User Manual
Mining and Utilizing Dataset Relevancy from Oceanographic Datasets (MUDROD) to Improve Data Discovery and Access
User Manual
Chaowei (Phil) Yang, Yongyao Jiang, Yun Li
NSF Spatiotemporal Innovation Center, George Mason University
Edward M Armstrong, Thomas Huang, David Moroni, Lewis John Mcgibbney, Chris Finch
Jet Propulsion Laboratory, NASA
Date: (08/18/2016)
MUDROD (Mining and Utilizing Dataset Relevancy from Oceanographic Datasets to Improve Data Discovery and Access) is a semantic discovery and search project funded by NASA AIST (NNX15AM85G). The objectives are to a) analyze web logs to discover the semantic relationships of datasets and user queries, b) construct a knowledge base by combining existing ontology and user browsing patterns, c) and improve data discovery by providing better ranked results, recommendation, and ontology navigation. This document is designed to walk you through the specific functionalities of the MUDROD system, including
-
web log ingesting;
-
session reconstruction;
-
vocabulary semantic relationship extraction;
-
search ranking;
-
recommendation
This tutorial will require MUDROD to already be deployed through Docker Container. Please refer to Accessing MUDROD through Docker Container for further information.
Before you get started, please make sure you are inside MUDROD docker container, which means your terminal will look like the picture below.
If your terminal look like the following picture instead,
Please make sure you log into the docker again using the following command and replace "demo" with the container name you specified.
$ docker attach **_demo_**
If system tells you that "You cannot attach to a stopped container, start it first", please run following commands first and attach it again.
$ docker start **_demo_**
$ docker attach **_demo_**
After logging into docker container, prepare MUDROD environment using the following commands.
$ cd /usr/local
$ ./run_mudrod_env.sh
$ cd mudrod
Web log ingesting and session reconstruction is a very time-consuming process on a single machine. To process one year of log takes about 8 hours on an average desktop, therefore we provide two types of testing data (Figure 1), which are stored on the docker container already.

Figure 1. Screenshot of testing data types and path
Testing data 1 (Testing_Data_1_3dayLog+Meta+Onto) is three days of PO.DAAC web log plus dataset metadata and ontology triples. They are prepared for the testing of step 2 and 3 (log ingesting and session reconstruction), which takes about 15~20mins.
Because three days of web log is not enough to capture the keyword and dataset connections, which could further affect the performance of ranking and recommendation, Testing data 2 (Testing_Data_2_ProcessedLog+Meta+Onto) is also provided, which the processed one year of web log results plus dataset metadata and ontology triples. They are prepared for the testing of step 4, 5, 6, 7, and 8.
The Web log ingesting function is used to import web logs into Elasticsearch.
As explained in step 1, you have to use testing data 1 for this step. To import the web logs from your local machine, please execute the following command line,
$ ./core/target/appassembler/bin/mudrod -logDir */data/mudrod_test_data/Testing_Data_1_3dayLog+Meta+Onto* -l
For three days of web log, this process would take about 10mins. Your logs are successfully imported when you see the message below (Figure 2).
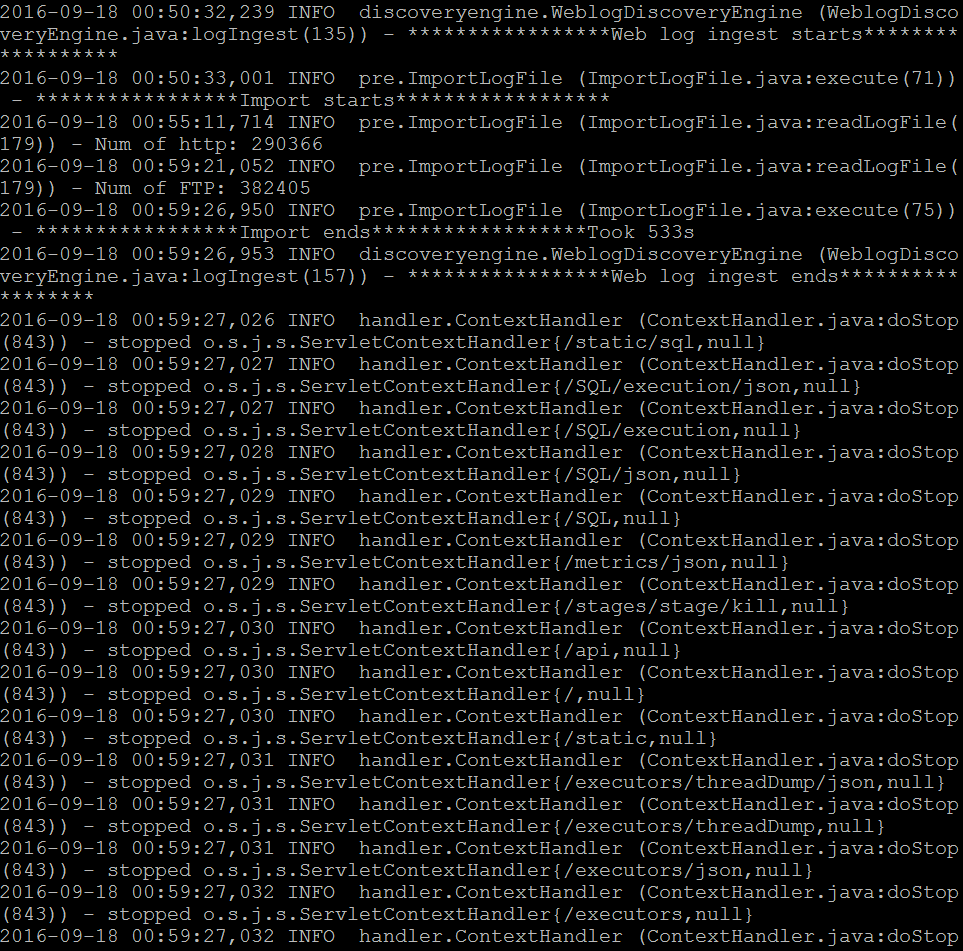
Figure 2. Result of web log ingesting
Please note that the web log ingesting function of MUDROD currently only supports web log in Apache Common format.
Session reconstruction is used to reconstruct session structure from raw web logs. This process consists of several steps. You also need to use testing data 1 for this step.
To reconstruct session from the imported web logs, please execute the following command line,
$ ./core/target/appassembler/bin/mudrod -logDir */data/mudrod_test_data/Testing_Data_1_3dayLog+Meta+Onto* -s
The execution time is about 5mins. The session reconstruction is successfully executed when you see the message below (Figure 3).
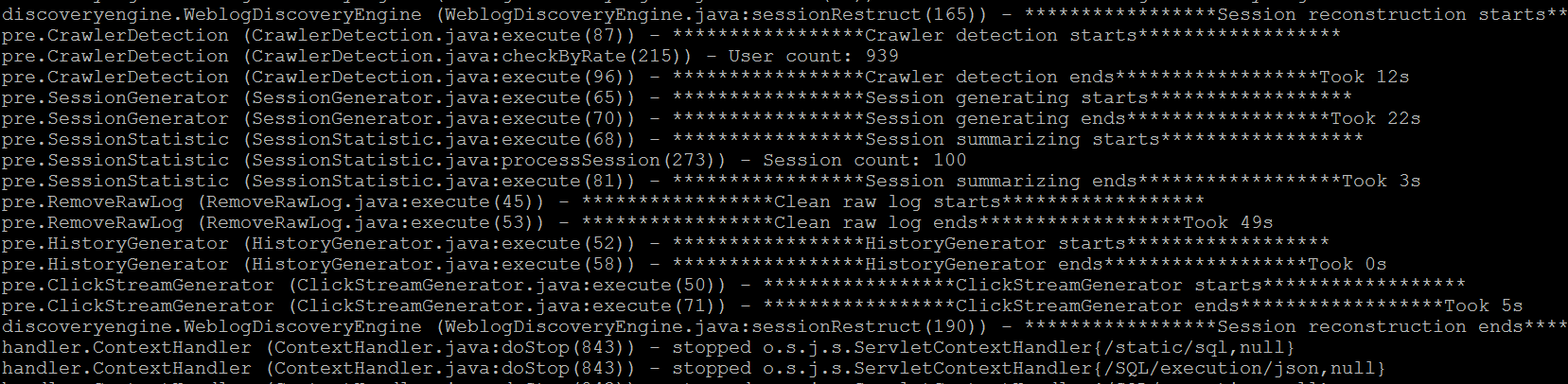
Figure 3. Result of session reconstruction
Step 3.2 to 3.6 are not required for step 4 and the steps after, only if you are interested in looking at the session structure.
The session structure visualization module is based on a open source software called Kibana. First, please go to this link: http://YourPublicIP:8080/mudrod-service. The first time you visit this page, the system will let you configure an index pattern (Figure 4). Please input the index name in the "index name or pattern" field, such as "mudrod", and then choose the “End_time” from Time-field name dropdown box.
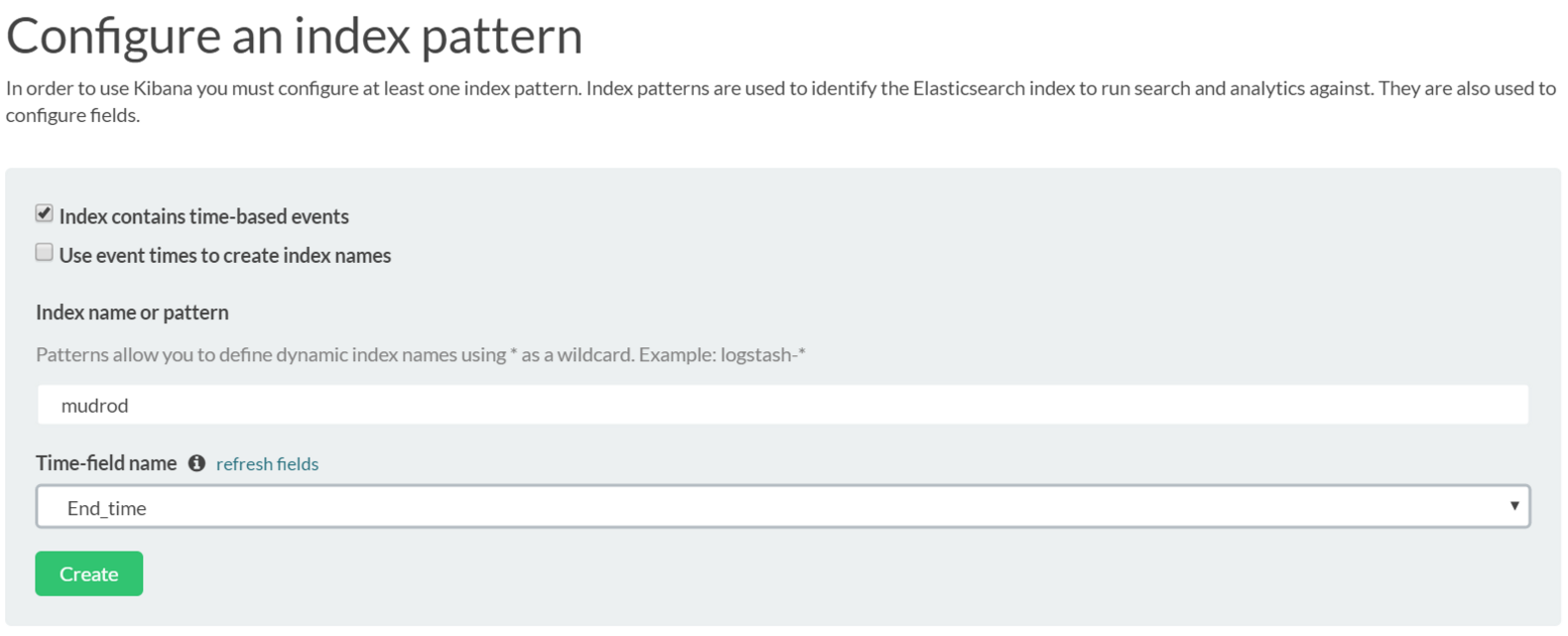
Figure 4. Index configuration page
After clicking the create button, all fields in the index will be listed. Please find the field named "SessionURL", after click edit, you will see the page below (Figure 5), change the format to URL, input "view" in label template, and then click on "update field".
