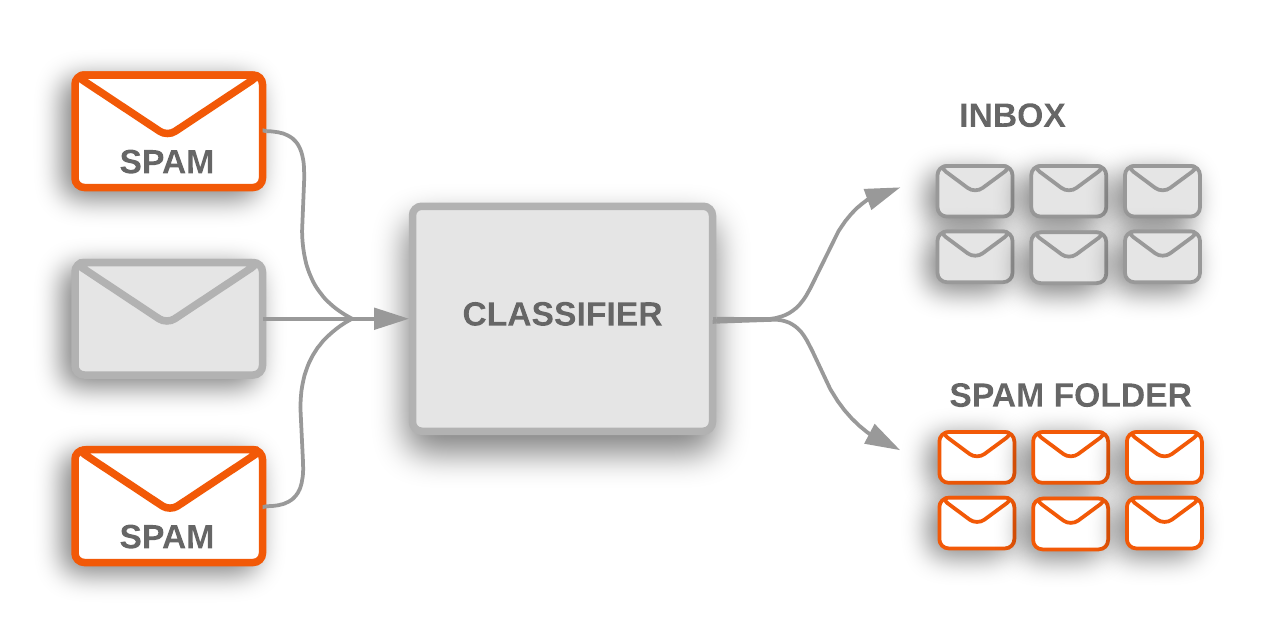
In this project I build a model for classifying the Email & SMS into spam or not spam using machine learning.

demo.mp4
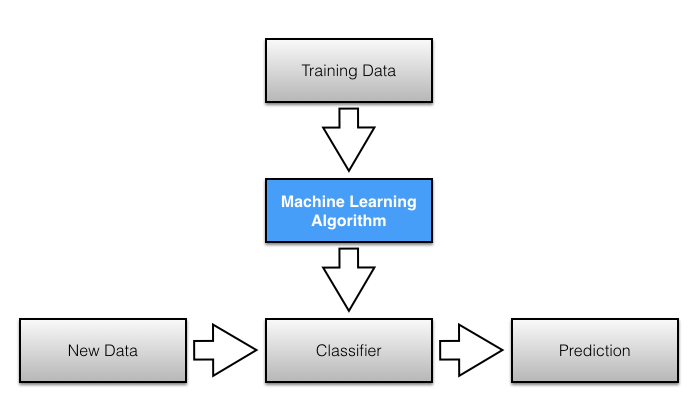
Extract the text and the target class from the dataset. Extract the features of the test using TF-IDF vectorizer for the Input features. Used MultinomialNB standard classifier to classify the data into spam or not spam.
I would highly recommend that before the hack night you have some kind of toolchain and development environment already installed and ready. If you have no idea where to start with this, try a combination like:
Pythonscikit-learn/sklearnPandasNumPymatplotlib- An environment to work in - something like
JupyterorSpyderFor Linux people, your package manager should be able to handle all of this. If it somehow can't, see if you can at least install Python and pip and then use pip to install the above packages.
The SMS/Email Spam Collection is a set of SMS tagged messages that have been collected for SMS/Email Spam research. It contains one set of SMS messages in English of 5,567 messages, tagged according being ham (legitimate) or spam.
You can collect raw dataset from here.
The files contain one message per line. Each line is composed by two columns:
Class- contains the label (ham or spam)Message- contains the raw text.
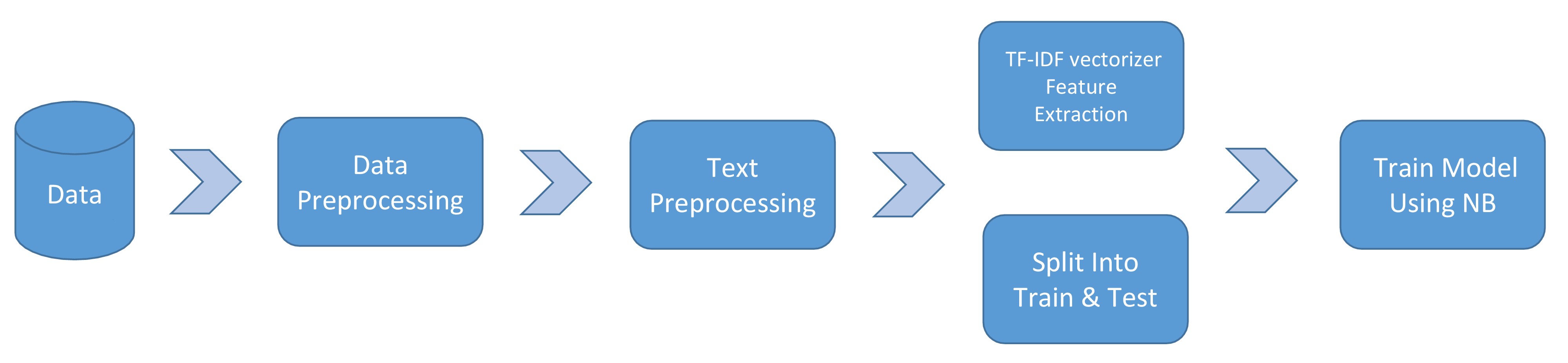
- Using TF-IDF for feature extraction of the text data for the messages.
- Use splits for skewed data(Since the number of ham are far more than the number of spam messages,the data is not balanced.)
- Use different standard classifiers for classification of the SMS/Emails.
- Compare the accuracy of various classifiers using standard classification metrics
import sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features=3000)
x = tfidf.fit_transform(df["transformed_text"]).toarray()
y = df["target"].values
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2)
from sklearn.naive_bayes import MultinomialNB
mnb = MultinomialNB()
mnb.fit(x_train,y_train)
y_pred = mnb.predict(x_test)
print("MultinomialNB TfidfVectorizer with max_features=3000")
print(f"accuracy: {accuracy_score(y_test,y_pred)}")
print(f"precision: {precision_score(y_test,y_pred)}")Multinomial Naive Bayes with TfidfVectorizer having max_features=3000
accuracy: 0.9709864603481625
precision: 1.0