![]()
I have taken an AQI dataset from Kaggle and performed some EDA on it as well as implemented a decision tree classiifer to classify the air quality into one of the six buckets:
- Good
- Moderate
- Satisfactory
- Poor
- Very Poor
- Severe
- The dataset is taken from Kaggle.
- It contains air quality data and AQI (Air Quality Index) at hourly and daily level of various stations across multiple cities in India from 2015 to 2020.
- For this particular project, I have used just a part of the datasets provided in Kaggle, which contains day-wise city air pollution data.
Libraries used:
1. Numpy
2. Pandas
3. Seaborn
4. Chart Studio
5. Plotly
6. Pandas Profiling
7. PyCaret
I have used Pandas Profiling for performing exploratory data analysis and PyCaret for performing the machine learning classification task. Below are their installation commands:
For Pandas Profiling:
pip install pandas-profiling[notebook]
or
pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
or
conda install -c conda-forge pandas-profiling
For PyCaret:
#create a conda environment
conda create --name yourenvname python=3.6
#activate environment
conda activate yourenvname
#install pycaret
pip install pycaret
#create notebook kernel connected with the conda environment
python -m ipykernel install --user --name yourenvname --display-name "display-name"
1. Dataframe

2. AQI bucket chart

3. Pearson's correlations

4. Most polluted cities

5. Least polluted cities

6. City wise pollutants analysis
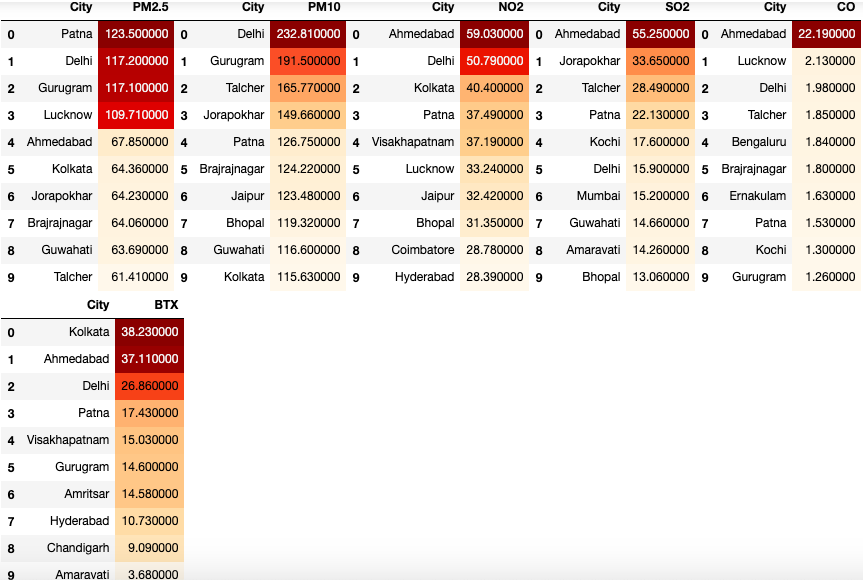
where BTX = Benzene + Toluene + Xylene
7. Yearly analysis

I would like to thank Parul Pandey as well as Naresh Bhat for providing amazing data exploration techniques from which I've pulled some here.
- Parul Pandey's notebook: https://www.kaggle.com/parulpandey/breathe-india-covid-19-effect-on-pollution
- Naresh Bhat's notebook: https://www.kaggle.com/nareshbhat/air-quality-analysis-eda-and-classification
I have used 'decision tree' as a classification model for this prediction problem based on the following results:

Using decision tree for classification, confusion matrix for validation data:
