QueryOptimization
See also:
- IOOptimization (Understanding and optimizing IO performance).
- PerformanceOptimization (Understanding and optimizing performance).
Blazegraph on a Journal (single machine) is great at fast evaluation of selective queries. A selective query is one where an index can be used to rapidly recover exact data on which the query needs to operate. In contrast, an unselective query has to read a lot of data from under constrained access paths. On the Journal that translates into random IOs that will eventually saturate your disk. If that is your workload, consider more spindles, SSD, or a cluster. A Blazegraph federation (cluster) organizes the data differently on the disk (most of the data is physically organized on the disk in key order) so we can do sustained sequential IOs for unselective queries. This means that unselective queries on a cluster can run with much less IO wait than on a Journal. However, a Journal will have less latency for selective queries since it has less coordination overhead. This is a classic throughput versus latency tradeoff.
Blazegraph is designed to pipeline a query evaluation very efficiently. There is no practical limit on the #of results which Blazegraph can return when it is pipelining a query, but unselective queries may saturate the disk with IO Wait. If you are trying to materialize too many results at once in the JVM, then you can run into problems. For example, this can happen if your query has a large result set and uses ORDER BY or DISTINCT. Both ORDER BY and DISTINCT force total materialization of the query result set even if you use OFFSET/LIMIT. Materialization of large result sets is expensive (today) because it puts a lot of heap pressure on the JVM — an issue addressed by our forthcoming analytic query milestone release — see below for details.
During a pipelined query evaluation, intermediate results flow from one query operator to the next in chunks. Different operators in the query plan run simultaneously as they consume their inputs. If one operator is producing solutions faster, then another operator can consume them, then multiple invocations of the slower operator can run simultaneously. The total CPU and RAM burden during pipelined evaluation is managed by limiting the size of the chunks flowing through the query plan, the #of concurrent instances of an operator which may be executing simultaneously for the same query, and the capacity of the input queue for each operator in the query plan. Low level annotations are available to control all of these parameters, but that is generally below the level at which users will do performance tuning. The other critical parameter is the #of queries running concurrently on the QueryEngine (discussed below).
You can do quite a bit to make queries fast, and a highly tuned application will really sing, but first you need to understand why your query is slow.
There are several ways in which things can go wrong for a query performance:
- Bad query (the query does not do what you intended).
- Bad join ordering (Blazegraph reorders joins, but sometimes it gets this wrong).
- Bad query plan (sometimes an alternative plan can be more efficient, e.g., subqueries with hash joins).
- Too much GC pressure (see below).
- Too much IO Wait.
- Too many concurrent queries.
IO Wait, CPU, and GC time are your guideposts in understanding what is going on inside your server. However, before you get started, you should review the configuration of your server. Make sure that you are using a server mode JVM (-server), that you have given your JVM enough memory, but not ALL your memory since the OS needs to use memory to buffer the disk as well. A good rule of thumb is to give the JVM 1/2 of the memory on the server and let the OS use the rest to buffer the disk. And never, ever let the JVM swap. Java does not handle swapping gracefully since it needs to scan memory when it does a GC pass, and performance will tank if GC is hitting the disk. You also need to make sure you are using read-only connection when you run your queries since you will have much higher potential concurrency that way (the B+Tree is single threaded for mutation, but fully concurrent for readers). Then there are a slew of other performance tuning parameters to consider, from the backing Journal mode (RWStore scales better than the WORM), to the branching factors, the B+Tree “write retention queue” capacity, etc. See PerformanceOptimization for some tips.
The first thing you should do look at the DISK activity and find out what is happening there. If the disk is saturated, then you are IO bound and you need to think about whether your query is doing what you want it to do, whether you want something you can have (realistic expectations), and whether the join ordering is bad (this can lead to excess IO). vmstat is a great tool for this under un*x. It reports blocks in, blocks out, CPU utilization, and the most important IO Wait. Depending on your requirements, you may be able to “fix” an IO Wait problem by adding spindles or using SSD, but first make sure that the query plan is good.
Next, take a look at the CPU. If you are CPU bound with little disk activity and low heap pressure (see below), then you might be looking at a bad join ordering problem with a tight loop in memory. Review the join plan carefully. It is also possible to hit concurrency bottlenecks. If you are running on a server with a LOT of cores (16, 24, or more) then you should look at the context switching (vmstat again). You can get into CAS spins and lock hot spots on a server with a lot of cores, which do not show up on a 8 core machine. If you believe that this is what is going on, you can put a profiler on the JVM and see where it is spending its time. You can get a lot of red herrings this way since the instrumentation of the JVM by the profiler can cause some methods that do basically nothing but are called frequently to be reported as “false” hot spots. Signatures of real hot spots are locks, or lock pools (stripped locks) which are hot or CAS contention (AtomicLong and friends). We put a lot of effort into eliminating this sort of hot spot, but sometimes a new one can show up.
