Implementation of Double Dueling Q-Network with prioritized experience replay learning to play zx-spectrum games
Implementation of Double Dueling Q-Network with prioritized experience replay learning to play zx-spectrum games. Using keras with plaidml backend, training was done on Radeon RX Vega M GH / Intel Core i7-8809G CPU @ 3.10GHz / 16.0 Gb RAM.
Based on https://github.com/gsurma/atari
Games are run using z80 emulator (https://github.com/ascvorcov/z80emu), every rendered frame is 20msec of real game time. No sound information provided, only screen capture in 16 indexed colors.
Frame skipping can be configured depending on environment. Every 4 frames are converted to grayscale, resized and cropped to 84x84 and combined into one "state image", where each "channel" represents a time slice (see sample images below).
Model evaluates state image, suggests action, observes resulting reward and state, adjusts neural network weights and repeats this loop until the end of the episode. End-of-episode condition is configured depending on environment.
Convolution neural network architecture:

Loss - loss function, determined from the difference between true and predicted q-value. Huber loss in our case - https://en.wikipedia.org/wiki/Huber_loss Each point is an average for 1000 episodes. Lower is better.
Accuracy - categorical_accuracy in terms of Keras, which is 'how often predictions have maximum in the same spot as true values'. Each point is an average for 1000 episodes. https://github.com/sagr4019/ResearchProject/wiki/General-Terminology#difference-between-accuracy-and-categorical_accuracy Higher is better (falls in range 0..100%)
Q - maximum expected q-value by model over the course of one episode. Each point is an average for 1000 episodes. Higher is better.
Score - max score reached by training model over time. Each score point is an average for 10 episodes. Higher is better.
Step - max simulation step reached by training model over time. Each point is an average for 10 episodes. Higher is better.
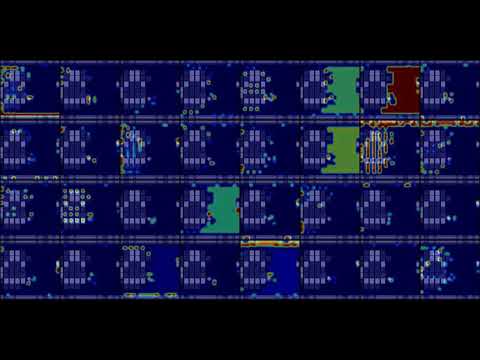
Model was training with condition "single knockdown = defeat", to speed up learning rate, with frame skip set to 2. After 1.5M iterations quality drops due to catastrophic forgetting. Maximum reached is 19700 points / 870 simulation steps.
Model did not discover 'throw off a cliff' strategy on adjacent screen, probably because it is difficult to execute or because it is cheap in terms of points. This strategy is more rewarding for human player since the goal is to advance to next level, not achieve high score. Also model did not discover any of finishing moves. Instead, model found a hack to earn infinite amount of points (not actually infinite since episode is time-limited) - stunning 'boss' with a jump-kick does not kill him, earns 100 points, and gives time for another jump-kick. Rarely random move is selected, and boss gets killed. Model is completely lost on next level, since both background color and enemy type is different.
Human and model results below are for single life loss.
| Subj | Games | Max | Avg | Mean | StdDev |
|---|---|---|---|---|---|
| random | 100 | 3850 | 872 | 550 | 775.1611107 |
| model | 100 | 19700 | 5939.5 | 4750 | 4097.999604 |
| human | 10 | 19600 | 6145 | 4725 | 4746.604049 |
 |
 |
|
 |
 |
 |
 |
 |
Activation heatmap for first convolutional layer of DDQN:
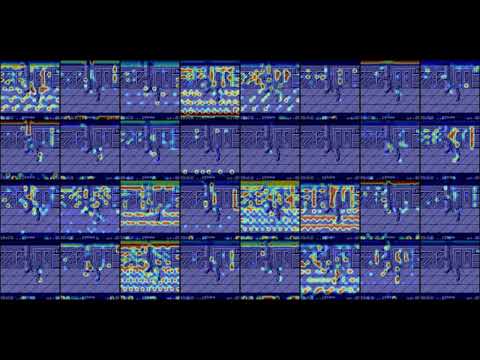
Model was training with condition "loss of one life = end of episode". After 45K episodes frame skipping was changed from 2 to 1, which can be seen on a chart. Maximum score reached is 3500 / 160 simulation steps.
Model doesn't "see" enemy bullets, and overall behavior looks random. Bonus pickup and weapon change also look accidental. Difficult game for machine learning, I could not get acceptable results by changing hyperparameters. Perhaps the problem is with constantly changing background, larger delay beween the shot and reward, and background noise of moving "stars".
