rules/python: Option to generate .pyc files for py_library. #1761
Comments
|
cc @rickeylev |
|
This is probably fairly easy to do by adding a The tricky part I'm not sure of is what that attribute points to. It can't point to a py_binary itself, since that would be a circular dependency. But we have to use Python to run py_compile somehow. Maybe allow it to be an executable or a single py file? If it's an executable, run it. If it's a py file, then run "$interpreter $file". This allows creating a pre-built executable if desired, while also allowing it to Just Work. (this again touches on the problem of how there's several cases where py-binaries want to be used as part of the toolchain)
Probably, yes. CHECKED_HASH is somewhat appealing, too, though, because it allows you to modify the source file and see the new behavior without having to rebuild, though. I'm +1 on defaulting to one and having an option for the other. Maybe base the default on I also like the idea of a library-level control here somehow, too. A scenario we've enountered with large packages (e.g. tensorflow), is the sheer number of modules has its own overhead; pyc helps, but being as how modifying them is the exception, not the rule, making them check their hash is wasted work. We'll have to figure out how a target-level and global-flag-level option should interact, though (which has precedence?).
Yeah, the details of the pyc infix aren't well understood to me. I think PEP 488 is another half of the puzzle. I swear I thought there was a part of the specification that included the "compile mode" of Python itself, too (e.g. debug for non-debug), but I don't see that mentioned. We also have to make sure that the generated name is recognized by the runtime that will be used. I think this is controlled by BYTECODE_SUFFIXES? One option is to simply stick this onto the toolchain, too. Another would be to pass the necessary suffix to the stub template so it can configure the runtime at startup. Additionally, the output path depends on if the original .py files is included or not. The Major.Minor Python version is in the |
Yeah, this is kind of a similar problem as the one faced for the coverage tool in bazelbuild/bazel#15590. However, there's an important difference:
Absolutely! However, that's something you can handle with I think the options we'd want exposed look something like
As well as the mostly orthogonal choices for "optimization" level. (which I will continue to put in quotes. It's really too bad that there isn't an optimization level which strips out docstrings, which you don't need in a server context, but leaves in assertions, which might be a bit dangerous to strip out)
This is why I suggested pre-compilation should be an attribute on the |
I think invoking the interpreter directly like that is a workable intermediate solution. So I'm +1 on doing that for now. I'm fairly certain we need a custom program to ensure deterministic behavior and pass the necessary info, though. The cli of -m py_compile isn't sufficient. However, I need to make a few architectural points about why such solutions make it hard or impossible to take full advantage of Bazel's processing model and features. As some concrete examples: When using embedded Python, there's no need for a standalone interpreter, so building one simply for precompilation is unnecessary work. (This is particularly salient to me because that's my primary way of building Python programs). Precompilation is a near perfect fit for using persistent workers, which would eliminate runtime startup overhead. This requires special support by the executable invoked. Precompilation must run in the exec configuration. This means the runtime itself may be built differently than the runtime actually used, may be run remotely, and/or run on an entirely different platform. So more steps have to be taken to ensure such details don't leak into the output. For example, the launcher script does several things to prevent system settings from affecting the runtime which have to be re-implemented. Similarly, the exec configuration usually emphasizes time-to-build over runtime-efficiency. This makes sense for typical user build tools, but less so for something like precompilation; precompilation is well defined and it's rate of invocation scales with the size of the overall build, ie the larger your transitive closure, the more it runs, so you're probably going to benefit from the precompiler (and runtime) being built with optimizations enabled. Such optimizations can extend beyond simply e.g. pyc -O levels, and into C-level optimizations that affect the runtime itself; these optimizations are hard to apply during a build, but are easy to apply to to an prebuilt executable which is later run. This isn't to say simply doing "$runtime -m py_compile" is bad or wrong, just that it leaves a lot sitting at the Bazel Buffet Table.
Srsly, right? This has bugged me for years! It's the sort of thing a custom precompiler executable could do, though. This also makes me think, if we exposed an optimization level, it'd probably be better done as a list of values instead of a simple number.
I agree. A case we have internally is that protocol buffers (which are handled by a special rule) are compiled by default. This is pretty akin to a library-level setting.
