SPARK-1316. Remove use of Commons IO #226
Closed
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
Merged build triggered. |
|
Merged build started. |
|
Looks good to me if Jenkins is happy. |
|
Jenkins, are you happy yet? |
|
Merged build finished. |
|
All automated tests passed. |
|
I merged this. Thanks! |
pdeyhim
pushed a commit
to pdeyhim/spark-1
that referenced
this pull request
Jun 25, 2014
(This follows from a side point on SPARK-1133, in discussion of the PR: apache#164 ) Commons IO is barely used in the project, and can easily be replaced with equivalent calls to Guava or the existing Spark `Utils.scala` class. Removing a dependency feels good, and this one in particular can get a little problematic since Hadoop uses it too. Author: Sean Owen <sowen@cloudera.com> Closes apache#226 from srowen/SPARK-1316 and squashes the following commits: 21efef3 [Sean Owen] Remove use of Commons IO
shivaram
added a commit
to amplab-extras/spark
that referenced
this pull request
Mar 25, 2015
[SPARKR-236] Use .onLoad instead of .onAttach to initialize SparkR
jongyoul
pushed a commit
to jongyoul/spark
that referenced
this pull request
Apr 9, 2015
This pull requests integrates SparkR, an R frontend for Spark. The SparkR package contains both RDD and DataFrame APIs in R and is integrated with Spark's submission scripts to work on different cluster managers.
Some integration points that would be great to get feedback on:
1. Build procedure: SparkR requires R to be installed on the machine to be built. Right now we have a new Maven profile `-PsparkR` that can be used to enable SparkR builds
2. YARN cluster mode: The R package that is built needs to be present on the driver and all the worker nodes during execution. The R package location is currently set using SPARK_HOME, but this might not work on YARN cluster mode.
The SparkR package represents the work of many contributors and attached below is a list of people along with areas they worked on
edwardt (edwart) - Documentation improvements
Felix Cheung (felixcheung) - Documentation improvements
Hossein Falaki (falaki) - Documentation improvements
Chris Freeman (cafreeman) - DataFrame API, Programming Guide
Todd Gao (7c00) - R worker Internals
Ryan Hafen (hafen) - SparkR Internals
Qian Huang (hqzizania) - RDD API
Hao Lin (hlin09) - RDD API, Closure cleaner
Evert Lammerts (evertlammerts) - DataFrame API
Davies Liu (davies) - DataFrame API, R worker internals, Merging with Spark
Yi Lu (lythesia) - RDD API, Worker internals
Matt Massie (massie) - Jenkins build
Harihar Nahak (hnahak87) - SparkR examples
Oscar Olmedo (oscaroboto) - Spark configuration
Antonio Piccolboni (piccolbo) - SparkR examples, Namespace bug fixes
Dan Putler (dputler) - Dataframe API, SparkR Install Guide
Ashutosh Raina (ashutoshraina) - Build improvements
Josh Rosen (joshrosen) - Travis CI build
Sun Rui (sun-rui)- RDD API, JVM Backend, Shuffle improvements
Shivaram Venkataraman (shivaram) - RDD API, JVM Backend, Worker Internals
Zongheng Yang (concretevitamin) - RDD API, Pipelined RDDs, Examples and EC2 guide
Author: Shivaram Venkataraman <shivaram@cs.berkeley.edu>
Author: Shivaram Venkataraman <shivaram.venkataraman@gmail.com>
Author: Zongheng Yang <zongheng.y@gmail.com>
Author: cafreeman <cfreeman@alteryx.com>
Author: Shivaram Venkataraman <shivaram@eecs.berkeley.edu>
Author: Davies Liu <davies@databricks.com>
Author: Davies Liu <davies.liu@gmail.com>
Author: hlin09 <hlin09pu@gmail.com>
Author: Sun Rui <rui.sun@intel.com>
Author: lythesia <iranaikimi@gmail.com>
Author: oscaroboto <oscarjr@gmail.com>
Author: Antonio Piccolboni <antonio@piccolboni.info>
Author: root <edward>
Author: edwardt <edwardt.tril@gmail.com>
Author: hqzizania <qian.huang@intel.com>
Author: dputler <dan.putler@gmail.com>
Author: Todd Gao <todd.gao.2013@gmail.com>
Author: Chris Freeman <cfreeman@alteryx.com>
Author: Felix Cheung <fcheung@AVVOMAC-119.local>
Author: Hossein <hossein@databricks.com>
Author: Evert Lammerts <evert@apache.org>
Author: Felix Cheung <fcheung@avvomac-119.t-mobile.com>
Author: felixcheung <felixcheung_m@hotmail.com>
Author: Ryan Hafen <rhafen@gmail.com>
Author: Ashutosh Raina <ashutoshraina@users.noreply.github.com>
Author: Oscar Olmedo <oscarjr@gmail.com>
Author: Josh Rosen <rosenville@gmail.com>
Author: Yi Lu <iranaikimi@gmail.com>
Author: Harihar Nahak <hnahak87@users.noreply.github.com>
Closes #5096 from shivaram/R and squashes the following commits:
da64742 [Davies Liu] fix Date serialization
59266d1 [Davies Liu] check exclusive of primary-py-file and primary-r-file
55808e4 [Davies Liu] fix tests
5581c75 [Davies Liu] update author of SparkR
f731b48 [Shivaram Venkataraman] Only run SparkR tests if R is installed
64eda24 [Shivaram Venkataraman] Merge branch 'R' of https://github.com/amplab-extras/spark into R
d7c3f22 [Shivaram Venkataraman] Address code review comments Changes include 1. Adding SparkR docs to API docs generated 2. Style fixes in SparkR scala files 3. Clean up of shell scripts and explanation of install-dev.sh
377151f [Shivaram Venkataraman] Merge remote-tracking branch 'apache/master' into R
eb5da53 [Shivaram Venkataraman] Merge pull request #3 from davies/R2
a18ff5c [Davies Liu] Update sparkR.R
5133f3a [Shivaram Venkataraman] Merge pull request #7 from hqzizania/R3
940b631 [hqzizania] [SPARKR-92] Phase 2: implement sum(rdd)
0e788c0 [Shivaram Venkataraman] Merge pull request #5 from hlin09/doc-fix
3487461 [hlin09] Add tests log in .gitignore.
1d1802e [Shivaram Venkataraman] Merge pull request #4 from felixcheung/r-require
11981b7 [felixcheung] Update R to fail early if SparkR package is missing
c300e08 [Davies Liu] remove duplicated file
b045701 [Davies Liu] Merge branch 'remote_r' into R
19c9368 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into remote_r
f8fa8af [Davies Liu] mute logging when start/stop context
e7104b6 [Davies Liu] remove ::: in SparkR
a1777eb [Davies Liu] move rules into R/.gitignore
e88b649 [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
6e20e71 [Davies Liu] address comments
b433817 [Davies Liu] Merge branch 'master' of github.com:apache/spark into R
a1cedad [Shivaram Venkataraman] Merge pull request #228 from felixcheung/doc
e089151 [Davies Liu] Merge pull request #225 from sun-rui/SPARKR-154_2
463e28c [Davies Liu] Merge pull request #2 from shivaram/doc-fixes
bc2d6d8 [Shivaram Venkataraman] Remove arg from sparkR.stop and update docs
d425363 [Shivaram Venkataraman] Some doc fixes for column, generics, group
1f1a7e0 [Shivaram Venkataraman] Some fixes to DataFrame, RDD, SQLContext docs
104ad4e [Shivaram Venkataraman] Check the right env in exists
cf5cd99 [Shivaram Venkataraman] Remove unused numCols argument
85a50ec [Shivaram Venkataraman] Merge pull request #226 from RevolutionAnalytics/master
3eacfc0 [Davies Liu] fix flaky test
733380d [Davies Liu] update R examples (remove master from args)
b21a0da [Davies Liu] Merge pull request #1 from shivaram/log4j-tests
a1493d7 [Shivaram Venkataraman] Address comments
e1f83ab [Shivaram Venkataraman] Send Spark INFO logs to a file in SparkR tests
58276f5 [Shivaram Venkataraman] Merge branch 'R' of https://github.com/amplab-extras/spark into R
52cc92d [Shivaram Venkataraman] Add license to create-docs.sh
6ff5ea2 [Shivaram Venkataraman] Add instructions to generate docs
1f478c5 [Shivaram Venkataraman] Merge branch 'R' of https://github.com/amplab-extras/spark into R
02b4833 [Shivaram Venkataraman] Add a script to generate R docs (Rd, html) Also fix some issues with our documentation
d6d3729 [Davies Liu] enable spark and pyspark tests
0e5a83f [Davies Liu] fix code style
afd8a77 [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
d87a181 [Davies Liu] fix flaky tests
7100fb9 [Shivaram Venkataraman] Fix libPaths in README
bdf3a14 [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
05e7375 [Davies Liu] sort generics
b44e371 [Shivaram Venkataraman] Include RStudio instructions in README
855537f [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
9fb6af3 [Davies Liu] mark R classes/objects are private
423ea3c [Shivaram Venkataraman] Ignore unknown jobj in cleanup
974e4ea [Davies Liu] fix flaky test
410ec18 [Davies Liu] fix zipRDD() tests
d8b24fc [Davies Liu] disable spark and python tests temporary
ce3ca62 [Davies Liu] fix license check
7da0049 [Davies Liu] fix build
2892e29 [Davies Liu] support R in YARN cluster
ebd4d07 [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
38cbf59 [Davies Liu] fix test of zipRDD()
756ece0 [Shivaram Venkataraman] Update README remove outdated TODO
d436f26 [Davies Liu] add missing files
40d193a [Shivaram Venkataraman] Merge pull request #224 from sun-rui/SPARKR-224-new
1a16cd6 [Davies Liu] rm PROJECT_HOME
56670ef [Davies Liu] rm man page
ba4b80b [Davies Liu] Merge branch 'remote_r' into R
f04080c [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into remote_r
028cbfb [Davies Liu] fix exit code of sparkr unit test
42d8b4c [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
ef26015 [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
a1870e8 [Shivaram Venkataraman] Merge pull request #214 from sun-rui/SPARKR-156_3
cb6e5e3 [Shivaram Venkataraman] Add scripts to start SparkR on windows
8030847 [Shivaram Venkataraman] Set windows file separators, install dirs
05afef0 [Shivaram Venkataraman] Only stop backend JVM if R launched it
95d2de3 [Davies Liu] fix spark-submit with R scripot
baefd9e [Shivaram Venkataraman] Make bin/sparkR use spark-submit As a part of this move the R initialization functions into first.R and first-submit.R
d6f2bdd [Shivaram Venkataraman] Fix run-tests path
ea90fab [Davies Liu] fix spark-submit with R path and sparkR -h
0e2412c [Davies Liu] fix bin/sparkR
9f6aa1f [Davies Liu] Merge branch 'R' of github.com:amplab-extras/spark into R
479e3fe [Davies Liu] change println() to logging
52ca6e5 [Shivaram Venkataraman] Add missing comma
716b16f [Shivaram Venkataraman] Merge branch 'R' of https://github.com/amplab-extras/spark into R
2d235d4 [Shivaram Venkataraman] Build SparkR with Maven profile
aae881b [Davies Liu] fix rat
ff776aa [Shivaram Venkataraman] Fix style
e4f1937 [Shivaram Venkataraman] Remove DFC example
f7b6936 [Davies Liu] remove Spark prefix for class
043959e [Davies Liu] cleanup
ba53b09 [Davies Liu] support R in spark-submit
f403b4a [Davies Liu] rm .travis.yml
c4a5bdf [Davies Liu] run sparkr tests in Spark
e8fc7ca [Davies Liu] fix .gitignore
35e5755 [Davies Liu] reduce size of example data
50bff63 [Davies Liu] add LICENSE header for R sources
facb6e0 [Davies Liu] add .gitignore for .o, .so, .Rd
18e5eed [Davies Liu] update docs
0a0e632 [Davies Liu] move sparkR into bin/
a76472f [Davies Liu] fix path of assembly jar
df3eeea [Davies Liu] move R/examples into examples/src/main/r
3415cc7 [Davies Liu] move Scala source into core/ and sql/
180fc9c [Davies Liu] move scala
014d253 [Davies Liu] delete man pages
49a8133 [Davies Liu] Merge branch 'remote_r' into R
44994c2 [Davies Liu] Moved files to R/
2fc553f [Shivaram Venkataraman] Merge pull request #222 from davies/column2
b043876 [Davies Liu] fix test
5e610cb [Davies Liu] add more API for Column
6f95d49 [Shivaram Venkataraman] Merge pull request #221 from shivaram/sparkr-stop-start
3214c6d [Shivaram Venkataraman] Merge pull request #217 from hlin09/cleanClosureFix
f5d3355 [Shivaram Venkataraman] Merge pull request #218 from davies/merge
70f620c [Davies Liu] address comments
4b1628d [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into merge
3139325 [Shivaram Venkataraman] Merge pull request #212 from davies/toDF
6122e0e [Davies Liu] handle NULL
bc2ff38 [Davies Liu] handle NULL
7f5e70c [Davies Liu] Update SerDe.scala
46454e4 [Davies Liu] address comments
dd52cbc [Shivaram Venkataraman] Merge pull request #220 from shivaram/sparkr-utils-include
662938a [Shivaram Venkataraman] Include utils before SparkR for `head` to work Before this change calling `head` on a DataFrame would not work from the sparkR script as utils would be loaded after SparkR and placed ahead in the search list. This change requires utils to be loaded before SparkR
1bc2998 [Shivaram Venkataraman] Merge pull request #179 from evertlammerts/sparkr-sql
7695d36 [Evert Lammerts] added tests
8190127 [Evert Lammerts] fixed parquetFile signature
d8c8fcc [Shivaram Venkataraman] Merge pull request #219 from shivaram/sparkr-build-final
963c7ee [Davies Liu] Merge branch 'master' into merge
8bff523 [Shivaram Venkataraman] Remove staging repo now that 1.3 is released
e52258f [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into toDF
05b9126 [Shivaram Venkataraman] Merge pull request #215 from davies/agg
8e1497d [Davies Liu] Update DataFrame.R
72adb14 [Davies Liu] Update SQLContext.R
66cc92a [Davies Liu] address commets
55c38bc [Shivaram Venkataraman] Merge pull request #216 from davies/select2
3e0555d [Shivaram Venkataraman] Merge pull request #193 from davies/daemon
0467474 [Davies Liu] add more selecter for DataFrame
9a6be74 [Davies Liu] include grouping columns in agg()
e87bb98 [Davies Liu] improve comment and logging
a6dc435 [Davies Liu] remove dependency of jsonlite
26a3621 [Davies Liu] support date.frame and Date/Time
4e4908a [Davies Liu] createDataFrame from rdd
5757b95 [Shivaram Venkataraman] Merge pull request #196 from davies/die
90f2692 [Shivaram Venkataraman] Merge pull request #211 from hlin09/generics
8583968 [Davies Liu] readFully()
46cea3d [Davies Liu] retry
01aa5ee [Davies Liu] add config for using daemon, refactor
ff948db [hlin09] Remove missingOrInteger.
ecdfda1 [hlin09] Remove duplication.
411b751 [Davies Liu] make RStudio happy
8f8813f [Davies Liu] switch back to use parallel
6bccbbf [hlin09] Move roxygen doc back to implementation.
ffd6e8e [Shivaram Venkataraman] Merge pull request #210 from hlin09/hlin09
471c794 [hlin09] Move getJRDD and broadcast's value to 00-generic.R.
89b886d [hlin09] Move setGeneric() to 00-generics.R.
97dde1a [hlin09] Add a test for access operators.