Both human and model results below are for full game with 3 lives.
| Subj | Games | Max | Avg | Mean | StdDev |
|---|---|---|---|---|---|
| random | 100 | 1700 | 602.5 | 600 | 321.4059235 |
| model | 100 | 3250 | 2075 | 2125 | 427.9089396 |
| human | 10 | 2050 | 1470 | 1575 | 481.433046 |
 |
 |
|
 |
 |
 |
 |
 |
Activation heatmap for first convolutional layer of DDQN:
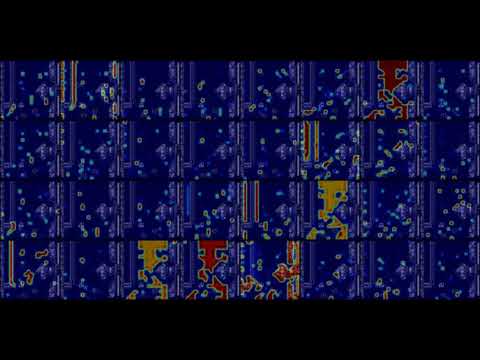
Model was training with condition "enemy scored > FF points = end of episode", to speed up learning rate. Frame skipping set to 2, entire game field does not fit into 84 pixels, only left part is captured (where most of the action takes place). I could not find where 'hit points' are stored in memory, so the only way to train was to focus on enemy score. Initial condition was 'enemy scored > 0 = end of episode", but this proved to be a bad strategy since the model could not learn how to recover after being hit.
Model learned a few nice combo moves (see gif below - fencing followed by upper strike when cornered), doesn't attack and prefer to defend in the corner. Unfortunately (as always) completely lost on a second level, probably due to a different background color.
At the beginning of learning process model discovered "beheading" fatality move, but abandoned it since it is difficult to execute, although it pays a significant reward of 500 points. With normal sparring, single level can earn 1300-1400 points.
| Subj | Games | Max | Avg | Mean | StdDev |
|---|---|---|---|---|---|
| random | 100 | 1700 | 340 | 200 | 351.1884584 |
| model | 100 | 2700 | 1546.5 | 1550 | 311.4202559 |
| human | 10 | 5150 | 1590 | 1375 | 1402.735423 |
 |
 |
|
 |
 |
 |
 |
 |
Activation heatmap for first convolutional layer of DDQN:
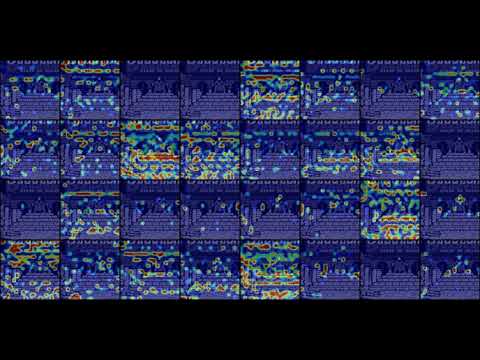
Model was training with condition "loss of one life = end of episode", with frame skipping set to 2. For quite a long time model could not learn the initial moves and died at the beginning of episode, which can be seen on the chart - average score is close to 100. Ultimately, final score is limited by amount of "fuel", since model did not learn "refueling" move - it is not giving any points, and delayed reward is too far in the future. Maximum reached is 1840 points / 156 steps.
Human and model results below are for single life loss.
| Subj | Games | Max | Avg | Mean | StdDev |
|---|---|---|---|---|---|
| random | 100 | 930 | 217.5 | 170 | 158.077944 |
| model | 100 | 1840 | 1501 | 1660 | 436.6180866 |
| human | 10 | 14150 | 6351 | 5285 | 4598.628902 |
 |
 |
|
 |
 |
 |
 |
 |
Activation heatmap for first convolutional layer of DDQN:

As usual, training with condition "loss of one life = end of episode", 2 frame skipping. Otherwise model is not punished for life loss and training is slowed down / quality drops. After 35K games model learns to track and deflect ball, but then the goal of game is replaced. Model discovers that hitting 'monsters' yields 100 points, while hitting blocks yields only 10-20 points, so the goal to hit high score is to hit as many monsters as possible, instead of going to next level. At the peak model can score up to 8K points on first level, while there are only 44 blocks, yielding no more than 1000 points total.
Both human and model results below are for full game with 3 lives.
| Subj | Games | Max | Avg | Mean | StdDev |
|---|---|---|---|---|---|
| random | 100 | 1790 | 118.1 | 40 | 300.4699854 |
| model | 100 | 9560 | 1941.9 | 1545 | 1809.13099 |
| human | 10 | 14880 | 5785 | 4060 | 4299.227967 |
 |
 |
|
 |
 |
 |
 |
 |
Activation heatmap for first convolutional layer of DDQN: