
Join our chat on Matrix or Telegram
VocabSieve (originally Simple Sentence Mining, ssmtool) is a program for sentence mining, in which sentences with target vocabulary words are collected and added into a spaced repetition system (SRS, e.g. Anki) for language learning. It is meant to help intermediate learners gain vocabulary efficiently by allowing card creation without interrupting the flow of content immersion. It can also import notes from Kindles or ereaders running KOReader, so you can effortlessly make cards with minimal interruption to your reading.
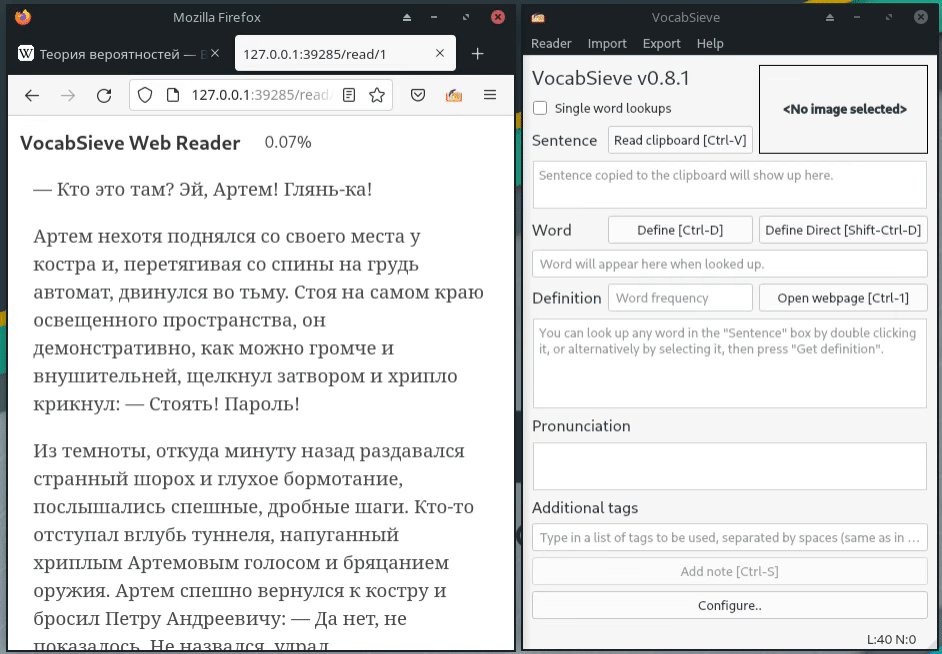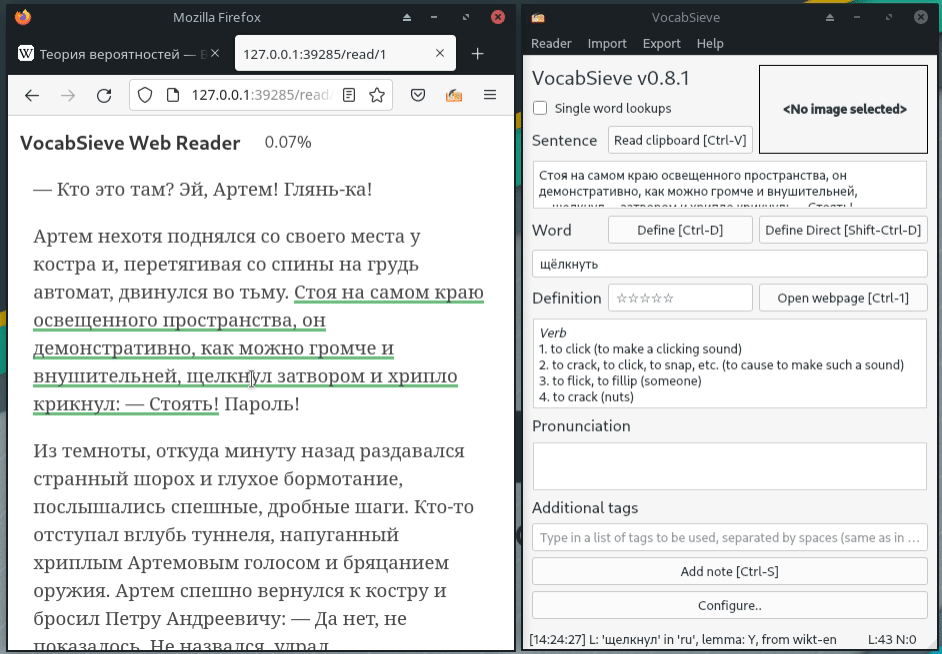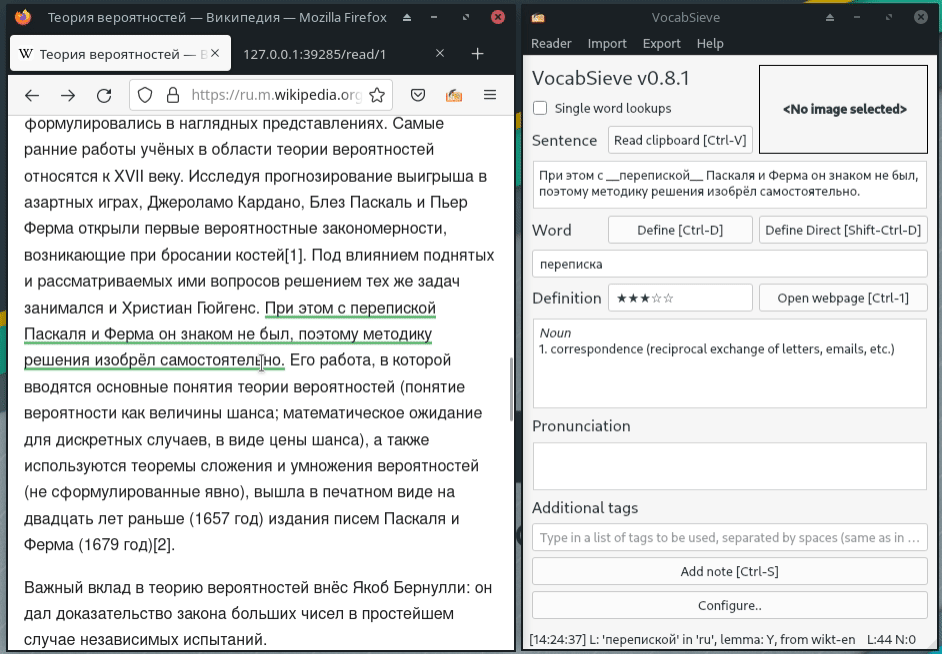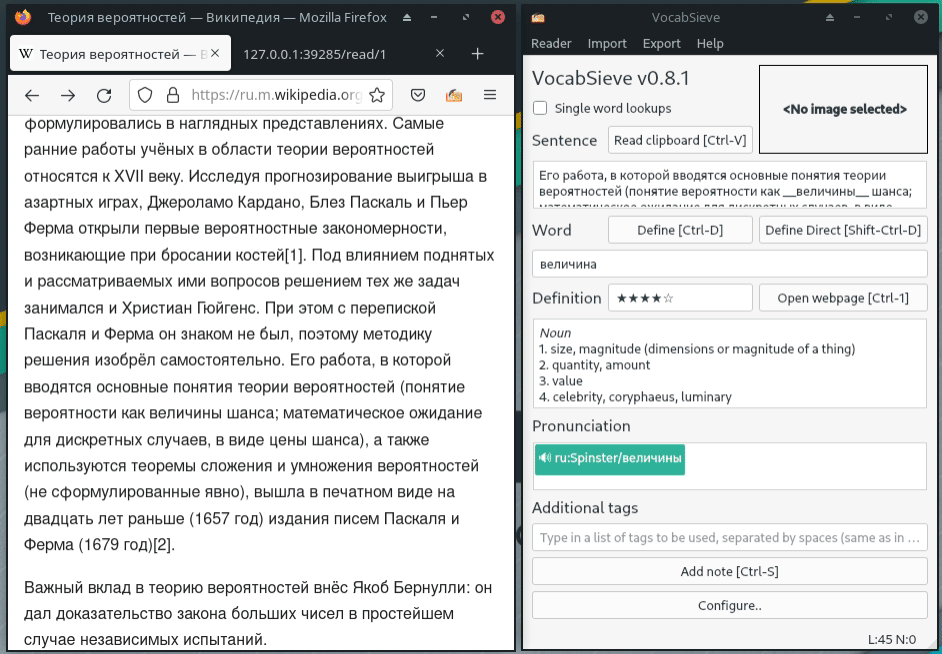
{kind=link}
- Quick word lookups: Getting definition, pronunciation, and frequency within one or two keypresses/clicks.
- Wide language support: Supports all languages listed on Google Translate, though it is currently optimized for European languages. Spanish, English, and Russian are routinely tested, but all other languages with a similar morphology should work well.
- Lemmatization: Automatically remove inflections to enhance dictionary experience (
books->book,ran->run). This works for most European languages. - Local-first: No internet is required if you use downloaded resources. VocabSieve has no central server, so there are no fees to keep it running, so you will never have to pay a subscription.