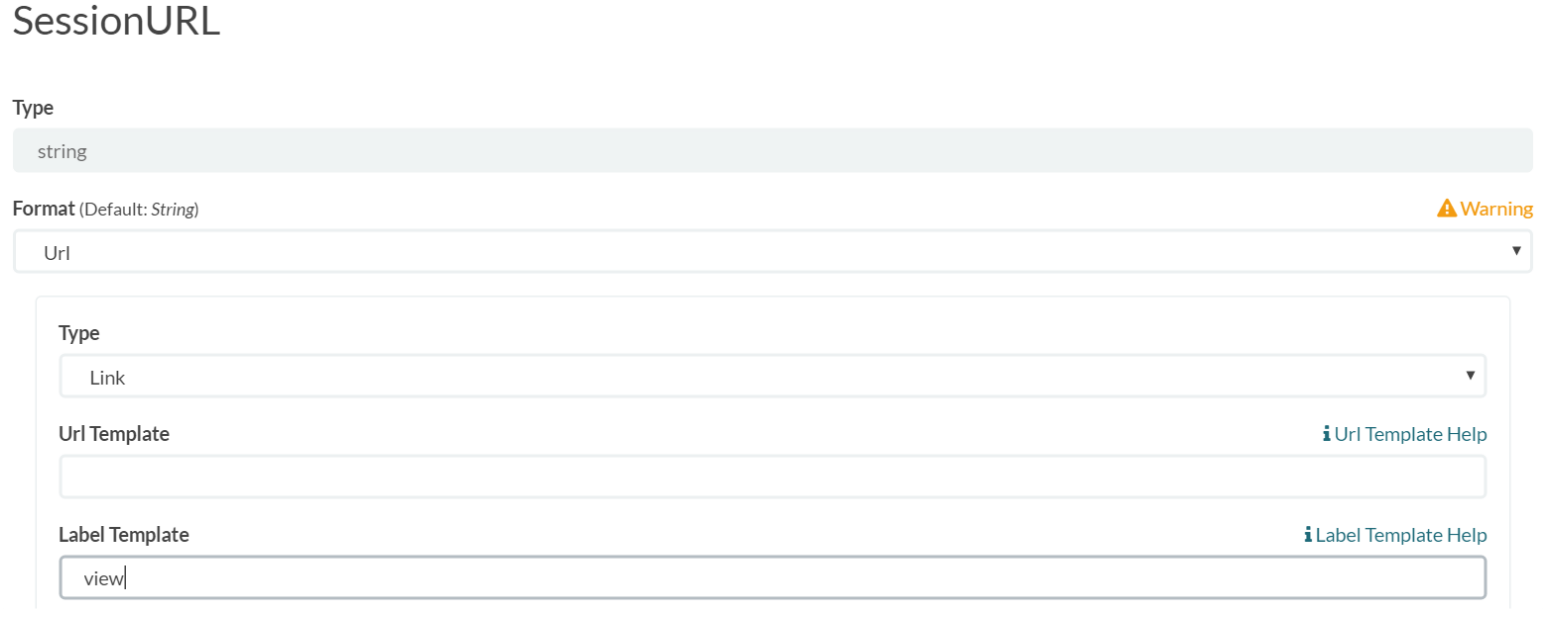
Figure 5. Hyperlink configuration page
Choose the "Discover" tab at the menu bar. If the system tells you that no result is found, as the image shows below (Figure 6), please change the time range of your web logs by clicking the top right area "Last 15 minutes".
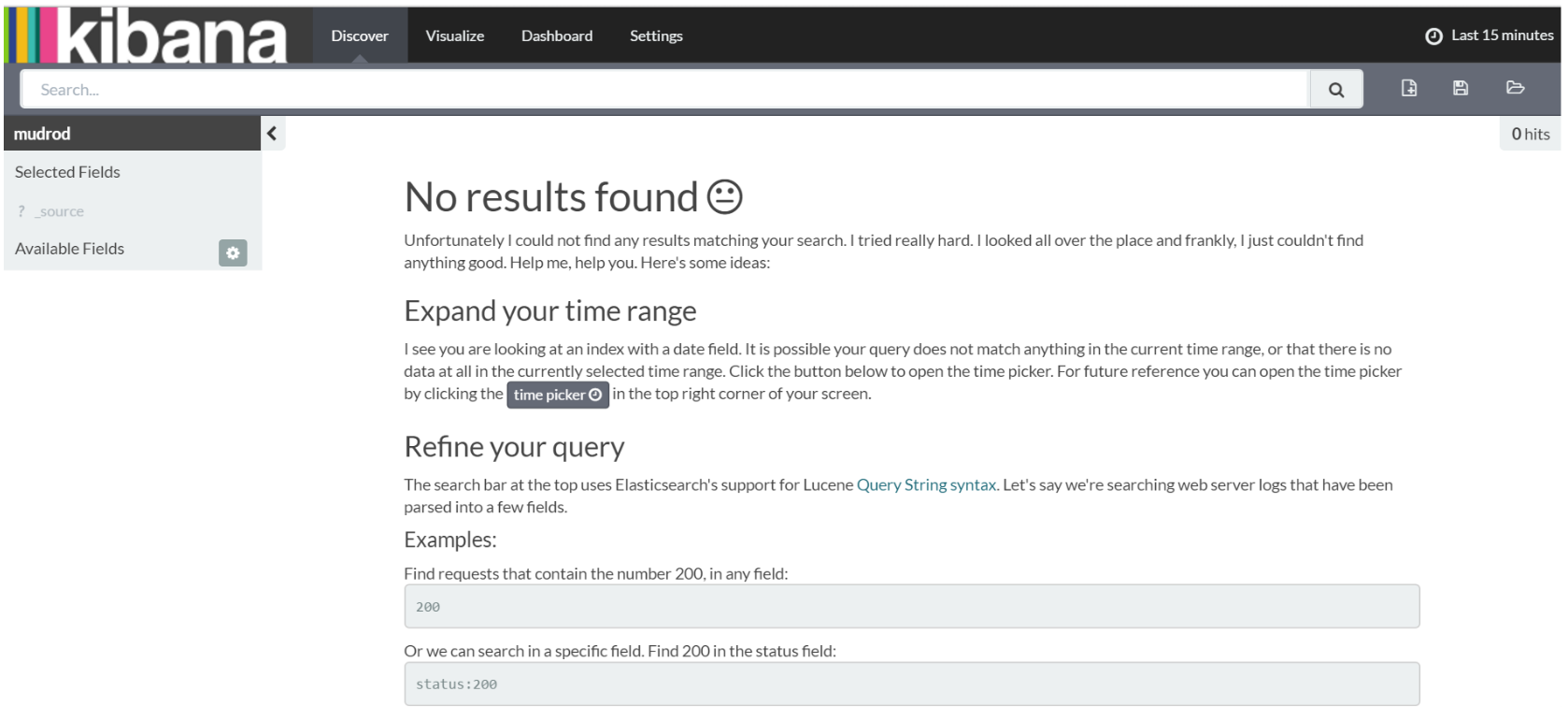
Figure 6. Page shows if no results found
If you are using testing data 1, please change the time range to "2015-01-31 to 2015-02-04" using absolute value (Figure 7).
