[SPARK-28227][SQL] Support projection, aggregate/window functions, and lateral view in the TRANSFORM clause #29087
Conversation
|
Test build #125770 has finished for PR 29087 at commit
|
sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4
Outdated
Show resolved
Hide resolved
| @@ -2558,6 +2558,131 @@ abstract class SQLQuerySuiteBase extends QueryTest with SQLTestUtils with TestHi | |||
| } | |||
| } | |||
| } | |||
|
|
|||
| test("SPARK-28227: test script transform with aggregation") { | |||
There was a problem hiding this comment.
Could you move the tests into SQLQueryTestSuite?
There was a problem hiding this comment.
Could you move the tests into
SQLQueryTestSuite?
This should wait for #29085, since currently we can't use script transform in sql/core
There was a problem hiding this comment.
@maropu
UT have been moved to transform.sql
|
Test build #125797 has finished for PR 29087 at commit
|
|
retest this please |
|
Test build #125872 has finished for PR 29087 at commit
|
|
retest this please |
|
Test build #127650 has finished for PR 29087 at commit
|
|
retest this please |
|
@HyukjinKwon as metioned in #29087 (comment). can you also help review that pr |
|
Test build #128276 has finished for PR 29087 at commit
|
|
Test build #128287 has finished for PR 29087 at commit
|
|
Test build #128289 has finished for PR 29087 at commit
|
|
Test build #130190 has finished for PR 29087 at commit
|
|
Test build #133214 has finished for PR 29087 at commit
|
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Kubernetes integration test status failure |
|
Test build #136513 has finished for PR 29087 at commit
|
|
retest this please |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #136727 has finished for PR 29087 at commit
|
|
retest this please |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #136739 has finished for PR 29087 at commit
|
|
Took a quick look. Looks ok to me too. |
|
retest this please |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #137051 has finished for PR 29087 at commit
|
|
retest this please |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #137209 has finished for PR 29087 at commit
|
|
Thanks! Merged to master. |
| SET spark.sql.parser.quotedRegexColumnNames=true; | ||
|
|
||
| SELECT TRANSFORM(`(a|b)?+.+`) | ||
| USING 'cat' AS (c) |
There was a problem hiding this comment.
nit: 2 spaces indentation
| FROM script_trans; | ||
|
|
||
| SET spark.sql.parser.quotedRegexColumnNames=false; | ||
|
|
There was a problem hiding this comment.
can we test something like TRANSFORM(distinct a, b) and check the error message?
There was a problem hiding this comment.
Will raise a follow up soon
|
late LGTM |