I agree. |
|
Worth noting mostly for the sake of code archeology that there's this comment in the code currently: https://github.com/bazelbuild/bazel/blob/6d72ca979f8cf582f53452d5f905346e7effb113/src/main/java/com/google/devtools/build/lib/rules/python/PythonSemantics.java#L69-L71 |
|
Thanks for filing & tracking! Do you have a suggestion of a workaround for the time-being? BTW, for others looking into this. A simple |
|
I would very much <3 to see this feature. we have a lot of heavy imports :(Some of our heavy hitter imports bog down both test & runtime (mainly test) One of the pain points right now is that we use pytorch in our bazel monorepo. However, because we import it in so many of our libraries, it incurs a large import time overhead (3.8 seconds). With pycache, it drops down to ~2.5 seconds. Is the general idea to generate pyc files once when all external third party repos are fetched at analysis time and then to ingest these files as input in Would love some pointers on where to start (even if it's just a hacky prototype 😅 ) |
|
I'm going to transfer this issue to the rules_python repo because, as of rules_python 0.31.0, we've enabled the rules_python-based implementation of the rules by default for Bazel 7+. This basically means this feature won't land in the Bazel builtin rules, but would instead be in the rules_python implementation. |
Can do! I've had parts of this mentally sketched out, but haven't thought it through entirely. This is already partially wired into the rules_python implementation, too. There's a stub function, All this function really has to do is loop over the sources, run a tool to generate the pyc files, and return them. The important thing is that it generates deterministic output (i.e. no timestamp based pyc files). It'll probably need some flags to control behavior a bit, as discussed, but lets focus on a prototype first. Anyways, the core code of this function is pretty simple: That's the first part, which is easy. The second part is defining the tool that is run to generate the pyc. For the purposes of experimenting, you can add an implicit attribute on py_library pointing to some executable to run. The tricky part here is the executable it points to can't be a regular py_binary -- that would result in a circular dependency. For experimenting, define it how you like to work out details (e.g. a sh_binary that just calls the system python would suffice for testing purposes). Within Google, we prebuild a binary and use an implicit attribute. A prebuilt binary is actually a good thing in this case, but not required. It allows neat things like building an binary with optimizations, having a generic binary that can generate byte code for any python version, building a cc_binary that embeds python, or heck, you could implement a byte code compiler in Rust or whatever if you really wanted to. I'm getting ahead of myself. Anyways. It's probably best to just start with invoking something like Using an implicit attribute, however -- that won't work well in the Bazel world where the environment isn't as tightly controlled and where there are many more platform configurations to worry about. In the open Bazel world, this precompiler tool needs to come from a toolchain. This is because we need toolchain resolution to find a tool that matches the target config (the target python version we need to generate byte code for) that can run on one of our available execution platforms. A basic implementation that re-used the same runtime would look something like this, I think: (there's variations of the above that would also work, but thats the gist). |
|
Was prototyping a bit. I really appreciate all the pointers here! I used the system python interpreter to prototype for now and noticed some weird behavior and perhaps I'm missing something fundamental here, but when bazel "compiles" these python files into pyc, sometimes, we run into the case where the sandbox only contains the directory Debugging this prototype, we see src.path for this situation is Is there something fundamental that I'm missing? Prototype: |
|
That action invocation doesn't look correct.
The second should result in an error from bazel about an output file not being created. |
|
Worth emphasizing the second point there,
You cannot assume that the tool can derive the output path from the input path, because for example that prefix
|
|
Another point worth noting here is that if you're using a python script to generate the |
|
Prototype done! Thanks for all the pointers! not pretty, but it does generate all the pyc files! (in our case, we use python310) |
|
Can clean it up a bit by doing args = ctx.actions.args()
args.add("-c")
args.add("""
from sys import argv
from py_compile import compile
compile(argv[1], cfile=argv[2])
""")
args.add(src)
args.add(pyc)
runtime=ctx.toolchains["@bazel_tools//tools/python:toolchain_type"].py3_runtime
ctx.actions.run(
executable=runtime.interpreter,
arguments=[args],
env={"SOURCE_DATE_EPOCH": "123"},
tools=[runtime.files]
...
)Modulo issues with cross-compiling, that at least will ensure use of the right I'd also note that setting |
|
Yay, a working prototype!
