Juhu is an open source search engine that doesn't track users and id fully customizable.


Here's a short video that explains the project and how it uses Redis:
Firstly of all a bot is used to run through different websites and that bot checks if the url is allowed to crawl or not. If able to crawl, it means it is able to be indexed. So, the bot scrapes the data from that website. Filters the data and stores in a form that it will be easier to search and index the scraped data. I want to attach a little architecture diagram here to clear out the things I said:

First of all, our server needs to be connected with the redis database. This is a long code but it works :).
import { Client } from "redis-om";
const client = new Client();
const connectDB = async () => {
if (!client.isOpen()) {
try {
await client.open(process.env.REDIS_WEBSITE_URL);
console.log("Connected to redis !");
} catch (error) {
console.log("failed connecting redis", error);
}
}
};Yes, I created a function to call it again and again. But if the server is connected to the database already then it won't try to connect again, meaning our useless effort is saved.
Then I created a Schema to store the data. Yes, the scraped data in a proper structured way. I am using JSON database provided by redis as a primary database here.
class Website extends Entity {}
export const websiteSchema = new Schema(
Website,
{
url: {
type: "string",
},
title: {
type: "text",
textSearch: true,
},
description: {
type: "text",
textSearch: true,
},
firstFewWords: {
type: "string",
},
loadTime: {
type: "number",
},
lastUpdated: {
type: "date",
},
backLinks: {
type: "number",
},
backLinkKeywords: {
type: "string[]",
},
urlKeywords: {
type: "string[]",
},
mainKeywords: {
type: "string[]",
textSearch: true,
},
headings: {
type: "string[]",
textSearch: true,
},
favicon: {
type: "string",
},
ogImage: {
type: "string",
},
},
{
dataStructure: "JSON",
}
);And to save the data, I have created a function and exported that so it can be called again and again from anywhere I want.
export const saveWebsiteData = async (website) => {
const repository = await getRepository();
const site = repository.createEntity(website);
const id = await repository.save(site);
return id;
};As I have created another database to save images, so there is a seperate schema and nearly the name save method:
class Image extends Entity {}
export const imageSchema = new Schema(
Image,
{
imageUrl: {
type: "string",
},
siteTitle: {
type: "text",
textSearch: true,
},
siteURL: {
type: "string",
},
altTag: {
type: "text",
textSearch: true,
},
},
{
dataStructure: "JSON",
}
);The data is accessed using Redis search and I have also used the datatypes in schema that will make me comfortable searching the query and getting the relevant result.
export const searchData = async (query) => {
await connectDB();
const repository = await client.fetchRepository(websiteSchema);
await repository.createIndex();
const sites = await repository
.search()
.where("title")
.matches(query)
.or("description")
.matches(query)
.or("urlKeywords")
.contain(query)
.or("headings")
.contains(query)
.or("mainKeywords")
.contains(query)
.return.all();
console.log("got website from redis", sites);
return sites;
};I have created a function named as searchData to createIndex and search for the results and if the result is found or if results are found then the function returns it and from another file or another part of the program, I can call this function with a query as an argument and search for the result. I have nested a lot of or statements here because at this moment, I don't have enough data to display so I am in a path Something is better than nothing.
And nearly same goes for image searching.
export const searchImage = async (query) => {
await connectDB();
const repository = await client.fetchRepository(imageSchema);
await repository.createIndex();
const images = await repository
.search()
.where("altTag")
.matches(query)
.or("siteTitle")
.matches(query)
.return.all();
console.log("got images from redis", images);
return images;
};If you want to use the code or try out the code then I am going to discuss the process in some points here.
node --version && npm --versionRun the above command and if you get an error or don't get anything back. Try setting up nodejs and npm. If you get some numbers back then you are ready to go.
git clone https://github.com/aashishpanthi/search-engineClone this repository in order to use the code. Remember you must have git installed in your computer before using the above command.
The package.json file is in root directory of the project so you can install the dependencies directly with this command:
npm installAnd to install the dependecy of the frontend part, go to client directory and run npm install there. I mean use the following commands:
cd client
npm installThe most important files needed for us to run our application is .env file. This file stores the secrets like API token, access token and other informations that we don't want to share with anyone. Let's create a .env file with command:
touch .envYou can create and edit files using graphical medium also. And those who are using windows, please use graphical way or swicth to linux.
Now paste these variables inside of the .env file.
MONGO_URI =
REDIS_IMAGE_URL =
REDIS_WEBSITE_URL =
PORT = 5000
NODE_ENV = development
May be you have already guessed what each variable is for but anyways, I will tell you one by one. MONGO_URI contains the configured url to the mongodb database. REDIS_IMAGE_URL and REDIS_WEBSITE_URL contain the configured url for the redis databases. I have used two seperate databases for the website data and the images. PORT is used to define the port where our server will listen to. And NODE_ENV contains the environment on which we are working on, that is either development or production.
Open two seperate terminal. Open the react server on one terminal as:
cd client
npm start
And open the express server on another terminal as:
node index.jsor with mongoose as
npm run devStartNode version of minimum 16.x is needed. The app is developed on Node v16.14.2
NPM version of minimum 8.x is needed. The app is developed on NPM v8.5.0.
