95 | 23.80/12.35 | 27.40/13.55 | 25.05/13.40 | 22.15/11.30 |
| ResNet+DRT | 31.56/13.26 | 31.65/13.20 | 39.55/14.30 | 35.55/13.25 | 25.65/12.15 | 32.05/13.10 | 31.40/13.70 | 25.05/13.15 |
| SRAN | 15.56/29.06 | 18.35/37.55 | 38.80/38.30 | 17.40/29.30 | 9.45/29.55 | 11.35/28.65 | 5.50/21.15 | 8.05/18.95 |
| CoPINet | 52.96/22.84 | 49.45/24.50 | 61.55/31.10 | 52.15/25.35 | 68.10/20.60 | 65.40/19.85 | 39.55/19.00 | 34.55/19.45 |
| PrAE Learner | 65.03/77.02 | 76.50/90.45 | 78.60/85.35 | 28.55/45.60 | 90.05/96.25 | 90.85/97.35 | 48.05/63.45 | 42.60/60.70 |
| Human | 84.41 | 95.45 | 81.82 | 79.55 | 86.36 | 81.81 | 86.36 | 81.81 |
Important
- Python 3.8
- PyTorch
- CUDA and cuDNN expected
See requirements.txt for a full list of packages required.
To train the PrAE learner, one needs to first extract rule annotations for the training configuration. We provide a simple script in src/auxiliary for doing this. Properly set path in the main() function, and your dataset folder will be populated with rule annotations in npz files.
To train the PrAE learner, run
python src/main.py train --dataset <path to dataset>
The default hyper-parameters should work. However, you can check main.py for a full list of arguments you can adjust.
In the codebase, window sliding and image preprocessing are delegated to the dataset loader and the code only supports training on configurations with a single component.
One thing we notice after code cleaning is that curriculum learning is not necessary, but in the manuscript we keep our original discovery.
To test on a new configuration, run
python src/main.py test --dataset <path to dataset> --config <new config> --model-path <path to a trained model>
Testing on 3x3Grid could potentially raise a CUDA-out-of-memory error. Try running on CPU then.
If you find the paper and/or the code helpful, please cite us.
@inproceedings{zhang2021abstract,
title={Abstract Spatial-Temporal Reasoning via Probabilistic Abduction and Execution},
author={Zhang, Chi and Jia, Baoxiong and Zhu, Song-Chun and Zhu, Yixin},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2021}
}
We'd like to express our gratitude towards all the colleagues and anonymous reviewers for helping us improve the paper. The project is impossible to finish without the following open-source implementations.