What is this line for? I'm guessing its just debug code because you're trying to isolate it to just the pip-generated files being processed? Adam's comments are in the right direction for cleaning it up. For an initial PR, the important parts are:
Before making it generally available we need to:
|
|
To keep things simple my inclination would be to leave out the "magic tag" altogether, since it's optional and at least in the context of a hermetic build it's very important to have it (worst case you run a different interpreter at runtime and it just rejects and ignores the There's also the part of this where it needs to get added in to the
There's also the question of whether we want to support "optimized" ( |
I think its OK to leave it out for the initial version, but it's necessary in order to support multiple versions of Python in the same build. Otherwise, it'll be a build error because different actions will attempt to create the same file with different content.
Good catch. This would put pyc-only builds and multi-version builds at odds. From what I'm reading, the The options I see here are:
In any case, I think we can just target py+pyc initially.
This is an interesting idea, but I'm not sure how it can be well accommodated. The two ways it could be done is using an aspect or transition. An aspect is the more natural way for e.g. a higher level rule, like a packaging one, to add extra information to its dependencies, but the issue with an aspect is it would conflict with the action performed by py_library. It could work OK if the py_library had any pyc-actions suppressed. It might work better for such a rule to do a split transition. Looking at how some other rules handle this might be informative (the case that comes to mind is c++; iirc, there's a combination of build flags, compiler flags, and providers that determine and provide debug information)
Yes, it belongs in PyInfo. iirc,
Yeah, I agree. Skip for the initial implementation. Note that This would be easy to add, though: just add a second arg to set the compilation optimization level and pass it onto the action. |
😅 Wondering if there's docs for when plain foo.pyc should also be read (or perhaps I'm misinterpreting) ? Doing some testing, I'm not quite sure placing the same toy examplein a directory we have the following ls -a
. .. main.py ryang.py ryang.pyc
If we run the following file, we see from the trace that we don't actually read from the "magic tag"
yeah 😓 |
pep-3147 has a handy flow-chart:
What I had envisioned looks more or less like this:
|
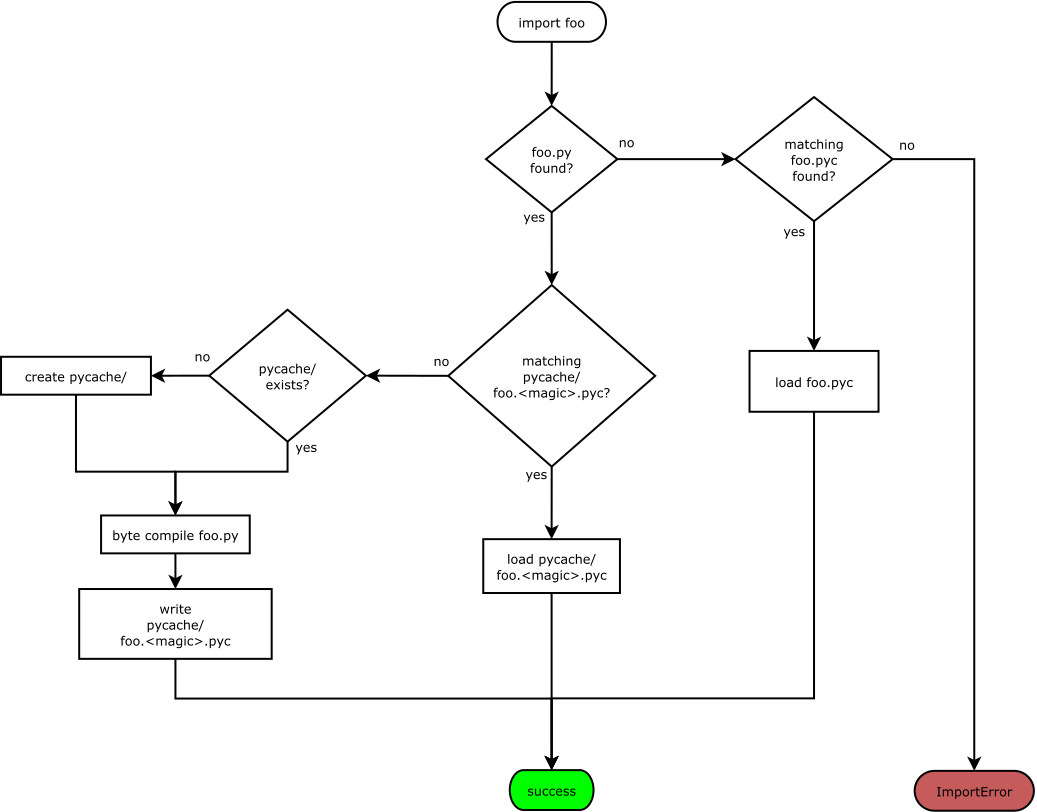
|
ah I see, python will only import the pyc in the same directory as the py file if and only if the original py file doesn't exist. For the consumer speedup at import time, we would only get speedups (meaning no need to generate a pyc file again) for the following
Wondering what downstream users would use options 3/4 for? |
|
Regardless, if you are using the |
hm... maybe my testing methodology is wrong or perhaps I'm missing something? Using the site-packages for debugging purposes, with pyc only, I see a speedup for bazel test (we're using linux-sandbox) spawn strategy i.e pyc onlydef maybe_precompile(ctx, srcs): pyc + py doesn't see a speedup. Even if I set the interpreter to use pyc + pydef maybe_precompile(ctx, srcs): |
|
