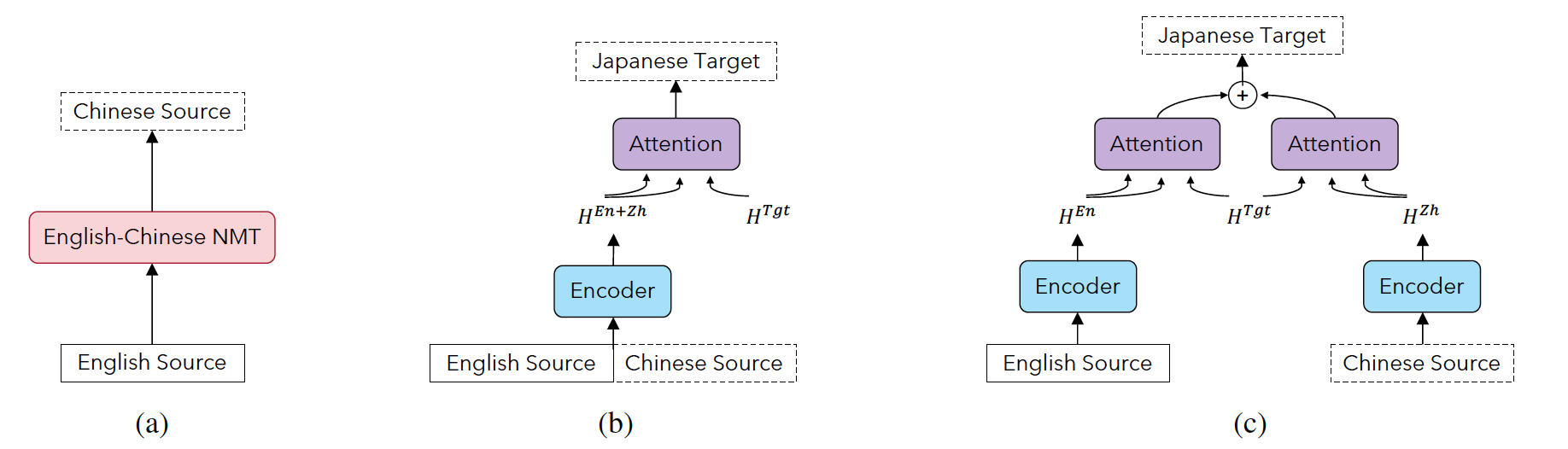
Multilingual neural machine translation models typically handle one source language at a time. However, prior work has shown that translating from multiple source languages improves translation quality. Different from existing approaches on multi-source translation that are limited to the test scenario where parallel source sentences from multiple languages are available at inference time, we propose to improve multilingual translation in a more common scenario by exploiting synthetic source sentences from auxiliary languages. We train our model on synthetic multi-source corpora and apply random masking to enable flexible inference with single-source or bi-source inputs. Extensive experiments on Chinese/English to Japanese and a large-scale multilingual translation benchmark show that our model outperforms the multilingual baseline significantly by up to +4.0 BLEU with the largest improvements on low-resource or distant language pairs.
- Zh/En-Ja
- Source Language: Zh (Chinese); Auxiliary Language: En (English); Target Language: Ja (Japanese);
- The training data consists of 0.67M sentence pairs for Japanese-Chinese and 3.0M sentence pairs for Japanese-English from ASPEC corpus. (ASPEC: Asian Scientific Paper Excerpt Corpus)
- To train the Chinese-English translation model for data augmentation, we use the training corpora (21.2M) from WMT18, newstest2017 as development set, and newstest2018 as test set.
- En-X
- The training data are from the WMT corpus (2013, 2014, 2016, 2017, 2018, and 2019)
- Training set can be downloaded from:
- Download (test set; spm model; dictionary): Google Drive
- We use all the available parallel data except for the WikiTitles released by WMT19. For French (Fr) and Czech (Cs), we randomly sample 10M sentence pairs from the full data.
- English (En), French (Fr), Czech (Cs), German(De), Finnish (Fi), Latvian (Lv), Estonian (Et), Romanian (Ro), Hindi(Hi), Turkish (Tr), and Gujarati (Gu).