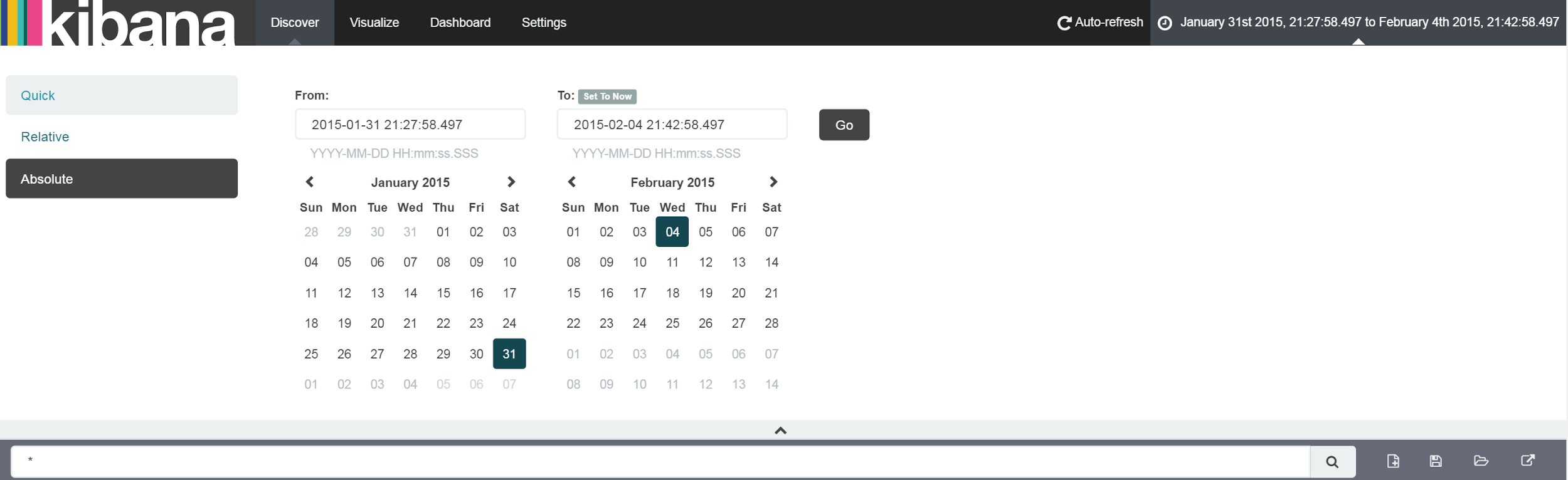
Figure 7. Setting absolute value for time range
Once the time range is set, logs falling into the range are shown in the main area of the discover page (Figure 8).
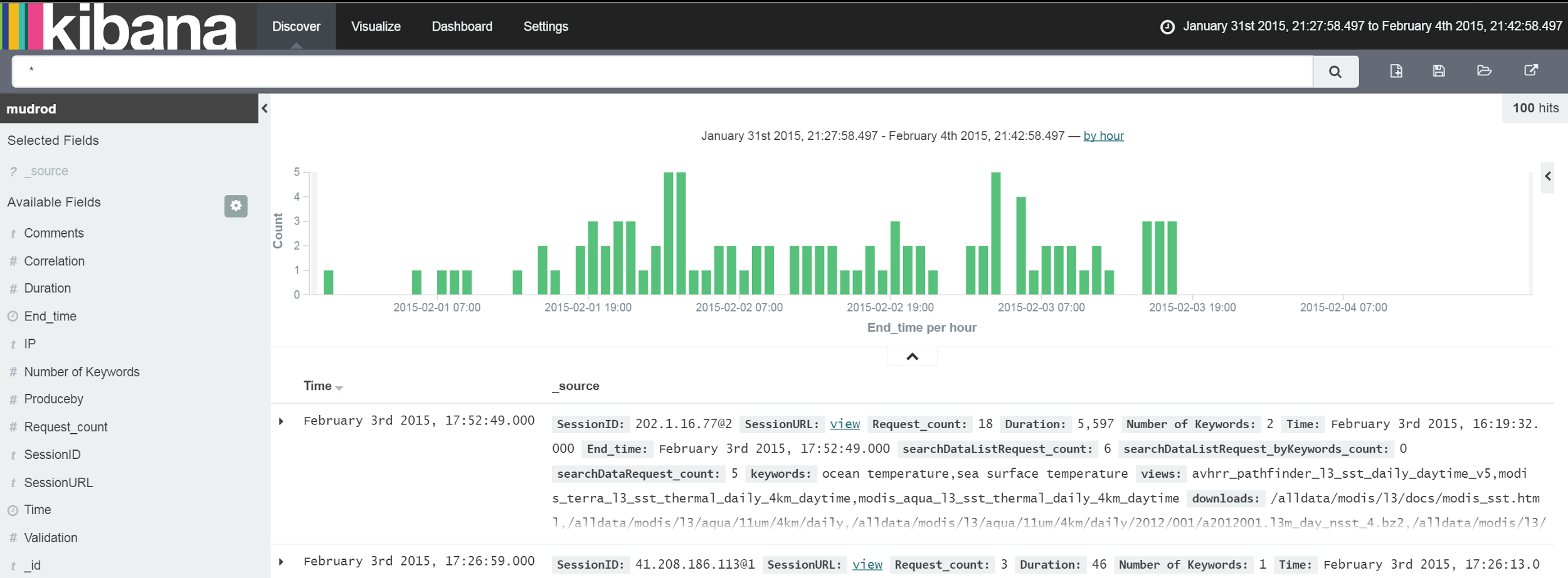
Figure 8. Result of discover page after time range set
If you are interested in data visualization and want to explore the log data deeply, please refer to Kibana User Guide.
Input "sessionstats*" in the search box. The table below the histogram will list data in types whose names contain "sessionstats". In order to get a brief overview of sessions, you can add fields from the available fields list in the left sidebar. We recommend the fields named "SessionID", "keywords", and "SessionURL". After add these three fields, you will see your page changed into something similar to the image below (Figure 9).
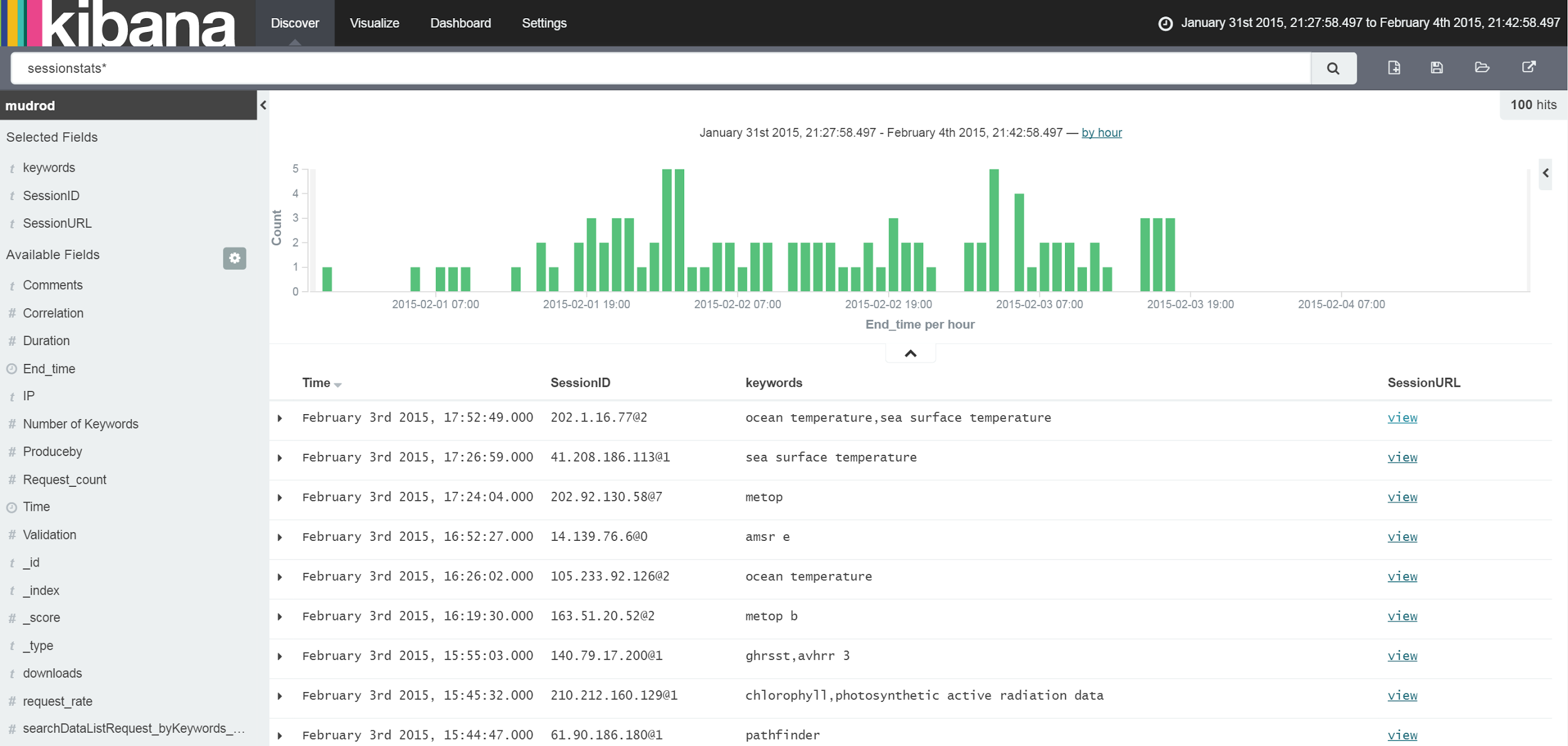
Figure 9. Result of session records locating
Click view link in the table row. The system will take you to the session tree structure page, where you can see the hierarchy tree view of the session as well as all of the requests in the session. An example session structure is shown below (Figure 10).
Tips: The prerequisite for this function is that MUDROD web service has been started, which means please come back to view session structure after step 5 is finished.
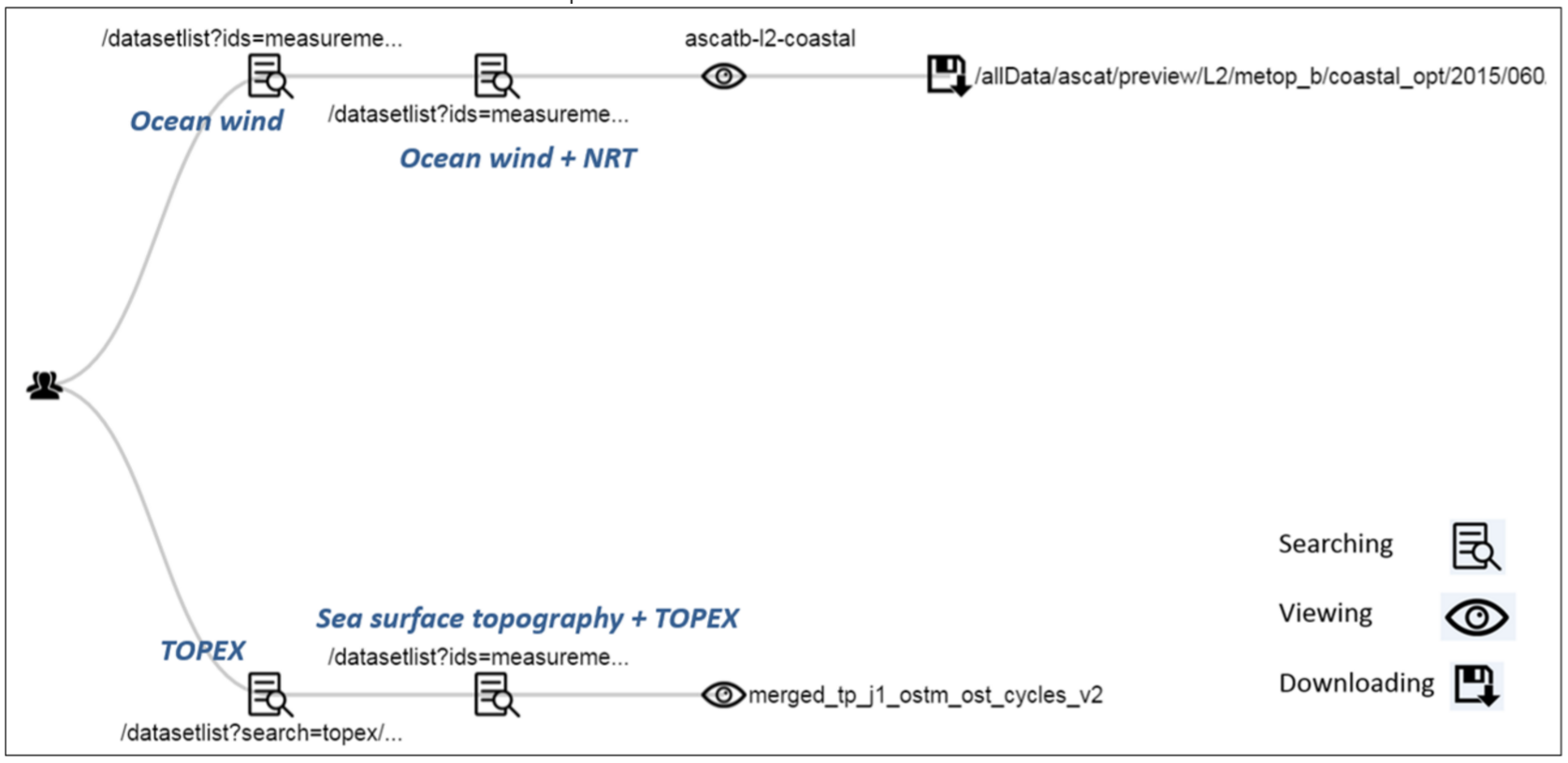
Figure 10. Result of session structure
Because 3 days of logs are not long enough to generate good vocabulary semantic relationships, please use testing data 2 to conduct this step.
To calculate similarity based on processed web logs, please execute the following command line,
$ ./core/target/appassembler/bin/mudrod -logDir */data/mudrod_test_data/Testing_Data_2_ProcessedLog+Meta+Onto* -p
This process is going to take about 5~10mins. The similarity is successfully calculated when you see the message below (Figure 11).
