RIP 32 Slave Acting Master Mode
- Current State: accept
- Authors: RongtongJin
- Shepherds: duhengforever@apache.org
- Mailing List discussion: dev@rocketmq.apache.org
- Pull Request:
- Released: <relased_version>
- Related Docs: English 中文版
-
Will we add a new module?
No
-
Will we add new APIs?
For the client, there are no new APIs. There will be new methods in the broker to enable slave acting master when the master is at fault. The broker and nameserver will have new APIs but ensure backward compatibility.
-
Will we add a new feature?
Yes, slave acting master mode is a new feature.
- Are there any problems of our current project?
Master-slave deployment
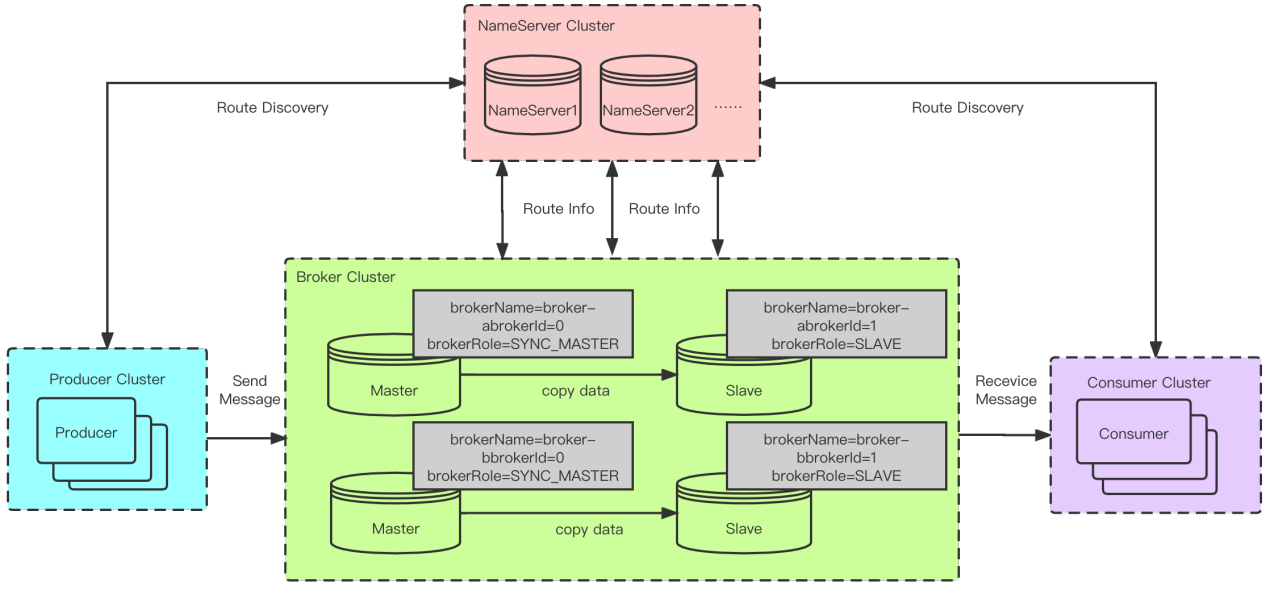
The figure above shows the RocketMQ master-slave deployment. Under this deployment mode, even if one master is down, the producer can still send messages to other masters. For the consumer, if the slave read is enabled, the consumer will automatically reconnect to the slave without consumption stagnation. However, there are also the following problems:
- Some operations limited to the master cannot be performed, including but not limited to:
- searchOffset
- maxOffset
- minOffset
- earliestMsgStoreTime
- endTransaction
- All lock operations, including lock, unlock, lockbatch, and unlockall
The specific impacts are:
- The client cannot obtain the lock of MQ in the replica group, so when the local lock expires, it will not be able to consume order messages of the broker group
- The client cannot actively end the transaction message in half state, and can only wait for the broker to check the transaction state Operations such as querying offset and earliestMsgStoreTime in admin tools or control cannot take effect on this broker group
-
The consumption of special messages on the failed broker group will be interrupted. The characteristics of such messages depend on the thread on the master broker to scan the special topics on the commit log and deliver the messages that meet the requirements back to the commit log. If the master broker goes offline, the consumption of special messages will be delayed or lost. This will affect the consumption of delayed messages, transaction messages, and pop messages in the current version.