Zh/En-Ja: Domain, Provenance ("Prov."), and the number of sentence pairs ("#Sent") in the training, development, and test data for Zh-Ja, En-Ja, and Zh-En.
| X-Y | Divide | Domain | Prov. | #Sent |
|---|---|---|---|---|
| Zh-Ja | train | Science | ASPEC | 0.66M |
| Zh-Ja | dev | Science | ASPEC | 2090 |
| Zh-Ja | test | Science | ASPEC | 2107 |
| Zh-Ja | test | News | Internal | 1000 |
| En-Ja | train | Science | ASPEC | 2.63M |
| En-Ja | dev | Science | ASPEC | 1790 |
| En-Ja | test | Science | ASPEC | 1812 |
| En-Ja | test | Query | Internal | 4999 |
| En-Ja | test | News | WMT20 | 993 |
| Zh-En | train | News | WMT18 | 18.7M |
| Zh-En | dev | News | WMT18 | 2001 |
En-X: Number of sentence pairs in the training data and the test set for each language pair.
| X-Y | Train Size | Test |
|---|---|---|
| Fr-En | 10.00M | newstest13 |
| Cs-En | 10.00M | newstest16 |
| De-En | 4.60M | newstest16 |
| Fi-En | 4.80M | newstest16 |
| Lv-En | 1.40M | newsdev17 |
| Et-En | 0.70M | newsdev18 |
| Ro-En | 0.50M | newsdev16 |
| Hi-En | 0.26M | newsdev14 |
| Tr-En | 0.18M | newstest16 |
| Gu-En | 0.08M | newsdev19 |
cd MNMT_Aux_Src_Lang
pip install --editable ./- For faster training install NVIDIA's apex library:
git clone https://github.com/NVIDIA/apex
cd apex
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" \
--global-option="--deprecated_fused_adam" --global-option="--xentropy" \
--global-option="--fast_multihead_attn" ./DATA_DIR=$1
OUTPUT_DIR=$2
BT_DATA_DIR=$3
python "MNMT_Aux_Src_Lang/train.py" "${DATA_DIR}" \
--save-dir "${OUTPUT_DIR}" \
--arch "transformer_vaswani_wmt_en_de_big" \
--task "translation_mtl_ols" \
--lang-pairs "fr-en,de-en,fi-en,cs-en,et-en,tr-en,lv-en,ro-en,hi-en,gu-en" \
--language-sample-temperature 5.0 \
--min-language-sample-temperature 1.0 \
--language-sample-warmup-epochs 5 \
--language-temperature-scheduler "linear" \
--data-bt "${BT_DATA_DIR}" \
--downsample-bt \
--dataset-impl "mmap" --share-all-embeddings --fp16 --ddp-backend=no_c10d \
--dropout 0.1 --optimizer "adam" --adam-betas '(0.9, 0.98)' --clip-norm 0.0 --weight-decay 0.0 \
--lr-scheduler inverse_sqrt --lr 0.0005 --warmup-updates 4000 --warmup-init-lr 1e-07 --min-lr 1e-09 \
--criterion "label_smoothed_cross_entropy" --label-smoothing 0.1 \
--max-tokens 4096 --max-update 100000 --update-freq 16 \
--no-progress-barWe test our model in a more realistic scenario where only a single source sentence for each test instance is provided. We experiment with two inference modes:
- single-source inference: where we provide our model with only a single source sentence during inference.
- bi-source inference: where we first augment the source sentence by translating it into an auxiliary language using the NMT model and then use our bi-source model to generate the target translation given the original and auxiliary source sentences.
- Beam Search: (during the inference) beam size = 8; length penalty = 1.0.
- Metrics: the case-sensitive detokenized BLEU using sacreBLEU:
- BLEU+case.mixed+numrefs.1+smooth.exp+tok.13a+version.1.4.3
- For Japanese, we use MeCab tokenizer before computing BLEU.
# E2X Bi-Source Inference Experiments
TEST_DATA="test-set"
RESULT="test-result"
mkdir -p "${RESULT}"
SPM="/path/to/spm.model"
inferenceFunction(){
PREFIX=$1
tgt_lang=$2
for aux_lang in "fr" "de" "fi" "cs" "et" "tr" "lv" "ro" "hi" "gu"; do
if [[ "${aux_lang}" != "${tgt_lang}" ]]; then
echo "inference: en + ${aux_lang} -> ${tgt_lang}"
paste "${TEST_DATA}/${PREFIX}.en" "${TEST_DATA}/${PREFIX}.trans.${aux_lang}" |
sed -r 's/\t/ /g' |
spm_encode --model "${SPM}" |
python "MNMT_Aux_Src_Lang/interactive.py" model \
--path "model/checkpoint.pt" \
--task "translation_mtl_ols" \
--lang-pairs "en-fr,en-de,en-fi,en-cs,en-et,en-tr,en-lv,en-ro,en-hi,en-gu" \
--source-lang "en" --target-lang "${tgt_lang}" \
--buffer-size 128 --batch-size 16 --beam 5 --lenpen 1.0 \
--remove-bpe=sentencepiece --no-progress-bar |
grep -P "^H" | cut -f 3- >"${RESULT}/${PREFIX}.en-${aux_lang}.${tgt_lang}"
python -m sacrebleu \
"${TEST_DATA}/${PREFIX}.${tgt_lang}" \
<"${RESULT}/${PREFIX}.en-${aux_lang}.${tgt_lang}"
fi
done
}
inferenceFunction "wmt13.fren" "fr"
inferenceFunction "wmt16.deen" "de"
inferenceFunction "wmt16.fien" "fi"
inferenceFunction "wmt16.csen" "cs"
inferenceFunction "dev18.eten" "et"
inferenceFunction "wmt16.tren" "tr"
inferenceFunction "dev17.lven" "lv"
inferenceFunction "dev16.roen" "ro"
inferenceFunction "dev14.hien" "hi"
inferenceFunction "dev19.guen" "gu"- Bilingual baseline: NMT model trained on each language pair separately.