09ff163 [Shivaram Venkataraman] Merge pull request #204 from cafreeman/sparkr-sql
15a713f [cafreeman] Fix example for `dropTempTable`
dc1291b [hlin09] Add checks for namespace access operators in cleanClosure.
b4c0b2e [Davies Liu] use fork package
3db5649 [cafreeman] Merge branch 'sparkr-sql' of https://github.com/amplab-extras/SparkR-pkg into sparkr-sql
789be97 [Shivaram Venkataraman] Merge pull request #207 from shivaram/err-remove
e60578a [cafreeman] update tests to guarantee row order
5eec6fc [Shivaram Venkataraman] Merge pull request #206 from sun-rui/SPARKR-156_2
3f7aed6 [Sun Rui] Fix minor typos in the function description.
a8cebf0 [Shivaram Venkataraman] Remove print statement in SparkRBackendHandler This print statement is noisy for SQL methods which have multiple APIs (like loadDF). We already have a better error message when no valid methods are found
5e3a576 [Sun Rui] Fix indentation.
f3d99a6 [Sun Rui] [SPARKR-156] phase 2: implement zipWithIndex() of the RDD class.
a582810 [cafreeman] Merge branch 'dfMethods' into sparkr-sql
7a5d6fd [cafreeman] `withColumn` and `withColumnRenamed`
c5fa3b9 [cafreeman] New `select` method
bcb0bf5 [Shivaram Venkataraman] Merge pull request #180 from davies/group
9dd6a5a [Davies Liu] Update SparkRBackendHandler.scala
e6fb8d8 [Davies Liu] improve logging
428a99a [Davies Liu] remove test, catch exception
fef99de [cafreeman] `intersect`, `subtract`, `unionAll`
befbd32 [cafreeman] `insertInto`
9d01bcd [cafreeman] `dropTempTable`
d8c1c09 [Davies Liu] add test to start and stop context multiple times
18c6004 [Shivaram Venkataraman] Merge pull request #201 from sun-rui/SPARKR-156_1
dfb399a [Davies Liu] address comments
f06ccec [Sun Rui] Use mapply() instead of for statement.
3c7674f [Davies Liu] Merge branch 'die' of github.com:davies/SparkR-pkg into die
ac8a852 [Davies Liu] close monitor connection in sparkR.stop()
4d0fb56 [Shivaram Venkataraman] Merge pull request #203 from shivaram/sparkr-hive-fix
62b0760 [Shivaram Venkataraman] Fix test hive context package name
47a613f [Shivaram Venkataraman] Fix HiveContext package name
fb3b139 [Davies Liu] fix tests
d0d4626 [Shivaram Venkataraman] Merge pull request #199 from davies/load
8b7fb67 [Davies Liu] fix HiveContext
bb46832 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into load
e9e2a03 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into group
b875b4f [Davies Liu] fix style
de2abfa [Shivaram Venkataraman] Merge pull request #202 from cafreeman/sparkr-sql
3675fcf [cafreeman] Update `explain` and fixed doc for `toJSON`
5fd9575 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into load
6fac596 [Davies Liu] support Column expression in agg()
f10a24e [Davies Liu] address comments
ff8b005 [cafreeman] 'saveAsParquetFile`
a5c2887 [cafreeman] fix test
3fab0f8 [cafreeman] `showDF`
779c102 [cafreeman] `isLocal`
68b11cf [cafreeman] `toJSON`
0ac4abc [cafreeman] 'explain`
20242c4 [cafreeman] clean up docs
6a1fe64 [Shivaram Venkataraman] Merge pull request #198 from cafreeman/sparkr-sql
198c130 [Shivaram Venkataraman] Merge pull request #200 from shivaram/sparkr-sql-build
870acd4 [Shivaram Venkataraman] Use rc2 explicitly
8b9a963 [cafreeman] Merge branch 'sparkr-sql' of https://github.com/amplab-extras/SparkR-pkg into sparkr-sql
bc90115 [cafreeman] Fixed docs
3865f39 [Sun Rui] [SPARKR-156] phase 1: implement zipWithUniqueId() of the RDD class.
a37fd80 [Davies Liu] Update sparkR.R
d18f9d3 [Shivaram Venkataraman] Remove SparkR snapshot build We now have 1.3.0 RC2 on Apache Staging
8de958d [Davies Liu] Update SparkRBackend.scala
4e0becc [Shivaram Venkataraman] Merge pull request #194 from davies/api
197a79b [Davies Liu] add HiveContext (commented)
32aa01d [Shivaram Venkataraman] Merge pull request #191 from felixcheung/doc
5073e07 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into load
7918634 [cafreeman] Fix test
acea146 [cafreeman] remove extra line
74269f3 [cafreeman] Merge branch 'dfMethods' into sparkr-sql
cd7ac8a [Shivaram Venkataraman] Merge pull request #197 from cafreeman/sparkr-sql
494a4dd [cafreeman] update export
e14c328 [cafreeman] `selectExpr`
32b37d1 [cafreeman] Fixed indent in `join` test.
2e7b190 [Felix Cheung] small update on yarn deploy mode.
8ff29d6 [Davies Liu] fix tests
12a6db2 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into api
294ca4a [cafreeman] `join`, `sort`, and `filter`
4fa6343 [cafreeman] Refactor `join` generic for use with `DataFrame`
3f22c8d [Shivaram Venkataraman] Merge pull request #195 from cafreeman/sparkr-sql
2b6f980 [Davies Liu] shutdown the JVM after R process die
e8639c3 [cafreeman] New 1.3 repo and updates to `column.R`
ed9a89f [Davies Liu] address comments
03bcf20 [Davies Liu] Merge branch 'group' of github.com:davies/SparkR-pkg into group
39c253d [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into group
98cc97a [Davies Liu] fix test and docs
e2d144a [Felix Cheung] Fixed small typos
3beadcf [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into api
06cbc2d [Davies Liu] launch R worker by a daemon
8a676b1 [Shivaram Venkataraman] Merge pull request #188 from davies/column
524c122 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into column
f798402 [Davies Liu] Update column.R
1d0f2ae [Davies Liu] Update DataFrame.R
03402eb [Felix Cheung] Updates as per feedback on sparkR-submit
76cf2e0 [Shivaram Venkataraman] Merge pull request #192 from cafreeman/sparkr-sql
1955a09 [cafreeman] return object instead of a list of one object
f585929 [cafreeman] Fix brackets
e998356 [cafreeman] define generic for 'first' in RDD API
71d66a1 [Davies Liu] fix first(0
8ec21af [Davies Liu] fix signature
acae527 [Davies Liu] refactor
d7b17a4 [Davies Liu] fix approxCountDistinct
7dfe27d [Davies Liu] fix cyclic namespace dependency
8caf5bb [Davies Liu] use S4 methods
5c0bb24 [Felix Cheung] Doc updates: build and running on YARN
773baf0 [Zongheng Yang] Merge pull request #178 from davies/random
862f07c [Shivaram Venkataraman] Merge pull request #190 from shivaram/SPARKR-79
b457833 [Shivaram Venkataraman] Merge pull request #189 from shivaram/stdErrFix
f7caeb8 [Davies Liu] Update SparkRBackend.scala
8c4deae [Shivaram Venkataraman] Remove unused function
6e51c7f [Shivaram Venkataraman] Fix stderr redirection on executors
7afa4c9 [Shivaram Venkataraman] Merge pull request #186 from hlin09/funcDep3
4d36ab1 [hlin09] Add tests for broadcast variables.
3f57e56 [hlin09] Fix comments.
7b72487 [hlin09] Fix comments.
ae05bf1 [Davies Liu] Merge branch 'sparkr-sql' of github.com:amplab-extras/SparkR-pkg into column
abb4bb9 [Davies Liu] add Column and expression
eb8ac11 [Shivaram Venkataraman] Set Spark version 1.3.0 in Windows build
5c72e73 [Davies Liu] wait atmost 100 seconds
e425437 [Shivaram Venkataraman] Merge pull request #177 from lythesia/master
a00f502 [lythesia] fix indents
0346e5f [Davies Liu] address comment
6134649 [Shivaram Venkataraman] Merge pull request #187 from cafreeman/sparkr-sql
ad0935e [lythesia] minor fixes
b0e7f73 [cafreeman] Update `sampleDF` test
7b0d070 [lythesia] keep partitions check
889c265 [cafreeman] numToInt utility function
27dd3a0 [lythesia] modify tests for repartition
cad0f0c [cafreeman] Fix docs and indents
2808dcf [cafreeman] Three more DataFrame methods
5ef66fb [Davies Liu] send back the port via temporary file
3b46429 [Davies Liu] Merge branch 'master' of github.com:amplab-extras/SparkR-pkg into random
798f453 [cafreeman] Merge branch 'sparkr-sql' into dev
9aa4acf [Shivaram Venkataraman] Merge pull request #184 from davies/socket
020bce8 [Shivaram Venkataraman] Merge pull request #183 from cafreeman/sparkr-sql
222e06b [cafreeman] Lazy evaluation and formatting changes
e776324 [Davies Liu] fix import
211cc15 [cafreeman] Merge branch 'sparkr-sql' into dev
3351afd [hlin09] Replaces getDependencies with cleanClosure, to serialize UDFs to workers.
e7c56d6 [lythesia] fix random partition key
50c74b1 [Davies Liu] address comments
083c89f [cafreeman] Remove commented lines an unused import
dfa119b [hlin09] Improve the coverage of processClosure.
a41c9b9 [cafreeman] Merge branch 'wrapper' into sparkr-sql
1cd714f [cafreeman] Wrapper function docs.
db0cd9e [cafreeman] Clean up for wrapper functions
818c19f [cafreeman] Update schema-related functions
a57884e [cafreeman] Remove unused import
d72e830 [cafreeman] Add wrapper for `StructField` and `StructType`
2ea2ecf [lythesia] use generic arg
09b9512 [hlin09] add docs
f4f077c [hlin09] Add recursive cleanClosure for function access.
f84ad27 [hlin09] Merge remote-tracking branch 'upstream/master' into funcDep2
5300766 [Shivaram Venkataraman] Merge pull request #185 from hlin09/hlin09
07aa7c0 [hlin09] Unifies the implementation of lapply with lapplyParitionsWithIndex.
f4dbb0b [Davies Liu] use socket in worker
8282c59 [Davies Liu] Update DataFrame.R
ba495a8 [Davies Liu] Update NAMESPACE
36dffb3 [cafreeman] Add 'head` and `first`
534a95f [cafreeman] Schema-related methods
64f488d [cafreeman] Cache and Persist Methods
30d71fd [cafreeman] Standardize method arguments for DataFrame methods
785898b [Shivaram Venkataraman] Merge pull request #182 from cafreeman/sparkr-sql
2619003 [Shivaram Venkataraman] Merge pull request #181 from cafreeman/master
a9bbe0b [cafreeman] Update existing SparkSQL functions
8c241a3 [cafreeman] Merge with master, include changes to method args
68d6de4 [cafreeman] Fix typos
8d2ec6e [Davies Liu] add sum/max/min/avg/mean
774e687 [Davies Liu] add missing API in SQLContext
1e72b4b [Davies Liu] missing API in SQLContext
3294949 [Chris Freeman] Restore `rdd` argument to `getJRDD`
3a58ebc [Davies Liu] rm unrelated file
8bd93b5 [Davies Liu] fix signature
c652b4c [cafreeman] Update method signatures to use generic arg
48c8827 [Davies Liu] update NAMESPACE
84e2d8c [Davies Liu] groupBy and agg()
7c3ddbd [Davies Liu] create jmode in JVM
9465426 [Davies Liu] load and save
982f342 [lythesia] fix numeric issue
7651d84 [lythesia] fix coalesce
4e712e1 [Davies Liu] use random port in backend
041d22b [Shivaram Venkataraman] Merge pull request #172 from cafreeman/sparkr-sql
0d07770 [cafreeman] Added `limit` and updated `take`
301d8e5 [cafreeman] Remove extraneous map functions
0387db2 [cafreeman] Remove colNames
04c4b65 [lythesia] add repartition/coalesce
231deab [cafreeman] Change reserialize to serializeToBytes
acf7e1a [cafreeman] Rework the Scala to R DataFrame Conversion
481ae37 [cafreeman] Updated stale comments and standardized arg names
21d4a97 [hlin09] Adds cleanClosure to capture the function closures.
d24ffb4 [hlin09] Merge remote-tracking branch 'upstream/master' into funcDep2
8be02de [hlin09] Revert "loop 1-12 test pass."
fddb9cc [hlin09] Revert "add docs"
f8ef0ab [hlin09] Revert "More docs"
8e4b3da [hlin09] Revert "More docs"
57e005b [hlin09] Revert "fix tests."
c10148e [Shivaram Venkataraman] Merge pull request #174 from shivaram/sparkr-runner
910e3be [Shivaram Venkataraman] Add a timeout for initialization Also move sparkRBackend.stop into a finally block
bf52b17 [Shivaram Venkataraman] Merge remote-tracking branch 'amplab-sparkr/master' into sparkr-runner
08102b0 [Shivaram Venkataraman] Merge pull request #176 from lythesia/master
9c77b20 [Chris Freeman] Merge pull request #2 from shivaram/sparkr-sql
179ab38 [lythesia] add try counts and increase time interval
71a73b2 [Shivaram Venkataraman] Use a getter for serialization mode This change encapsulates the semantics of serialization mode for RDDs inside a getter function. For PipelinedRDDs if a backing JavaRDD is available we use that else we fall back to a default serialization mode
06bf250 [Shivaram Venkataraman] Merge pull request #173 from shivaram/windows-space-fix
88bf97f [Shivaram Venkataraman] Create SparkContext for R shell launch
f9268d9 [Shivaram Venkataraman] Fix code review comments
e6ad12d [Shivaram Venkataraman] Update comment describing sparkR-submit
17eda4c [Shivaram Venkataraman] Merge pull request #175 from falaki/docfix
ba2b72b [Hossein] Spark 1.1.0 is default
4cd7d3f [lythesia] retry backend connection
749e2d0 [Hossein] Updated README
bc04cf4 [Shivaram Venkataraman] Use SPARKR_BACKEND_PORT in sparkR.R as default Change SparkRRunner to use EXISTING_SPARKR_BACKEND_PORT to differentiate between the two
22a19ac [Shivaram Venkataraman] Use a semaphore to wait for backend to initalize Also pick a random port to avoid collisions
7f1f0f8 [cafreeman] Move comments to fit 100 char line length
8b84e4e [cafreeman] Make if statements more explicit
ce5d5ab [cafreeman] New tests for Union and Object File
b063320 [cafreeman] Changed 'serialized' to 'serializedMode'
0981dff [Zongheng Yang] Merge pull request #168 from sun-rui/SPARKR-153_2
86fc639 [Shivaram Venkataraman] Move sparkR-submit into pkg/inst
fd8f8a9 [Shivaram Venkataraman] Merge branch 'hqzizania-master'
a33dbea [Shivaram Venkataraman] Merge branch 'master' of https://github.com/hqzizania/SparkR-pkg into hqzizania-master
384e6e2 [Shivaram Venkataraman] Merge pull request #171 from hlin09/hlin09
1f5a6ac [hlin09] fixed comments
7f7596a [cafreeman] Additional handling for "row" serialization
8c3b8c5 [cafreeman] Add test for UnionRDD on "row" serialization
b1141f8 [cafreeman] Fixed formatting issues.
5db30bf [cafreeman] Changed serialized from bool to string
2f0c0b8 [cafreeman] Add check for serialized type
d243dfb [cafreeman] Clean up code
5ff63a2 [cafreeman] Change test from boolean to string
77fec1a [cafreeman] Updated .Rd files
9224989 [cafreeman] Various updates for DataFrame to RRDD
26af62b [cafreeman] DataFrame to RRDD
e004481 [cafreeman] Update UnionRDD test
5292be7 [hlin09] Adds support of pipeRDD().
e2a7560 [Shivaram Venkataraman] Merge pull request #170 from cafreeman/sparkr-sql
5d537f4 [cafreeman] Add pairRDD to Description
b6fa88e [cafreeman] Updating to current master
0cda231 [Sun Rui] [SPARKR-153] phase 2: implement aggregateByKey() and foldByKey().
95ee6b4 [Shivaram Venkataraman] Merge remote-tracking branch 'amplab-sparkr/master' into sparkr-runner
67fbc60 [Shivaram Venkataraman] Add support for SparkR shell to use spark-submit This ensures that SparkConf options are read in both in batch and interactive modes
2271030 [Shivaram Venkataraman] Merge pull request #167 from sun-rui/removePartionByInRDD
7fcb46a [Sun Rui] Remove partitionBy() in RDD.
52f94c4 [Shivaram Venkataraman] Merge pull request #160 from lythesia/master
59e2d54 [lythesia] merge with upstream
5836650 [Zongheng Yang] Merge pull request #163 from sun-rui/SPARKR-153_1
141723e [Sun Rui] fix comments.
f73a07e [Shivaram Venkataraman] Merge pull request #165 from shivaram/sparkr-sql-build
10ffc6d [Shivaram Venkataraman] Set Spark version to 1.3 using staging dependency Also fix the maven build
c91ede2 [Shivaram Venkataraman] Merge pull request #164 from hlin09/hlin09
9d335a9 [hlin09] Makes git to ignore Eclipse meta files.
94066bf [Sun Rui] [SPARKR-153] phase 1: implement fold() and aggregate().