-
There is no reverse synchronization of metadata. After the master is manually pulled up again, it is easy to cause the fallback of metadata. For example, after the master goes online, it synchronizes the backward consumer offset to the slave, and the consumer offset of this group of brokers rollback, resulting in a large number of repeated consumption.
DLedger deployment
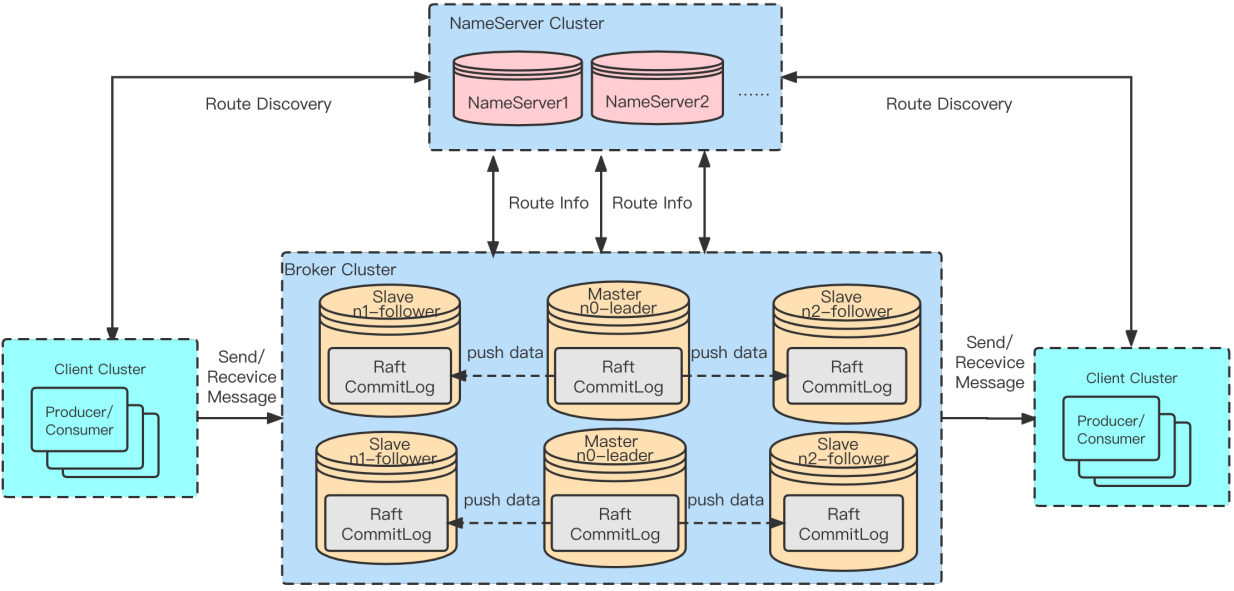
The above figure shows the dledger (raft) deployment, which can avoid the above issues by selecting a new master. However, it can be seen that three or more replicas are required in one broker group under the dledger deployment.
RIP-32 put forward a new proposal, slave acting master mode, as an upgrade of master-slave deployment mode. Under the original master-slave deployment mode, the slave will play a more important role in case of failure of the same group master through slave acting master, lightweight heartbeat, replica group information acquisition, broker pre-online mechanism, special message escape, etc.
- What can we benefit from proposed changes?
- When the master goes offline, the slave with the smallest brokerId in the broker group will undertake the tasks of slave reading and some tasks that the client and control can access but can only be completed on the master node.
- After the master goes offline, the special message consumption on the failed broker group will not be interrupted. The slave with the smallest brokerId in the broker group will undertake the task, and the delayed messages, pop messages, transaction messages, etc. can still operate normally.
- After the master goes offline, the slave acts as the master for a period of time. Then when the Master goes online again, through the pre-online mechanism, the master will automatically complete the reverse synchronization of metadata before going online. There will be no metadata roll back, resulting in a large number of repeated consumption of messages or a large number of replay of special messages.
- What problem is this proposal designed to solve?
In master-slave deployment mode, after the master goes offline, some operations that can only be performed on the Master cannot be performed, special message consumption is interrupted, and metadata is rollback after the master goes online again.
- What problem is this proposal NOT designed to solve?
This RIP is not intended to change the original RocketMQ architecture. It is not intended to replace the master-slave architecture or DLedger architecture. It is an enhancement of the master-slave architecture.
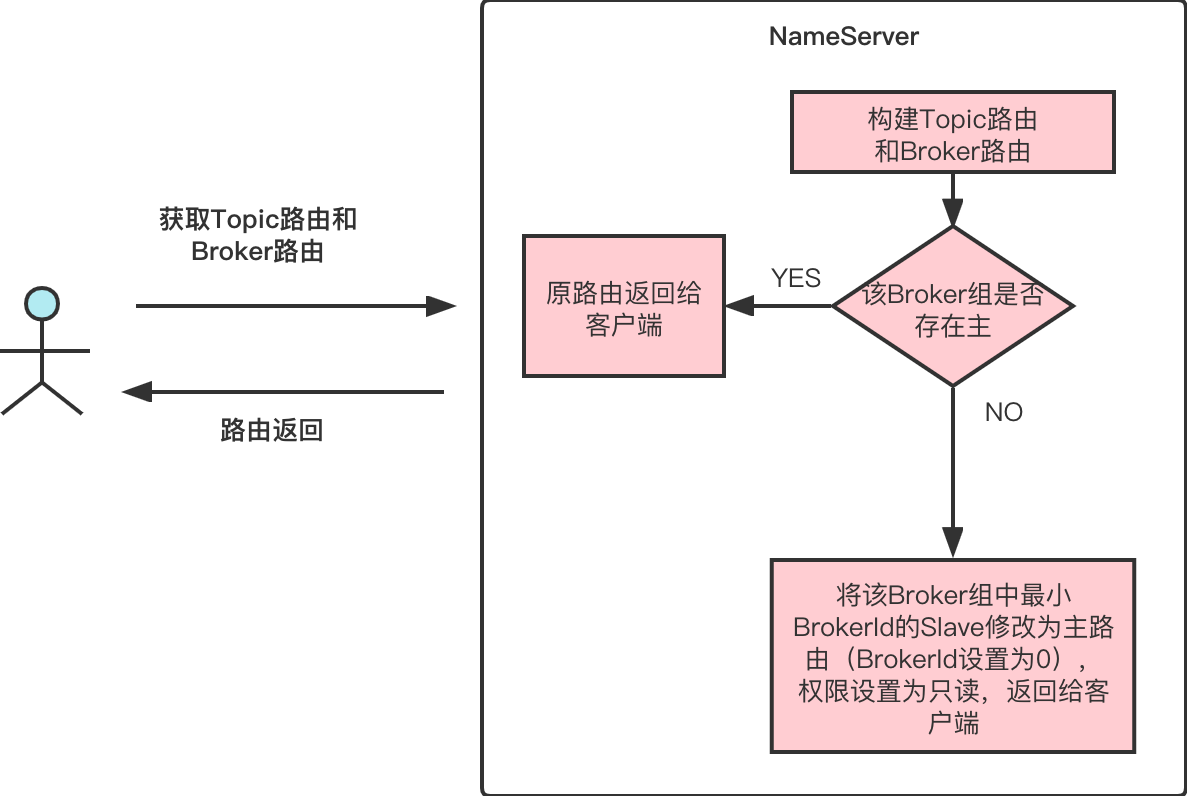
In RIP-32, when the master goes offline, the slave can consume normally, and the operation can only be performed by the master without modifying the client code. This is because nameserver supports the acting master mode. Acting master here means that nameserver will treat the living slave with the smallest broker id as an acting master when the broker group is no master, by replacing the broker id for that slave with 0 when broker permission is changed to 4 (read-only) in topic route so that the slave acts as the master in read-only mode in the client view.
public void changeSpecialServiceStatus(boolean shouldStart) {
……
changeScheduleServiceStatus(shouldStart);
changeTransactionCheckServiceStatus(shouldStart);
if (this.ackMessageProcessor != null) {
LOG.info("Set PopReviveService Status to {}", shouldStart);
this.ackMessageProcessor.setPopReviveServiceStatus(shouldStart);
}
}In addition, when the Master goes offline, the Slave with the smallest broker id takes over the scanning and redelivery of special messages.
As mentioned above, the surviving Slave with the smallest broker id will act master after master failure and therefore requires a mechanism that ensures that:
-
Nameserver can detect brokers up and down in time and complete topic route replacement and topic route elimination from offline brokers.
-
Brokers are aware of the ups and downs of a group of brokers in time.
First, Nameserver already has an active mechanism, which periodically scans inactive brokers and takes them offline. The "heartbeat" between the original broker and Nameserver relies on registerBroker operation, which involves topic information reporting and is too heavy. RIP-32 adds BrokerHeartbeat requests between Nameserver and broker, which will send the lightweight heartbeat to nameserver at regular intervals. If a scheduled nameserver task detects that it has not received the heartbeat of the broker after the heartbeat timeout period, it will unregister the broker. The heartbeat timeout is set when registerBroker, and if a change to the minimum broker id is found in a broker group, all brokers in that group are notified. And replace the slave topic route of the smallest broker id to act as the master in read-only mode when the topic route is fetched.
Second, there are two mechanisms to sense when a group of brokers is on or off in a timely manner. First is when the nameserver detects a change in the smallest broker id in the group described above, it reversely notifies all brokers in the group. Secondly, RIP-32 adds a GetBrokerMemberGroup request to the nameserver to get the broker replica group.
if (this.brokerConfig.isEnableSlaveActingMaster()) {
scheduledFutures.add(this.brokerHeartbeatExecutorService.scheduleAtFixedRate(new AbstractBrokerRunnable(this.brokerConfig) {
@Override
public void run2() {
if (isIsolated) {
return;
}
try {
BrokerController.this.sendHeartbeat();
} catch (Exception e) {
BrokerController.LOG.error("sendHeartbeat Exception", e);
}
}
}, 1000, brokerConfig.getBrokerHeartbeatInterval(), TimeUnit.MILLISECONDS));
scheduledFutures.add(this.syncBrokerExecutorService.scheduleAtFixedRate(new AbstractBrokerRunnable(this.brokerConfig) {
@Override public void run2() {
try {
BrokerController.this.syncBrokerMemberGroup();
} catch (Throwable e) {
BrokerController.LOG.error("sync BrokerMemberGroup error. ", e);
}
}
}, 1000, this.brokerConfig.getSyncBrokerMemberGroupPeriod(), TimeUnit.MILLISECONDS));
}The slave broker that is the smallest broker id in the broker group will start acting mode. Once the master Broker comes back online, the slave broker will also be aware of this through the nameserver’s notification or its own scheduled task to synchronize information about broker replicas information, and the acting mode is automatically terminated.
After the acting mode is enabled, the slave with the smallest broker id will undertake the scanning and redelivery of special messages.
We can scan the slave commit log, but if the scanned message is re-delivered to the commitlog, the unwritten semantics of the slave will be destroyed. Therefore, RIP-32 proposes an escape mechanism to deliver the special messages to the commit log of other masters remotely or locally.
- Remote Escape
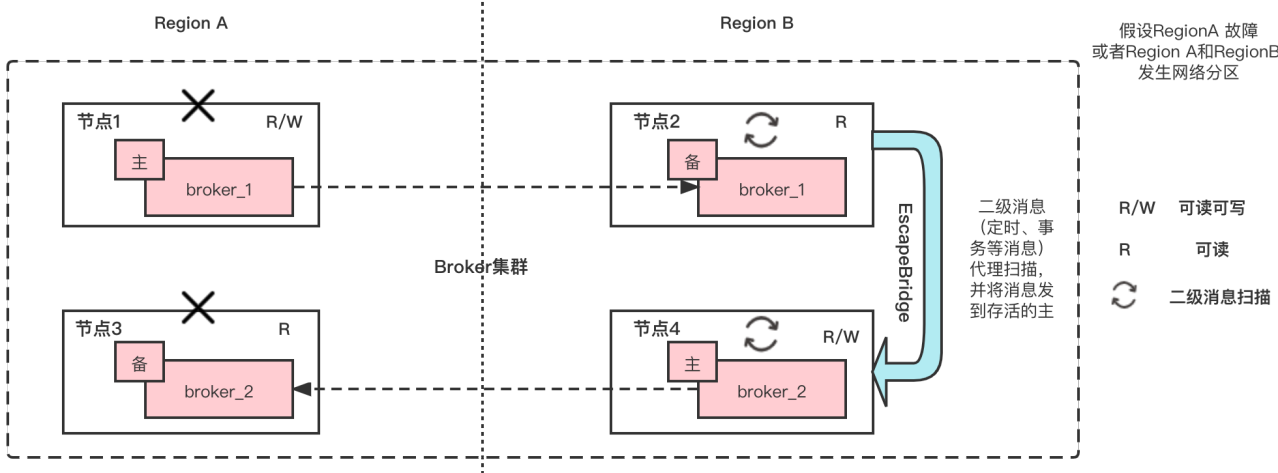
As shown in the figure above, assuming that region a fails, node 2 in region B will undertake the task of scanning specail messages, and send the final messages remotely to the surviving master in the current broker cluster through EscapeBridge.
