Fix the data output exception when accessing Hive using Spark JDBC So… #2085
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Hisoka-X
approved these changes
Jul 4, 2022
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
#2084
The data read from hive is the same as the column names, not the real data
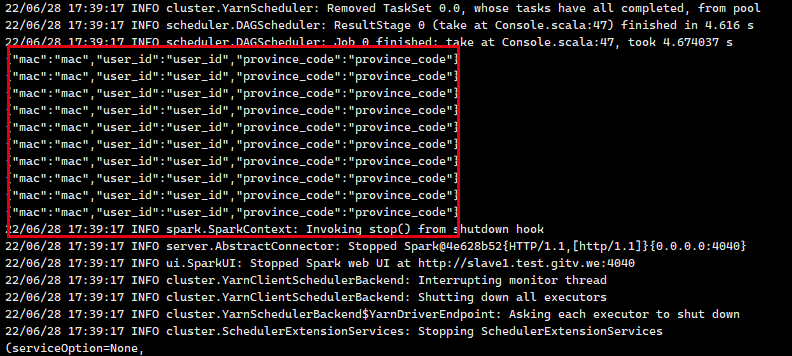
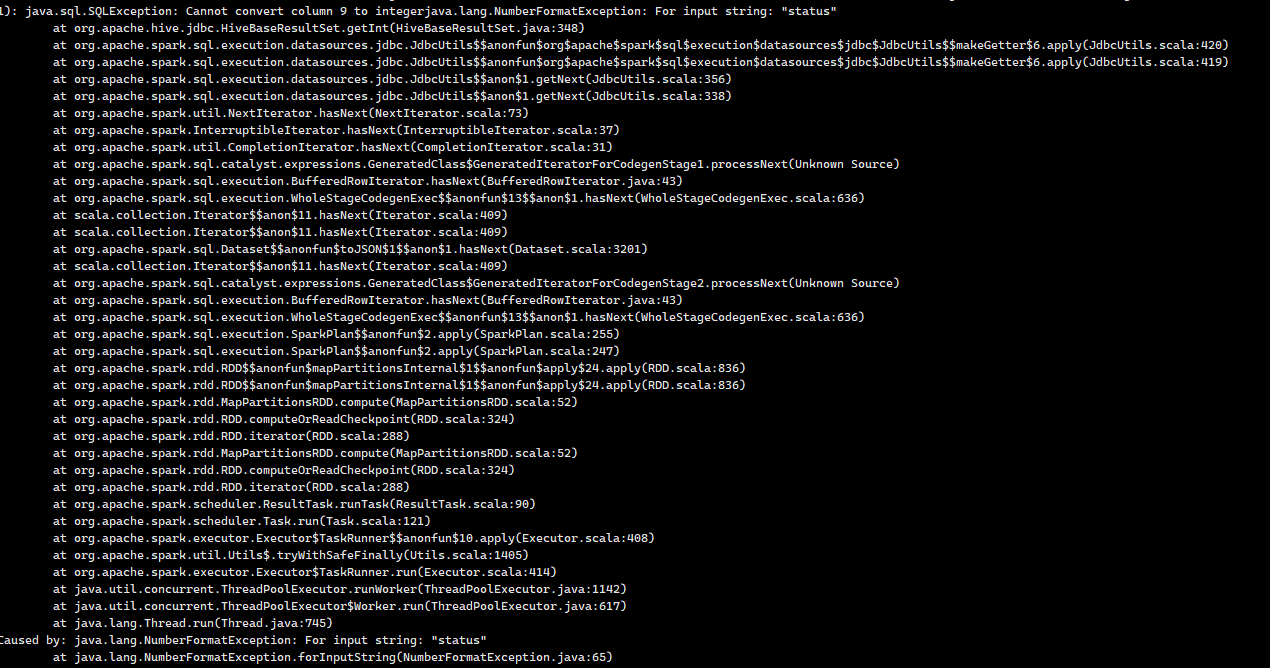

If the queryed field type is numeric, the following exception is reported
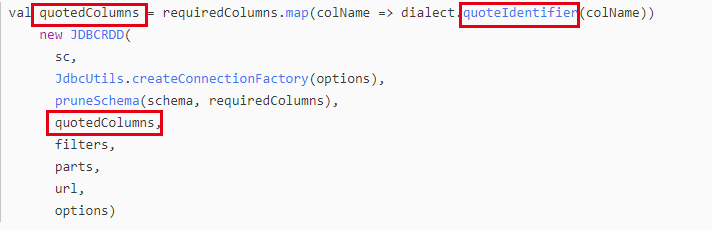
By looking at the Spark source code, it is found that double quotation marks and column names are used when reading data through Jdbc to stitch column names, so it will result in the correct data not being returned
The solution is to re-implement the Hive dialect
Purpose of this pull request
Check list
New License Guide