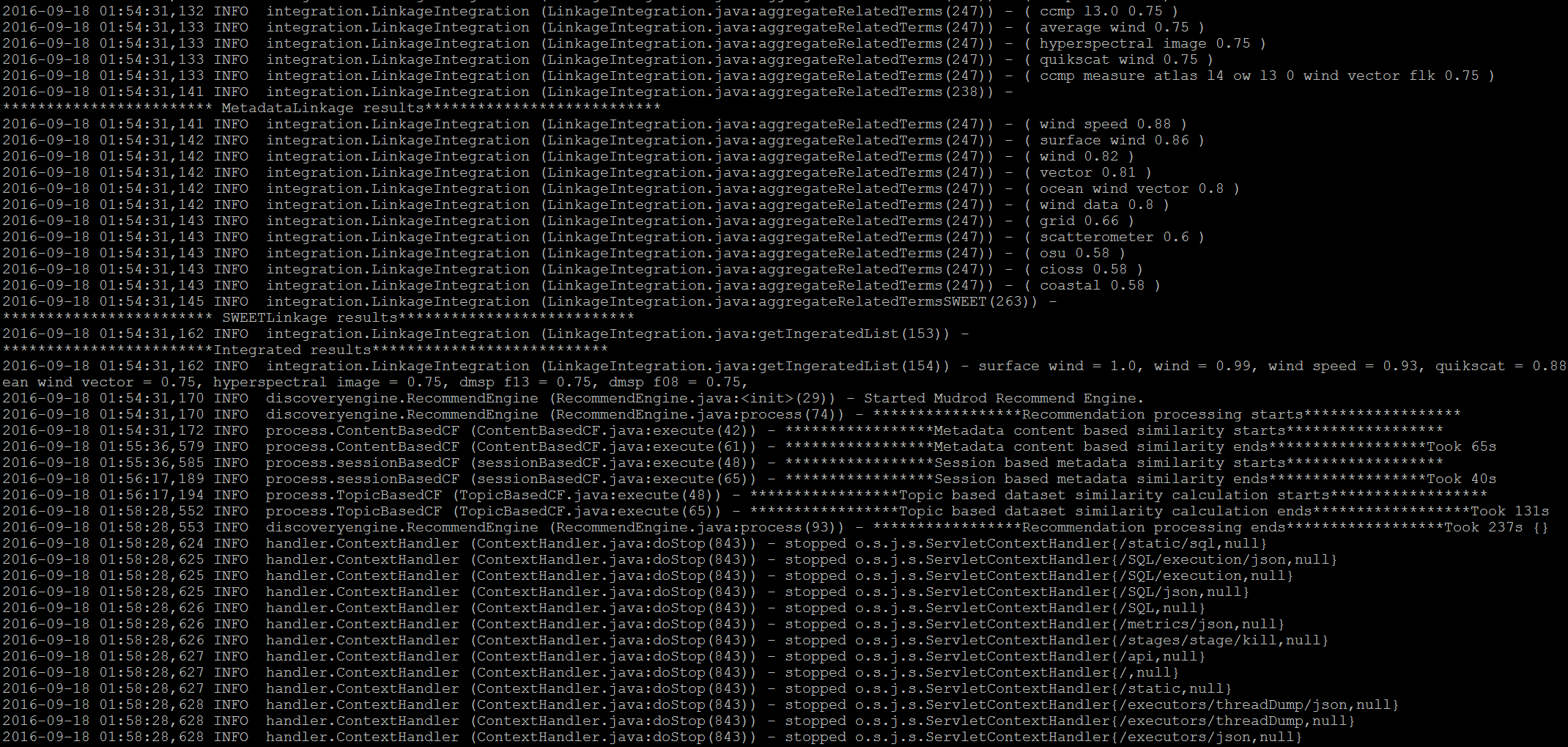
Figure 11. Result of vocabulary semantic relationship extraction
To run MUDROD web service, please execute the following command line
$ cd /usr/local/mudrod/service
$ export MAVEN_OPTS="-Xmx1024m -Xms1024m" && mvn tomcat7:run
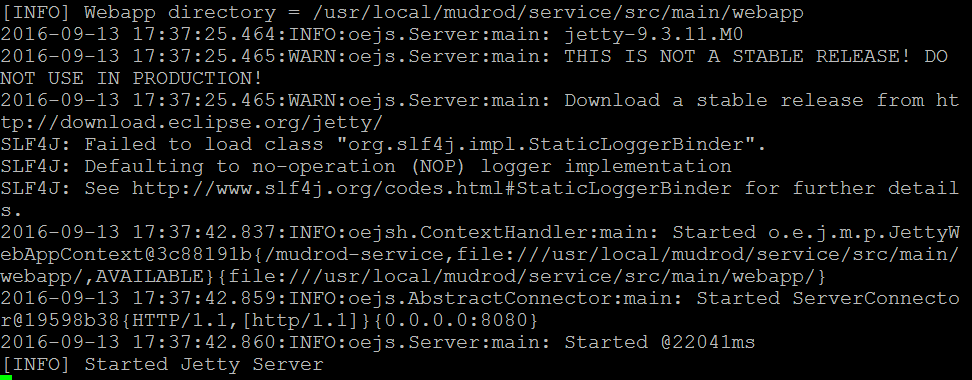
Figure 12. Result of starting MUDROD web service
After you see the message above (Figure 12), you will now be able to access the MUDROD Web Application at http://YourPublicIP:8080/mudrod-service (Figure 13).