…e the error clear ### What changes were proposed in this pull request? According to #29087 (comment), add UT in `transform.sql` It seems that distinct is not recognized as a reserved word here ``` -- !query explain extended SELECT TRANSFORM(distinct b, a, c) USING 'cat' AS (a, b, c) FROM script_trans WHERE a <= 4 -- !query schema struct<plan:string> -- !query output == Parsed Logical Plan == 'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false) +- 'Project ['distinct AS b#x, 'a, 'c] +- 'Filter ('a <= 4) +- 'UnresolvedRelation [script_trans], [], false == Analyzed Logical Plan == org.apache.spark.sql.AnalysisException: cannot resolve 'distinct' given input columns: [script_trans.a, script_trans.b, script_trans.c]; line 1 pos 34; 'ScriptTransformation [*], cat, [a#x, b#x, c#x], ScriptInputOutputSchema(List(),List(),None,None,List(),List(),None,None,false) +- 'Project ['distinct AS b#x, a#x, c#x] +- Filter (a#x <= 4) +- SubqueryAlias script_trans +- View (`script_trans`, [a#x,b#x,c#x]) +- Project [cast(a#x as int) AS a#x, cast(b#x as int) AS b#x, cast(c#x as int) AS c#x] +- Project [a#x, b#x, c#x] +- SubqueryAlias script_trans +- LocalRelation [a#x, b#x, c#x] ``` Hive's error 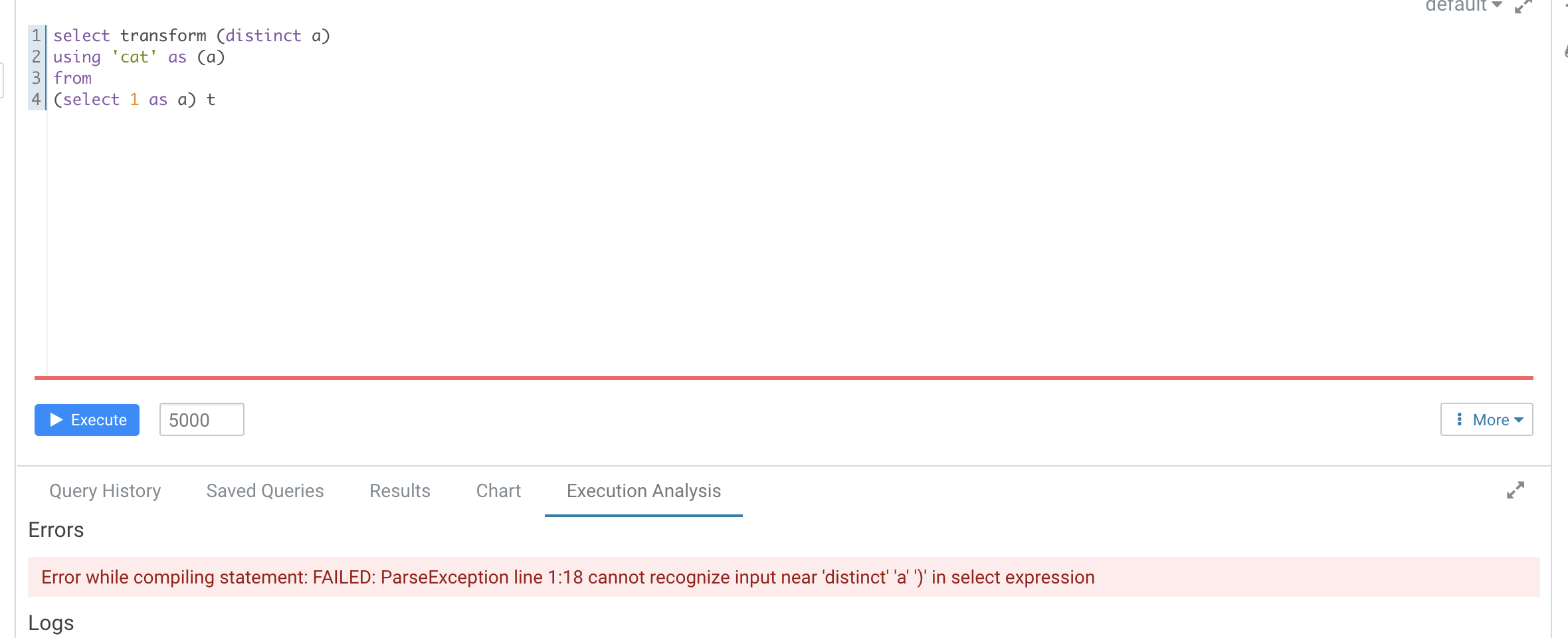 ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added Ut Closes #32149 from AngersZhuuuu/SPARK-28227-new-followup. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
| @@ -1558,14 +1558,9 @@ class Analyzer(override val catalogManager: CatalogManager) | |||
| } else { | |||
| a.copy(aggregateExpressions = buildExpandedProjectList(a.aggregateExpressions, a.child)) | |||
| } | |||
| // If the script transformation input contains Stars, expand it. | |||
| // TODO: Remove this logic and see SPARK-34035 | |||
There was a problem hiding this comment.
Please do not forget to fix this, @AngersZhuuuu
What changes were proposed in this pull request?
For Spark SQL, it can't support script transform SQL with aggregationClause/windowClause/LateralView.
This case we can't directly migration Hive SQL to Spark SQL.
In this PR, we treat all script transform statement's query part (exclude transform about part) as a separate query block and solve it as ScriptTransformation's child and pass a UnresolvedStart as ScriptTransform's input. Then in analyzer level, we pass child's output as ScriptTransform's input. Then we can support all kind of normal SELECT query combine with script transformation.
Such as transform with aggregation:
When we build AST, we treat it as
then in Analyzer's
ResolveReferences, resolve* (UnresolvedStar), then sql behavior likeAbout UT, in this pr we add a lot of different SQL to check we can support all kind of such SQL and each kind of expressions can work well, such as alias, case when, binary compute etc...
Why are the changes needed?
Support transform with aggregateClause/windowClause/LateralView etc , make sql migration more smoothly
Does this PR introduce any user-facing change?
User can write transform with aggregateClause/windowClause/LateralView.
How was this patch tested?
Added UT