9c391c7 [hqzizania] Merge remote-tracking branch 'upstream/master'
5f29551 [hqzizania] modified: pkg/R/RDD.R modified: pkg/R/context.R
d968664 [lythesia] fix comment
7972858 [Shivaram Venkataraman] Merge pull request #159 from sun-rui/SPARKR-150_2
7690878 [lythesia] separate out pair RDD functions
f4573c1 [Sun Rui] Use reduce() instead of sortBy().take() to get the ordered elements.
63e62ed [Sun Rui] [SPARKR-150] phase 2: implement takeOrdered() and top().
050390b [Shivaram Venkataraman] Fix bugs in inferring R file
8398f2e [Shivaram Venkataraman] Add sparkR-submit helper script Also adjust R file path for YARN cluster mode
bd6705b [Zongheng Yang] Merge pull request #154 from sun-rui/SPARKR-150
c7964c9 [Sun Rui] Merge with upstream master.
7feac38 [Sun Rui] Use default arguments for sortBy() and sortKeyBy().
de2bfb3 [Sun Rui] Fix minor comments and add more test cases.
0c6e071 [Zongheng Yang] Merge pull request #157 from lythesia/master
f5038c0 [lythesia] pull out anonymous functions in groupByKey
ba6f044 [lythesia] fixes for reduceByKeyLocally
343b6ab [Oscar Olmedo] Export sparkR.stop Closes #156 from oscaroboto/master
25639cf [Shivaram Venkataraman] Replace tabs with spaces
bb25920 [Shivaram Venkataraman] Merge branch 'dputler-master'
fd836db [hlin09] fix tests.
24a7f13 [hlin09] More docs
a465165 [hlin09] More docs
6ad4fc3 [hlin09] add docs
b082a35 [lythesia] add reduceByKeyLocally
7ca6512 [Shivaram Venkataraman] First cut of SparkRRunner
193f5fe [hlin09] loop 1-12 test pass.
345f1b8 [dputler] [SPARKR-195] Implemented project style guidelines for if-else statements
8043559 [Sun Rui] Add a TODO to use binary search in the range partitioner.
91b2fd6 [Sun Rui] Add more test cases.
e8ebbe4 [Shivaram Venkataraman] Merge pull request #152 from cafreeman/sparkr-sql
0c53d6c [dputler] Data frames now coerced to lists, and messages issued for a data frame or matrix on how they are parallelized
6d57ec0 [cafreeman] Remove json test file since we're using a temp
ac1ef09 [cafreeman] Update registerTempTable test
d9da451 [Sun Rui] [SPARKR-150] phase 1: implement sortBy() and sortByKey().
08ff30b [Shivaram Venkataraman] Merge pull request #153 from hqzizania/master
9767e8e [hqzizania] modified: pkg/man/collect-methods.Rd
5d69f0a [hqzizania] modified: pkg/R/RDD.R
4914091 [hqzizania] modified: pkg/inst/tests/test_rdd.R
742a68b [cafreeman] Update test_sparkRSQL.R
a95823e [hqzizania] modified: pkg/R/RDD.R
2d04526 [cafreeman] Formatting
fae9bdd [cafreeman] Renamed to SQLUtils.scala
39888ea [Chris Freeman] Update test_sparkSQL.R
fce2453 [cafreeman] Updated documentation for SQLContext
13fbf12 [cafreeman] Regenerated .Rd files
51ecf41 [cafreeman] Updated Scala object
30d7337 [cafreeman] Added SparkSQL test
74b3ed6 [cafreeman] Incorporate code feedback
554bda0 [Zongheng Yang] Merge pull request #147 from shivaram/sparkr-ec2-fixes
a5f4f8f [cafreeman] Squashed commit of the following:
f34bb88 [Shivaram Venkataraman] Remove profiling information from this PR
c662f29 [Zongheng Yang] Merge pull request #146 from shivaram/spark-1.2-build
21e9b74 [Zongheng Yang] Merge pull request #145 from lythesia/master
76f6b9e [Shivaram Venkataraman] Merge pull request #149 from hqzizania/master
1c2dbec [lythesia] minor fix for refactoring join code
5b380d3 [hqzizania] modified: pkg/man/combineByKey.Rd modified: pkg/man/groupByKey.Rd modified: pkg/man/partitionBy.Rd modified: pkg/man/reduceByKey.Rd
98794fe [hqzizania] modified: pkg/R/RDD.R
b66534d [Zongheng Yang] Merge pull request #144 from shivaram/fix-rd-files
60da1df [Shivaram Venkataraman] Initialize timing variables
179aa75 [Shivaram Venkataraman] Bunch of fixes for longer running jobs 1. Increase the timeout for socket connection to wait for long jobs 2. Add some profiling information in worker.R 3. Put temp file writes before stdin writes in RRDD.scala
06d99f0 [Shivaram Venkataraman] Fix URI to have right number of slashes
add97f5 [Shivaram Venkataraman] Use URL encode to create valid URIs for jars
4eec962 [lythesia] refactor join functions
73430c6 [Shivaram Venkataraman] Make SparkR work on paths with spaces on Windows
aaf8f47 [Shivaram Venkataraman] Exclude hadoop client from Spark dependency
227ee42 [Zongheng Yang] Merge pull request #141 from shivaram/SPARKR-140
ac5ceb1 [Shivaram Venkataraman] Fix code review comments
32394de [Shivaram Venkataraman] Regenerate Rd files for SparkR This fixes a number of issues in SparkR man pages. The main changes are 1. Don't export or generate docs for PipelineRDD 2. Fix variable names for Filter, count to match base methods 3. Document missing arguments for sparkR.init, print.jobj etc.
e157bf6 [Shivaram Venkataraman] Use prev_serialized to track if JRDD is serialized This changes introduces a new variable in PipelineRDD environment to track if the prev_jrdd is serialized or not.
7428a7e [Zongheng Yang] Merge pull request #143 from shivaram/SPARKR-181
7dd1797 [Shivaram Venkataraman] Address code review comments
8f81c45 [Shivaram Venkataraman] Remove roxygen export for PipelinedRDD
0cb90f1 [Zongheng Yang] Merge pull request #142 from shivaram/SPARKR-169
d1c6e6c [Shivaram Venkataraman] Buffer stderr from R and return it on Exception This change buffers the last 100 lines from R process and passes these lines back to the driver if we have an exception. This will help users debug why their tasks failed on the cluster
d6c1393 [Shivaram Venkataraman] Suppress warnings from normalizePath
a382835 [Shivaram Venkataraman] Fix serialization tracking in pipelined RDDs When creating a pipeline RDD, we need to check if the JavaRDD belonging to the parent is serialized.
da39529 [Zongheng Yang] Merge pull request #140 from sun-rui/SPARKR-183
2814caa [Sun Rui] Merge with upstream master.
cd2a5b3 [Sun Rui] Add reference to Nagle's algorithm and clean code.
52356b6 [Shivaram Venkataraman] Merge pull request #139 from shivaram/fix-backend-exit
97e5a1f [Sun Rui] [SPARKR-183] Fix the issue that parallelize collect tests are slow.
a9f8e8e [Shivaram Venkataraman] Merge pull request #138 from concretevitamin/fix-collect-test
125ae43 [Shivaram Venkataraman] Fix SparkR backend to exit in more cases This change has two fixes 1. When the workspace is saved (from R or RStudio) the backend connection seems to be closed before the finalizer is run. In such cases we reopen the connection and stop the backend 2. With RStudio when R is restarted, there are port-conflicts which appear due to a race condition between the JVM and rsession restart. This change adds a 1 sec sleep to avoid this race.
12c102a [Zongheng Yang] Simplify a unit test.
9c0637a [Zongheng Yang] Merge pull request #137 from shivaram/fix-docs
0df0e18 [Shivaram Venkataraman] Fix documentation for includePackage
7549f88 [Zongheng Yang] Merge pull request #136 from shivaram/man-updates
7edbe46 [Shivaram Venkataraman] Add missing man pages
9cb9567 [Shivaram Venkataraman] Merge pull request #131 from shivaram/rJavaExpt
1fa722e [Shivaram Venkataraman] Rename to SerDe now
2fcb051 [Shivaram Venkataraman] Rename to SerDeJVMR
d112cf0 [Shivaram Venkataraman] Style fixes
9fd01cc [Shivaram Venkataraman] Remove unnecessary braces
0881931 [Shivaram Venkataraman] Some more style fixes
f00b531 [Shivaram Venkataraman] Address code review comments. Big changes include style fixes throughout for named arguments
c09ba05 [Shivaram Venkataraman] Change jobj id to be just an integer Add a new print.jobj that gets the class name and prints it Also add a utility function isInstanceOf
be05b16 [Shivaram Venkataraman] Check if context, connection exist before stopping
d596a23 [Shivaram Venkataraman] Address code review comments
396e7ac [Shivaram Venkataraman] Changes to make new backend work on Windows This change uses file.path to construct the Java binary path in a OS agnostic way and uses system2 to handle quoting binary paths correctly. Tests pass on Mac OSX and a Windows EC2 instance.
e7a4e03 [Shivaram Venkataraman] Remove unused file BACKEND.md
62f380b [Shivaram Venkataraman] Update worker.R to use new deserialization call
8b9c4e6 [Shivaram Venkataraman] Change RDD name, setName to use new backend
6dcd5c5 [Shivaram Venkataraman] Merge branch 'master' of https://github.com/amplab-extras/SparkR-pkg into rJavaExpt
0873397 [Shivaram Venkataraman] Refactor java object tracking into a new singleton. Also add comments describing each class
95db964 [Shivaram Venkataraman] Add comments, cleanup new R code
bcd4258 [Zongheng Yang] Merge pull request #130 from lythesia/master
74dbc5e [Sun Rui] Match method using parameter types.
7ad4a4d [Sun Rui] Use 1 char to represent types on the backend->client direction.
bace887 [Sun Rui] Use an integer count for the backend java object ID because Uniqueness isn't guaranteed by System.identityHashCode().
b38d04f [Sun Rui] Use 1 char to represent types on the client -> backend direction.
f88bc68 [lythesia] Merge branch 'master' of github.com:lythesia/SparkR-pkg
71d41f5 [lythesia] add test case for fullOuterJoin
eb4f423 [lythesia] --amend
cffecc5 [lythesia] add test case for fullOuterJoin
a547dd2 [Shivaram Venkataraman] Move classTag, rddRef into newJObject call This avoids them getting eagerly garbage collected
1255391 [Shivaram Venkataraman] Add a finalizer for jobj objects This enables Java objects to be garbage collected on the backend when they are no longer referenced in R. Also rename newJava to newJObject to be more consistent with callJMethod
70fa409 [Sun Rui] Add YARN Conf Dir to the class path when launching the backend.
a1108ca [lythesia] add fullOuterJoin in RDD.R
2152727 [Shivaram Venkataraman] Remove empty file
cd08bee [Shivaram Venkataraman] Update all functions to use new backend All unit tests pass.
9de49b7 [Shivaram Venkataraman] Add high level calls for methods, constructors Also update BACKEND.md
5a97ea4 [Shivaram Venkataraman] Add jobj S3 class that holds backend refs
e071d3e [Shivaram Venkataraman] Change SparkRBackend to use general method calls This change uses a custom protocl + JNI to invoke any method on a given object type. Also update serializers, deserializers to make code more concise
49f0404 [Shivaram Venkataraman] Merge pull request #129 from lythesia/master
7f8cd82 [lythesia] update man
4715ed2 [Yi Lu] Update RDD.R
5a53801 [lythesia] fix name,setName
4f3870b [lythesia] add name,setName in RDD.R
1c25700 [Shivaram Venkataraman] Merge pull request #128 from sun-rui/SPARKR-165
c8507d8 [Sun Rui] [SPARKR-165] IS_SCALAR is not present in R before 3.1
2cff2bd [Sun Rui] Add function to invoke Java method.
7a31da1 [Shivaram Venkataraman] Merge branch 'dputler-master'. Closes #119
0ceba82 [Shivaram Venkataraman] Merge branch 'master' of https://github.com/dputler/SparkR-pkg into dputler-master
735f70c [Shivaram Venkataraman] Merge pull request #125 from 7c00/rawcon
fccfe6c [Shivaram Venkataraman] Merge pull request #127 from sun-rui/SPARKR-164
387bd57 [Sun Rui] [SPARKR-164] Temporary files used by SparkR accumulat as time goes on.
5f2268f [Shivaram Venkataraman] Add support to stop backend
5f745c0 [Shivaram Venkataraman] Update notes in backend
22015c1 [Shivaram Venkataraman] Add first cut of SparkR Backend
52821da [Todd Gao] switch the order of packages and function deps
d7b0007 [Todd Gao] remove memCompress
cb6873e [Shivaram Venkataraman] Merge pull request #126 from sun-rui/SPARKR-147
c5962eb [Todd Gao] further optimize using rawConnection
f04c6e0 [Sun Rui] [SPARKR-147] Support multiple directories as input to textFile.
b7de604 [Todd Gao] optimize execFunctionDeps loading in worker.R
4d4fc30 [Shivaram Venkataraman] Merge pull request #122 from cafreeman/master
b508877 [cafreeman] Update SparkR_IDE_Setup.sh
21ed9d7 [cafreeman] Update build.sbt
f73ec16 [cafreeman] Delete SparkR_IDE_Setup_Guide.md
d63b026 [cafreeman] Delete SparkR_Quick_Start_Guide.md
6e6cb62 [cafreeman] Update SparkR_IDE_Setup.sh
bc6042b [cafreeman] Update build.sbt
a8197d5 [cafreeman] Merge remote-tracking branch 'upstream/master'
d671564 [Zongheng Yang] Merge pull request #123 from shivaram/jcheck-void
76b8d00 [Zongheng Yang] Merge pull request #124 from shivaram/master
b690d58 [Shivaram Venkataraman] Specify how to change Spark versions in README
0fb003d [Shivaram Venkataraman] Merge branch 'master' of https://github.com/amplab-extras/SparkR-pkg into jcheck-void
1c227b4 [Shivaram Venkataraman] Also add a check in context.R
96812b6 [Shivaram Venkataraman] Check for exceptions after void method calls
f5c216d [cafreeman] Merge remote-tracking branch 'upstream/master'
90c8933 [Zongheng Yang] Merge pull request #121 from shivaram/fix-sort-order
bd0e3b4 [Shivaram Venkataraman] Fix saveAsTextFile test case
2e55f67 [Shivaram Venkataraman] Merge branch 'master' of https://github.com/amplab-extras/SparkR-pkg into fix-sort-order
f10c607 [Shivaram Venkataraman] Merge pull request #118 from sun-rui/saveAsTextFile
6c9bfc0 [Sun Rui] Merge remote-tracking branch 'SparkR_upstream/master' into saveAsTextFile
6faedbe [cafreeman] Update SparkR_IDE_Setup_Guide.md
57008bc [cafreeman] Update SparkR_IDE_Setup.sh
bb1c17d [cafreeman] Update SparkR_IDE_Setup.sh
538bfdb [cafreeman] Update SparkR_Quick_Start_Guide.md
31322c6 [cafreeman] Update SparkR_IDE_Setup.sh
ca3f593 [Sun Rui] Refactor RRDD code.
df58d95 [cafreeman] Update SparkR_Quick_Start_Guide.md
b488c88 [cafreeman] Rename Spark_IDE_Setup.sh to SparkR_IDE_Setup.sh
b2545a4 [cafreeman] Added IDE Setup Guide
0ffb5de [cafreeman] Merge branch 'master' of https://github.com/cafreeman/SparkR-pkg
bd8fbfb [cafreeman] Merge remote-tracking branch 'upstream/master'
98efa5b [cafreeman] Added Quick Start Guide
3cf88f2 [Shivaram Venkataraman] Sort lists before comparing in unit tests Since Spark doesn't guarantee that shuffle results will always be in the same order, we need to sort the results before comparing for deterministic behavior
d621dbc [Shivaram Venkataraman] Merge pull request #120 from sun-rui/objectFile
c4a44d7 [Sun Rui] Add @seealso in comments and extract some common code into a function.
724e3a4 [cafreeman] Update Spark_IDE_Setup.sh
8153e5a [Sun Rui] [SPARKR-146] Support read/save object files in SparkR.