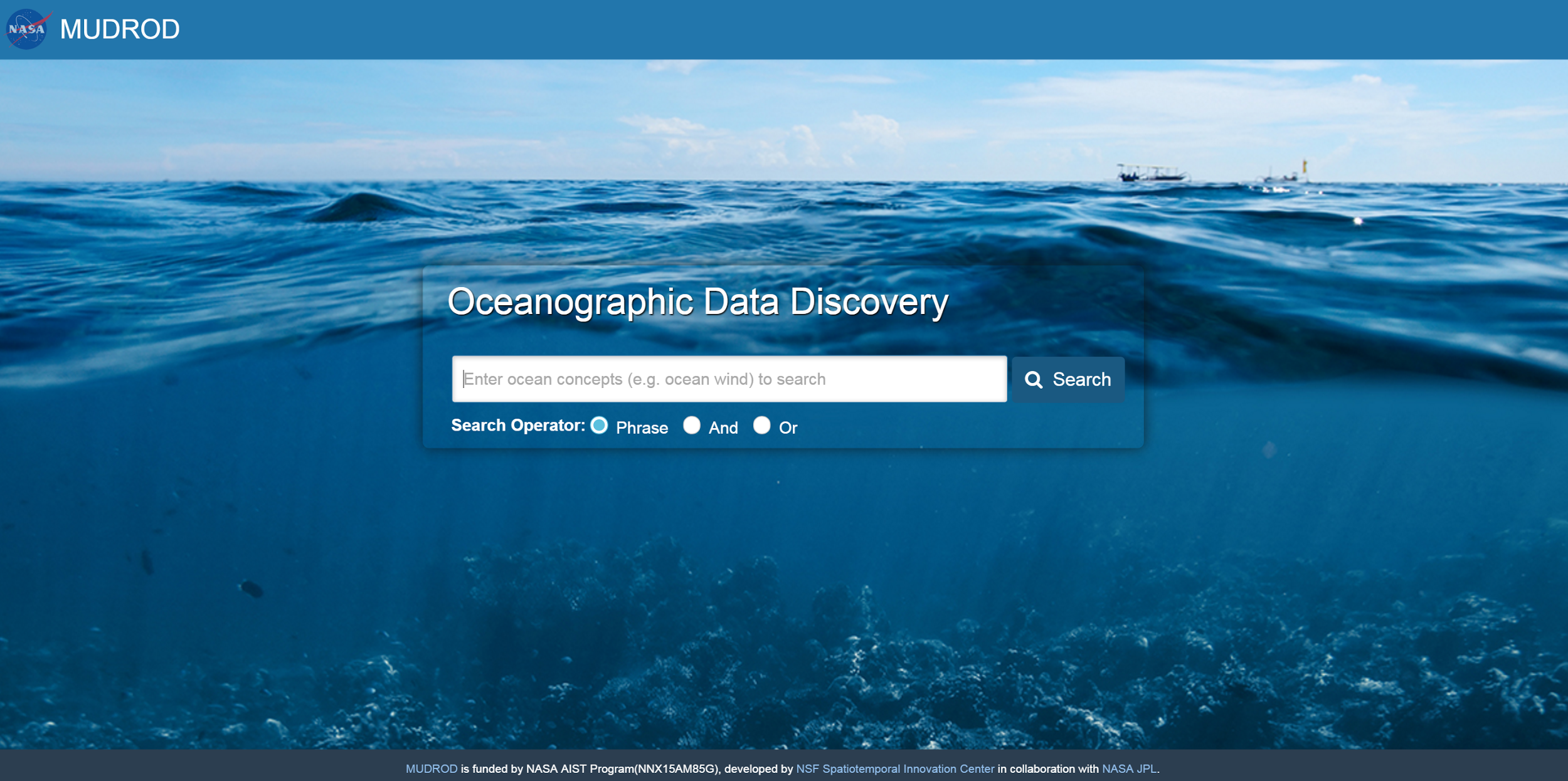
Figure 13. MUDROD application user interface
Although users can quickly start MUDROD web application using mvn:jetty, which uses a simple version, it won’t be able to publish a stable service. To publish MUDROD service in production mode, please refer to publish MUDROD service through Tomcat.
The ranking function is based on a machine learning model which takes a number of features, such as vector space model, version, processing level, release date, all-time popularity, monthly-popularity, and user popularity. If you search datasets by keywords such as "ocean wind". Related datasets are listed in a descending order of relevance as image shows below (Figure 14).
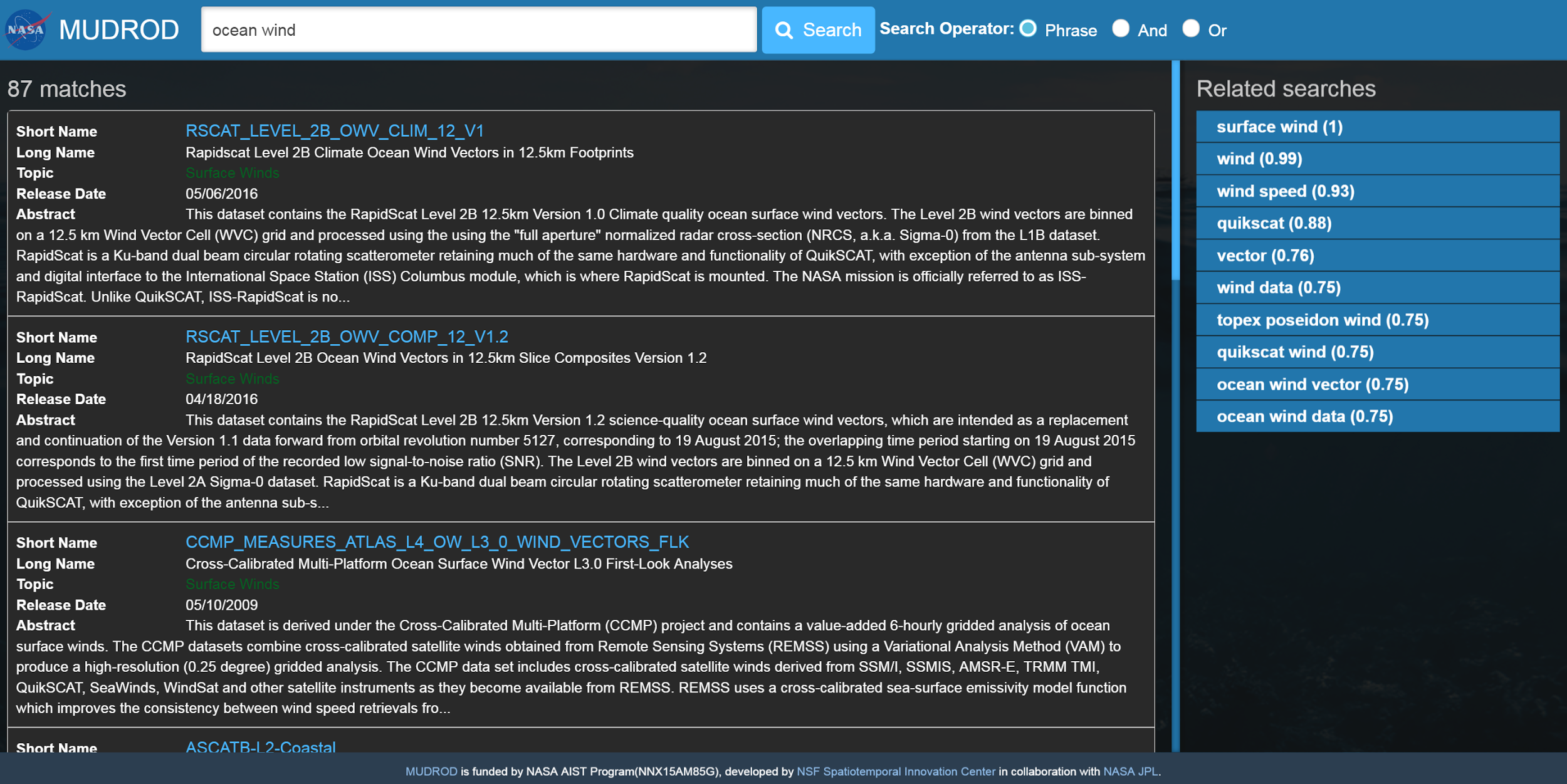
Figure 14. Searching result of "ocean wind"
The query navigation results are keywords similarity derived from web logs, metadata, and SWEET ontology. In the "related searches" list on the right-hand side, as image shows below (Figure 15), you would see a list of related searches sorted in a descending order of similarity, which is the value in the parenthesis.