😅 I was under the impression that py + pyc in the same directory would not result in speedups https://peps.python.org/pep-3147/ |

|
No, you're right, I missed that bit. So if |
|
I think we have the following paths:
Going back to why would pyc be useful and tradeoffs of generating pyc, I think the pros / cons of each decision would be
Coming at this from a python rules consumer perspective, It would seem the first option of pyc + py just moves the pyc creation stage earlier rather than at runtime (import time) Default behavior (unless one uses a cli arg otherwise, is to generate pyc files in pycache upon import) Wondering what the use case for pyc only is (just curious 😅)? |
|
There's basically three use cases for
|
|
Assuming we want to solve for the use case of
Would consumers have something like? As well as some sort of flag that can set this attribute for all py_libraries? i.e ?If we were to do it this way, I think we'd need to make changes in a couple of areas? (haven't worked too much with starlark rules, so I may be doing something wrong here) Would we need to |
|
I don't think we'd want the attribute to be boolean; as discussed above I think there's probably 4 modes of interest:
The difference between I'd probably call it It would probably make sense for the initial default to be 1, for backwards compatibility, though really we'd also probably want the default to be So, the place to start would probably be with the toolchain configuration. And for an MVP at least, we can just leave it there and not yet expose options on a per-library basis. We don't actually have to change However, if we allow ourselves to make changes to
A distribution could use either Footnotes
|
|
Yes, have a string-valued setting. The default should be "default", or "auto", or some other sentinel. This allows easier detecting of "did someone set this?", plus some freedom in implementation.
Yeah, this is a tricky question. For "released" code, unchecked hash is the obvious choice. When doing development, you want checked hash (or disable pyc entirely) for sources you're going to modify, and unchecked for ones you haven't. This also makes me think that, for something like pip.parse-generated libraries, it would make sense for those to set unchecked hash (i.e. a library-level setting), because you're really unlikely to modify those (if you are, you might as well just modify the generated build file, too). Another case that comes to is generated code (e.g. py_proto_library). Such code has to go through a build step to see changes anyways, so adding an extra call to precompile isn't that much overhead. (In the case of py_proto_library, because protos tends to generate a lot of files, skipping the py->pyc is a net win). I can imagine some extra set of flags to control behavior here from the "outside" (I'm thinking a label flag that points to a richer config), but lets keep it simple for now -- I think a library level setting for this makes sense (with the 5 modes listed: auto, py-only, pyc-only, pyc-checked-hash, pyc-unchecked-hash). |
|
A trickier case to handle where you'd want to use |
|
Was doing some prototyping to pipeline this I notice that in areas where Assuming we'd want the end user to be able to do something like Would we need to propagate from PY_SRCS_ATTRS? Or is there a way to do this solely via PyInfo?
Currently, I just use a
Does bzlmod support pytest with multiple pip/python versions? I see there's this comment here |
|
Coincidentally, we have some internal work in this area planned, so I thought I'd post some of our analysis that seemed relevant. Note that this isn't documenting a decision. It's merely trying to inform from looking at the use case we're trying to solve (in brief, precompiling enabled by default) and the constraints we have. A
It seems like there are 3 flags to decide behavior?
re: flag vs attribute precedence: this is a really tough question. We could come up with reasonable scenarios where both are sensible behaviors. Overall, the attribute taking precedence seems like the better default behavior. The main case for having the flag take precedence is: what if a target you don't own sets precompile=only (having just pyc makes sense if it just generates code), but you have to deploy to an environment where that pyc won't be valid (i.e. your build is for Python 3.10, but you deploy to something with python 3.9). This is somewhat of an edge case for us, but seems like it would be much more common in OSS. This case is also where the The above case also implies that there's a distinction between binaries and libraries in this regard (i.e. a binary level-setting applies transitively). As a general rule, if there's a global flag to set the default or force the state, then it probably should also be a binary-level attribute. It's not always possible or desirable to set a global flag, especially if there's just a handful of targets that need it. That said, a binary level setting also comes with problems. As an example, given:
Then the problem is the library can't directly see what the binary needs, and only outputs |
I'm not sure I understand the question. What goes into PyInfo is derived from the target attributes (srcs and deps, usually). The core logic, when unrolled, should basically be: Does that answer your question?
I think you're hinting at the issue of you need an exec-config interpreter, but the python toolchain only has a target-config interpreter? I think your 3 basic options are:
I think a combination of (2) and (3) is probably the best? (2) invokes toolchain resolution, which permits the target config to influence selection (i.e. allows the target config pythonversion=3.10 to select a toolchain that can generate 3.10 bytecode). (3) allows abstracting how the precompiler binary is implemented (i.e. it could be a pre-compiled binary or simply lookup the "regular" interpreter).
Yes, but recall how toolchain resolution and matching works: it's taking the key:value constraints and looking over lists to find something that matches. I say this because it sounds like you might be thinking/desiring this:
Yes, it supports multiple versions. That comment is out of date. |
This can be avoided if we're willing to complicate the |
|
I've been working on adding this functionality. You can see the WIP here: main...rickeylev:rules_python:precompile.toolchain Everything appears to work, so I've started cleaning it up. The basic gist of what I have implemented is:
The two basic ways to use precompilation are:
If you like optimizing Python code, then optimizing the precompiler tool might be fun. Unfortunately, precompiling adds a decent amount of overhead. As an example, the bzlmod example has about 2,000 py files. This takes about 60+ seconds to precompile as a regular action (1 py file per action) 🙁. So I implemented a second precompiler that is a multiplexed, sandbox-aware, persistent worker. This reduced build time from 60s to about 4 seconds (yes, single-digit). I think we can do better, but I haven't explored where the bottleneck is. If we can change it to be a prebuilt binary, then we'd have more options for optimizing it, too. |
|
A few observations: Persistent workerThis approach worries me a bit because there's a lot of rough edges around using a persistent worker with remote execution (which my team uses exclusively). Python interpreter startup time is a lot; it's not surprising that you get significant benefits from a persistent worker, especially since AFAKT the implementation for
pyc-only modeI'm not sure this works in if You're also not supporting the use case of permitting specific libraries to be pyc-only without setting it overall. This could be done; similarly to precompile=disabled you'd need to add the pyc to the normal sources as well as as pycs in order to support cases that were not collecting pyc. |
|
re: persistent worker: Yes, all good points. The precompiler works as a non-worker, regular worker, or multiplexed worker, and there's a flag to set the execution_requirements for the precompile action. re: py_compile fully imports: It doesn't import (execute) the py code. It just uses the importlib libraries to read the file and compile it to pyc. I found that surprising, but maybe not so much if this is closely coupled to the import system's processing of things (e.g. re: linking with libpython: Yes, that'd be awesome. I'd love to get a cc_binary that statically links with libpython working. For something like the precompiler, which is a single file that only uses the stdlib, such a thing seems doable. re: library-level pyc-only: Ah yeah, I forgot about that. That should be doable with target-level attribute to control that. |
|
I forgot that you can't actually choose to be pyc-only at the I'll maybe take a time-boxed crack at trying to get such a |
|
re: remote builds, performance, persistent workers: A thought: Right now, each source file is processed with a separate action. Some performance could be regained with non-worker execution by sending all of a target's sources to a single invocation. This would at least change the overhead to once-per-target instead of once-per-file. For targets with many sources (e.g. something from pypi), this would probably help a decent amount. |
One of our repos using remote execution: |
|
Didn't really have time to figure out a truly portable way to do the source hashing, but I did try a different, much simpler python implementation: from sys import argv
import py_compile
src_path, src_name, dest, optimize, checked = argv[1:]
py_compile.compile(
src_path,
cfile=dest,
dfile=src_name,
optimize=int(optimize),
invalidation_mode=(
py_compile.PycInvalidationMode.CHECKED_HASH
if bool(int(checked))
else py_compile.PycInvalidationMode.UNCHECKED_HASH
),
)This avoids $ time (for f in $(git ls-files '*.py'); do python3 tools/precompiler/precompiler.py --src $f --src_name $f --pyc /tmp/temp2.pyc --invalidation_mode UNCHECKED_HASH --optimize=0; done)
real 0m10.133s
user 0m8.744s
sys 0m1.381s
$ time (for f in $(git ls-files '*.py'); do python3 tools/precompiler/precompiler2.py $f $f /tmp/temp.pyc 0 0; done)
real 0m3.492s
user 0m2.867s
sys 0m0.600sThis does suggest that the persistent worker implementation should at the very least be kept separate from the single-file implementation. Or at least should process imports lazily as-needed. |
|
Oh, nice analysis. I see similar. All those unused imports add up. re: lazy imports: Yeah, I'll do this, at the least. This is an easy change to make. re: splitting worker impl into another file: That's a good idea, too; it would avoid having to parse all the worker-related code. It'll have to wait for another PR, though. The argparse import itself isn't too bad, so I'm going to keep the |
This implements precompiling: performing Python source to byte code compilation at build time. This allows improved program startup time by allowing the byte code compilation step to be skipped at runtime. Precompiling is disabled by default, for now. A subsequent release will enable it by default. This allows the necessary flags and attributes to become available so users can opt-out prior to it being enabled by default. Similarly, `//python:features.bzl` is introduced to allow feature detection. This implementation is made to serve a variety of use cases, so there are several attributes and flags to control behavior. The main use cases being served are: * Large mono-repos that need to incrementally enable/disable precompiling. * Remote execution builds, where persistent workers aren't easily available. * Environments where toolchains are custom defined instead of using the ones created by rules_python. To that end, there are several attributes and flags to control behavior, and the toolchains allow customizing the tools used. Fixes #1761
Description of the feature request:
Add options on one or more of the
py_libraryrule itself, the python toolchain configuration, or the bazel command line, to generate python bytecode files as part of the build.In addition to the basic on/off option, it might be useful to include options to
.pyfile out of the build outputs - the.pyc-only use case.What underlying problem are you trying to solve with this feature?
When python loads a module, it parses the source code to an AST, which it then attempts to cache in bytecode format. Building those as part of the build process solves a few issues:
To quote the documentation for the py_compile module:
Particularly in the case where bazel is being used to build a tarball of code that includes (but may not be limited to) python, and might then be deployed somewhere that's read-only to most users, it would be useful to be able to include these precompiled bytecode files.
The attempt to compile the bytecode files would fail on syntactically-invalid python code, which is probably a good thing for catching failures earlier on in the build process.
Having
.pycfiles available improves application startup time. Especially for large python codebases, if some module is transitively imported from thousands of unit tests, currently each of those tests would end up re-parsing the python source file, which is a waste of time. Having the.pycfiles is also helpful for improving startup times for "serverless" platforms.The
.pycfiles can be substantially smaller than the source files. For situations where application distribution size is important, e.g. "serverless" platforms, this can matter.Some people place value on the marginal degree of obfuscation and tamper resistance offered by
.pyc-only distributions. While reverse-engineering the source from a.pycfile isn't hard, it's also not nothing.Which operating system are you running Bazel on?
Linux
What is the output of
bazel info release?release 5.3.0
If
bazel info releasereturnsdevelopment versionor(@non-git), tell us how you built Bazel.No response
What's the output of
git remote get-url origin; git rev-parse master; git rev-parse HEAD?No response
Have you found anything relevant by searching the web?
No response
Any other information, logs, or outputs that you want to share?
References/notes:
https://docs.python.org/3/library/py_compile.html
The default compilation mode is
TIMESTAMP; this is probably a bad idea. In a bazel build we'd probably want to useUNCHECKED_HASH. Would also need to ensure that the embedded path name was appropriately relative.From PEP-3147:
This means that in the case where the
.pyfile is still being included, the output path would need to depend on the python interpreter version. This probably would require an attribute to be added topy_runtimefor that purpose.The text was updated successfully, but these errors were encountered: