[SPARK-34637] [SQL] Support DPP + AQE when the broadcast exchange can be reused #31756
Conversation
|
@cloud-fan Please help me review if you have available time. Thanks for your help. |
|
Test build #135798 has finished for PR 31756 at commit
|
| @@ -1409,4 +1409,17 @@ class DynamicPartitionPruningSuiteAEOff extends DynamicPartitionPruningSuiteBase | |||
| with DisableAdaptiveExecutionSuite | |||
|
|
|||
| class DynamicPartitionPruningSuiteAEOn extends DynamicPartitionPruningSuiteBase | |||
| with EnableAdaptiveExecutionSuite | |||
| with EnableAdaptiveExecutionSuite { | |||
| test("simple inner join triggers DPP with mock-up tables test") { | |||
There was a problem hiding this comment.
Only for debug. I will remove this test later.
|
Can you briefly introduce your approach? |
|
@cloud-fan
|
| SubqueryBroadcastExec(name, index, buildKeys, reuseQueryStage) | ||
|
|
||
| val canReuseExchange = conf.exchangeReuseEnabled && buildKeys.nonEmpty && | ||
| plan.find { |
There was a problem hiding this comment.
PlanAdaptiveDynamicPruningFilters is a stage optimization rule and the input plan is only a small piece of the plan tree (for one stage). I think we should put the entire plan as a parameter of this rule, when creating this rule in AdaptiveSparkPlanExec
...c/main/scala/org/apache/spark/sql/execution/adaptive/PlanAdaptiveDynamicPruningFilters.scala
Outdated
Show resolved
Hide resolved
|
Kubernetes integration test unable to build dist. exiting with code: 1 |
|
Test build #136696 has finished for PR 31756 at commit
|
|
Test build #751342356 for PR 31756 at commit |
|
Test build #137409 has finished for PR 31756 at commit
|
|
Test build #751377372 for PR 31756 at commit |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
| @@ -310,6 +310,11 @@ case class AdaptiveSparkPlanExec( | |||
| rdd | |||
| } | |||
|
|
|||
| override def doExecuteBroadcast[T](): broadcast.Broadcast[T] = { | |||
| val broadcastPlan = getFinalPhysicalPlan() | |||
| broadcastPlan.doExecuteBroadcast() | |||
There was a problem hiding this comment.
nit: getFinalPhysicalPlan().doExecuteBroadcast()
|
|
||
| /** | ||
| * A rule to insert dynamic pruning predicates in order to reuse the results of broadcast. | ||
| */ | ||
| case class PlanAdaptiveDynamicPruningFilters( | ||
| stageCache: TrieMap[SparkPlan, QueryStageExec]) extends Rule[SparkPlan] { | ||
| originalPlan: SparkPlan) extends Rule[SparkPlan] { |
| case _ => false | ||
| }.isDefined | ||
|
|
||
| if(canReuseExchange) { |
There was a problem hiding this comment.
nit: if (canReuseExchange)
| @@ -41,15 +40,26 @@ case class PlanAdaptiveDynamicPruningFilters( | |||
| adaptivePlan: AdaptiveSparkPlanExec), exprId, _)) => | |||
| val packedKeys = BindReferences.bindReferences( | |||
There was a problem hiding this comment.
we can move this into if (canReuseExchange)
|
In general LGTM, can we add some tests? |
|
Test build #751980907 for PR 31756 at commit |
|
Test build #137410 has finished for PR 31756 at commit
|
| // +- HashAggregate | ||
| // +- Filter | ||
| // +- FileScan | ||
| // +- SubqueryBroadcast |
There was a problem hiding this comment.
subquery has different symbols in the tree string format. please try to explain some plans locally and update this comment.
| // +- FileScan | ||
| // +- SubqueryBroadcast | ||
| // +- AdaptiveSparkPlan | ||
| // +- BroadcastQueryStage |
There was a problem hiding this comment.
there is no other place to reuse this broadcast, right?
There was a problem hiding this comment.
This broadcast only be reused in the build side.
| // +- FileScan | ||
| // +- SubqueryBroadcast | ||
| // +- AdaptiveSparkPlan | ||
| // +- BroadcastQueryStage |
There was a problem hiding this comment.
how is broadcast before the FileScan? what is being broadcast
There was a problem hiding this comment.
This broadcast is in the DPP subquery of the FileScan. It will broadcast the results of the build side and then prune the dataset.
There was a problem hiding this comment.