17f9909 [cafreeman] Update Spark_IDE_Setup.sh
a9eb080 [cafreeman] IDE Shell Script
64d800c [dputler] Merge remote branch 'upstream/master'
1fbdb2e [dputler] Added the ability for the user to specify a text file location throught the use of tilde expansion or just the file name if it is in the working directory.
d83c017 [Shivaram Venkataraman] Merge pull request #113 from sun-rui/stringHashCodeInC
a7d9cdb [Sun Rui] Fix build on Windows.
7d81b05 [Shivaram Venkataraman] Merge pull request #114 from hlin09/hlin09
47c4bb7 [hlin09] fix reviews
a457f7f [Shivaram Venkataraman] Merge pull request #116 from dputler/master
0fa48d1 [Shivaram Venkataraman] Merge pull request #117 from sun-rui/keyBy
85cfeb4 [Sun Rui] [SPARKR-144] Implement saveAsTextFile() in the RDD class.
09083d9 [Sun Rui] Add keyBy() to the RDD class.
caad5d7 [dputler] Adding the script to install software on the Cloudera Quick Start VM.
dca3d05 [hlin09] Minor fix.
ece5f7d [hlin09] Merge remote-tracking branch 'upstream/master' into hlin09
a40874b [hlin09] Use extendible accumulators aggregate the cogroup values.
d0347ce [Zongheng Yang] Merge pull request #112 from sun-rui/outer_join
492f76e [Sun Rui] Refine code and add description.
ba01358 [Shivaram Venkataraman] Merge pull request #115 from sun-rui/SPARKR-130
5c8e46e [Sun Rui] Fix per the review comments.
7190a2c [Sun Rui] Update comment to add a reference to storage levels.
1da705e [hlin09] Fix the review comments.
c4b77be [Sun Rui] [SPARKR-130] Add persist(storageLevel) API to RDD.
b424a1a [hlin09] Add function cogroup().
9770312 [Shivaram Venkataraman] Merge pull request #111 from hlin09/hlin09
cead7df [hlin09] fix review comments.
54f712e [Sun Rui] Implement string hash code in C.
425f0c6 [Sun Rui] Add leftOuterJoin() and rightOuterJoin() to the RDD class.
39509c7 [hlin09] add Rd file for foreach and foreachPartition.
63d6ac7 [hlin09] Adds function foreach() and foreachPartition().
9c954df [Zongheng Yang] Merge pull request #105 from sun-rui/join
c71228d [Sun Rui] Pre-allocate list with fixed length. Add test case for join() using string key.
bc3e9f6 [Shivaram Venkataraman] Merge pull request #108 from concretevitamin/take-optimize
c06fc90 [Zongheng Yang] Fix: only optimize for unserialized dataset case.
d399aeb [Zongheng Yang] Apply size-capping on logical representation instead of physical.
e4217dd [Zongheng Yang] Merge pull request #107 from shivaram/master
7952180 [Shivaram Venkataraman] Copy, use getLocalDirs from Spark Utils.scala
08e24c3 [Zongheng Yang] Merge pull request #109 from hlin09/hlin09
97d4e02 [Zongheng Yang] Min() upper-bound size with actual size.
bb779bf [hlin09] Rename the filter function to filterRDD to follow the API consistency. Filter() is also kept.
ce1661f [Zongheng Yang] Fix slow take(): deserialize only up to necessary # of elements.
4dca9b1 [Shivaram Venkataraman] Merge pull request #106 from hlin09/hlin09
1220d92 [hlin09] Adds function numPartitions().
2326a65 [Shivaram Venkataraman] Use SPARK_LOCAL_DIRS to create tmp files
e119757 [hlin09] Minor fix.
9c24c8b [hlin09] Adds function countByKey().
48fce67 [hlin09] Adds countByValue().
6679eef [Sun Rui] Update documentation for join().
70586b4 [Sun Rui] Add join() to the RDD class.
e6fb999 [Zongheng Yang] Merge pull request #103 from shivaram/rlibdir-fix
a21f146 [Shivaram Venkataraman] Merge pull request #102 from hlin09/hlin09
32eb619 [Shivaram Venkataraman] Merge pull request #104 from sun-rui/add_keys_values
d8692e9 [Sun Rui] Add keys() and values() for the RDD class.
18b9be1 [Shivaram Venkataraman] Allow users to set where SparkR is installed This also adds a warning if somebody tries to call sparkR.init multiple times.
a17f135 [hlin09] Adds tests for flatMap and flatMapValues.
4bcf59b [hlin09] Adds function flatMapValues.
4a193ef [Zongheng Yang] Merge pull request #101 from ashutoshraina/master
60d22f2 [Ashutosh Raina] changed sbt version
5400793 [Zongheng Yang] Merge pull request #98 from shivaram/windows-fixes-build
36d61a7 [Shivaram Venkataraman] Merge pull request #97 from hlin09/hlin09
f7d7d89 [hlin09] Remove redundant code in test.
6bbe823 [hlin09] minor style fix.
9b47f3a [Shivaram Venkataraman] Merge pull request #100 from hnahak87/patch-1
7f6e4ea [Harihar Nahak] Update logistic_regression.R
a605047 [Shivaram Venkataraman] Merge pull request #99 from hlin09/makefile
323151d [hlin09] Fix yar flag in Makefile to remove build error in Maven.
8911897 [hlin09] Make reserialize() private function in package.
79aee73 [Shivaram Venkataraman] Add notes on how to build SparkR on windows
49a99e7 [Shivaram Venkataraman] Clean up some commented code
ddc271b [Shivaram Venkataraman] Only append file:/// to non empty jar paths
a53952e [Shivaram Venkataraman] Add windows build scripts
325b179 [hlin09] Merge remote-tracking branch 'upstream/master' into hlin09
daf5040 [hlin09] Add reserialize() before union if two RDDs are not both serialized.
536afb1 [hlin09] Add new function of union().
7044677 [Shivaram Venkataraman] Merge branch 'master' of https://github.com/amplab-extras/SparkR-pkg into windows-fixes
d22a02d [Zongheng Yang] Merge pull request #94 from shivaram/windows-fixes-stdin
51924f7 [Shivaram Venkataraman] Merge pull request #90 from oscaroboto/master
eb97d85 [Shivaram Venkataraman] Merge pull request #96 from sun-rui/add_clarification_readme
5a128f4 [Sun Rui] Add clarification on setting Spark master when launching the SparkR shell.
187526a [oscaroboto] Update sparkR.R
32c567b [Shivaram Venkataraman] Merge pull request #95 from concretevitamin/master
4cd2d5e [Zongheng Yang] Notes about spark-ec2.
1c28e3b [Shivaram Venkataraman] Merge branch 'master' of https://github.com/amplab-extras/SparkR-pkg into windows-fixes
8e8a029 [Zongheng Yang] Merge pull request #92 from shivaram/sparkr-yarn
721043b [Zongheng Yang] Update README.md with YARN instructions.
1681f58 [Shivaram Venkataraman] Use temporary files for input instead of stdin This fixes a bug for Windows where stdin would get truncated
b084314 [oscaroboto] removed ... from example
44c93d4 [oscaroboto] Added example to SparkR.R
be82dcc [Shivaram Venkataraman] Merge pull request #93 from hlin09/hlin09
868554d [oscaroboto] Update sparkR.R
488ac47 [hlin09] Add generated Rd file of previous added functions, distinct() and mapValues().
b2740ad [hlin09] Add test for filter all elements. Add filter() as alias.
08d3631 [hlin09] Minor style fixes.
2c0e34f [hlin09] Adds function Filter(), which extracts the elements that satisfy a predicate.
5951d3b [Shivaram Venkataraman] Remove SBT plugin
4e70ced [oscaroboto] changed ExecutorEnv to sparkExecutorEnvMap, to make it consistent with sparkEnvirMap
903d18a [oscaroboto] changed executorEnv to sparkExecutorEnvMap, will do the same in R
f97346e [oscaroboto] executorEnv to lower-case e
88a524e [oscaroboto] Added LD_LIBRARY_PATH to the ExecutorEnv. This is need so that the nodes can find libjvm.so, or if the master has a different LD_LIBRARY_PATH then the nodes. Make sure to export LD_LIBRARY_PATH that includes the path to libjvm.so in the nodes.
1d208ae [oscaroboto] added the YARN_CONF_DIR to the classpath
8a9b75c [oscaroboto] forgot to change hm and ee inside the for loops
579db58 [Shivaram Venkataraman] Merge pull request #91 from sun-rui/add_max_min
4381efa [Sun Rui] use reduce() to implemement max() and min().
a5459c5 [Shivaram Venkataraman] Consolidate yarn flags
86b04eb [Shivaram Venkataraman] Don't use quotes around yarn
bf0797f [Shivaram Venkataraman] Add dependency on spark yarn module
af5fe77 [Shivaram Venkataraman] Fix SBT build, add dependency tree plugin
4917607 [Sun Rui] Add maximum() and minimum() API to RDD.
51bbbe4 [Shivaram Venkataraman] Changes to make SparkR work with YARN
9d5e3ab [oscaroboto] a few stylistic changes. Also change vars to sparkEnvirMap and eevars to ExecutorEnv, to match sparkR.R
578f545 [oscaroboto] a few stylistic changes
39eea2f [oscaroboto] Modification to dynamically create a sparkContext with YARN. Added .setExecutorEnv to the sparkConf in createSparkContext within the RRDD object. This modification was made together with sparkR.R
17ec42e [oscaroboto] A modification to dynamically create a sparkContext with YARN. sparkR.R modified to pass custom Jar file names and EnvironmentEnv to the sparkConf. RRDD.scala was also modified to accept the new inputs to creatSparkContext.
624ac9d [Shivaram Venkataraman] Merge pull request #87 from sun-rui/SPARKR-125
4f213db [Shivaram Venkataraman] Merge pull request #89 from sun-rui/SPARKR-108
eb833c5 [Shivaram Venkataraman] Merge pull request #88 from hlin09/hlin09
07bf971 [Sun Rui] [SPARKR-108] Implement map-side reduction for reduceByKey().
4accba1 [hlin09] Fixes style and adds an optional param 'numPartition' in distinct().
80d303a [hlin09] typo fixed.
e37a9b5 [hlin09] Adds function distinct() and mapValues().
08dac06 [Sun Rui] [SPARKR-125] Get the iterator of the parent RDD before launching a R worker process in compute() of RRDD/PairwiseRRDD
c4ba53c [Shivaram Venkataraman] Merge pull request #85 from edwardt/master
72a9d27 [root] reorder to keep relative ordering the same
f3fcb10 [root] fix up build.sbt also to match pom.xml
5ecbe3e [root] Make spark verison configurable in build script per ISSUE122
a44e63d [Shivaram Venkataraman] Merge pull request #84 from sun-rui/SPARKR-94
fbb5663 [Sun Rui] Add {} to one-line functions and add a test case for lookup where no match is found.
95beb4e [Shivaram Venkataraman] Merge pull request #82 from edwardt/master
36776c5 [edwardt] missed one 0.9.0 revert
b26deec [Sun Rui] [SPARKR-94] Add a method to get an element of a pair RDD object by key.
1ba256e [edwardt] Keep 0.9.0 and says uses 1.1.0 by default
5380c43 [root] missed one version
21f74da [root] upgrade to spark version 1.1.0 to match lastest merge list
ddfcde9 [root] merge
67d067a [Shivaram Venkataraman] Merge pull request #81 from sun-rui/SparkR-117
993868f [Sun Rui] [SPARKR-117] Update Spark dependency to 1.1.0
d20661a [Zongheng Yang] Merge pull request #80 from sun-rui/master
0b2da9f [Sun Rui] Update Rd file and add a test case for mapPartitions.
5879648 [Sun Rui] Add mapPartitions() method to RDD for API consistency.
c033461 [Shivaram Venkataraman] Merge pull request #79 from sun-rui/fix-kmeans
f62b77e [Sun Rui] Adjust coding style.
b40911d [Sun Rui] Fix syntax error in examples/kmeans.R.
5304451 [Shivaram Venkataraman] Merge pull request #78 from sun-rui/master
70ffbfb [Sun Rui] Fix a bug that modifications to build.sbt won't trigger rebuilding.
a25696c [Shivaram Venkataraman] Merge pull request #76 from edwardt/addjira
b8bbd93 [edwardt] Update README.md
615d930 [edwardt] Update README.md
e522e69 [edwardt] Update README.md
03e6ced [edwardt] Update README.md
3007015 [root] don't check in gedit buffer file'
c35c9a6 [root] Add where to enter bugs ad feeback
469eae3 [edwardt] Update README.md
61b4a43 [edwardt] Update Makefile (style uniformity)
ce3337d [edwardt] Update README.md
7ff68fc [root] Merge branch 'master' of https://github.com/edwardt/SparkR-pkg
16353f5 [root] add links to devtools and install_github
513b9e5 [Shivaram Venkataraman] Merge pull request #72 from edwardt/master
31608a4 [edwardt] Update Makefile (style uniformity)
4ffe146 [root] Makefile: factor out SPARKR_VERSION to reduce potential copy&paste error; cp & rm called with -f in build/clean phase; .gitignore includes checkpoints and unit test log generated by run-tests.sh
715275f [Zongheng Yang] Merge pull request #68 from shivaram/master
90e2083 [Shivaram Venkataraman] Add return type to hasNext
8eb983d [Shivaram Venkataraman] Fix up comment
2206164 [Shivaram Venkataraman] Delete temporary files after they are read This change deletes temporary files used for communication between Rscript and the JVM once they have been completely read.
5881da7 [Zongheng Yang] Merge pull request #67 from shivaram/improve-shuffle
81251e2 [Shivaram Venkataraman] Address code review comments
a5f573f [Shivaram Venkataraman] Use a better list append in shuffles This is helpful in scenarios where we have a large number of values in a bucket
388e64d [Shivaram Venkataraman] Merge pull request #55 from RevolutionAnalytics/master
e1f95b6 [Zongheng Yang] Merge pull request #65 from concretevitamin/parallelize-fix
fc1a71a [Zongheng Yang] Fix that collect(parallelize(sc,1:72,15)) drops elements.
b8204c5 [Zongheng Yang] Minor: update a URL in README.
86f30c3 [Antonio Piccolboni] better fix for amplab-extras/SparkR-pkg#53
b3c318d [Antonio Piccolboni] delayed loading to have all namespaces available.
f323e97 [Antonio Piccolboni] tentative fix for amplab-extras/SparkR-pkg#53
6f82269 [Zongheng Yang] Merge pull request #48 from shivaram/master
8f433e5 [Shivaram Venkataraman] Move up Hadoop in pom.xml and add back protobufs As Hadoop 1.0.4 doesn't use protobufs, we can't exclude protobufs from Spark always. This change tries to order the dependencies so that the shader first picks up Hadoop's protobufs over Mesos.
bfe7e26 [Shivaram Venkataraman] Merge pull request #36 from RevolutionAnalytics/vectorize-examples
059ae41 [Antonio Piccolboni] and more formatting
9dbd531 [Antonio Piccolboni] more formatting per committer request
948738a [Antonio Piccolboni] converted tabs to spaces per project request
49f5f5a [Shivaram Venkataraman] Merge pull request #35 from shivaram/master
3eb5ad3 [Shivaram Venkataraman] on_failure -> after_failure in travis.yml
139bdee [Shivaram Venkataraman] Cache sbt, maven, ivy dependencies
4ebced2 [Shivaram Venkataraman] Merge pull request #34 from shivaram/master
8437061 [Shivaram Venkataraman] Exclude protobuf from Spark dependency in Maven This avoids pulling in multiple versions of protobuf from Mesos and Hadoop.
91aa527 [Antonio Piccolboni] vectorized version, 36s 10 slices 10^6 per slice. The older version takes 30 sec on 1/10th of data.
f137a57 [Antonio Piccolboni] for rstudio users
1f7ffb0 [Antonio Piccolboni] implemented using matrices and vectorized calls wherever possible
46b23df [Antonio Piccolboni] replace require with library
b15d7db [Antonio Piccolboni] faster parsing
8b7aeb3 [Antonio Piccolboni] 22x speed improvement, 3X mem impovement
c5bce07 [Zongheng Yang] Merge pull request #30 from shivaram/string-tests
21fa2d8 [Shivaram Venkataraman] Fix bug where serialized was not changed for RRRD Reason: When an RRDD is created in getJRDD we have converted any possibly unserialized RDD to a serialized RDD.
9d1ea20 [Shivaram Venkataraman] Merge branch 'master' of github.com:amplab/SparkR-pkg into string-tests
7b9348c [Shivaram Venkataraman] Add tests for partition with string keys Add two tests one with a string array and one from a textFile to test both codepaths
aacd726 [Shivaram Venkataraman] Update README with maven proxy instructions
803e62c [Shivaram Venkataraman] Merge pull request #28 from concretevitamin/master
7c093e6 [Zongheng Yang] Use inherits() to test an object's class.
061c591 [Shivaram Venkataraman] Merge pull request #26 from hafen/master
90f9fda [Ryan Hafen] Fix isRdd() to properly check for class
5b10cc7 [Zongheng Yang] Merge pull request #24 from shivaram/master
7014f83 [Shivaram Venkataraman] Remove unused transformers in maven's pom.xml
b00cea5 [Shivaram Venkataraman] Add support for a Maven build
11ec9b2 [Shivaram Venkataraman] Merge pull request #12 from concretevitamin/pipelined
6b18a90 [Zongheng Yang] Merge branch 'master' into pipelined
57127b8 [Zongheng Yang] Merge pull request #23 from shivaram/master
1ac3940 [Zongheng Yang] Review feedback.
a06fb34 [Zongheng Yang] Remove outdated comment.
0a1fc13 [Shivaram Venkataraman] Fixes for using SparkR with Hadoop2. 1. Exclude ASM, Netty from Hadoop similar to Spark. 2. Concat services files to ensure HDFS filesystems work. 3. Update README with an example
9a1db44 [Zongheng Yang] Merge pull request #22 from shivaram/master
e462448 [Shivaram Venkataraman] Use `$` for calling `put` instead of .jrcall
ed4559a [Shivaram Venkataraman] Add support for passing Spark environment vars This change creates a new `createSparkContext` method in RRDD as we can't pass Map<String, String> through rJava. Also use SPARK_MEM in local mode to increase heap size and update the README with some examples.
10228fb [Shivaram Venkataraman] Merge pull request #20 from concretevitamin/digit-ex
1398d9f [Zongheng Yang] Add linear_solver_mnist to examples/.
d484c2a [Zongheng Yang] Add tests for actions on PipelinedRDD.
d9cb95c [Zongheng Yang] Add setCheckpointDir() to context.R; comment fix.
f8bc8a9 [Zongheng Yang] Minor edits per Shivaram's comments.
8cd67f7 [Shivaram Venkataraman] Merge pull request #15 from shivaram/master
d4468a9 [Shivaram Venkataraman] Remove trailing comma
e2714b8 [Shivaram Venkataraman] Remove Apache Staging repo and update README
334eace [Zongheng Yang] Add a multi-transformation test to benchmark on pipelining.
5650ad7 [Zongheng Yang] Put serialized field inside env for both RDD and PipelinedRDD.
0b9e8bb [Zongheng Yang] First cut at PipelinedRDD.
a4c431e [Zongheng Yang] Add `isCheckpointed` field and checkpoint().
dac0795 [Zongheng Yang] Minor inline comment style fix.
bfb8e26 [Zongheng Yang] Add isCached field (inside an env) and unpersist().
295bff6 [Zongheng Yang] Merge pull request #11 from shivaram/master
4cb209c [Shivaram Venkataraman] Search rLibDir in worker before libPaths This ensures we pick up the SparkR intended and not an older version installed on the same machine
ef198ff [Zongheng Yang] Merge pull request #10 from shivaram/unit-tests
e0557a8 [Shivaram Venkataraman] Update travis to install plyr
8b18bc1 [Shivaram Venkataraman] Merge branch 'master' of github.com:amplab/SparkR-pkg into unit-tests
4a9ca31 [Shivaram Venkataraman] Use smaller broadcast and plyr instead of Matrix Matrix package takes around 2s to load and slows down unit tests.
21c6a61 [Zongheng Yang] Merge pull request #8 from shivaram/master
08c2947 [Shivaram Venkataraman] Move dev install directory to front of libPaths
bda42ee [Shivaram Venkataraman] Merge pull request #7 from JoshRosen/travis
cc5f5c0 [Josh Rosen] Add Travis CI integration (using craigcitro/r-travis)
b6c864b [Shivaram Venkataraman] Merge pull request #6 from concretevitamin/env-style-fix
4fcef22 [Zongheng Yang] Use one style ($) for accessing names in environments.
8a948c6 [Shivaram Venkataraman] Merge pull request #4 from shivaram/master
24978eb [Shivaram Venkataraman] Update README to use install_github
8899db4 [Shivaram Venkataraman] Update TODO.md
91792de [Shivaram Venkataraman] Update Spark requirements
f34f4bf [Shivaram Venkataraman] Check tests for failures and output error msg
cd750d3 [Shivaram Venkataraman] Update run-tests to use new path
1877b7c [Shivaram Venkataraman] Unset R_TESTS to make tests work with R CMD check Also silence Akka remoting logs and update Makefile to build on log4j changes
e60e18a [Shivaram Venkataraman] Update README to remove Spark installation notes
4450189 [Shivaram Venkataraman] Add Spark 0.9 dependency from Apache Staging Also clean up assembly jar from inst on make clean
5eb2131 [Shivaram Venkataraman] Update repo path in README
ec8210e [Shivaram Venkataraman] Remove broadcastId hack as it is public in Spark
9f0e080 [Shivaram Venkataraman] Merge branch 'install-github'
5c88fbd [Shivaram Venkataraman] Add helper script to run tests
77450a1 [Shivaram Venkataraman] Remove dependency on Spark Logging
6cb00d1 [Shivaram Venkataraman] Update README and add helper script install-dev.sh
28346ca [Shivaram Venkataraman] Only normalize if SPARK_HOME is not empty
0fd6571 [Shivaram Venkataraman] Normalize SPARK_HOME before passing it
ff96d5c [Shivaram Venkataraman] Pass in SPARK_HOME and jar file path
34c4dce [Shivaram Venkataraman] Move src into pkg and update Makefile This enables the package to be installed using install_github using devtools and automates the build procedure.
b25afed [Shivaram Venkataraman] Change package name to edu.berkeley.cs.amplab
c691464 [Shivaram Venkataraman] Add Apache 2.0 License file
27a4a4b [Shivaram Venkataraman] Add notes on how to compile roxygen2 docs
ca63844 [Shivaram Venkataraman] Add broadcast documentation Also generate documentation for sample, takeSample etc.
e4dd976 [Shivaram Venkataraman] Update TODO.md
e42d435 [Shivaram Venkataraman] Add support for broadcast variables
6b638e7 [Shivaram Venkataraman] Add the assembly jar to SparkContext
bf24e32 [Shivaram Venkataraman] Merge branch 'master' of github.com:amplab/SparkR-pkg
43c05ce [Zongheng Yang] Fix a flaky/incorrect test for sampleRDD().
c6a9dfc [Zongheng Yang] Initial port of the kmeans example.
6885581 [Zongheng Yang] Implement element-level sampleRDD() and takeSample() with tests.
d3a4987 [Zongheng Yang] Add a test for lapplyPartitionsWithIndex on pairwise RDD.
c7899c1 [Zongheng Yang] Add lapplyPartitionsWithIndex, with a test and an alias function.
a9a7436 [Shivaram Venkataraman] Add DFC example from Tselil, Benjamin and Jonah
fbc5a95 [Zongheng Yang] Implement take() and takeSample().
c4a3409 [Shivaram Venkataraman] Use RDD instead of RRDD
dfad3f5 [Zongheng Yang] Add test_utils.R: a unit test for convertJListToRList().
a45227d [Zongheng Yang] Update .gitignore.
238fe6e [Zongheng Yang] Add a unit test for textFile().
a88898b [Zongheng Yang] Rename test_rrd to test_rrdd
10c8baa [Shivaram Venkataraman] Make SparkR work as a standalone package. Changes include: 1. Adding a new `sbt` project that builds RRDD.scala 2. Change the onLoad functions to load the assembly jar for SparkR 3. Set rLibDir in RRDD.scala and worker.R to load things correctly
78adcd8 [Shivaram Venkataraman] Add a gitignore
ca6108f [Shivaram Venkataraman] Merge branch 'SparkR-scalacode' of ../SparkR
999bd61 [Shivaram Venkataraman] Update collectPartition in R and use ClassTag
c58f63e [Shivaram Venkataraman] Update collectPartition in R and use ClassTag
48265fd [Shivaram Venkataraman] Use new version of collectPartitions in take
d4fe086 [Shivaram Venkataraman] Move collectPartitions to JavaRDDLike Also remove numPartitions in JavaRDD and update R code
bfecd7b [Shivaram Venkataraman] Scala 2.10 changes 1. Update sparkR script 2. Use classTag instead of classManifest
092a4b3 [Shivaram Venkataraman] Add combineByKey, update TODO
ac0d81d [Shivaram Venkataraman] Add more documentation
d1dc3fa [Shivaram Venkataraman] Add more documentation
c515e3a [Shivaram Venkataraman] Update TODO
db56a34 [Shivaram Venkataraman] Add a test case for include package
41cea51 [Shivaram Venkataraman] Ensure all parent environments are serialized. Also add a test case with an inline function
a978e84 [Shivaram Venkataraman] Add support to include packages in the worker
12bf8ce [Shivaram Venkataraman] Add support to include packages in the worker
fb7e72c [Shivaram Venkataraman] Cleanup TODO
16ac314 [Shivaram Venkataraman] Add documentation for functions in context, sparkR
85b1d25 [Shivaram Venkataraman] Set license to Apache
88f1101 [Shivaram Venkataraman] Add unit test running instructions
c40768e [Shivaram Venkataraman] Update TODO
0c7efbf [Shivaram Venkataraman] Refactor RRDD.scala and add comments to functions
5880d42 [Shivaram Venkataraman] Refactor RRDD.scala and add comments to functions
2dee36c [Shivaram Venkataraman] Remove empty test file
a82219b [Shivaram Venkataraman] Update TODOs
5db00dc [Shivaram Venkataraman] Add reduceByKey, groupByKey and refactor shuffle Other ch…
liancheng
pushed a commit
to liancheng/spark
that referenced
this pull request
Mar 17, 2017
…ter class. (apache#226) ## What changes were proposed in this pull request? We merged in and closed PR apache#221 too soon, missing this commit that addressed the last review comments there. ## How was this patch tested? Ran the existing unit tests.
bzhaoopenstack
pushed a commit
to bzhaoopenstack/spark
that referenced
this pull request
Sep 11, 2019
* Add bosh acceptance test job * replace zuul home path with ansible var * Add resource cleanup and improve for bosh acc test job Close theopenlab/openlab#4
cloud-fan
pushed a commit
that referenced
this pull request
Apr 19, 2021
…gate expressions without aggregate function ### What changes were proposed in this pull request? This PR: - Adds a new expression `GroupingExprRef` that can be used in aggregate expressions of `Aggregate` nodes to refer grouping expressions by index. These expressions capture the data type and nullability of the referred grouping expression. - Adds a new rule `EnforceGroupingReferencesInAggregates` that inserts the references in the beginning of the optimization phase. - Adds a new rule `UpdateGroupingExprRefNullability` to update nullability of `GroupingExprRef` expressions as nullability of referred grouping expression can change during optimization. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [NOT groupingexprref(0) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #31913 from peter-toth/SPARK-34581-keep-grouping-expressions. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
cloud-fan
pushed a commit
that referenced
this pull request
May 2, 2021
…gate expressions without aggregate function ### What changes were proposed in this pull request? This PR adds a new rule `PullOutGroupingExpressions` to pull out complex grouping expressions to a `Project` node under an `Aggregate`. These expressions are then referenced in both grouping expressions and aggregate expressions without aggregate functions to ensure that optimization rules don't change the aggregate expressions to invalid ones that no longer refer to any grouping expressions. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [_groupingexpression#233], [NOT _groupingexpression#233 AS (NOT (id IS NULL))#230, count(1) AS c#228L] +- Project [isnull(value#219) AS _groupingexpression#233] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #32396 from peter-toth/SPARK-34581-keep-grouping-expressions-2. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
JeffInChrist
added a commit
to JeffABC/spark
that referenced
this pull request
May 15, 2021
* [SPARK-34225][CORE][FOLLOWUP] Replace Hadoop's Path with Utils.resolveURI to make the way to get URI simple
### What changes were proposed in this pull request?
This PR proposes to replace Hadoop's `Path` with `Utils.resolveURI` to make the way to get URI simple in `SparkContext`.
### Why are the changes needed?
Keep the code simple.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes #32164 from sarutak/followup-SPARK-34225.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35070][SQL] TRANSFORM not support alias in inputs
### What changes were proposed in this pull request?
Normal function parameters should not support alias, hive not support too
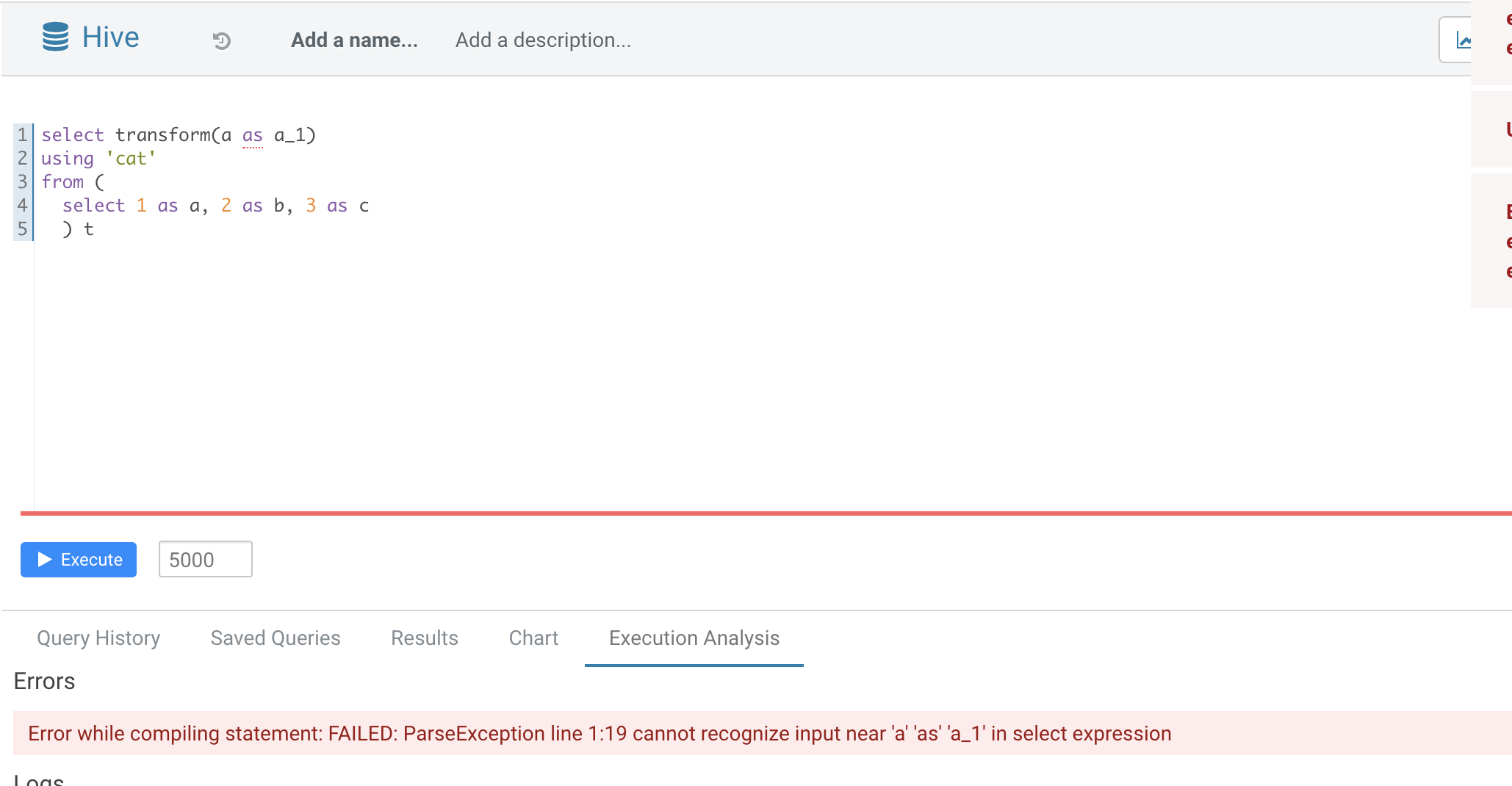
In this pr we forbid use alias in `TRANSFORM`'s inputs
### Why are the changes needed?
Fix bug
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes #32165 from AngersZhuuuu/SPARK-35070.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [MINOR][CORE] Correct the number of started fetch requests in log
### What changes were proposed in this pull request?
When counting the number of started fetch requests, we should exclude the deferred requests.
### Why are the changes needed?
Fix the wrong number in the log.
### Does this PR introduce _any_ user-facing change?
Yes, users see the correct number of started requests in logs.
### How was this patch tested?
Manually tested.
Closes #32180 from Ngone51/count-deferred-request.
Lead-authored-by: yi.wu <yi.wu@databricks.com>
Co-authored-by: wuyi <yi.wu@databricks.com>
Signed-off-by: attilapiros <piros.attila.zsolt@gmail.com>
* [SPARK-34995] Port/integrate Koalas remaining codes into PySpark
### What changes were proposed in this pull request?
There are some more changes in Koalas such as [databricks/koalas#2141](https://github.com/databricks/koalas/commit/c8f803d6becb3accd767afdb3774c8656d0d0b47), [databricks/koalas#2143](https://github.com/databricks/koalas/commit/913d68868d38ee7158c640aceb837484f417267e) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`.
### Why are the changes needed?
We should port the whole Koalas codes into PySpark and synchronize them.
### Does this PR introduce _any_ user-facing change?
Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring.
### How was this patch tested?
Manually tested in local.
Closes #32154 from itholic/SPARK-34995.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* Revert "[SPARK-34995] Port/integrate Koalas remaining codes into PySpark"
This reverts commit 9689c44b602781c1d6b31a322162c488ed17a29b.
* [SPARK-34843][SQL][FOLLOWUP] Fix a test failure in OracleIntegrationSuite
### What changes were proposed in this pull request?
This PR fixes a test failure in `OracleIntegrationSuite`.
After SPARK-34843 (#31965), the way to divide partitions is changed and `OracleIntegrationSuites` is affected.
```
[info] - SPARK-22814 support date/timestamp types in partitionColumn *** FAILED *** (230 milliseconds)
[info] Set(""D" < '2018-07-11' or "D" is null", ""D" >= '2018-07-11' AND "D" < '2018-07-15'", ""D" >= '2018-07-15'") did not equal Set(""D" < '2018-07-10' or "D" is null", ""D" >= '2018-07-10' AND "D" < '2018-07-14'", ""D" >= '2018-07-14'") (OracleIntegrationSuite.scala:448)
[info] Analysis:
[info] Set(missingInLeft: ["D" < '2018-07-10' or "D" is null, "D" >= '2018-07-10' AND "D" < '2018-07-14', "D" >= '2018-07-14'], missingInRight: ["D" < '2018-07-11' or "D" is null, "D" >= '2018-07-11' AND "D" < '2018-07-15', "D" >= '2018-07-15'])
```
### Why are the changes needed?
To follow the previous change.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
The modified test.
Closes #32186 from sarutak/fix-oracle-date-error.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35032][PYTHON] Port Koalas Index unit tests into PySpark
### What changes were proposed in this pull request?
Now that we merged the Koalas main code into the PySpark code base (#32036), we should port the Koalas Index unit tests to PySpark.
### Why are the changes needed?
Currently, the pandas-on-Spark modules are not tested fully. We should enable the Index unit tests.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Enable Index unit tests.
Closes #32139 from xinrong-databricks/port.indexes_tests.
Authored-by: Xinrong Meng <xinrong.meng@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [SPARK-35099][SQL] Convert ANSI interval literals to SQL string in ANSI style
### What changes were proposed in this pull request?
Handle `YearMonthIntervalType` and `DayTimeIntervalType` in the `sql()` and `toString()` method of `Literal`, and format the ANSI interval in the ANSI style.
### Why are the changes needed?
To improve readability and UX with Spark SQL. For example, a test output before the changes:
```
-- !query
select timestamp'2011-11-11 11:11:11' - interval '2' day
-- !query schema
struct<TIMESTAMP '2011-11-11 11:11:11' - 172800000000:timestamp>
-- !query output
2011-11-09 11:11:11
```
### Does this PR introduce _any_ user-facing change?
Should not since the new intervals haven't been released yet.
### How was this patch tested?
By running new tests:
```
$ ./build/sbt "test:testOnly *LiteralExpressionSuite"
```
Closes #32196 from MaxGekk/literal-ansi-interval-sql.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35083][CORE] Support remote scheduler pool files
### What changes were proposed in this pull request?
Use hadoop FileSystem instead of FileInputStream.
### Why are the changes needed?
Make `spark.scheduler.allocation.file` suport remote file. When using Spark as a server (e.g. SparkThriftServer), it's hard for user to specify a local path as the scheduler pool.
### Does this PR introduce _any_ user-facing change?
Yes, a minor feature.
### How was this patch tested?
Pass `core/src/test/scala/org/apache/spark/scheduler/PoolSuite.scala` and manul test
After add config `spark.scheduler.allocation.file=hdfs:///tmp/fairscheduler.xml`. We intrudoce the configed pool.

Closes #32184 from ulysses-you/SPARK-35083.
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35104][SQL] Fix ugly indentation of multiple JSON records in a single split file generated by JacksonGenerator when pretty option is true
### What changes were proposed in this pull request?
This issue fixes an issue that indentation of multiple output JSON records in a single split file are broken except for the first record in the split when `pretty` option is `true`.
```
// Run in the Spark Shell.
// Set spark.sql.leafNodeDefaultParallelism to 1 for the current master.
// Or set spark.default.parallelism for the previous releases.
spark.conf.set("spark.sql.leafNodeDefaultParallelism", 1)
val df = Seq("a", "b", "c").toDF
df.write.option("pretty", "true").json("/path/to/output")
# Run in a Shell
$ cat /path/to/output/*.json
{
"value" : "a"
}
{
"value" : "b"
}
{
"value" : "c"
}
```
### Why are the changes needed?
It's not pretty even though `pretty` option is true.
### Does this PR introduce _any_ user-facing change?
I think "No". Indentation style is changed but JSON format is not changed.
### How was this patch tested?
New test.
Closes #32203 from sarutak/fix-ugly-indentation.
Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-34995] Port/integrate Koalas remaining codes into PySpark
### What changes were proposed in this pull request?
There are some more changes in Koalas such as [databricks/koalas#2141](https://github.com/databricks/koalas/commit/c8f803d6becb3accd767afdb3774c8656d0d0b47), [databricks/koalas#2143](https://github.com/databricks/koalas/commit/913d68868d38ee7158c640aceb837484f417267e) after the main code porting, this PR is to synchronize those changes with the `pyspark.pandas`.
### Why are the changes needed?
We should port the whole Koalas codes into PySpark and synchronize them.
### Does this PR introduce _any_ user-facing change?
Fixed some incompatible behavior with pandas 1.2.0 and added more to the `to_markdown` docstring.
### How was this patch tested?
Manually tested in local.
Closes #32197 from itholic/SPARK-34995-fix.
Authored-by: itholic <haejoon.lee@databricks.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [MINOR][DOCS] Soften security warning and keep it in cluster management docs only
### What changes were proposed in this pull request?
Soften security warning and keep it in cluster management docs only, not in the main doc page, where it's not necessarily relevant.
### Why are the changes needed?
The statement is perhaps unnecessarily 'frightening' as the first section in the main docs page. It applies to clusters not local mode, anyhow.
### Does this PR introduce _any_ user-facing change?
Just a docs change.
### How was this patch tested?
N/A
Closes #32206 from srowen/SecurityStatement.
Authored-by: Sean Owen <srowen@gmail.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
* [SPARK-34787][CORE] Option variable in Spark historyServer log should be displayed as actual value instead of Some(XX)
### What changes were proposed in this pull request?
Make the attemptId in the log of historyServer to be more easily to read.
### Why are the changes needed?
Option variable in Spark historyServer log should be displayed as actual value instead of Some(XX)
### Does this PR introduce any user-facing change?
No
### How was this patch tested?
manual test
Closes #32189 from kyoty/history-server-print-option-variable.
Authored-by: kyoty <echohlne@gmail.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35101][INFRA] Add GitHub status check in PR instead of a comment
### What changes were proposed in this pull request?
TL;DR: now it shows green yellow read status of tests instead of relying on a comment in a PR, **see https://github.com/HyukjinKwon/spark/pull/41 for an example**.
This PR proposes the GitHub status checks instead of a comment that link to the build (from forked repository) in PRs.
This is how it works:
1. **forked repo**: "Build and test" workflow is triggered when you create a branch to create a PR which uses your resources in GitHub Actions.
1. **main repo**: "Notify test workflow" (previously created a comment) now creates a in-progress status (yellow status) as a GitHub Actions check to your current PR.
1. **main repo**: "Update build status workflow" regularly (every 15 mins) checks open PRs, and updates the status of GitHub Actions checks at PRs according to the status of workflows in the forked repositories (status sync).
**NOTE** that creating/updating statuses in the PRs is only allowed from the main repo. That's why the flow is as above.
### Why are the changes needed?
The GitHub status shows a green although the tests are running, which is confusing.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested at:
- https://github.com/HyukjinKwon/spark/pull/41
- HyukjinKwon#42
- HyukjinKwon#43
- https://github.com/HyukjinKwon/spark/pull/37
**queued**:
<img width="861" alt="Screen Shot 2021-04-16 at 10 56 03 AM" src="https://user-images.githubusercontent.com/6477701/114960831-c9a73080-9ea2-11eb-8442-ddf3f6008a45.png">
**in progress**:
<img width="871" alt="Screen Shot 2021-04-16 at 12 14 39 PM" src="https://user-images.githubusercontent.com/6477701/114966359-59ea7300-9ead-11eb-98cb-1e63323980ad.png">
**passed**:

**failure**:

Closes #32193 from HyukjinKwon/update-checks-pr-poc.
Lead-authored-by: HyukjinKwon <gurwls223@apache.org>
Co-authored-by: Hyukjin Kwon <gurwls223@apache.org>
Co-authored-by: Yikun Jiang <yikunkero@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [MINOR][INFRA] Upgrade Jira client to 2.0.0
### What changes were proposed in this pull request?
SPARK-10498 added the initial Jira client requirement with 1.0.3 five year ago (2016 January). As of today, it causes `dev/merge_spark_pr.py` failure with `Python 3.9.4` due to this old dependency. This PR aims to upgrade it to the latest version, 2.0.0. The latest version is also a little old (2018 July).
- https://pypi.org/project/jira/#history
### Why are the changes needed?
`Jira==2.0.0` works well with both Python 3.8/3.9 while `Jira==1.0.3` fails with Python 3.9.
**BEFORE**
```
$ pyenv global 3.9.4
$ pip freeze | grep jira
jira==1.0.3
$ dev/merge_spark_pr.py
Traceback (most recent call last):
File "/Users/dongjoon/APACHE/spark-merge/dev/merge_spark_pr.py", line 39, in <module>
import jira.client
File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/__init__.py", line 5, in <module>
from .config import get_jira
File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/config.py", line 17, in <module>
from .client import JIRA
File "/Users/dongjoon/.pyenv/versions/3.9.4/lib/python3.9/site-packages/jira/client.py", line 165
validate=False, get_server_info=True, async=False, logging=True, max_retries=3):
^
SyntaxError: invalid syntax
```
**AFTER**
```
$ pip install jira==2.0.0
$ dev/merge_spark_pr.py
git rev-parse --abbrev-ref HEAD
Which pull request would you like to merge? (e.g. 34):
```
### Does this PR introduce _any_ user-facing change?
No. This is a committer-only script.
### How was this patch tested?
Manually.
Closes #32215 from dongjoon-hyun/jira.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [SPARK-35116][SQL][TESTS] The generated data fits the precision of DayTimeIntervalType in spark
### What changes were proposed in this pull request?
The precision of `java.time.Duration` is nanosecond, but when it is used as `DayTimeIntervalType` in Spark, it is microsecond.
At present, the `DayTimeIntervalType` data generated in the implementation of `RandomDataGenerator` is accurate to nanosecond, which will cause the `DayTimeIntervalType` to be converted to long, and then back to `DayTimeIntervalType` to lose the accuracy, which will cause the test to fail. For example: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137390/testReport/org.apache.spark.sql.hive.execution/HashAggregationQueryWithControlledFallbackSuite/udaf_with_all_data_types/
### Why are the changes needed?
Improve `RandomDataGenerator` so that the generated data fits the precision of DayTimeIntervalType in spark.
### Does this PR introduce _any_ user-facing change?
'No'. Just change the test class.
### How was this patch tested?
Jenkins test.
Closes #32212 from beliefer/SPARK-35116.
Authored-by: beliefer <beliefer@163.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35114][SQL][TESTS] Add checks for ANSI intervals to `LiteralExpressionSuite`
### What changes were proposed in this pull request?
In the PR, I propose to add additional checks for ANSI interval types `YearMonthIntervalType` and `DayTimeIntervalType` to `LiteralExpressionSuite`.
Also, I replaced some long literal values by `CalendarInterval` to check `CalendarIntervalType` that the tests were supposed to check.
### Why are the changes needed?
To improve test coverage and have the same checks for ANSI types as for `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ build/sbt "test:testOnly *LiteralExpressionSuite"
```
Closes #32213 from MaxGekk/interval-literal-tests.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-34716][SQL] Support ANSI SQL intervals by the aggregate function `sum`
### What changes were proposed in this pull request?
Extend the `Sum` expression to to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Sum` to support `DayTimeIntervalType` and `YearMonthIntervalType`.
### Does this PR introduce _any_ user-facing change?
'No'.
Should not since new types have not been released yet.
### How was this patch tested?
Jenkins test
Closes #32107 from beliefer/SPARK-34716.
Lead-authored-by: gengjiaan <gengjiaan@360.cn>
Co-authored-by: beliefer <beliefer@163.com>
Co-authored-by: Hyukjin Kwon <gurwls223@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35115][SQL][TESTS] Check ANSI intervals in `MutableProjectionSuite`
### What changes were proposed in this pull request?
Add checks for `YearMonthIntervalType` and `DayTimeIntervalType` to `MutableProjectionSuite`.
### Why are the changes needed?
To improve test coverage, and the same checks as for `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ build/sbt "test:testOnly *MutableProjectionSuite"
```
Closes #32225 from MaxGekk/test-ansi-intervals-in-MutableProjectionSuite.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
* [SPARK-35092][UI] the auto-generated rdd's name in the storage tab should be truncated if it is too long
### What changes were proposed in this pull request?
the auto-generated rdd's name in the storage tab should be truncated as a single line if it is too long.
### Why are the changes needed?
to make the ui shows more friendly.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
just a simple modifition in css, manual test works well like below:
before modified:

after modified:
Tht titile needs just one line:

Closes #32191 from kyoty/storage-rdd-titile-display-improve.
Authored-by: kyoty <echohlne@gmail.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
* [SPARK-35109][SQL] Fix minor exception messages of HashedRelation and HashJoin
### What changes were proposed in this pull request?
It seems that we miss classifying one `SparkOutOfMemoryError` in `HashedRelation`. Add the error classification for it. In addition, clean up two errors definition of `HashJoin` as they are not used.
### Why are the changes needed?
Better error classification.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes #32211 from c21/error-message.
Authored-by: Cheng Su <chengsu@fb.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
* [SPARK-34581][SQL] Don't optimize out grouping expressions from aggregate expressions without aggregate function
### What changes were proposed in this pull request?
This PR:
- Adds a new expression `GroupingExprRef` that can be used in aggregate expressions of `Aggregate` nodes to refer grouping expressions by index. These expressions capture the data type and nullability of the referred grouping expression.
- Adds a new rule `EnforceGroupingReferencesInAggregates` that inserts the references in the beginning of the optimization phase.
- Adds a new rule `UpdateGroupingExprRefNullability` to update nullability of `GroupingExprRef` expressions as nullability of referred grouping expression can change during optimization.
### Why are the changes needed?
If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid.
Here is a simple example:
```
SELECT not(t.id IS NULL) , count(*)
FROM t
GROUP BY t.id IS NULL
```
In this case the `BooleanSimplification` rule does this:
```
=== Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification ===
!Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L]
+- Project [value#219 AS id#222] +- Project [value#219 AS id#222]
+- LocalRelation [value#219] +- LocalRelation [value#219]
```
where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression.
Before this PR:
```
== Optimized Logical Plan ==
Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L]
+- Project [value#219 AS id#222]
+- LocalRelation [value#219]
```
and running the query throws an error:
```
Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L]
java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L]
```
After this PR:
```
== Optimized Logical Plan ==
Aggregate [isnull(id#222)], [NOT groupingexprref(0) AS (NOT (id IS NULL))#234, count(1) AS c#232L]
+- Project [value#219 AS id#222]
+- LocalRelation [value#219]
```
and the query works.