First of all I created an account on redis cloud and used the cloud database. You can also create free account on Redis Cloud
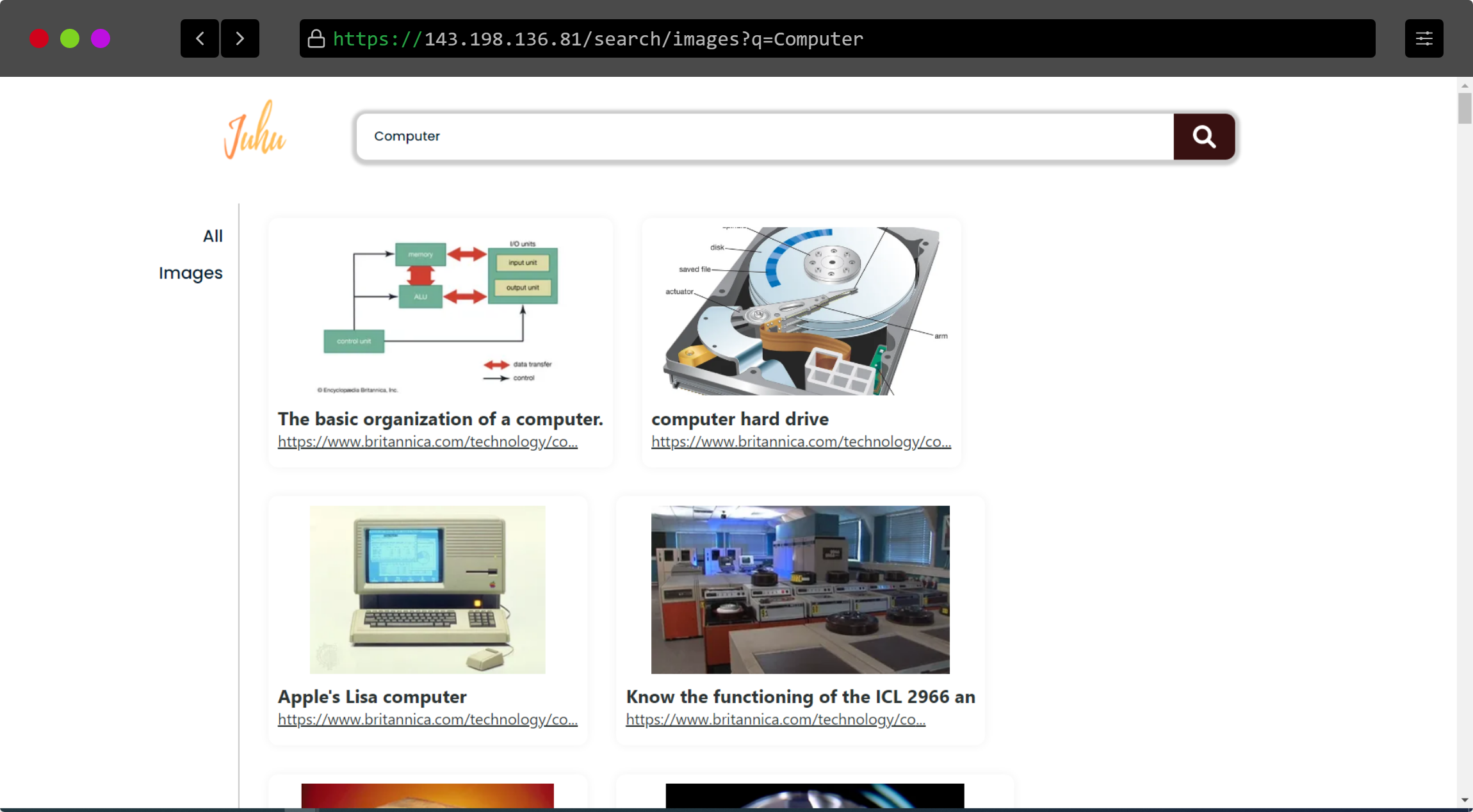
The MERN app is deployed over digital ocean. And an IP address is got. You can access the website from here http://143.198.136.81/
The scraper/crawler/bot or spider whatever you call it is deployed over a linode server. The Ubuntu server is used to deploy the bot. Yes, I have also used the Ubuntu to develop the application. I could have shared the IP address of bot but it doesn't listen to any http request to I don't think I will share.
Here some resources to help you quickly get started using Redis Stack. If you still have questions, feel free to ask them in the Redis Discord or on Twitter.
- Sign up for a free Redis Cloud account using this link and use the Redis Stack database in the cloud.
- Based on the language/framework you want to use, you will find the following client libraries:
I have used Redis OM Node (JS) to make this search engine.
{
"description": "An open source search engine in NodeJS",
"hidden": false,
"rank": 21,
"type": "Building Block",
"contributed_by": "Redis Labs",
"repo_url": "https://github.com/aashishpanthi/search-engine",
"download_url": "https://github.com/aashishpanthi/search-engine/archive/refs/heads/main.zip",
"hosted_url": "http://143.198.136.81:5000/",
"language": ["JavaScript"],
"redis_features": ["search","database"],
"redis_modules": ["RediJSON","RediSearch"],
"app_image_urls": [
"https://user-images.githubusercontent.com/60884239/187238474-58389c1e-0a40-44ef-a9c6-cc973298f4cc.png",
"https://user-images.githubusercontent.com/60884239/187239207-8bf91d3f-97f7-4720-822f-14178c69ed44.png"
],
"youtube_url": "https://www.youtube.com/watch?v=a2KDXRHfrqA",
"special_tags": ["Hackathon"],
"verticals": ["Technology", "Education"],
"markdown": "https://raw.githubusercontent.com/aashishpanthi/search-engine/main/README.md"
}
- Developer Hub - The main developer page for Redis, where you can find information on building using Redis with sample projects, guides, and tutorials.
- Redis Stack getting started page - Lists all the Redis Stack features. From there you can find relevant docs and tutorials for all the capabilities of Redis Stack.
- Redis Rediscover - Provides use-cases for Redis as well as real-world examples and educational material
- RedisInsight - Desktop GUI tool - Use this to connect to Redis to visually see the data. It also has a CLI inside it that lets you send Redis CLI commands. It also has a profiler so you can see commands that are run on your Redis instance in real-time