[SPARK-29431][WebUI] Improve Web UI / Sql tab visualization with cached dataframes. #26082
Conversation
|
ok to test |
|
Test build #111998 has finished for PR 26082 at commit
|
967b4f5
to
7d0ff6a
Compare
|
Conflicts resolved |
|
Test build #112183 has finished for PR 26082 at commit
|
|
@joshrosen-stripe @wangyum Do you think it is and interesting feature for you too? |
|
I don't have the bandwidth to shepherd / review this right now, but I am following along because I'm excited to see this UX pain-point get addressed: the SQL tab is one of my go-to debugging tools, but (prior to this PR) it was really unhelpful when using caching. I do have a question about the new UX, though: With today's existing behavior, the "number of rows scanned" metrics from inputs always reflect the total data volume read: if I have a table with a 100k rows and I scan the whole thing then I'll see "100k input rows" on the scan node. With your PR, I'd expect to see 100k rows scanned during the job which initially populates the cache. What happens if we're reading the cache a second time? It sounds like we'd still display the cached part of the plan, but what metrics would we show? If we had 100% cache hits, would we see empty SQL metrics on the UI (e.g. zero rows scanned)? If we had a mixture of cache hits and misses, would we see metrics corresponding only to what's been recomputed? I have slight concerns that the metrics might be confusing except to eagle-eyed readers who spot that there's a cache node in the middle of a plan. Maybe we could color nodes upstream of a cache? Or somehow give a clearer visual indication of the cache nodes, maybe via a different color or something? I'm not sure what's the right approach here. |
|
Hi @joshrosen-stripe |




|
Hi @srowen, |
|
I don't have a strong opinion on this. Yes I guess the question is whether it clarifies more than confuses. So this always adds the 'relation' to the graph? Sounds plausible but I don't know if for some reason that isn't meant to be shown here with the other nodes. I don't necessarily think the metrics are an issue, but is there any indication at all that the source is a cached DataFrame in the output? |
|
About your questions, yes, it add the relation to the graph always when appears InMemoryTableScan node. Looking for this kind of node it seems only appear when the chache method is called so there is no other uses of InMemorytableScan. |
|
I think it could be OK. @cloud-fan do you have any opinions - is there any downside to showing more info this way? |
|
Expanding to @dongjoon-hyun maybe for a check - does this sound reasonable? I don't see a downside other than a bigger graph, but it contains more info. |
what do you mean by partial cached df? In general this idea LGTM. Can you compare the UI with a parquet scan? Similar to parquet scan, the cached table also supports filter pushdown. Maybe better to display it so that users can understand why a query doesn't read all the rows of a cached table. |
|
With partial dataframe I mean, for example, when you have a cached dataframe, and the first action you make on it is show(10), only a few elements of this dataframe will be cached. You could do count() on the cached dataframe and this will make the rest of the elements be cached. This is what I'm trying to show with the images. I attach an example with a simple parquet file |


c030902
to
09b4ed3
Compare
|
@dongjoon-hyun What is your opinion about this changes? Thank you |
|
Test build #114426 has finished for PR 26082 at commit
|
|
Test build #114424 has finished for PR 26082 at commit
|
|
Hello, is there any ETA on when this might be merged? I have some follow-up changes I'd like to create a PR for these JIRAs. |
|
I don't have an opinion on the UI change; I know there is also some rumbling that it's already got far too much going on. I wouldn't open a bunch of JIRAs or changes just yet, unless they are clear wins or simplifications. |
| val relation = plan match { | ||
| case inMemTab: InMemoryTableScanExec => Seq(fromSparkPlan(inMemTab.relation.cachedPlan)) | ||
| case _ => Seq() | ||
| } |
There was a problem hiding this comment.
Cannot we just add InMemoryTableScanExec.relation.cachedPlan into children? Then I think you don't need to add relation to SparkPlanInfo.
There was a problem hiding this comment.
I do in that way because I don't want to impact in other parts of the code. As in InMemoryTableScan is treated as a relation(not a children) I do in the same way in SparkPlanInfo.
It's possible that if we add directly to children it don't affect unexpectedly but I'm not sure.
There was a problem hiding this comment.
I think SparkPlanInfo is only used for UI? If so, adding cachedPlan into children should be fine.
| @@ -33,7 +34,8 @@ class SparkPlanInfo( | |||
| val simpleString: String, | |||
| val children: Seq[SparkPlanInfo], | |||
| val metadata: Map[String, String], | |||
| val metrics: Seq[SQLMetricInfo]) { | |||
| val metrics: Seq[SQLMetricInfo], | |||
| val relation: Seq[SparkPlanInfo] = Seq()) { | |||
There was a problem hiding this comment.
I'm a little worried about adding a new parameter to SparkPlanInfo. What's the semantic of it for general cases?
There was a problem hiding this comment.
I tried to replicate the same structure that in InMemoryTableScan where the relation is a different element and is not a children.
This attribute has a default value so it not impact in any case where is not used. Only in this case is used. Do you think there is a better way to solve it without the new attribute? Thanks!
There was a problem hiding this comment.
Can we treat InMemoryTableScan.relation as its child in the UI?
|
@viirya @cloud-fan I'm going to change the PR to add directly to the child. Thanks for your comments |
09b4ed3
to
c383de4
Compare
|
@viirya @cloud-fan I have updated the PR with the comments. Sorry for the wait! |
|
Test build #118482 has finished for PR 26082 at commit
|
|
LGTM, cc @gengliangwang |
|
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. |
|
@cloud-fan @gengliangwang what are the next steps with this PR once @planga82 resolved conflicts with master? |
|
Let's fix the conflict and get it merged. |
|
@planga82 the conflict was simple. I am not sure if you are active recently. So I just resolved it for you. |
|
ok to test |
|
Thanks guys for picking this up again, awesome! |
|
Thanks @gengliangwang ! |
|
Test build #123427 has finished for PR 26082 at commit
|
|
Thanks, merging to master |
What changes were proposed in this pull request?
With this pull request I want to improve the Web UI / SQL tab visualization. The principal problem that I find is when you have a cache in your plan, the SQL visualization don’t show any information about the part of the plan that has been cached.
Before the change
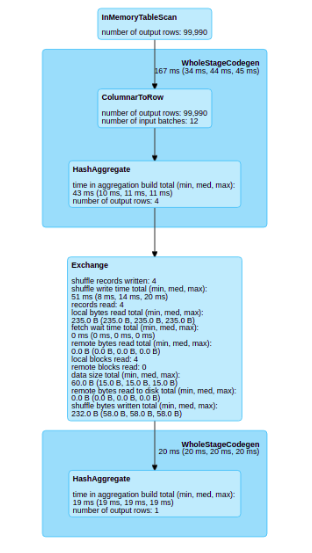

After the change
Why are the changes needed?
When we have a SQL plan with cached dataframes we lose the graphical information of this dataframe in the sql tab
Does this PR introduce any user-facing change?
Yes, in the sql tab
How was this patch tested?
Unit testing and manual tests throught spark shell