### Does this PR introduce _any_ user-facing change?
Yes, the query works.
### How was this patch tested?
Added new UT.
Closes #31913 from peter-toth/SPARK-34581-keep-grouping-expressions.
Authored-by: Peter Toth <peter.toth@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-35122][SQL] Migrate CACHE/UNCACHE TABLE to use AnalysisOnlyCommand
### What changes were proposed in this pull request?
Now that `AnalysisOnlyCommand` in introduced in #32032, `CacheTable` and `UncacheTable` can extend `AnalysisOnlyCommand` to simplify the code base. For example, the logic to handle these commands such that the tables are only analyzed is scattered across different places.
### Why are the changes needed?
To simplify the code base to handle these two commands.
### Does this PR introduce _any_ user-facing change?
No, just internal refactoring.
### How was this patch tested?
The existing tests (e.g., `CachedTableSuite`) cover the changes in this PR. For example, if I make `CacheTable`/`UncacheTable` extend `LeafCommand`, there are few failures in `CachedTableSuite`.
Closes #32220 from imback82/cache_cmd_analysis_only.
Authored-by: Terry Kim <yuminkim@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-31937][SQL] Support processing ArrayType/MapType/StructType data using no-serde mode script transform
### What changes were proposed in this pull request?
Support no-serde mode script transform use ArrayType/MapType/StructStpe data.
### Why are the changes needed?
Make user can process array/map/struct data
### Does this PR introduce _any_ user-facing change?
Yes, user can process array/map/struct data in script transform `no-serde` mode
### How was this patch tested?
Added UT
Closes #30957 from AngersZhuuuu/SPARK-31937.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [SPARK-35045][SQL][FOLLOW-UP] Add a configuration for CSV input buffer size
### What changes were proposed in this pull request?
This PR makes the input buffer configurable (as an internal configuration). This is mainly to work around the regression in uniVocity/univocity-parsers#449.
This is particularly useful for SQL workloads that requires to rewrite the `CREATE TABLE` with options.
### Why are the changes needed?
To work around uniVocity/univocity-parsers#449.
### Does this PR introduce _any_ user-facing change?
No, it's only internal option.
### How was this patch tested?
Manually tested by modifying the unittest added in https://github.com/apache/spark/pull/31858 as below:
```diff
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
index fd25a79619d..705f38dbfbd 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
-2456,6 +2456,7 abstract class CSVSuite
test("SPARK-34768: counting a long record with ignoreTrailingWhiteSpace set to true") {
val bufSize = 128
val line = "X" * (bufSize - 1) + "| |"
+ spark.conf.set("spark.sql.csv.parser.inputBufferSize", 128)
withTempPath { path =>
Seq(line).toDF.write.text(path.getAbsolutePath)
assert(spark.read.format("csv")
```
Closes #32231 from HyukjinKwon/SPARK-35045-followup.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [SPARK-34837][SQL] Support ANSI SQL intervals by the aggregate function `avg`
### What changes were proposed in this pull request?
Extend the `Average` expression to support `DayTimeIntervalType` and `YearMonthIntervalType` added by #31614.
Note: the expressions can throw the overflow exception independently from the SQL config `spark.sql.ansi.enabled`. In this way, the modified expressions always behave in the ANSI mode for the intervals.
### Why are the changes needed?
Extend `org.apache.spark.sql.catalyst.expressions.aggregate.Average` to support `DayTimeIntervalType` and `YearMonthIntervalType`.
### Does this PR introduce _any_ user-facing change?
'No'.
Should not since new types have not been released yet.
### How was this patch tested?
Jenkins test
Closes #32229 from beliefer/SPARK-34837.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35107][SQL] Parse unit-to-unit interval literals to ANSI intervals
### What changes were proposed in this pull request?
Parse the year-month interval literals like `INTERVAL '1-1' YEAR TO MONTH` to values of `YearMonthIntervalType`, and day-time interval literals to `DayTimeIntervalType` values. Currently, Spark SQL supports:
- DAY TO HOUR
- DAY TO MINUTE
- DAY TO SECOND
- HOUR TO MINUTE
- HOUR TO SECOND
- MINUTE TO SECOND
All such interval literals are converted to `DayTimeIntervalType`, and `YEAR TO MONTH` to `YearMonthIntervalType` while loosing info about `from` and `to` units.
**Note**: new behavior is under the SQL config `spark.sql.legacy.interval.enabled` which is `false` by default. When the config is set to `true`, the interval literals are parsed to `CaledarIntervalType` values.
Closes #32176
### Why are the changes needed?
To conform the ANSI SQL standard which assumes conversions of interval literals to year-month or day-time interval but not to mixed interval type like Catalyst's `CalendarIntervalType`.
### Does this PR introduce _any_ user-facing change?
Yes.
Before:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 days 1 hours 2 minutes 3.123 seconds
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
interval
```
After:
```sql
spark-sql> SELECT INTERVAL '1 01:02:03.123' DAY TO SECOND;
1 01:02:03.123000000
spark-sql> SELECT typeof(INTERVAL '1 01:02:03.123' DAY TO SECOND);
day-time interval
```
### How was this patch tested?
1. By running the affected test suites:
```
$ ./build/sbt "test:testOnly *.ExpressionParserSuite"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z create_view.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z date.sql"
$ SPARK_GENERATE_GOLDEN_FILES=1 build/sbt "sql/testOnly *SQLQueryTestSuite -- -z timestamp.sql"
```
2. PostgresSQL tests are executed with `spark.sql.legacy.interval.enabled` is set to `true` to keep compatibility with PostgreSQL output:
```sql
> SELECT interval '999' second;
0 years 0 mons 0 days 0 hours 16 mins 39.00 secs
```
Closes #32209 from MaxGekk/parse-ansi-interval-literals.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-34715][SQL][TESTS] Add round trip tests for period <-> month and duration <-> micros
### What changes were proposed in this pull request?
Similarly to the test from the PR https://github.com/apache/spark/pull/31799, add tests:
1. Months -> Period -> Months
2. Period -> Months -> Period
3. Duration -> micros -> Duration
### Why are the changes needed?
Add round trip tests for period <-> month and duration <-> micros
### Does this PR introduce _any_ user-facing change?
'No'. Just test cases.
### How was this patch tested?
Jenkins test
Closes #32234 from beliefer/SPARK-34715.
Authored-by: gengjiaan <gengjiaan@360.cn>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35125][K8S] Upgrade K8s client to 5.3.0 to support K8s 1.20
### What changes were proposed in this pull request?
Although AS-IS master branch already works with K8s 1.20, this PR aims to upgrade K8s client to 5.3.0 to support K8s 1.20 officially.
- https://github.com/fabric8io/kubernetes-client#compatibility-matrix
The following are the notable breaking API changes.
1. Remove Doneable (5.0+):
- https://github.com/fabric8io/kubernetes-client/pull/2571
2. Change Watcher.onClose signature (5.0+):
- https://github.com/fabric8io/kubernetes-client/pull/2616
3. Change Readiness (5.1+)
- https://github.com/fabric8io/kubernetes-client/pull/2796
### Why are the changes needed?
According to the compatibility matrix, this makes Apache Spark and its external cluster manager extension support all K8s 1.20 features officially for Apache Spark 3.2.0.
### Does this PR introduce _any_ user-facing change?
Yes, this is a dev dependency change which affects K8s cluster extension users.
### How was this patch tested?
Pass the CIs.
This is manually tested with K8s IT.
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
- Run SparkR on simple dataframe.R example
Run completed in 17 minutes, 44 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes #32221 from dongjoon-hyun/SPARK-K8S-530.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35102][SQL] Make spark.sql.hive.version read-only, not deprecated and meaningful
### What changes were proposed in this pull request?
Firstly let's take a look at the definition and comment.
```
// A fake config which is only here for backward compatibility reasons. This config has no effect
// to Spark, just for reporting the builtin Hive version of Spark to existing applications that
// already rely on this config.
val FAKE_HIVE_VERSION = buildConf("spark.sql.hive.version")
.doc(s"deprecated, please use ${HIVE_METASTORE_VERSION.key} to get the Hive version in Spark.")
.version("1.1.1")
.fallbackConf(HIVE_METASTORE_VERSION)
```
It is used for reporting the built-in Hive version but the current status is unsatisfactory, as it is could be changed in many ways e.g. --conf/SET syntax.
It is marked as deprecated but kept a long way until now. I guess it is hard for us to remove it and not even necessary.
On second thought, it's actually good for us to keep it to work with the `spark.sql.hive.metastore.version`. As when `spark.sql.hive.metastore.version` is changed, it could be used to report the compiled hive version statically, it's useful when an error occurs in this case. So this parameter should be fixed to compiled hive version.
### Why are the changes needed?
`spark.sql.hive.version` is useful in certain cases and should be read-only
### Does this PR introduce _any_ user-facing change?
`spark.sql.hive.version` now is read-only
### How was this patch tested?
new test cases
Closes #32200 from yaooqinn/SPARK-35102.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-35136] Remove initial null value of LiveStage.info
### What changes were proposed in this pull request?
To prevent potential NullPointerExceptions, this PR changes the `LiveStage` constructor to take `info` as a constructor parameter and adds a nullcheck in `AppStatusListener.activeStages`.
### Why are the changes needed?
The `AppStatusListener.getOrCreateStage` would create a LiveStage object with the `info` field set to null and right after that set it to a specific StageInfo object. This can lead to a race condition when the `livestages` are read in between those calls. This could then lead to a null pointer exception in, for instance: `AppStatusListener.activeStages`.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Regular CI/CD tests
Closes #32233 from sander-goos/SPARK-35136-livestage.
Authored-by: Sander Goos <sander.goos@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-35138][SQL] Remove Antlr4 workaround
### What changes were proposed in this pull request?
Remove Antlr 4.7 workaround.
### Why are the changes needed?
The https://github.com/antlr/antlr4/commit/ac9f7530 has been fixed in upstream, so remove the workaround to simplify code.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UTs.
Closes #32238 from pan3793/antlr-minor.
Authored-by: Cheng Pan <379377944@qq.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35120][INFRA] Guide users to sync branch and enable GitHub Actions in their forked repository
### What changes were proposed in this pull request?
This PR proposes to add messages when the workflow fails to find the workflow run in a forked repository, for example as below:
**Before**


**After**


(typo `foce` in the image was fixed)
See this example: https://github.com/HyukjinKwon/spark/runs/2380644793
### Why are the changes needed?
To guide users to enable Github Actions in their forked repositories (and sync their branch to the latest `master` in Apache Spark).
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
Manually tested in:
- https://github.com/HyukjinKwon/spark/pull/47
- https://github.com/HyukjinKwon/spark/pull/46
Closes #32235 from HyukjinKwon/test-test-test.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35131][K8S] Support early driver service clean-up during app termination
### What changes were proposed in this pull request?
This PR aims to support a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, to clean up `Driver Service` resource during app termination.
### Why are the changes needed?
The K8s service is one of the important resources and sometimes it's controlled by quota.
```
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
Apache Spark creates a service for driver whose lifecycle is the same with driver pod.
It means a new Spark job submission fails if the number of completed Spark jobs equals the number of service quota.
**BEFORE**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver 0/1 Completed 0 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver 0/1 Completed 0 78s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 80m
org-apache-spark-examples-sparkpi-a32c9278e7061b4d-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 31m
org-apache-spark-examples-sparkpi-a9f1f578e721ef62-driver-svc ClusterIP None <none> 7078/TCP,7079/TCP,4040/TCP 80s
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 3 3
$ bin/spark-submit...
Exception in thread "main" io.fabric8.kubernetes.client.KubernetesClientException:
Failure executing: POST at: https://192.168.64.50:8443/api/v1/namespaces/default/services.
Message: Forbidden! User minikube doesn't have permission.
services "org-apache-spark-examples-sparkpi-843f6978e722819c-driver-svc" is forbidden:
exceeded quota: service, requested: services=1, used: services=3, limited: services=3.
```
**AFTER**
```
$ k get pod
NAME READY STATUS RESTARTS AGE
org-apache-spark-examples-sparkpi-23d5f278e77731a7-driver 0/1 Completed 0 26s
org-apache-spark-examples-sparkpi-d1292278e7768ed4-driver 0/1 Completed 0 67s
org-apache-spark-examples-sparkpi-e5bedf78e776ea9d-driver 0/1 Completed 0 44s
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 172m
$ k describe quota
Name: service
Namespace: default
Resource Used Hard
-------- ---- ----
services 1 3
```
### Does this PR introduce _any_ user-facing change?
Yes, this PR adds a new configuration, `spark.kubernetes.driver.service.deleteOnTermination`, and enables it by default.
The change is documented at the migration guide.
### How was this patch tested?
Pass the CIs.
This is tested with K8s IT manually.
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
- Run SparkR on simple dataframe.R example
Run completed in 19 minutes, 9 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
Closes #32226 from dongjoon-hyun/SPARK-35131.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
* [SPARK-35103][SQL] Make TypeCoercion rules more efficient
## What changes were proposed in this pull request?
This PR fixes a couple of things in TypeCoercion rules:
- Only run the propagate types step if the children of a node have output attributes with changed dataTypes and/or nullability. This is implemented as custom tree transformation. The TypeCoercion rules now only implement a partial function.
- Combine multiple type coercion rules into a single rule. Multiple rules are applied in single tree traversal.
- Reduce calls to conf.get in DecimalPrecision. This now happens once per tree traversal, instead of once per matched expression.
- Reduce the use of withNewChildren.
This brings down the number of CPU cycles spend in analysis by ~28% (benchmark: 10 iterations of all TPC-DS queries on SF10).
## How was this patch tested?
Existing tests.
Closes #32208 from sigmod/coercion.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: herman <herman@databricks.com>
* [SPARK-35117][UI] Change progress bar back to highlight ratio of tasks in progress
### What changes were proposed in this pull request?
Small UI update to add highlighting the number of tasks in progress in a stage/job instead of highlighting the whole in progress stage/job. This was the behavior pre Spark 3.1 and the bootstrap 4 upgrade.
### Why are the changes needed?
To add back in functionality lost between 3.0 and 3.1. This provides a great visual queue of how much of a stage/job is currently being run.
### Does this PR introduce _any_ user-facing change?
Small UI change.
Before:

After (and pre Spark 3.1):

### How was this patch tested?
Updated existing UT.
Closes #32214 from Kimahriman/progress-bar-started.
Authored-by: Adam Binford <adamq43@gmail.com>
Signed-off-by: Kousuke Saruta <sarutak@oss.nttdata.com>
* [SPARK-35080][SQL] Only allow a subset of correlated equality predicates when a subquery is aggregated
### What changes were proposed in this pull request?
This PR updated the `foundNonEqualCorrelatedPred` logic for correlated subqueries in `CheckAnalysis` to only allow correlated equality predicates that guarantee one-to-one mapping between inner and outer attributes, instead of all equality predicates.
### Why are the changes needed?
To fix correctness bugs. Before this fix Spark can give wrong results for certain correlated subqueries that pass CheckAnalysis:
Example 1:
```sql
create or replace view t1(c) as values ('a'), ('b')
create or replace view t2(c) as values ('ab'), ('abc'), ('bc')
select c, (select count(*) from t2 where t1.c = substring(t2.c, 1, 1)) from t1
```
Correct results: [(a, 2), (b, 1)]
Spark results:
```
+---+-----------------+
|c |scalarsubquery(c)|
+---+-----------------+
|a |1 |
|a |1 |
|b |1 |
+---+-----------------+
```
Example 2:
```sql
create or replace view t1(a, b) as values (0, 6), (1, 5), (2, 4), (3, 3);
create or replace view t2(c) as values (6);
select c, (select count(*) from t1 where a + b = c) from t2;
```
Correct results: [(6, 4)]
Spark results:
```
+---+-----------------+
|c |scalarsubquery(c)|
+---+-----------------+
|6 |1 |
|6 |1 |
|6 |1 |
|6 |1 |
+---+-----------------+
```
### Does this PR introduce _any_ user-facing change?
Yes. Users will not be able to run queries that contain unsupported correlated equality predicates.
### How was this patch tested?
Added unit tests.
Closes #32179 from allisonwang-db/spark-35080-subquery-bug.
Lead-authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Co-authored-by: Wenchen Fan <cloud0fan@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-35052][SQL] Use static bits for AttributeReference and Literal
### What changes were proposed in this pull request?
- Share a static ImmutableBitSet for `treePatternBits` in all object instances of AttributeReference.