Finally, you also need to pay attention to GC. If there is too much pressure on the JVM heap, then application throughput falls through the floor. Blazegraph generally controls this pretty well, but you can get pathological cases. Depending on how you have the JVM setup, this might appear as one core being at 100% activity while the others are idle or all cores might be at 100% (parallel GC). Note that there will always be very low IO wait if you are GC bound. If you have a significant IO Wait, then you do not need to look at the heap pressure.
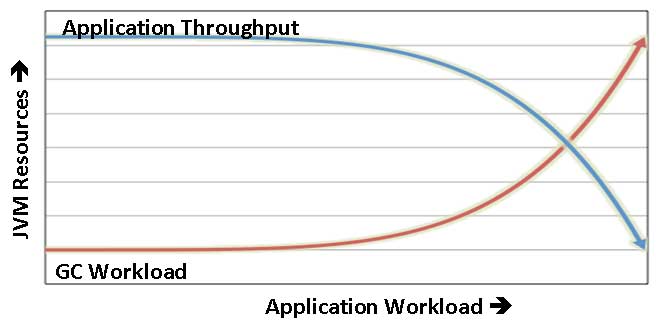
You can use jstat to report on GC at the command line or jvisualvm to see this in a UI. You can also use any number of excellent Java profilers, such as YourKit. If you are seeing 20% GC time, then you are getting into a high heap pressure scenario and your throughput is dropping. If it is about 50%, then 1/2 of the CPU time is going to garbage collection and your throughput has fallen by AT LEAST 50%. Heap pressure is driven by the object creation and retention rate. Make sure that you are not running too many queries in parallel for the server resources you have available. The NanoSparqlServer uses a thread pool to control the #of application level query threads. If you are using the Sesame API, then you have to control the query parallelism yourself. If you have a query that is creating a lot of heap pressure, then see if you can make your query more selective, change it so it does not materialize as much data on the JVM heap (ORDER BY forces everything to be materialized — even if you use it with OFFSET and LIMIT), or explore some of the low level parameters for tuning the QueryEngine (experts only). You can also enable the Analytic query mode. See below.
Now that you have an idea of where the bottleneck lies, it is time to look at your query.
Blazegraph reorders joins. This is done based on the fast range counts of the different triple/quad patterns in the query. The algorithm basically starts with the most selective access path and the best index for that and propagates variable bindings in order to estimate the as-bound cardinality and hence the order in which the subsequent joins should be executed. This works great most of the time, but it can get the join order wrong (cardinality estimation error can increase exponentially, so bad join orders do happen).
If you have a bad join order you can reorder the joins by hand, but first you need to disable the join optimizer. See QueryHints for more about this and other interesting bits query hints, but basically you need to add this to your query somewhere within a group graph pattern:
hint:Query hint:Optimizer "None" .
Or you can simply specify that some join must run first or last. Again, see QueryHints for more information.
Finally, see the section on the Runtime Query Optimizer (below) for automatically fixing bad join orderings.
The NanoSparqlServer offers an explain option to see more details for the query evaluation. Explain is particularly helpful for query authors that try to understand and optimize the behavior of their queries, and may help you detect potential correctness and performance problems.
To enable the explain mode, just check the "explain" box on the UI or add &explain to the query URL. The explain option is described in detail on the dedicated Explain page.
The AnalyticQuery package does NOT suffer from JVM heap pressure. What we have done is develop a memory manager for the Java native process heap, NOT the JVM object heap. The MemoryManager is pretty much the RWStore for main memory (up to 4 terabytes of main memory). It is 100% Java and works with NIO buffers to manage native memory. We use the MemoryManager to put very large working sets onto the native process heap, rather than the JVM object heap.
The analytic query package also includes a new hash tree index structure, the HTree, which we use for DISTINCT and GROUP BY on large result sets. We run the HTree against the MemoryManager so the data stays in RAM, but stays off the JVM object heap. Finally, we will be introducing a new Runtime Query Optimizer (RTO). The RTO is very slick and gives excellent performance on unselective queries by doing runtime optimization of the query plan and paying attention to the actual correlations, which exist in the data for the query. It will be fantastic on a cluster doing heavy analytic queries.
The analytic query mode scales up to more data, but it is NOT always faster than the JVM versions. In particular, the JVM DISTINCT is faster since it is based on a concurrent hash map while the HTree is (currently) single threaded for writers. In general, the JVM query operators enjoy a slight performance edge for selective queries, but the analytic query operations have a MUCH better performance when the query needs to materialize a lot of data on the heap - ZERO GC!
Also, the analytic mode is not a "cure all". It will not fix a bad join order. Do not just turn it on for everything. Figure out why your query is slow, and then make the right changes.
To enable analytic query, just check "analytic" box on the UI.
[X] Analytic
Or you can just add &analytic to the query URL.
This feature is available in the 1.3.x maintenance and development branch. It is currently alpha (1/8/2014) and is tentatively scheduled for GA in 2014Q1.
The purpose of the RTO is to discover a join ordering that reduces the total cost of executing a query. For low-latency queries, the RTO is not necessary and should not be enabled. We are looking into how to automatically enable the RTO when it can provide a benefit, but for now you have to do this explicitly using a query hint. Enabling the RTO makes sense when you have a high latency query and want to discovery a join ordering that will reduce the cost of that query. The RTO really only makes sense for expensive queries, and can only really help when the problem with the query is a bad join ordering. You still need to make sure that your query is doing what it needs to do and that the bottleneck is due to a bad join ordering - see the rest of this page for more information on these topics.
Unlike other query optimization techniques, the RTO optimizes the query based on the actual costs to execute the query. It does this by sampling different join orderings and observing the actual cardinality of those join orderings. Based on this, the RTO develops an estimate of the cost of the different possible join orderings and rapidly converges on a join ordering for the query that is known to be good.
The Runtime Query Optimizer (RTO) is based on a runtime sampling designed to discover the best join ordering for a specific query and data set. The approach was inspired by ROX.
The basic concept is that the query is transformed into a join graph. A join graph is:
- A set of vertices, which represent access paths (SPARQL Basic Graph Patterns).
- A set of edges, which represent possible joins between those vertices.
- A set of constraints on those joins (SPARQL FILTERs).
The RTO then explores the join graph to discover a join ordering that is optimal in the data for a given query. It does this by sampling the vertices (the access paths), incrementally building up join paths (sequences of joins), and pruning the join paths once it discovers a join order that dominates (is strictly better than) the alternatives for a given set of vertices. This process continues until a complete join ordering is discovered that dominates all of the alternatives.
The RTO is based on sampling. It will make better estimates when it uses random samples and larger sample sizes. Also, when using random samples, the RTO may recommend different join orderings each time it runs for each given query and data set. That is Ok - all of these join orderings will be good, though some may be better than others. The join orderings will converge as the size and distribution of the samples increases. Of course, large random samples can increase the cost of the RTO. This is especially true of randomly or evenly distributed samples as they can drive IOs by reading a wide range of index pages to collect the sample. Fast, pretty good query plans can be obtained using a bias, dense sample. More accurate query plans can be obtained by increasing the sample size and by using various random sampling strategies. If you have a long running query, then it can be worthwhile to let the RTO sample more fully and produce a query plan that will reduce the total running time of the query.
To enable RTO, it must be enabled by using a query hint (see QueryHints). This can be done for a specific join group (hint:Group) or for the entire query (hint:Query).
hint:Query hint:optimizer "Runtime".
If you want to know more about how the RTO is optimizing your query, enable the Explain mode.
[x] Explain
The information from the Explain can also be used to "fix" a bad query plan by disabling the query optimizer for that query (see QueryHints) and then explicitly reordering the joins yourself. However, if your query is parameterized, then hidden correlations between the query and the data may mean that a different join ordering is required for each distinct instance of your query template. In this case, you might not be able to find a single query plan that will always do well for that query template.
The Explain mode will show you the actual join ordering that the RTO discovered. It will also show you the sub-queries associated with the RTO so you can see the actual cost of running the part of the query plan that was handled by the RTO.
For example, here is LUBM Q9 with the RTO enabled.
PREFIX ub: <http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#>
SELECT ?x ?y ?z
WHERE {
hint:Group hint:optimizer "Runtime". # Enable the RTO.
?x a ub:Student . # v1
?y a ub:Faculty . # v2
?z a ub:Course . # v3
?x ub:advisor ?y . # v4
?y ub:teacherOf ?z . # v5
?x ub:takesCourse ?z . # v6
}
If you enable the Explain mode for this query, then part of the explain will include the following table. This table summarizes the final join ordering selected by the RTO.
vert srcCard * f ( in sumRgCt tplsRead out limit adjCard) = estRead estCard : sumEstRead sumEstCard
2 * ( 35973 500 500 500 500) = 35973 35973 : 35973 35973
5 35973 * 3.01 ( 166 503 503 500 500 500) = 1515 108352 : 37488 144325
4 108352 * 6.41 ( 78 501 501 500 500 500) = 3211 694564 : 40699 838889
6 694564 * 0.02 ( 400 9 9 9 500 9) = 0 15627 : 40699 854516
1 15627 * 0.44 ( 9 4 4 4 500 4) = 1 6945 : 40700 861461
3 6945 * 1.00 ( 4 4 4 4 500 4) = 4 6945 : 40704 868406
The key columns are:
vert : The vertices in the join path in the selected evaluation order.
srcCard : The estimated input cardinality to each join (E means Exact).
f : The estimated join hit ratio for each join.
in : The #of input solutions for each cutoff join.
limit : The sample size for each cutoff join.
out : The #of output solutions for each cutoff join.
sumEstCard : The cumulative estimated cardinality of the join path.
In order to figure out the actual join order, you need to look at the predSummary column in the Explain view. The number in the square brackets is the identifier for each predicate in the join group. This corresponds 1:1 with the vertex labels in the RTO table above. For this query, those predicates are:
SPOPredicate[2](?y, Vocab(14)[http://www.w3.org/1999/02/22-rdf-syntax-ns#type], Vocab(87)[http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#Faculty])
SPOPredicate[5](?y, Vocab(-115)[http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#teacherOf], ?z)
SPOPredicate[4](?x, Vocab(116)[http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#advisor], ?y)
SPOPredicate[6](?x, Vocab(-116)[http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#takesCourse], ?z)
SPOPredicate[1](?x, Vocab(14)[http://www.w3.org/1999/02/22-rdf-syntax-ns#type], Vocab(107)[http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#Student])
SPOPredicate[3](?z, Vocab(14)[http://www.w3.org/1999/02/22-rdf-syntax-ns#type], Vocab(82)[http://www.lehigh.edu/~zhp2/2004/0401/univ-bench.owl#Course])
Using this information, you can look back at the original query and figure out the actual join ordering. We have labeled the vertices in the original query (above) as v1, v2, ..., v6 to make this simpler.
The RTO is currently an alpha feature and will be optimized and hardened before GA. The current implementation can be used to analyze a query with complex joins and identify an optimal join ordering. This provides a very useful tool for a hard problem.
Known limitations include:
- OPTIONALs are not reordered.
- Only triples mode joins are fully supported. Sampling of named graph, default graph, and scale-out access paths may produce results, but there are known problems.
- Sub-groups and Sub-selects are not reordered within the parent group.
- The RTO may do too much work if there are cardinality estimate underflows (i.e., if sampling can not identify any solutions for some join orderings).
Logging can be very useful to understand your query. The following logger will show the original query, the parse tree, the bigdata AST and optimized AST, and the physical query plan (bops).
log4j.logger.com.bigdata.rdf.sparql.ast.eval=INFO
Using the SolutionsLog you can also see the solutions as they flow between the operators in the query plan. Make sure that you uncomment the first line to enable the SolutionsLog. This provides a lot of detail, so you do not want this on during normal query evaluation, but it is a great tool for debugging a query.
##
# Solutions trace (tab delimited file). Uncomment the next line to enable.
#log4j.logger.com.bigdata.bop.engine.SolutionsLog=INFO,solutionsLog
log4j.additivity.com.bigdata.bop.engine.SolutionsLog=false
log4j.appender.solutionsLog=org.apache.log4j.ConsoleAppender
#log4j.appender.solutionsLog=org.apache.log4j.FileAppender
log4j.appender.solutionsLog.Threshold=ALL
log4j.appender.solutionsLog.File=solutions.csv
log4j.appender.solutionsLog.Append=true
# I find that it is nicer to have this unbuffered since you can see what
# is going on and to make sure that I have complete rule evaluation logs
# on shutdown.
log4j.appender.solutionsLog.BufferedIO=false
log4j.appender.solutionsLog.layout=org.apache.log4j.PatternLayout
log4j.appender.solutionsLog.layout.ConversionPattern=SOLUTION:\t%m