Can you make it more clear that this is the subquery in the file scan node, not the child of it?
|
@JkSelf will you have time to look at the questions and comments? |
|
@tgravescs Sorry for the delay responses. |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
made this comment in one of the thread but it got collapse so making it again. |
|
Test build #138203 has finished for PR 31756 at commit
|
|
@tgravescs This approach mainly contain two steps.
|
| if (canReuseExchange) { | ||
| exchange.setLogicalLink(adaptivePlan.executedPlan.logicalLink.get) | ||
| val newAdaptivePlan = AdaptiveSparkPlanExec( | ||
| exchange, adaptivePlan.context, adaptivePlan.preprocessingRules, true) |
There was a problem hiding this comment.
ditto: adaptivePlan.copy(inputPlan = exchange)
| @@ -1463,6 +1474,37 @@ abstract class DynamicPartitionPruningSuiteBase | |||
| } | |||
| } | |||
| } | |||
|
|
|||
| test("SPARK-34637: test DPP side broadcast query stage is created firstly") { | |||
There was a problem hiding this comment.
nit: SPARK-34637: DPP ... remove the test
| test("SPARK-34637: test DPP side broadcast query stage is created firstly") { | ||
| withSQLConf(SQLConf.DYNAMIC_PARTITION_PRUNING_REUSE_BROADCAST_ONLY.key -> "true") { | ||
| val df = sql( | ||
| """ WITH view1 as ( |
| // +- HashAggregate | ||
| // +- Filter | ||
| // +- FileScan | ||
| // Dynamicpruning Subquery |
There was a problem hiding this comment.
Did try to explain some queries locally? If you did you should see how subqueries are displayed. For example, select 1, (select 2):
Project [1 AS 1#7, scalar-subquery#6 [] AS scalarsubquery()#9]
: +- Project [2 AS 2#8]
: +- OneRowRelation
+- OneRowRelation
There was a problem hiding this comment.
Yes. In this case, it looks like the following:
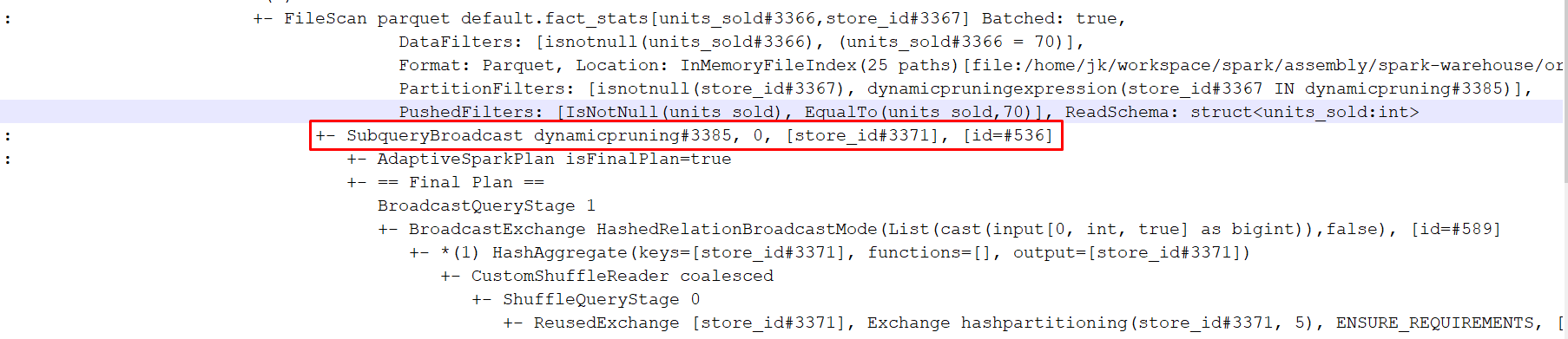
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #138367 has finished for PR 31756 at commit
|
|
Test build #138376 has finished for PR 31756 at commit
|
|
thanks, merging to master! |
…be reused We have supported DPP in AQE when the join is Broadcast hash join before applying the AQE rules in [SPARK-34168](https://issues.apache.org/jira/browse/SPARK-34168), which has some limitations. It only apply DPP when the small table side executed firstly and then the big table side can reuse the broadcast exchange in small table side. This PR is to address the above limitations and can apply the DPP when the broadcast exchange can be reused. Resolve the limitations when both enabling DPP and AQE No Adding new ut Closes apache#31756 from JkSelf/supportDPP2. Authored-by: jiake <ke.a.jia@intel.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
What changes were proposed in this pull request?
We have supported DPP in AQE when the join is Broadcast hash join before applying the AQE rules in SPARK-34168, which has some limitations. It only apply DPP when the small table side executed firstly and then the big table side can reuse the broadcast exchange in small table side. This PR is to address the above limitations and can apply the DPP when the broadcast exchange can be reused.
Why are the changes needed?
Resolve the limitations when both enabling DPP and AQE
Does this PR introduce any user-facing change?
No
How was this patch tested?
Adding new ut