- Share three static ImmutableBitSets for `treePatternBits` in three kinds of Literals.
- Add an ImmutableBitSet as a subclass of BitSet.
### Why are the changes needed?
Reduce the additional memory usage caused by `treePatternBits`.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Existing tests.
Closes #32157 from sigmod/leaf.
Authored-by: Yingyi Bu <yingyi.bu@databricks.com>
Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
* [SPARK-35134][BUILD][TESTS] Manually exclude redundant netty jars in SparkBuild.scala to avoid version conflicts in test
### What changes were proposed in this pull request?
The following logs will print when Jenkins execute [PySpark pip packaging tests](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/137500/console):
```
copying deps/jars/netty-all-4.1.51.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-buffer-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-codec-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-common-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-handler-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-resolver-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-transport-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-transport-native-epoll-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
```
There will be 2 different versions of netty4 jars copied to the jars directory, but the `netty-xxx-4.1.50.Final.jar` not in maven `dependency:tree `, but spark only needs to rely on `netty-all-xxx.jar`.
So this pr try to add new `ExclusionRule`s to `SparkBuild.scala` to exclude unnecessary netty 4 dependencies.
### Why are the changes needed?
Make sure that only `netty-all-xxx.jar` is used in the test to avoid possible jar conflicts.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
- Pass the Jenkins or GitHub Action
- Check Jenkins log manually, there should be only
`copying deps/jars/netty-all-4.1.51.Final.jar -> pyspark-3.2.0.dev0/deps/jars`
and there should be no such logs as
```
copying deps/jars/netty-buffer-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-codec-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-common-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-handler-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-resolver-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-transport-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
copying deps/jars/netty-transport-native-epoll-4.1.50.Final.jar -> pyspark-3.2.0.dev0/deps/jars
```
Closes #32230 from LuciferYang/SPARK-35134.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [SPARK-35018][SQL][TESTS] Check transferring of year-month intervals via Hive Thrift server
### What changes were proposed in this pull request?
1. Add a test to check that Thrift server is able to collect year-month intervals and transfer them via thrift protocol.
2. Improve similar test for day-time intervals. After the changes, the test doesn't depend on the result of date subtractions. In the future, the type of date subtract can be changed. So, current PR should make the test tolerant to the changes.
### Why are the changes needed?
To improve test coverage.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
By running the modified test suite:
```
$ ./build/sbt -Phive -Phive-thriftserver "test:testOnly *SparkThriftServerProtocolVersionsSuite"
```
Closes #32240 from MaxGekk/year-month-interval-thrift-protocol.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-34974][SQL] Improve subquery decorrelation framework
### What changes were proposed in this pull request?
This PR implements the decorrelation technique in the paper "Unnesting Arbitrary Queries" by T. Neumann; A. Kemper
(http://www.btw-2015.de/res/proceedings/Hauptband/Wiss/Neumann-Unnesting_Arbitrary_Querie.pdf). It currently supports Filter, Project, Aggregate, Join, and UnaryNode that passes CheckAnalysis.
This feature can be controlled by the config `spark.sql.optimizer.decorrelateInnerQuery.enabled` (default: true).
A few notes:
1. This PR does not relax any constraints in CheckAnalysis for correlated subqueries, even though some cases can be supported by this new framework, such as aggregate with correlated non-equality predicates. This PR focuses on adding the new framework and making sure all existing cases can be supported. Constraints can be relaxed gradually in the future via separate PRs.
2. The new framework is only enabled for correlated scalar subqueries, as the first step. EXISTS/IN subqueries can be supported in the future.
### Why are the changes needed?
Currently, Spark has limited support for correlated subqueries. It only allows `Filter` to reference outer query columns and does not support non-equality predicates when the subquery is aggregated. This new framework will allow more operators to host outer column references and support correlated non-equality predicates and more types of operators in correlated subqueries.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing unit and SQL query tests and new optimizer plan tests.
Closes #32072 from allisonwang-db/spark-34974-decorrelation.
Authored-by: allisonwang-db <66282705+allisonwang-db@users.noreply.github.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-35068][SQL] Add tests for ANSI intervals to HiveThriftBinaryServerSuite
### What changes were proposed in this pull request?
After the PR https://github.com/apache/spark/pull/32209, this should be possible now.
We can add test case for ANSI intervals to HiveThriftBinaryServerSuite
### Why are the changes needed?
Add more test case
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added UT
Closes #32250 from AngersZhuuuu/SPARK-35068.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-33976][SQL][DOCS] Add a SQL doc page for a TRANSFORM clause
### What changes were proposed in this pull request?
Add doc about `TRANSFORM` and related function.

### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Not need
Closes #31010 from AngersZhuuuu/SPARK-33976.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: angerszhu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-34877][CORE][YARN] Add the code change for adding the Spark AM log link in spark UI
### What changes were proposed in this pull request?
On Running Spark job with yarn and deployment mode as client, Spark Driver and Spark Application master launch in two separate containers. In various scenarios there is need to see Spark Application master logs to see the resource allocation, Decommissioning status and other information shared between yarn RM and Spark Application master.
In Cluster mode Spark driver and Spark AM is on same container, So Log link of the driver already there to see the logs in Spark UI
This PR is for adding the spark AM log link for spark job running in the client mode for yarn. Instead of searching the container id and then find the logs. We can directly check in the Spark UI
This change is only for showing the AM log links in the Client mode when resource manager is yarn.
### Why are the changes needed?
Till now the only way to check this by finding the container id of the AM and check the logs either using Yarn utility or Yarn RM Application History server.
This PR is for adding the spark AM log link for spark job running in the client mode for yarn. Instead of searching the container id and then find the logs. We can directly check in the Spark UI
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added the unit test also checked the Spark UI
**In Yarn Client mode**
Before Change

After the Change - The AM info is there

AM Log

**In Yarn Cluster Mode** - The AM log link will not be there

Closes #31974 from SaurabhChawla100/SPARK-34877.
Authored-by: SaurabhChawla <s.saurabhtim@gmail.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
* [SPARK-34035][SQL] Refactor ScriptTransformation to remove input parameter and replace it by child.output
### What changes were proposed in this pull request?
Refactor ScriptTransformation to remove input parameter and replace it by child.output
### Why are the changes needed?
refactor code
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existed UT
Closes #32228 from AngersZhuuuu/SPARK-34035.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: AngersZhuuuu <angers.zhu@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-34338][SQL] Report metrics from Datasource v2 scan
### What changes were proposed in this pull request?
This patch proposes to leverage `CustomMetric`, `CustomTaskMetric` API to report custom metrics from DS v2 scan to Spark.
### Why are the changes needed?
This is related to #31398. In SPARK-34297, we want to add a couple of metrics when reading from Kafka in SS. We need some public API change in DS v2 to make it possible. This extracts only DS v2 change and make it general for DS v2 instead of micro-batch DS v2 API.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test.
Implement a simple test DS v2 class locally and run it:
```scala
scala> import org.apache.spark.sql.execution.datasources.v2._
import org.apache.spark.sql.execution.datasources.v2._
scala> classOf[CustomMetricDataSourceV2].getName
res0: String = org.apache.spark.sql.execution.datasources.v2.CustomMetricDataSourceV2
scala> val df = spark.read.format(res0).load()
df: org.apache.spark.sql.DataFrame = [i: int, j: int]
scala> df.collect
```
<img width="703" alt="Screen Shot 2021-03-30 at 11 07 13 PM" src="https://user-images.githubusercontent.com/68855/113098080-d8a49800-91ac-11eb-8681-be408a0f2e69.png">
Closes #31451 from viirya/dsv2-metrics.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-35145][SQL] CurrentOrigin should support nested invoking
### What changes were proposed in this pull request?
`CurrentOrigin` is a thread-local variable to track the original SQL line position in plan/expression. Usually, we set `CurrentOrigin`, create `TreeNode` instances, and reset `CurrentOrigin`.
This PR updates the last step to set `CurrentOrigin` to its previous value, instead of resetting it. This is necessary when we invoke `CurrentOrigin` in a nested way, like with subqueries.
### Why are the changes needed?
To keep the original SQL line position in the error message in more cases.
### Does this PR introduce _any_ user-facing change?
No, only minor error message changes.
### How was this patch tested?
existing tests
Closes #32249 from cloud-fan/origin.
Authored-by: Wenchen Fan <wenchen@databricks.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
* [SPARK-34472][YARN] Ship ivySettings file to driver in cluster mode
### What changes were proposed in this pull request?
In YARN, ship the `spark.jars.ivySettings` file to the driver when using `cluster` deploy mode so that `addJar` is able to find it in order to resolve ivy paths.
### Why are the changes needed?
SPARK-33084 introduced support for Ivy paths in `sc.addJar` or Spark SQL `ADD JAR`. If we use a custom ivySettings file using `spark.jars.ivySettings`, it is loaded at https://github.com/apache/spark/blob/b26e7b510bbaee63c4095ab47e75ff2a70e377d7/core/src/main/scala/org/apache/spark/deploy/SparkSubmit.scala#L1280. However, this file is only accessible on the client machine. In YARN cluster mode, this file is not available on the driver and so `addJar` fails to find it.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Added unit tests to verify that the `ivySettings` file is localized by the YARN client and that a YARN cluster mode application is able to find to load the `ivySettings` file.
Closes #31591 from shardulm94/SPARK-34472.
Authored-by: Shardul Mahadik <smahadik@linkedin.com>
Signed-off-by: Thomas Graves <tgraves@apache.org>
* [SPARK-35153][SQL] Make textual representation of ANSI interval operators more readable
### What changes were proposed in this pull request?
In the PR, I propose to override the `sql` and `toString` methods of the expressions that implement operators over ANSI intervals (`YearMonthIntervalType`/`DayTimeIntervalType`), and replace internal expression class names by operators like `*`, `/` and `-`.
### Why are the changes needed?
Proposed methods should make the textual representation of such operators more readable, and potentially parsable by Spark SQL parser.
### Does this PR introduce _any_ user-facing change?
Yes. This can influence on column names.
### How was this patch tested?
By running existing test suites for interval and datetime expressions, and re-generating the `*.sql` tests:
```
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z interval.sql"
$ build/sbt "sql/testOnly *SQLQueryTestSuite -- -z datetime.sql"
```
Closes #32262 from MaxGekk/interval-operator-sql.
Authored-by: Max Gekk <max.gekk@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35132][BUILD][CORE] Upgrade netty-all to 4.1.63.Final
### What changes were proposed in this pull request?
There are 3 CVE problems were found after netty 4.1.51.Final as follows:
- [CVE-2021-21409](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-21409)
- [CVE-2021-21295](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-21295)
- [CVE-2021-21290](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-21290)
So the main change of this pr is upgrade netty-all to 4.1.63.Final avoid these potential risks.
Another change is to clean up deprecated api usage: [Tiny caches have been merged into small caches](https://github.com/netty/netty/blob/4.1/buffer/src/main/java/io/netty/buffer/PooledByteBufAllocator.java#L447-L455)(after [netty#10267](https://github.com/netty/netty/pull/10267)) and [should use PooledByteBufAllocator(boolean, int, int, int, int, int, int, boolean, int)](https://github.com/netty/netty/blob/4.1/buffer/src/main/java/io/netty/buffer/PooledByteBufAllocator.java#L227-L239) api to create `PooledByteBufAllocator`.
### Why are the changes needed?
Upgrade netty-all to 4.1.63.Final avoid CVE problems.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass the Jenkins or GitHub Action
Closes #32227 from LuciferYang/SPARK-35132.
Authored-by: yangjie01 <yangjie01@baidu.com>
Signed-off-by: Sean Owen <srowen@gmail.com>
* [SPARK-35044][SQL][FOLLOWUP][TEST-HADOOP2.7] Fix hadoop 2.7 test due to diff between hadoop 2.7 and hadoop 3
### What changes were proposed in this pull request?
dfs.replication is inconsistent from hadoop 2.x to 3.x, so in this PR we use `dfs.hosts` to verify per https://github.com/apache/spark/pull/32144#discussion_r616833099
```
== Results ==
!== Correct Answer - 1 == == Spark Answer - 1 ==
!struct<> struct<key:string,value:string>
![dfs.replication,<undefined>] [dfs.replication,3]
```
### Why are the changes needed?
fix Jenkins job with Hadoop 2.7
### Does this PR introduce _any_ user-facing change?
test only change
### How was this patch tested?
test only change
Closes #32263 from yaooqinn/SPARK-35044-F.
Authored-by: Kent Yao <yao@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
* [SPARK-35113][SQL] Support ANSI intervals in the Hash expression
### What changes were proposed in this pull request?
Support ANSI interval in HashExpression and add UT
### Why are the changes needed?
Support ANSI interval in HashExpression
### Does this PR introduce _any_ user-facing change?
User can pass ANSI interval in HashExpression function
### How was this patch tested?
Added UT
Closes #32259 from AngersZhuuuu/SPARK-35113.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Max Gekk <max.gekk@gmail.com>
* [SPARK-35120][INFRA][FOLLOW-UP] Try catch an error to show the correct guidance
### What changes were proposed in this pull request?
This PR proposes to handle 404 not found, see https://github.com/apache/spark/pull/32255/checks?check_run_id=2390446579 as an example.
If a fork does not have any previous workflow runs, it seems throwing 4…
wangyum
added a commit
that referenced
this pull request
May 26, 2023
… expressions from aggregate expressions without aggregate function (#941) * [SPARK-34581][SQL] Don't optimize out grouping expressions from aggregate expressions without aggregate function ### What changes were proposed in this pull request? This PR adds a new rule `PullOutGroupingExpressions` to pull out complex grouping expressions to a `Project` node under an `Aggregate`. These expressions are then referenced in both grouping expressions and aggregate expressions without aggregate functions to ensure that optimization rules don't change the aggregate expressions to invalid ones that no longer refer to any grouping expressions. ### Why are the changes needed? If aggregate expressions (without aggregate functions) in an `Aggregate` node are complex then the `Optimizer` can optimize out grouping expressions from them and so making aggregate expressions invalid. Here is a simple example: ``` SELECT not(t.id IS NULL) , count(*) FROM t GROUP BY t.id IS NULL ``` In this case the `BooleanSimplification` rule does this: ``` === Applying Rule org.apache.spark.sql.catalyst.optimizer.BooleanSimplification === !Aggregate [isnull(id#222)], [NOT isnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#226, count(1) AS c#224L] +- Project [value#219 AS id#222] +- Project [value#219 AS id#222] +- LocalRelation [value#219] +- LocalRelation [value#219] ``` where `NOT isnull(id#222)` is optimized to `isnotnull(id#222)` and so it no longer refers to any grouping expression. Before this PR: ``` == Optimized Logical Plan == Aggregate [isnull(id#222)], [isnotnull(id#222) AS (NOT (id IS NULL))#234, count(1) AS c#232L] +- Project [value#219 AS id#222] +- LocalRelation [value#219] ``` and running the query throws an error: ``` Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] java.lang.IllegalStateException: Couldn't find id#222 in [isnull(id#222)#230,count(1)#226L] ``` After this PR: ``` == Optimized Logical Plan == Aggregate [_groupingexpression#233], [NOT _groupingexpression#233 AS (NOT (id IS NULL))#230, count(1) AS c#228L] +- Project [isnull(value#219) AS _groupingexpression#233] +- LocalRelation [value#219] ``` and the query works. ### Does this PR introduce _any_ user-facing change? Yes, the query works. ### How was this patch tested? Added new UT. Closes #32396 from peter-toth/SPARK-34581-keep-grouping-expressions-2. Authored-by: Peter Toth <peter.toth@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit cfc0495) * [SPARK-34037][SQL] Remove unnecessary upcasting for Avg & Sum which handle by themself internally ### What changes were proposed in this pull request? The type-coercion for numeric types of average and sum is not necessary at all, as the resultType and sumType can prevent the overflow. ### Why are the changes needed? rm unnecessary logic which may cause potential performance regressions ### Does this PR introduce _any_ user-facing change? no ### How was this patch tested? tpcds tests for plan Closes #31079 from yaooqinn/SPARK-34037. Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com> (cherry picked from commit a235c3b) Co-authored-by: Peter Toth <peter.toth@gmail.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
(This follows from a side point on SPARK-1133, in discussion of the PR: #164 )
Commons IO is barely used in the project, and can easily be replaced with equivalent calls to Guava or the existing Spark
Utils.scalaclass.Removing a dependency feels good, and this one in particular can get a little problematic since Hadoop uses it too.