- Local Escape
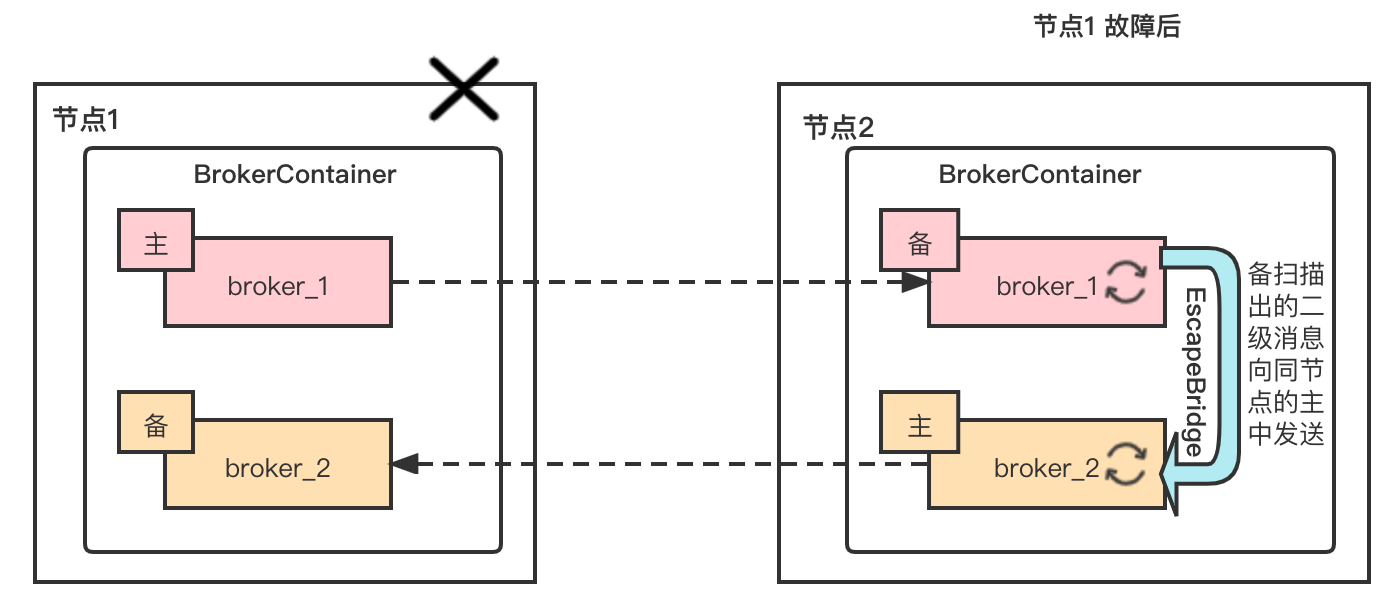
Local escape needs to be operated in the BrokerContainer mode (see RIP-31 for details). If there is a surviving master in the BrokerContainer, it will give priority to escape to the master commit log of the same process to avoid remote RPC.
Behavior changes of various special messages
- Delayed Message
When the slave acts the master, the scheduleMessageService will start, and the delayed messages time up will escape to the local master first through EscapeBridge. If not, they will escape to the remote master. Messages stored on the broker that has not expired in time will be escaped to other surviving masters. In terms of data volume, if a large number of delayed messages on the broker have not expired, remote escape will cause large data flow within the cluster, but it is basically controllable.
- POP Message
-
Add the broker name attribute when CK/ACK spells a key. This allows each broker to cancel CK/ACK messages from other brokers while scanning revive topic.