- Sane defaults: Little configuration is needed other than settings for the Anki deck. It comes with two dictionary sources by default for most languages and one pronunciation source that should cover most needs. It comes with a working note type, saving you the effort of finding an appropriate one and/or styling it if you don't want to.
- Local resource support: Dictionaries in StarDict, Migaku, plain JSON, MDX, Lingvo (.dsl), CSV; frequency lists; and audio libraries. Cognates data can also be imported for more accurate vocabulary tracking.
- Web reader: Read epub, fb2 books, or plain articles with one-click word lookups and Anki export.
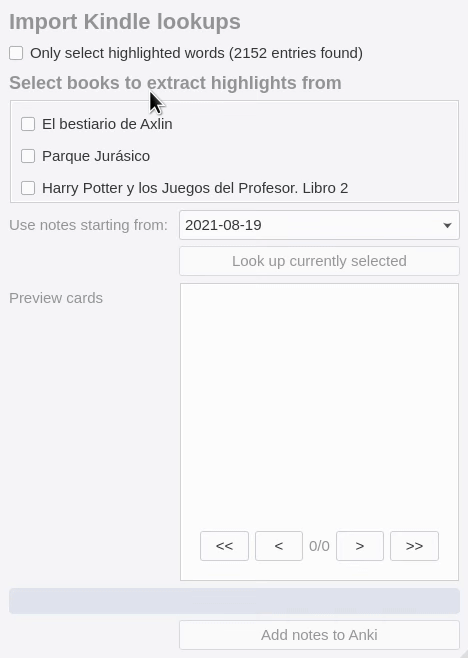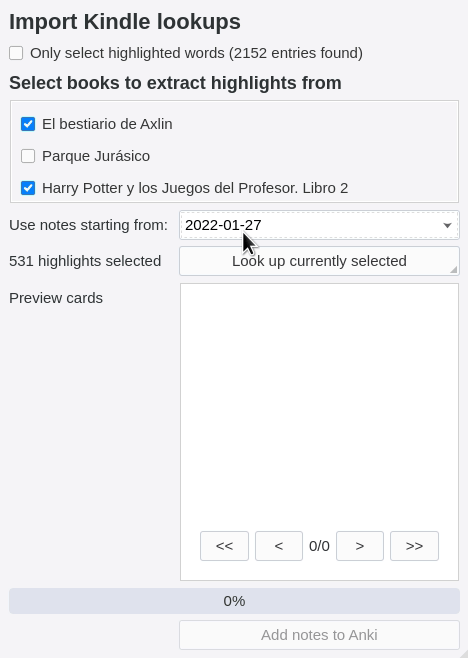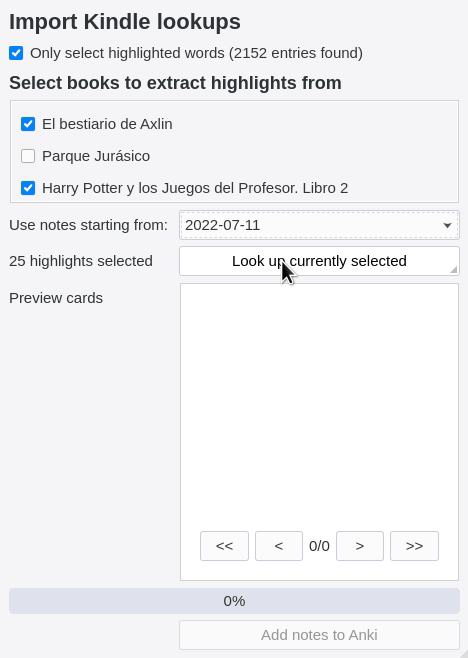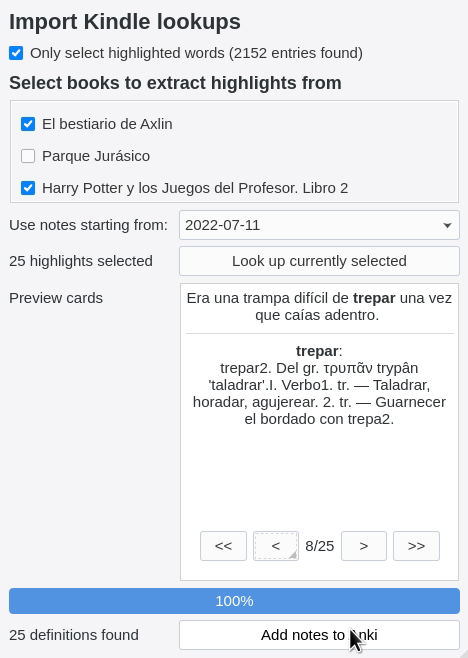
- eReader integration: Batch-import KOReader and Kindle highlights to Anki sentence cards to build vocabulary efficiently without interrupting your reading.
- Vocabulary tracking: Track your learning progress effortlessly when you look up (including from ereader), review your Anki cards, or immerse. The data never leaves your computer, and can easily be exported for your own use.
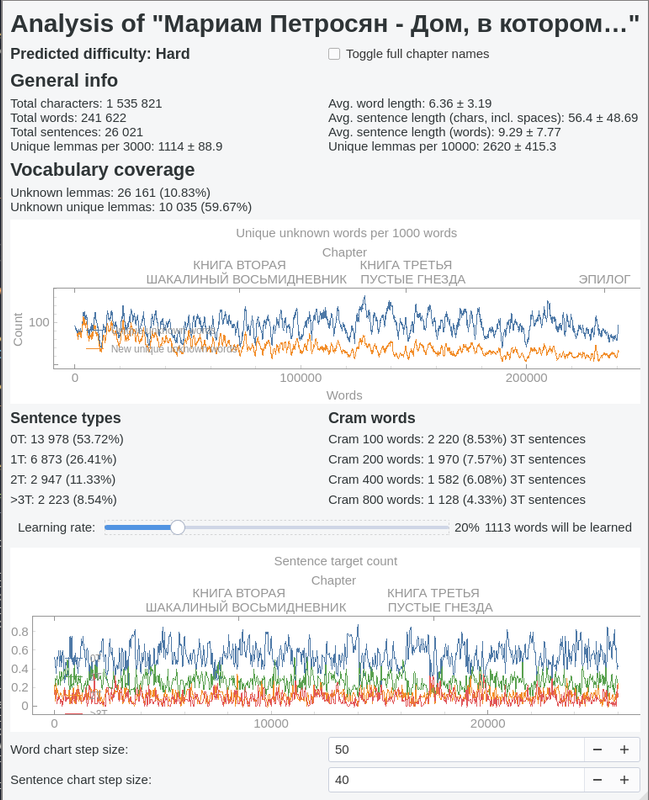
- Book analysis: Not sure what to read? Once VocabSieve gets enough data of what words you know, it can quickly scan books and predict your level of understanding.
Manual (The text originally on the wiki or this document or the blog post has since been moved there, with some updates.)
Windows and Mac users: If you want to install this program, go to Releases and from the latest release, download the appropriate file for your operating system.
For a nightly build, please check the CI artifacts page. These are not considered ready for release and likely contain bugs. It is recommended to use the debug version to get more details when things go wrong.
Click to show distro-specific installation instructions
First, you need to add the ::guru overlay. Skip this section if you have already done so.
# eselect repository enable guru
# emaint -r guru sync
Install the package:
# emerge -av app-misc/vocabsieve
Use your favorite AUR helper (or manually) to install the pacakge vocabsieve.
At this time, there are no packages for other distributions. If you are able to create packages for them, please tell me!
The easiest method is to download an AppImage from for a release from the Releases tab on the right. You may also download an AppImage for a nightly build on the CI artifacts page.
Alternatively, you may also simply use pip3 to install VocabSieve: pip3 install --user -U vocabsieve. Depends on your system, you may need to install gcc and liblzo2 with headers. NOTE: do not use this if you don't know how to deal with Python environments.
Ubuntu: apt install liblzo2-dev zlib1g-dev python3-pip python3-pyqt5 python3-pyqt5.qtsvg, then pip3 install --user -U vocabsieve
This should install an executable and a desktop icon and behave like any other GUI application you may have.
To run from source, simply use pip3 -r requirements.txt and then python3 vocabsieve.py.
For debugging purposes, set the environmental variable VOCABSIEVE_DEBUG to any value. This will create a separate profile (settings and databases for records and dictionaries) so you may perform tests without affecting your normal profile. For each different value of VOCABSIEVE_DEBUG, a separate profile is generated. This can be any number or string.
Pull requests are welcome! If you want to implement a significant feature, be sure to first ask by creating an issue so that no effort is wasted on doing the same work twice.
If you want to leverage VocabSieve to build your own plugins/apps, you can refer to the API Documentation.
Note that VocabSieve is still alpha software. API is not guaranteed to be stable at this point.
You are welcome to report bugs, suggest features/enhancements, or ask for clarifications by opening a GitHub issue.
I don't really need donations. If you appreciate this tool, consider making a donation to the Free Software Foundation or the Electronic Frontier Foundation to protect our digital future and defend our freedom.
The definitions provided by the program by default come from English Wiktionary, without which this program would never have been created. LingvaTranslate is used to obtain Google Translate results. Fоrvо scraping code is inspired by this repository. Lemmatization capabilities come from simplemma and pymorphy3.
App icon is made from icons by Freepik available on Flaticon.