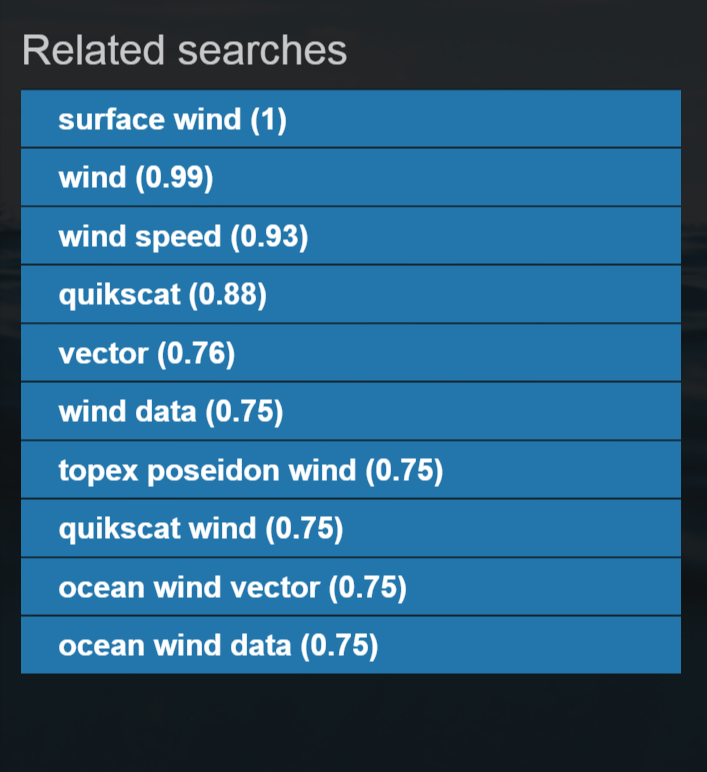
Figure 15. Screenshot of related searches
Currently, the recommendation function recommends datasets to users from two aspects which are content-based recommendation and session-based recommendation. The former method recommends similar datasets based on metadata attributes, such as topic, term, processing level, sensor, project, format, variables, etc. while the latter method recommends datasets based on user history extracted from web logs, which is similar to the function known as "People who viewed this product also viewed" on Amazon. The results of these two methods are combined into a final list.
After you click into any dataset in the ranking results, in the "related datasets" list, you would be able to find datasets they may also be interested in. 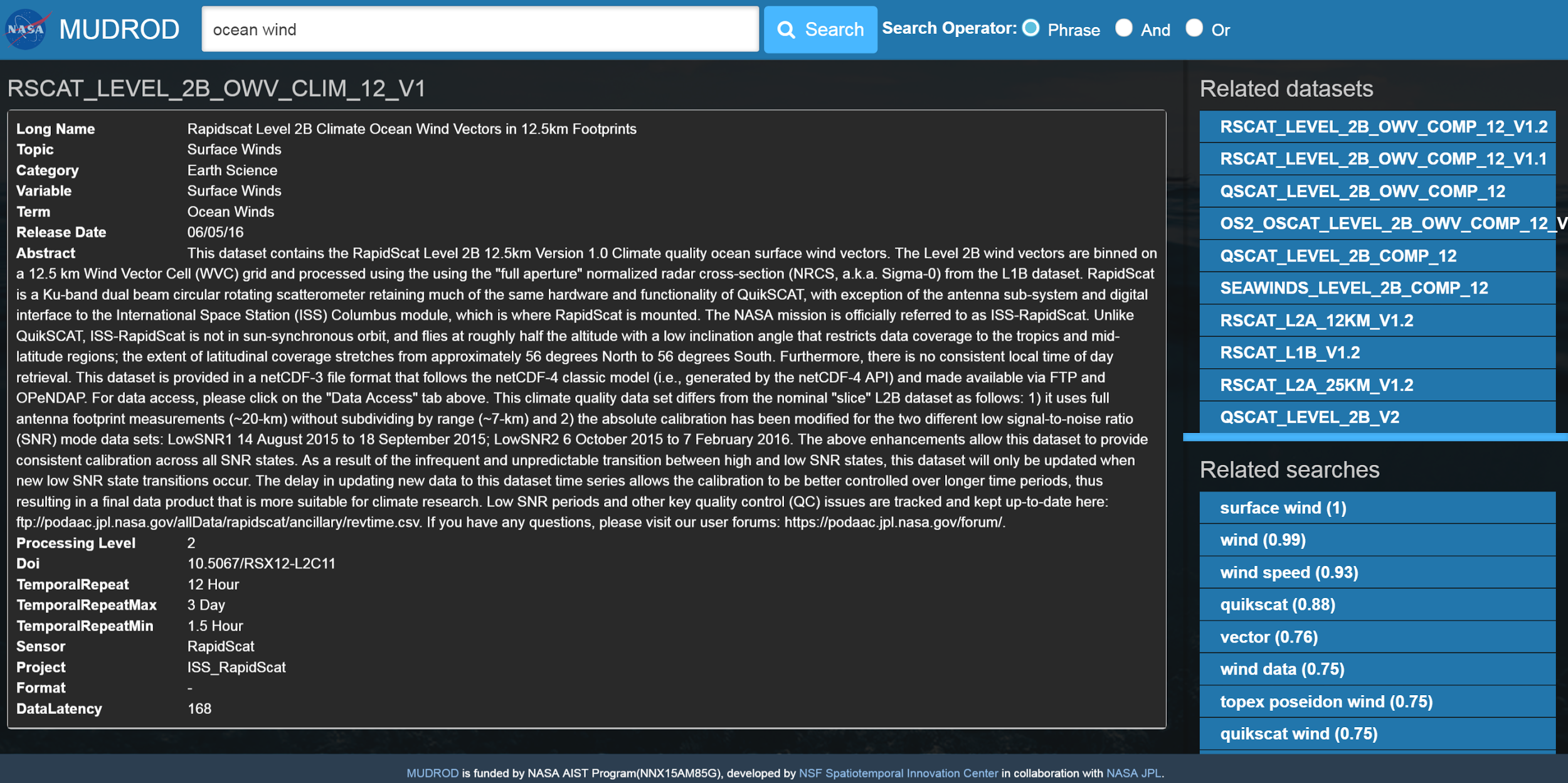
Figure 16. Screenshot of related datasets
-
Jiang, Y., Y. Li, C. Yang, E. M. Armstrong, T. Huang & D. Moroni (2016) Reconstructing Sessions from Data Discovery and Access Logs to Build a Semantic Knowledge Base for Improving Data Discovery. ISPRS International Journal of Geo-Information, 5, 54. http://www.mdpi.com/2220-9964/5/5/54#stats
-
Jiang, Y., Y. Li, C. Yang, K. Liu, E. M. Armstrong, T. Huang & D. Moroni (2016) A Comprehensive Approach to Determining the Linkage Weights among Geospatial Vocabularies - An Example with Oceanographic Data Discovery. International Journal of Geographical Information Science (submitted)
-
Y. Li, Jiang, Y., C. Yang, K. Liu, E. M. Armstrong, T. Huang & D. Moroni (2016) Leverage cloud computing to improve data access log mining. IEEE Oceans 2016. (in press)