-
The CK/ACK message on the slave will be escaped to another specified master-A (the same master is required; otherwise, CK/ACK cannot cancel and the message is duplicated). Master-A scans its commit log message and cancels it. Based on the information in the CK message, the messages are pulled to the slave (locally if present, remotely otherwise) and then dropped to a local retry topic
- Transaction message
After the master broker goes offline, the slave broker will play the role of standby reading and proxy secondary messages. Therefore, some metadata in the slave broker, including consumer offset and delayed message progress, will be more advanced than the offline master broker. If the master broker goes online again, the slave broker metadata will be overwritten by the master broker, and this group of broker metadata will be rolled back, which may cause a large number of duplicate messages. Therefore, a pre-online mechanism is needed to complete the reverse synchronization of metadata.
The concept of the data version needs to be added to metadata such as consumer offset and delay offset. In order to prevent too frequent version number updates, the concept of update step size needs to be added. For example, for consumer offset, the version number is increased to the next version more than 500 update times.
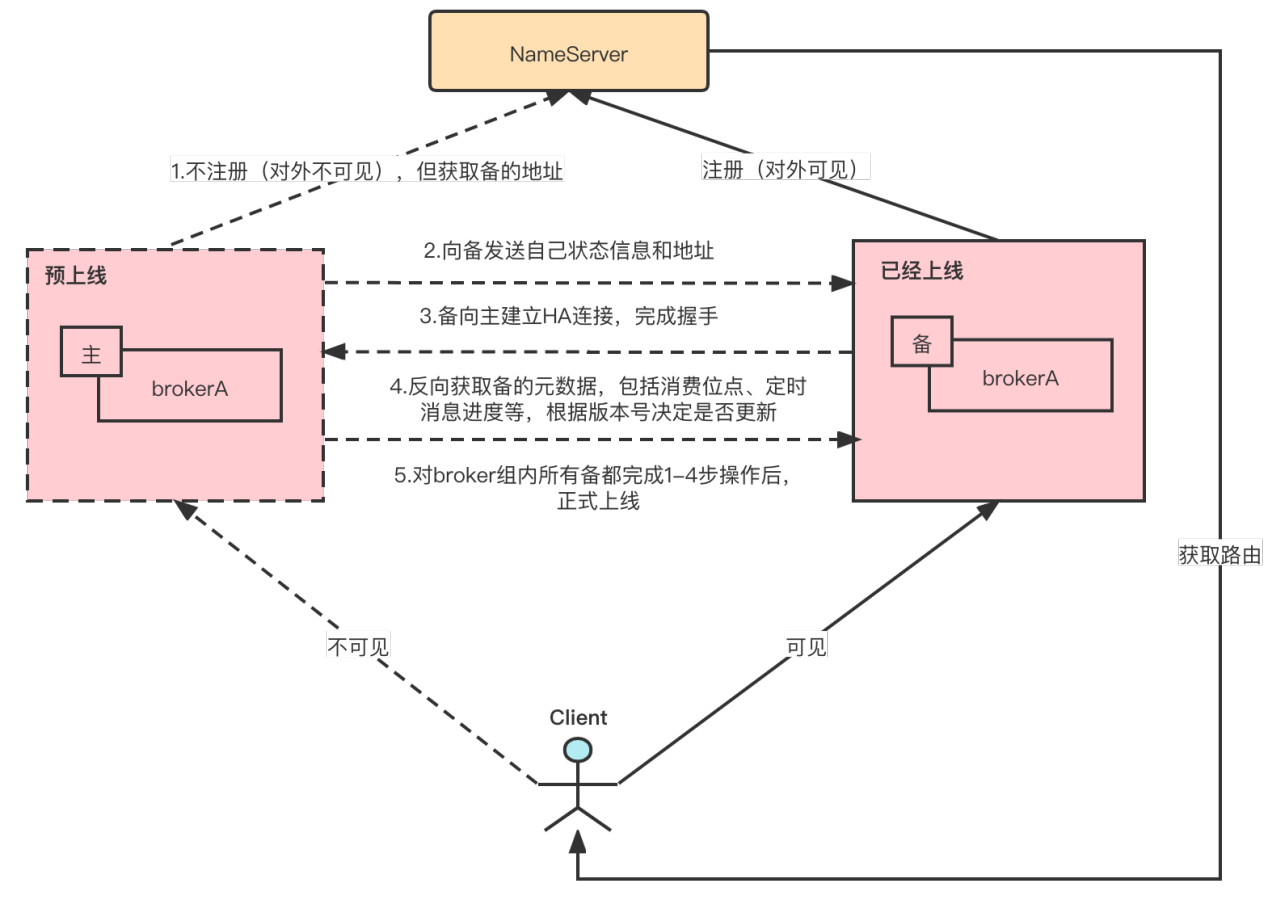
As shown in the above figure, the master broker will be in pre-online progress before it is launched. Before it is in pre-online progress, it will not be visible to the client (the broker will have isIsolated flag, and when it is true, it will not register and send heartbeat to nameserver). Therefore, it will not provide services to the client, and the scanning process of special messages will not be started. The specific pre-online mechanism is as follows:
- The master broker obtains the slave broker address from the nameserver but does not register.
- Master broker sends its own status information and address to slave broker.
- After the slave broker obtains the master broker address and status information, it establishes the HA connection, completes the handshake, and enters the transfer state.
- After the master broker completes the handshake, it reversely obtains the metadata of the slave, including the consumer offset, delayed message progress, etc., and determines whether to update it according to the data version.
After completing steps 1-4 for all slave brokers in the broker group, the master broker officially goes online, registers with the nameserver, and officially provides services to the client.
When the slave acts as the master, the external view is a "read-only" master, so order messages can still lock the queue. However, after the master is re-launched, it may cause multiple consumers to lock the same queue within a certain time. For example, a consumer still locks a slave broker’s queue, and a consumer locks the same queue of the master, resulting in disorder and repetition of order messages.
Therefore, during lock operation, RIP-32 requires that the quorum of the brokers in the replica group be locked successfully. However, the two replicas cannot reach the principle of Qurum, so RIP-32 provides the lockInStrictMode parameter to indicate whether the strict mode is used when the consumer locks the queue of order messages. Strict mode means that for a single queue, the lock is successful only when the quorum members of the replica group are locked successfully. Non-strict mode means that the lock is successful even if any replica is locked successfully. This parameter is false by default. When the ordering of messages is higher than the availability, please set this parameter to false.
- Method signature changes
Requests and API changes
New request codes are added
public static final int GET_BROKER_MEMBER_GROUP = 901;
public static final int BROKER_HEARTBEAT = 904;
public static final int NOTIFY_MIN_BROKER_ID_CHANGE = 905;
public static final int EXCHANGE_BROKER_HA_INFO = 906;BrokerHeartbeatRequestHeader
public class BrokerHeartbeatRequestHeader implements CommandCustomHeader {
@CFNotNull
private String clusterName;
@CFNotNull
private String brokerAddr;
@CFNotNull
private String brokerName;
……
}Data structure in BrokerMemberGroup
public class BrokerMemberGroup {
private String cluster;
private String brokerName;
private Map<Long/* brokerId */, String/* broker address */> brokerAddrs;
……
}GetBrokerMemberGroupRequestHeader
public class GetBrokerMemberGroupRequestHeader implements CommandCustomHeader {
@CFNotNull
private String clusterName;
@CFNotNull
private String brokerName;
……
}NotifyMinBrokerIdChangeRequestHeader
public class NotifyMinBrokerIdChangeRequestHeader implements CommandCustomHeader {
@CFNullable
private Long minBrokerId;
@CFNullable
private String brokerName;
@CFNullable
private String minBrokerAddr;
@CFNullable
private String offlineBrokerAddr;
@CFNullable
private String haBrokerAddr;
……
}ExchangeHAInfoRequestHeader
public class ExchangeHAInfoRequestHeader implements CommandCustomHeader {
@CFNullable
public String masterHaAddress;
@CFNullable
public Long masterFlushOffset;
@CFNullable
public String masterAddress;
}ExchangeHAInfoResponseHeader
public class ExchangeHAInfoResponseHeader implements CommandCustomHeader {
@CFNullable
public String masterHaAddress;
@CFNullable
public Long masterFlushOffset;
@CFNullable
public String masterAddress;
}The registerBrokerRequestHeader adds heartbeatTimeOutMillis and enableActingMaster. Heartbeat timeOutMillis indicates the heartbeat timeout time, and enableActingMaster indicates whether the broker starts the slave acting master mode.
public class RegisterBrokerRequestHeader implements CommandCustomHeader {
@CFNotNull
private String brokerName;
@CFNotNull
private String brokerAddr;
@CFNotNull
private String clusterName;
@CFNotNull
private String haServerAddr;
@CFNotNull
private Long brokerId;
@CFNullable
private Long heartbeatTimeoutMillis;
@CFNullable
private Boolean enableActingMaster;
private boolean compressed;
private Integer bodyCrc32 = 0;
……
}Increase onlyThisBroker field LockBatchRequestBody/UnLockBatchRequestBody, false by default, to complete the qurom locked
LockBatchRequestBody:
public class LockBatchRequestBody extends RemotingSerializable {
private String consumerGroup;
private String clientId;
private boolean onlyThisBroker = false;
private Set<MessageQueue> mqSet = new HashSet<MessageQueue>();
……
}UnLockBatchRequestBody
public class UnlockBatchRequestBody extends RemotingSerializable {
private String consumerGroup;
private String clientId;
private boolean onlyThisBroker = false;
private Set<MessageQueue> mqSet = new HashSet<MessageQueue>();
……
}New Configuration
Configuration in nameserver:
-
scanNotActiveBrokerInterval: scan not active broker intervals, each scan will determine whether the broker heartbeat timeout, the default 5 s.
-
supportActingMaster: If nameserver supports slave acting master mode, when enabled, the slave with the smallest broker id in the masterless state will be replaced with master (i.e. BrokerId =0) in TopicRoute and serve the client in read-only mode. The default is false.
Configuration in broker:
-
enableSlaveActingMaster: enables the slave acting master in broker. The default value is false.
-
enableRemoteEscape: indicates whether remote escape is allowed. The default value is false.
-
brokerHeartbeatInterval: broker sends heartbeat interval (different from registration interval) to nameserver, default is 1s.
-
brokerNotActiveTimeoutMillis: broker inactive timeout, more than the time namesrv is still not yet received the broker heartbeat, then determine the broker offline, the default 10 s.
-
sendHeartbeatTimeoutMillis: broker sends a heartbeat timeout, default 1 s.
-
lockInStrictMode: specifies whether to use strict mode for consuming order message lock queues on the consumer. The default mode is false.
-
skipPreOnline: the broker skips the pre-online process. The default is false.
-
compatibleWithOldNameSrv: Specifies whether to register the old nameserver in compatibility mode. The default value is true. For details about the compatibility mode, see the following.
-
CLI command changes
The client code and admin have not changed.
- Log format or content changes
No
- Are backward and forward compatibility taken into consideration?
Yes, the RIP-32 takes compatibility into account. RIP-32 involves two components, broker and Nameserver, which are compatible as follows:
New nameserver and old broker: The new Nameserver is fully compatible with the old Broker without compatibility problems.
Old nameserver and new broker: The new broker enables the slaveActingMaster, which sends BROKER_HEARTBEAT and GET_BROKER_MEMBER_GROUP requests to the nameserver, but the older Nameserver cannot handle these requests. Therefore, you need to configure compatibleWithOldNameSrv=true in broker config to enable the old namesrv compatibility mode, in which some of the broker's new RPCs are implemented by reusing the old RequestCode:
-
The new lightweight heartbeat will be implemented by reusing QUERY_DATA_VERSION
-
GetBrokerMemberGroup is implemented by reusing GET_ROUTEINFO_BY_TOPIC by adding rmq_sys_ {brokerName} system topic for each broker, Obtain the survival information of the replica group by obtaining the route of the system topic.
Clients have no compatibility issues with new versions of nameserver and broker.
-
Are there deprecated APIs?
Nothing specific.
-
How do we do migration?
Upgrade normally.
In consideration of compatibility, it is recommended to upgrade the nameserver before upgrading the broker.
If the order is to upgrade the broker first and then the nameserver, the broker needs to make the compatibleWithOldNamesrv config true.
We will implement the proposed changes by 2 phases.
- Complete all functions on nameserver
- Complete all functions on the broker except transaction message escape.
- Escape bridge remote delivery is completed by using the built-in producer and consumer.
- Complete the escape of the transaction message.
- Escape bridge replaces the built-in producer and consumer, extracts only the necessary APIs, and converges all APIs to the brokerOutAPI.
No other alternatives