- Multilingual baseline: multilingual NMT model trained on Zh-Ja and En-Ja data for Zh/En-Ja, and all English-centric data for En-X.
- Multilingual + pseudo: multilingual NMT model trained on the concatenation of the original parallel data and pseudo data.
- Multilingual + pivot: multilingual NMT model with pivot decoding (by first translating the source to the auxiliary language and then translating from the auxiliary to the target language).
We adopt the Transformer architecture as the backbone model for all our experiments. (Attention is All you Need)
BLEU scores on Zh/En to Ja translation task.
| Models | Inference | Science | News | Avg |
|---|---|---|---|---|
| Bilingual baseline | - | 46.6 | 18.7 | 32.6 |
| Multilingual baseline | - | 47.6 | 20.6 | 34.1 |
| Multilingual + pseudo | - | 47.5 | 20.1 | 33.8 |
| Multilingual + pivot | - | 20.5 | 7.7 | 14.1 |
| Ours (multi-enc) | single | 47.6 | 20.5 | 34.1 |
| Ours (single-enc) | single | 48.0 | 20.1 | 34.1 |
| Ours (multi-enc) | bi-source | 47.8 | 20.9 | 34.5 |
| Ours (single-enc) | bi-source | 48.1 | 20.8 | 34.4 |
BLEU scores on En/Zh to Ja translation task.
| Models | Inference | Science | Query | News | Avg |
|---|---|---|---|---|---|
| Bilingual baseline | - | 43.1 | 12.1 | 9.2 | 21.5 |
| Multilingual baseline | - | 42.7 | 13.3 | 9.8 | 21.9 |
| Multilingual + pseudo | - | 42.3 | 13.8 | 9.2 | 21.8 |
| Multilingual + pivot | - | 19.4 | 10.8 | 6.7 | 12.3 |
| Ours (multi-enc) | single | 42.3 | 13.0 | 8.4 | 21.2 |
| Ours (single-enc) | single | 42.6 | 14.5 | 10.1 | 22.4 |
| Ours (multi-enc) | bi-source | 42.8 | 14.5 | 10.6 | 22.6 |
| Ours (single-enc) | bi-source | 42.7 | 15.1 | 10.6 | 22.8 |
BLEU scores of the baseline models and our model with single-source and bi-source inference on En-X translation task.
| Models | Fr | Cs | De | Fi | Lv | Et | Ro | Hi | Tr | Gu | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Bilingual baseline | 31.8 | 25.8 | 33.8 | 20.6 | 22.3 | 13.9 | 25.2 | 11.2 | 12.5 | 7.8 | 20.5 |
| Multilingual baseline | 31.1 | 25.3 | 33.9 | 21.4 | 24.7 | 19.1 | 28.3 | 11.3 | 17.1 | 12.6 | 22.5 |
| Multilingual + pseudo | 30.8 | 24.7 | 33.0 | 20.7 | 24.3 | 19.4 | 28.3 | 13.0 | 17.9 | 13.4 | 22.5 |
| Ours (single-source) | 31.8 | 26.5 | 34.7 | 22.1 | 26.0 | 20.4 | 29.5 | 14.2 | 18.8 | 14.8 | 23.9 |
| Ours (bi-source) | 31.6 | 26.5 | 35.3 | 22.3 | 26.5 | 21.1 | 29.1 | 15.3 | 19.2 | 17.4 | 24.4 |
- ACL Anthology: https://aclanthology.org/2021.findings-emnlp.260/
@inproceedings{auxiliary,
title = "Improving Multilingual Neural Machine Translation with Auxiliary Source Languages",
author = "Xu, Weijia and Yin, Yuwei and Ma, Shuming and Zhang, Dongdong and Huang, Haoyang",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.260",
doi = "10.18653/v1/2021.findings-emnlp.260",
pages = "3029--3041",
}Please refer to the LICENSE file for more details.
If there is any question, feel free to create a GitHub issue or contact us by Email.