Support Vector Machines (SVM) is a supervised machine learning algorithm used to analyze data for classification. The algorithm calculates one or more hyperplanes which separates the data points of one class from the other one. The hyperplane which has the largest margin between the two classes is selected. A hyperplane can be represented as the set of points x satisfying 1 where w is the normal vector to the hyperplane and b is the offset of the hyperplane from the origin. The input x belongs to:-
- class -1 if
- class +1 if
In cases of non-linear problem , SVM is extended with the hinge loss function and the problem becomes an optimization problem to reduce this loss.
Federated SVM makes use of hinge loss function and updates the model parameter w as . The below picture gives an overview of federated SVM :-
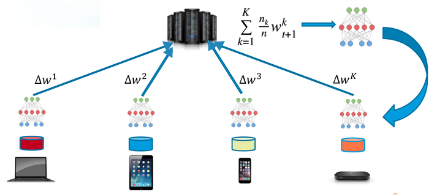
The dataset used here for validating the federated SVM is MNIST handwritten digits dataset. Two datasets are made from MNIST dataset one set contains the digits 0 & 6 and the other set containing 3 & 8. Each of the digits in these sets are divided into three clusters using kmeans clustering algorithm and concatenated with their respective pair. This is done to simulate the different data distributions that the client may have. Now we have two datasets having three sets each, following picture illustrates the same:-

