This is a tutorial on git using the command line. My goal is to make this tutorial as deep as it gets within time, so this tutorial will evolve gradually within time. However, first things first, because that I believe that an ordinary developer should learn basic git concepts and what it does, when to use what, I'll focus on that at first. Later then, I want to extend this tutorial about advanced features of git.
- 0 Introduction
- 1 Branches
- 2 Branches Demo
- 3 Basic Git Commands
- 4 Working With Remote
- 5 More On Branching
- 6 Merge Basics
- 7 Git Log Basics
- 8 Fixing Merge Conflicts
- 9 Revert Basics
- 10 Rebase Basics
- 11 Cherry Picking
Let's first think about the concept. Git is a versioning tool, and what's a versioning tool. Think about this, you with your team is working in a daily magazine. There are writers and also multiple reviewers and editors. Sometimes, even, a simple article, possibly written by more than one writer. After the article is finished with a draft, reviewers may put some note, editors change the article. So this means that, before a final version of an article, several people are working with the initial article. How they are going to be aware of the changes at the same time and work wisely? That's the case example of a version control.
Assuming you are the writer. You make an initial draft, version 1, make multiple copies for the same draft, let's say, there are 2 editors whose names are Mark and David, working with you, then making 2 draft copies of version one. Then, Mark makes a change in paragraph 2, and make the version draft 1.1. However, editor 2 makes a change also on paragraph 2, but also on paragraph 4. Assuming David is a senior editor, he will be the one who decides for all the changes. It's very easy to apply on draft version 1.2 for parapraph 4 because, there are no changes, however, on paragraph 2, Mark made some changes so David has 3 options;
- Apply only Mark's changes (ignoring his own changes)
- Apply only his own changes (ignoring Mark's changes)
- Make a mix of Mark's changes and his.
After then, draft version 1.3 which is a merge of 1.1 and 1.2, will be released and can be sent to the reviewers.
In this example, I just wanted to mention 2 things. First of all, Git is a version tool, and secondly, it's not dependent on programming languages or working domain. It's domain-agnostic, it only focuses on versions based on files.
First of all, I'll call any project as "repository". This can be a repository of a Magazine - March, or a repository of a framework written in Java, or it could containt just a README.md file. That's not important. Just to set the terminology right.
In the introduction part, I've written about how people can work with different versions at the same time. So, if there is an initial version of a file, let's say, version 1.0, then if two people are going to work with that, then it can be cloned (copied) so that different workers can work with their own version. This is called as "branch" in git. A branch is a version of the "repository" inherited from it's parent version.
Let's give a real world example. You are to write a framework. It has database part, and business-logic part, which are located in different packages. Architect makes a boiler-plate code, and initialized git with it, because it's the first branch initialized, it's called as "master" branch, every other branch inherited either from this branch, or inherited from any branch inherited from it. Then, the developers who is going to work with the database part, will have his/her own branch inherited from the master branch. Let's call it "repo-db-feature", and the developer who is going to work with the business-logic will have his/her own branch too, "repo-business-feature".
In this demo, we will see how a simple branch is created.
- Make a folder, called as "repo1"
- Make a file called as "content.txt". The content of the file should be as follows;
This is an initial sentence of the file from master.
- Apply the following commands;
git init
git status
git add content.txt
git status
git commit -m "initial commit"
git status
The output in my windows command line is as follows;
D:\repo1>git init
Initialized empty Git repository in D:/repo1/.git/
D:\repo1>git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
content.txt
nothing added to commit but untracked files present (use "git add" to track)
D:\repo1>git add content.txt
D:\repo1>git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: content.txt
D:\repo1>git commit -m "initial commit"
[master (root-commit) c351f84] initial commit
1 file changed, 1 insertion(+)
create mode 100644 content.txt
D:\repo1>git status
On branch master
nothing to commit, working tree clean
Let's explain what do these commands.
In the previous section, we have used the following commands.
- git init
- git status
- git add content.txt
- git commit -m "initial commit"
This is the command that initializes the repository. When you have a repository, in the master folder, you run command and git makes a secret folder called as ".git", stores git-related files so that git can track everything that changes under this command.
This is the command when we want to see a summary of the changed/tracked/untracked files.
The following command says that we have a file which is not tracked by git. Because we created this file after we git-init, the git system doesn't track the file but status reports that to us.
D:\repo1>git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
content.txt
nothing added to commit but untracked files present (use "git add" to track)
After we create a file in a git repository, we run the git status (we don't have to but just to be sure if we need to), and see that there are untracked files. With git-add command, we add them and make git-aware of that;
D:\repo1>git add content.txt
D:\repo1>git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: content.txt
As you can see, after we add the file, git tells us that there is a new file (or a changed file), to be committed.
When we commit our changes, they become persistent to the git system. So any changes, you need to add them, and then commit them so that it will be written into your branch.
The command pattern is as follows;
git commit -m "<your_commit_comment_here>"
Let's take a look at to this;
D:\repo1>git commit -m "initial commit"
[master (root-commit) c351f84] initial commit
1 file changed, 1 insertion(+)
create mode 100644 content.txt
D:\repo1>git status
On branch master
nothing to commit, working tree clean
As you can see, after we commit, git status gives us no any information, it seems, it's only interested in new files and changed files. So how are we supposed to be sure that our commit is persisted.
With "git log" command (which is actually a bit complex then it seems with multiple parameters), we can see the list of all the commits like a LIFO stack. So we see on the top of the list, the latest commit.
D:\repo1>git log
commit c351f84ded3f797302e127026fd161f69c2b7f70 (HEAD -> master)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Sun Oct 18 23:58:42 2020 +0200
initial commit
Generally, you have lot's of commits but you only need to see the last n commits. Then you should use;
git log -n <number_of_commits_you_want_to_see>
ex: git log -n 2
It's nice to work git in local, and also useful for you to control your own projects' versioning. But when you work with multiple people or in teams, you need to have your repository at remote. To make an example of that, we will use github, so I assume you have already a github account.
A new repository is created on the git-server, in this demo, our git-server will be github but it can also only be bitbucket or any other git-based server.
Here is what we are going to do;
- create a repository named "example" on github
- clone the repository to your local environment (your computer)
- add a simple file named with "content.txt" (with any arbitrary content)
- commit the file to local default branch (in this case, the master branch or microsoft github terminology: main branch)
- push it to the git server (github)
In your github UI, you can create a repository by pressing the + button on top right. When you create it, it will be similar to the following;
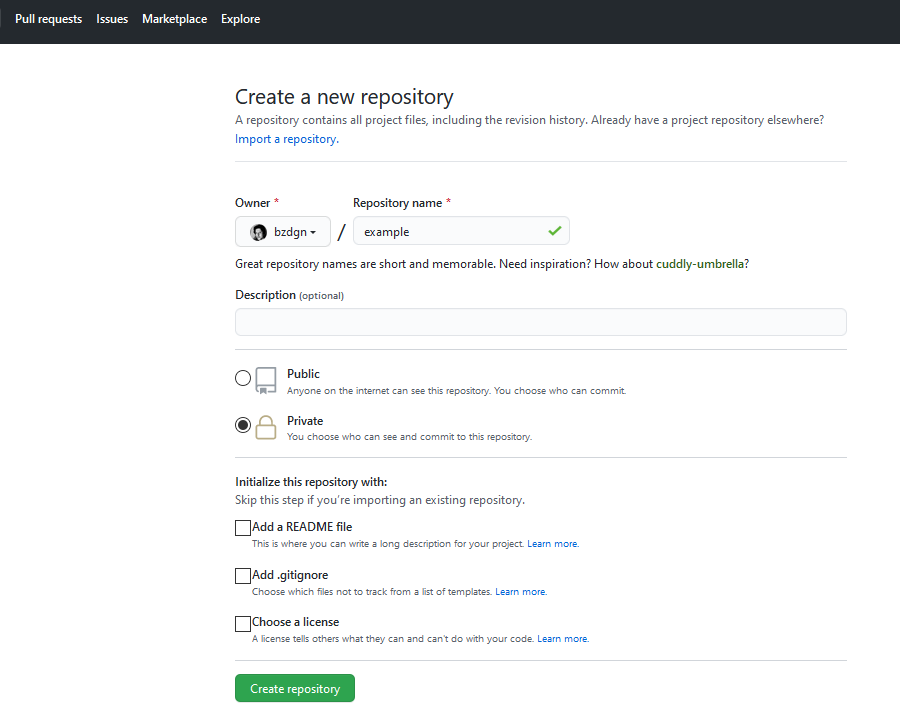
You can see that initially you can add a README.md file, and also a .gitignore file (will be discussed later) but you don't have to do that, you can also add them after you create your project.
After you create the project in the server (github), in order to work with that repository, you have to clone it on your local branch. There is a section with https/ssh, as you can see in the following capture;
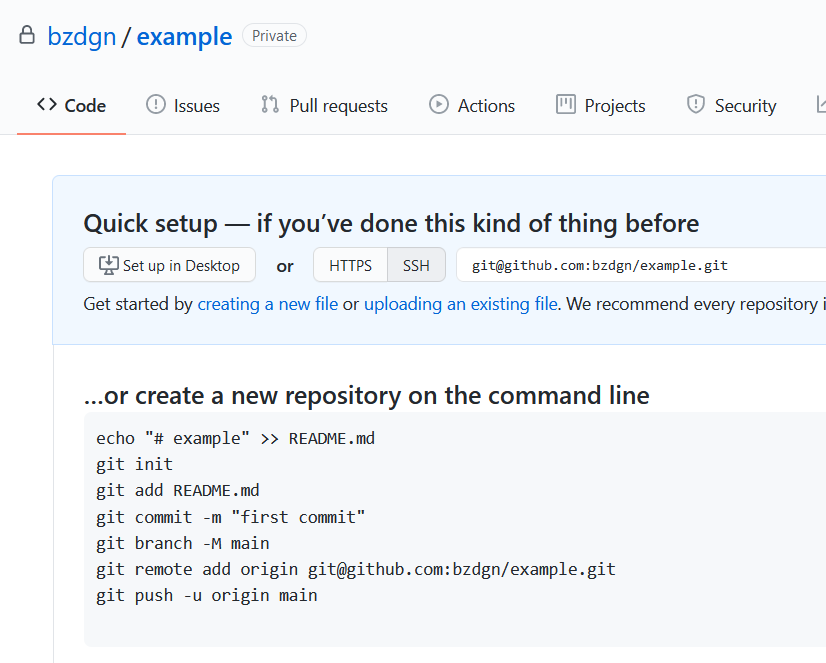
You can use that link, via an ssh or an https protocol (I use ssh always if possible), and clone it to your local environment. Cloning means, you copy everything that the repo in the server has;
For this example, I've used this command to clone my github repo from the server: git clone git@github.com:bzdgn/example.git
But in general, it will be like;
git clone git@github.com:<your_username>/<your_repo_name>.git
Get into the main directory of your cloned repository on your local environment, and make a file with any content, named as "content.txt". Then commit and push the file;
git add content.txt
git commit -m "initial commit for content.txt"
git push
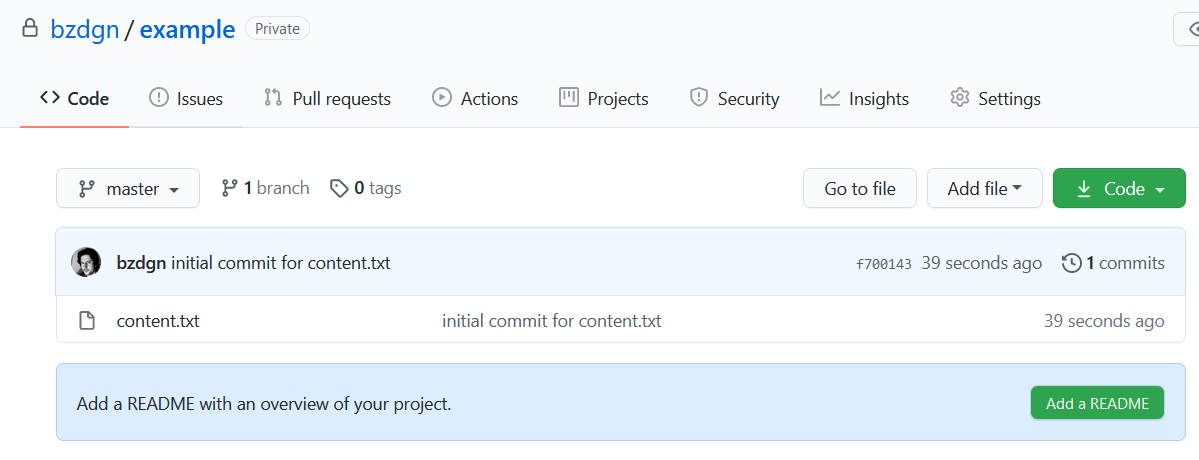
git push command (actually you can explicitly the branch name if you are working with multiple branch, but this will push to the only branch which is main), will push the committed changes to the server. Then you can check via github to see the changes. You will see the content.txt file now;
Before we go further, there are several basic commands about branching. These are trivial commands for creating and removing branches;
If there are multiple branches, you can checkout on one particular branch with;
git checkout <branch_name>
To create a new branch inherited from existing branch, the following command can be used;
git checkout -b <branch_name>
For example, when you create a new branch with git checkout -b <branch_name> while you are in master, the new branch will be inherited from master. But if you are on a feature branch, then it will be inherited from the feature_branch and create a new branch with the designated branch name.
To rename an existing branch, you can use this command;
git branch -m <old_branch_name> <new_branch_name>
To delete an existing branch, you can use the following;
git branch -d <branch_name>
But beware that if there are unmerged commits, you will get errors
However, you can also force deleting by the capital "D", as written below;
git branch -D <branch_name>
To list all the existing local branches;
git branch
Let's start what is a merge by giving an example. Let's say, in a master/main branch, the November edition of a magazine we have. Every author has their own branches, development/draft brances for their articles for the upcoming November edition. As writer (or developer), you have to write your own article and make a draft branch. This branch of yours contains only changes due to your article, the page you are responsible for. When you are done, that draft must be merged with the master/main branch.
The simples case of a merge is, while you are working on your own branch, no change on master branch is done. This is a specific type of a merge under-the-hood, called as fast-forward. Let's see that within an example.
- Make a folder, called as "repo2", cd to this folder and initialize with git:
git init - create a file with the name "contents2.txt" with the followings;
This is the master version
Entry 1 is about cars
Entry 2 is about roads
Entry 3 is about houses
- Apply
git add contents2.txt - Apply
git commit -m "initial commit from master branch" - Create a new branch, called as feature1:
git checkout -b feature1 - Open "contents2.txt" and update the line starting with "Entry 2" as follows;
This is the master version
Entry 1 is about cars
Entry 2 is about bikes
Entry 3 is about houses
git statusto see the changes- Apply
git add contents2.txt - Apply
git commit -m "feature commit from feature branch"
If everything goes well, your output in your command line should similar to this (depending on the os)
D:\>mkdir repo2
D:\>cd repo2
D:\repo2>git init
Initialized empty Git repository in D:/repo2/.git/
D:\repo2>git add contents2.txt
D:\repo2>git commit -m "initial commit from master branch"
[master (root-commit) bd6ce60] initial commit from master branch
1 file changed, 4 insertions(+)
create mode 100644 contents2.txt
D:\repo2>git checkout -b feature1
Switched to a new branch 'feature1'
D:\repo2>git status
On branch feature1
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: contents2.txt
no changes added to commit (use "git add" and/or "git commit -a")
D:\repo2>git add contents2.txt
D:\repo2>git commit -m "feature commit from feature branch"
[feature1 bc569e1] feature commit from feature branch
1 file changed, 1 insertion(+), 1 deletion(-)
Type git branch to see all the branches;
D:\repo2>git branch
* feature1
master
To see the changes, let's first checkout the master and apply git-log;
- git checkout master
- git log
As you can see below, there is only 1 commit in master branch;
D:\repo2>git checkout master
Switched to branch 'master'
D:\repo2>git log
commit bd6ce60ea770f37509bc20c79dd13f5ddd23f6ba (HEAD -> master)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Mon Oct 19 02:15:36 2020 +0200
initial commit from master branch
Let's do the same for feature1 branch;
- git checkout feature1
- git log
D:\repo2>git checkout feature1
Switched to branch 'feature1'
D:\repo2>git log
commit bc569e1a905b71c6e4315f245b9a1da3803ccb2f (HEAD -> feature1)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Mon Oct 19 02:16:20 2020 +0200
feature commit from feature branch
commit bd6ce60ea770f37509bc20c79dd13f5ddd23f6ba (master)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Mon Oct 19 02:15:36 2020 +0200
initial commit from master branch
As you can see, there are 2 commits on feature1 branch. So, assuming we are done, we have to apply a merge on master. When we say "merge on master", it means, specifically, merging our existing branch on to master. To do that, normally we checkout on the branch we want to use as a target, and merge the feature branch on to it. But before going further, I want to introduce you the git diff command;
Using git dif we can compare one branch with another (and vice versa), let's apply it so;
git diff feature1 master
The output is as follows;
D:\repo2>git diff feature1 master
diff --git a/contents2.txt b/contents2.txt
index d0a9b56..115ec54 100644
--- a/contents2.txt
+++ b/contents2.txt
@@ -1,4 +1,4 @@
This is the master version
Entry 1 is about cars
-Entry 2 is about bikes
+Entry 2 is about roads
Entry 3 is about houses
\ No newline at end of file
This means, feature1 branch deletes the line starting within the contents2.txt, and adding the line starting with +.
If you apply the other way around, git diff master feature1, you will see that the - and the + lines are interchanged;
D:\repo2>git diff master feature1
diff --git a/contents2.txt b/contents2.txt
index 115ec54..d0a9b56 100644
--- a/contents2.txt
+++ b/contents2.txt
@@ -1,4 +1,4 @@
This is the master version
Entry 1 is about cars
-Entry 2 is about roads
+Entry 2 is about bikes
Entry 3 is about houses
\ No newline at end of file
This makes sense so. Anyways, with the git diff feature1 master command, we see that "roads" word is deleted and "bikes" word is added on the line starting with "Entry 2". Before merging, let's see the last view of the contents2.txt file in master branch;
- git checkout master
- cat contents2.txt (for windows: type contents2.txt)
D:\repo2>git checkout master
Switched to branch 'master'
D:\repo2>type contents2.txt
This is the master version
Entry 1 is about cars
Entry 2 is about roads
Entry 3 is about houses
Let's merge it with master;
git checkout master
git merge feature1
Here is the output of the command line;
D:\repo2>git checkout master
Already on 'master'
D:\repo2>git merge feature1
Updating bd6ce60..bc569e1
Fast-forward
contents2.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
Let's see the latest merged contents2.txt file content;
This is the master version
Entry 1 is about cars
Entry 2 is about bikes
Entry 3 is about houses
As you can see, it's equalized with the branch version. Let's check that also with the "git log" command, both branches now, after the merge, should have the same commits;
git log
And the output is;
D:\repo2>git log
commit bc569e1a905b71c6e4315f245b9a1da3803ccb2f (HEAD -> master, feature1)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Mon Oct 19 02:16:20 2020 +0200
feature commit from feature branch
commit bd6ce60ea770f37509bc20c79dd13f5ddd23f6ba
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Mon Oct 19 02:15:36 2020 +0200
initial commit from master branch
Before moving any further, I want to tell what a fast-forward merge means. If no changes are made on master branch, while you are working with a feature branch (or a sub-branch), and then you merge it on master, then it just fast forwards all the commits into master. That simple! Think about this, you start watching Video streaming on a train on your phone app, while going back from work to home. You watched the first 30 minutes of the movie. Then you come at home, eat something and then, you open your pc, using the same subscription, to the same Video Streaming company, you start the movie, and it just continues from the same point where you have paused. It actually checks if other clients to the same subscription (phone, pad, computer...) watched that movie, if so, it fast-forwards, assuming you have already watched that, which is true.
But merge is not always bed of roses, so there are cases where you have more work to do. But before jumping into that section, I just want to talk a bit about git log and also git diff command.
Git log is a very powerful command line tool that you can use to see the commits, and also to filter them based on several parameters. You can play with git log so that it makes it easier for you to see the commits, the hash, author, date and other parameters so. Let's give some examples about git log.
To see the commits, you can just use git log as below;
D:\git-tutorial>git log
commit 03b5d54030825a7386d34dfaad40527300ec8772 (HEAD -> main, origin/main, origin/HEAD)
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 02:41:39 2020 +0200
WIP for Section 7
commit 143d649ed8ae7567b56663100b2f62ad64b141c3
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 02:34:52 2020 +0200
Update README.md
commit f74c49a54c1adf8c42475940db578302421535a6
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 02:33:09 2020 +0200
Update README.md
commit 7b04a36f590d5676c11cf5d8995438d02323feee
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 01:53:17 2020 +0200
Update README.md
commit 08c2c65ec4c20832857ecbc89931544f4f90ed06
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 01:37:21 2020 +0200
Update README.md
:
As you can see, you can see the commit stack, the first shown commit is the last one, and if it exceeds the maximum line of the command line, you will see a colon (:). If you press space, you will see the older commits in the next page. If you press just space, you will go down. If you press q, then you will quit to terminal.
Let's see, the commits as one line: git log --oneline
You will only see the hash and the git commit message as below. The last commit, again is the first one, and called as HEAD.
D:\git-tutorial>git log --oneline
03b5d54 (HEAD -> main, origin/main, origin/HEAD) WIP for Section 7
143d649 Update README.md
f74c49a Update README.md
7b04a36 Update README.md
08c2c65 Update README.md
fe8ff56 re-rename
80f8d29 rename
7397024 Update README.md
4728263 trim png file
f64e866 Update README.md
75ef53f Update README.md
e68b146 Update README.md
29c94e8 Update README.md
0b87e08 Update README.md
7e04f9a Update README.md
f0e233d Merge branch 'main' of github.com:bzdgn/git-tutorial into main
1880c1f misc files
008a458 wip
c507fd2 pushing to remote - wip
1b82ea0 Second commit for basic git commands
d7765d4 Initial commit for README
35bba2f Initial commit
Please note that HEAD actually is a pointer to the lastest log as you can see here;

Let's see only the last 3 commits, then you can use: git log -n <number_of_commits
Here is an example;
D:\git-tutorial>git log -n 3
commit 03b5d54030825a7386d34dfaad40527300ec8772 (HEAD -> main, origin/main, origin/HEAD)
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 02:41:39 2020 +0200
WIP for Section 7
commit 143d649ed8ae7567b56663100b2f62ad64b141c3
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 02:34:52 2020 +0200
Update README.md
commit f74c49a54c1adf8c42475940db578302421535a6
Author: Levent Divilioglu <bzdgn@users.noreply.github.com>
Date: Mon Oct 19 02:33:09 2020 +0200
Update README.md
You can also mix the options like, see the last 3 commits and in the --oneline format;
D:\git-tutorial>git log -n 3 --oneline
03b5d54 (HEAD -> main, origin/main, origin/HEAD) WIP for Section 7
143d649 Update README.md
f74c49a Update README.md
You can also use the filter, and see the last 3 commits of the same author;
D:\git-tutorial>git log -n 3 --oneline --author="Levent Divilioglu"
03b5d54 (HEAD -> main, origin/main, origin/HEAD) WIP for Section 7
143d649 Update README.md
f74c49a Update README.md
When merging one branch (usually a feature branch) with another (mostly master/main branch), a merge conflict is likely to be happen, especially if you are working with a team. For unexperienced users, merge conflicts seems a bit scary but it's not a scary case. Let's first start explaining what is a merge conflict.
You remember the simplest merge case we have spoken above: fast-forward. It's the case, when you are working in a branch, nothing happens on the master, so, when you merge onto master, git just makes a copy of the commits you have done on your branch, and puts on to the top of HEAD of the master branch. So it's actually nothing more than a fast-forward. On that case, no conflicts are expected. But what happens, while you are merging on your feature branch, a team member of yours also working on another branch, and what happens, at the same time, you two, are working on the same file? Then, if your friend merges it before you, you will have a merge conflict, because the file you are working with, has already changed so you have to decide to take his changes, or ignore it and use your changes.
Let's summarize what happens in this example. Assume that you have an existing two commits on master, which is X1 and X2. HEAD points to the latest commit, which is X2;
X1 -> X2(HEAD)
Then Mark and David, makes their own branchs, respectively, branch_mark, and branch_david. branch_mark has only one commit, which is M1. branch_mark seems like this;
X1 -> X2 -> M1
And branch_david seems like this, with one commit;
X1 -> X2 -> D1
Assume that Mark, merges his branch to master, and it's a fast-forward so for Mark (who is lucky), doesn't have any merge conflicts. And then the master will be as below;
X1 -> X2 -> M1 (HEAD)
Then David, checksout on master, and apply the git merge branch_david, so he tries to merge his branch on master and then, because the commit M1 and D1 has changes on the same file, he will get merge conflicts. This is what you need to know theory-wise.
Now it's time to make a practice.
- Create a folder called as repo3 and apply:
git init - Create a file contents.txt with the following content;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
<fill here with something>
Then she married with him have have 3 children.
- Apply:
git add contents - Apply:
git commit -m "master main commit"
Now, we have a master branch with 1 commit. We need to create 2 more branches. branch_a and branch_b. These branches will have different changes for the 4th line.
For branch_a, here is what you need to do;
- Apply:
git checkout -b branch_a - Edit the contents file as below;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
And she met with a very ugly, smelly giant wolf!!!1
Then she married with him have have 3 children.
- Apply:
git add contents.txt - Apply:
git commit -m "branch_a commit"
For branch_b, here is what you need to do;
- Apply:
git checkout master(So we need to branched from master like we did n branch_a) - Apply:
git checkout -b branch_b - Edit the contents file as below;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
And she met with a very handsome prince.
Then she married with him have have 3 children.
- Apply:
git add contents.txt - Apply:
git commit -m "branch_b commit"
So, here how contents.txt file is seen on master/main branch. You can checkout on master and open the contents.txt to see it;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
<fill here with something>
Then she married with him have have 3 children.
Here how the same file looks on branch_a master. You can checkout on master and open the contents.txt to see it;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
And she met with a very ugly, smelly giant wolf!!!1
Then she married with him have have 3 children.
And lastly, here how the same file looks on branch_b master. You can checkout on master and open the contents.txt to see it;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
And she met with a very handsome prince.
Then she married with him have have 3 children.
Let's merge branch_a first, to master branch;
- Apply:
git checkout master - Apply:
git merge branch_a
You will see something similar to this;
D:\repo3>git checkout master
Switched to branch 'master'
D:\repo3>git merge branch_a
Updating 9d872b9..3a46183
Fast-forward
contents.txt | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
And the content of the contents.txt file is changed to the following;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
And she met with a very ugly, smelly giant wolf!!!1
Then she married with him have have 3 children.
Himm... looks doesn't right. Children should not read a story that a beautiful girl marries with a smelly giant ugly wolf and have 3 children! We have to fix it, aren't we?
But before doing so, let's see the commits on git log;
D:\repo3>git log --oneline
3a46183 (HEAD -> master, branch_a) branch_a commit
9d872b9 master main commit
As you can see, the only commit of branch_a branch is copied on the top of master. Now, let's merge the branch_b to master;
- Apply:
git checkout master - Apply:
git merge branch_b
The output will be as follows as expected;
D:\repo3>git checkout master
Already on 'master'
D:\repo3>git merge branch_b
Auto-merging contents.txt
CONFLICT (content): Merge conflict in contents.txt
Automatic merge failed; fix conflicts and then commit the result.
Ohh, merge conflict, what are we going to do?!! May be we have to turn the computer off, wait a few seconds and turn it on again. Of course I'm joking, what we are going to do is fixing the merge conflict. That's what we have expected right, even if we are working alone, with our own branches, we can have merge conflicts as you can see.
Let's check the file contents.txt;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
<<<<<<< HEAD
And she met with a very ugly, smelly giant wolf!!!1
=======
And she met with a very handsome prince.
>>>>>>> branch_b
Then she married with him have have 3 children.
You have to learn how to read this, if you are using eclipse, or a simple notepad, it's not important. Take a look at to this;
...
<<<<<<< HEAD
Here will be the content of the HEAD conflicting with current branch.
=======
Here will be the content of the merging branch, conflicting with HEAD.
>>>>>>> branch_name
...
What I want to mention is, starting with the line <<<<<<< HEAD to the =======, you have the conflicting part of the current(in this case, master) branch. And beginning from the =======, to the >>>>>>> branch_name, that content is the conflicting part of the merging branch. These two are conflicting, and you can choose from the current branch (ours), or you can choose from the merging branch (theirs), or you just mix it, or remove it, at least, it's just a simple text right. As soon as you fix it, it's not important.
Let's take the part coming from the branch_b, I've edited the contents.txt as below;
Once upon a time, there was a very beautiful girl.
She liked to go to the forest with her dog every day.
One day, she was lost in the road.
And she met with a very handsome prince.
Then she married with him have have 3 children.
To merge it;
- Apply:
git add contents.txt - Apply:
git commit -m "solving merge conflicts" - Apply:
git log --oneline
Here is what you get;
D:\repo3>git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: contents.txt
no changes added to commit (use "git add" and/or "git commit -a")
D:\repo3>git add contents.txt
D:\repo3>git commit -m "solving merge conflicts"
[master 5a73c0c] solving merge conflicts
D:\repo3>git log --oneline
5a73c0c (HEAD -> master) solving merge conflicts
eafc758 (branch_b) branch_b commit
3a46183 (branch_a) branch_a commit
9d872b9 master main commit
So the merge conflict is solved. git merge has much more many options, but to solve conflict, we only need to fix the conflicting files.
It sometimes happens that you commit something and it doesn't work, either because that's dependent on configuration, or because you were just careless, or you just fix something while you break something else. The reason is not important, git revert is used for that, for reverting one or several commits. The most simple definition for git revert is, it's just an undo for git.
I believe, understanding the use case of revert is very important, and as you know it, you will be more careful when you are applying your commits. Why? Because you will know and consider if something goes wrong, you have to revert it, and that's why, a simple commit must be tidy. We will see that, especially when we talk about rebase in the next section.
Let's learn it by practice;
- Create a folder: repo4 and change to the directory.
- Apply:
git init - Create "contents.txt" with the contents below;
My first sentence.
- Apply:
git add contents.txtandgit commit -m "first commit" - Edit "contents.txt" with the contents below;
My second sentence.
- Apply:
git add contents.txtandgit commit -m "second commit"
When you apply git log --oneline, you will see the following two commits;
D:\repo4>git log --oneline
ba97727 (HEAD -> master) second commit
7d7ba6b first commit
And the latest status of the file of "contents.txt" is as below;
My first sentence.
My second sentence.
Let's remove our last commit. So, let's see the last commit: git log -n 1
D:\repo4>git log -n 1
commit ba97727c7e79967493eb19e11432d804545bb3f6 (HEAD -> master)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Tue Oct 20 09:15:49 2020 +0200
second commit
We have to remember this hash to make a revert: ba97727c7e79967493eb19e11432d804545bb3f6
Now, there are two ways to apply a git revert;
First way is;
- Apply:
git revert ba97727c7e79967493eb19e11432d804545bb3f6 - The upper command will automatically open the default text editor, in my system it's vi, and the default is vi or vim in linux. It just simply ask the user to update the revert commit message. Do as you wish, and if you are using vi/vim too, when you are done, just press escape and write "wq!", which stands for write&quit, as shown below;

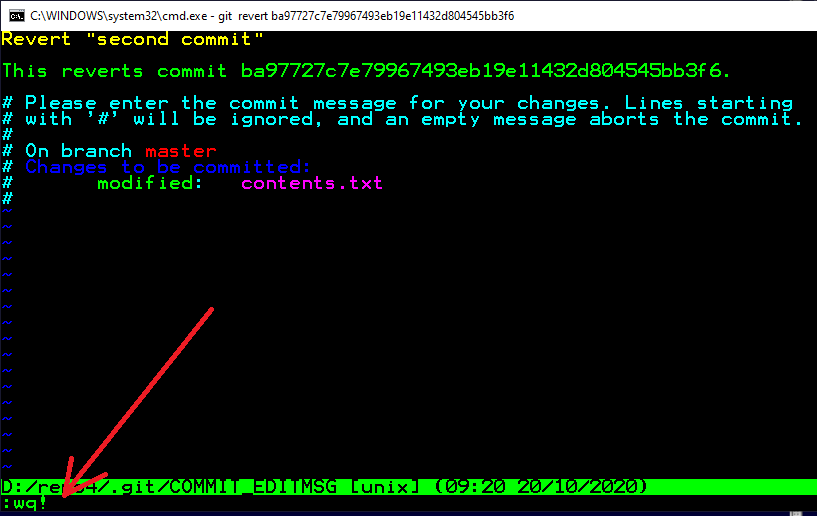
As you are done with revert message editing, it's done. Apply as simple git log --oneline to see the revert message;
D:\repo4>git revert ba97727c7e79967493eb19e11432d804545bb3f6
[master 103d8ab] Revert "second commit"
1 file changed, 1 insertion(+), 2 deletions(-)
D:\repo4>git log --oneline
103d8ab (HEAD -> master) Revert "second commit"
ba97727 second commit
7d7ba6b first commit
As you can see, the second commit is reverted, to be sure, you can check the "contents.txt" file to see that the second line is gone.
The second way to revert is this, using reference with HEAD
Instead of reverting via hash, if you apply this command;
git revert HEAD~1..HEAD
and edit the revert-message through the default text editor, it will revert the last commit as well. The generic version of this command should be like;
git revert HEAD~<number_of_commits>..HEAD
If you run git revert HEAD~5..HEAD, it means "revert the last 5 commits".
Let's make an example for this;
- Create a directory "repo5", change to this directory and apply:
git init - I believe now you can easily do this sequentially. Create a file named as "contents.txt" and add every line and commit it distinctively.
This is my first line
This is my second line
This is my third line
This is my fourth line
This is my fifth line
So there will be 5 commits.
When you are done, it should look like this when you apply git log --oneline;
D:\repo5>git log --oneline
ea7166b (HEAD -> master) fifth commit
e370bf7 fourth commit
e39e38e third commit
1d64d23 second commit
ebb38da first commit
So, I want to revert the last 3 commits, which means, the last 3 lines will be removed. There are again, two ways to do that. You will see why it is so and you will regret the first way we are going to take.
Just apply: git revert HEAD~3..HEAD, after this command, for 3 times, you are going to edit revert message for each commit. Then you will get to the terminal automatically;
D:\repo5>git revert HEAD~3..HEAD
[master e8ee88b] Revert "fifth commit"
1 file changed, 1 insertion(+), 2 deletions(-)
[master 07b06f9] Revert "fourth commit"
1 file changed, 1 insertion(+), 2 deletions(-)
[master c0793bf] Revert "third commit"
1 file changed, 1 insertion(+), 2 deletions(-)
Apply the git log and see, there are 3 distinct revert commits;
D:\repo5>git log --oneline
c0793bf (HEAD -> master) Revert "third commit"
07b06f9 Revert "fourth commit"
e8ee88b Revert "fifth commit"
ea7166b fifth commit
e370bf7 fourth commit
e39e38e third commit
1d64d23 second commit
ebb38da first commit
Check the file "contents.txt" so see the last 3 lines related to the last 3 commits are deleted;
This is my first line
This is my second line
So it's very annoying to commit for every revert right? There's a better way, let's see that. Again, we have to set our repo up;
- Delete and create the directory "repo5", change to this directory and apply:
git init - I believe now you can easily do this sequentially. Create a file named as "contents.txt" and add every line and commit it distinctively.
This is my first line
This is my second line
This is my third line
This is my fourth line
This is my fifth line
So there will be 5 commits.
To revert the last 3 commits;
- Apply:
git revert HEAD~3..HEAD --no-commit - Apply:
git commit -m "reverting last 3 commits"
Now you can check git log;
D:\repo5>git log --oneline
cbc87d4 (HEAD -> master) reverting last 3 commits
ea7166b fifth commit
e370bf7 fourth commit
e39e38e third commit
1d64d23 second commit
ebb38da first commit
You see, so in our command git revert HEAD~3..HEAD --no-commit, the --no-commit option just reverts the commits, and then we manually enter a commit message regarding to our reverts. Simpler and better!
Just to ensure, check your file and see the last three lines regarding to the three commits are removed;
This is my first line
This is my second line
Well done!
When we work on drafts, it's quite messy. Before we release something, we need to clean our workbench. The same applies to working with git environment. You work on your branch, make a dozen of commits and then if you push it to the remote, it will be annoying! Just for a simple functionality, if you make multiple commits to fix typos, renames, it's hard for readibility in git log, and also it's hard for manageability. Besides, when you do so, if you make a mistake, you are going to revert all those messy commits! So here another question comes: "What is a commit", in my huble opinion, a unit of work as small as possible that cannot be separable, should be wrapped in one commit!
My rule of thumb again;
"A unit of work as small as possible that cannot be separable, should be wrapped in one commit!"
This can change from team to team, you can discuss, but at least that's how I do in git.
So what's a rebase then? In this section, I'll not go into the depth of rebase, it's an advanced tool comes with git. But I want to introduce "squashing" which git rebase makes it available to us. When you want to unify multiple commits related to a unit of work, you use rebase to squash those commits into one. Git is a very smart tool, will collect those multiple commits, makes one new commit from the start of the rebase point. So simply: We will use git rebase to squash multiple commits into one.
What's good in this? Let's say, you make a commit for a fix, then several commits for renaming typos, because you were clumpsy. So finally, for one unit of code, you have 2 commits let's say. Then later on, you push it to the master, and it's seen that your fix has errors, breaks the integration tests somehow (I have written integration tests because if you push something while unit tests are failing, dude, you are doing it all wrong!), so you need to revert it. But because you have not wrapped your commits into one commit, you have to revert 2. If you have 5 commits on one fix, you have to revert 5 commits. And then, it looks really bad on git log. That's why, always squash a unit of work to one commit!
Again: "A unit of work as small as possible that cannot be separable, should be wrapped in one commit!"
So let's go for an example, learn it by heart as we always do;
Here is our setup;
- Create the directory "repo6", change to this directory and apply:
git init - I believe now you can easily do this sequentially. Create a file named as "contents.txt" and add every line and commit it distinctively.
Go to the station Eindhoven
Find the yellow machine to load your OV chipkaart
Put your kaart in the machine
Load money on the machine
Use your bank card to and enter your pin to finish
So there will be 5 commits again.
As you can see, this time, our content is givin sequential orders to someone. But the last three lines are tabbed because they are transactional, needs to be done at one time. So I want to unify these three commits into one. Let's do so.
If you apply git log --oneline it should be as below;
D:\repo6>git log --oneline
855b968 (HEAD -> master) fifth commit
d3be3fb fourth commit
7403a76 third commit
c0707fa second commit
59f5769 first commit
So let's squash the last three commit (those are seen on the top of commit stack, the top three!), into one.
Now we have to be careful, we are going to use a new command;
git rebase -i <commit #>
We need to squash the last 3, but the rebase commit will be the one before them, it's the one that we would like to left behind. So;
Apply: git rebase -i c0707fa
This will take you to the rebase screen within the default system text editor. Take a look at to the top 3 commands, yes, they are commands this time. You should also read the whole thing for once to understand what we do there;
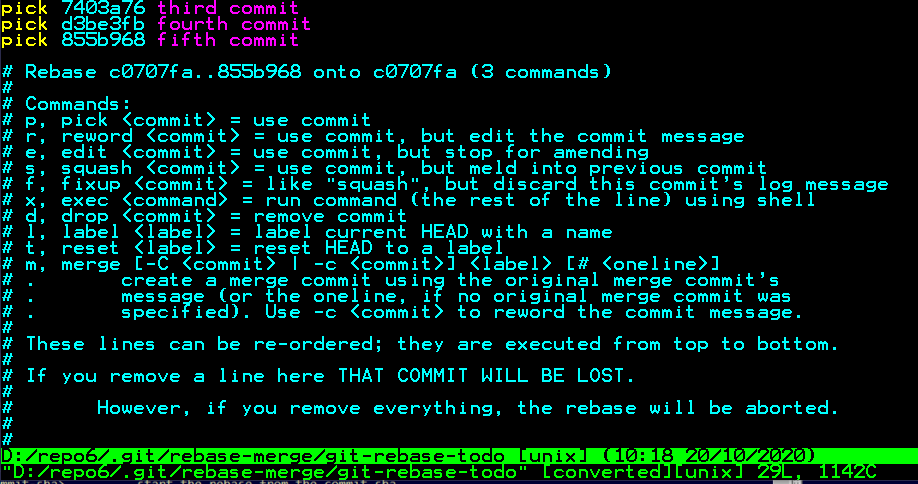
Let's focus on those 3 top lines;
pick 7403a76
pick d3be3fb
pick 855b968
We want to pick the third commit, and mix/merge the fourth and fifth commits. The hash of third commit is : 7403a76, so to mix the others, we are going to use squash instead of pick, like below;
pick 7403a76
squash d3be3fb
squash 855b968
When you apply, it should be seen like below, and then save and quit it;
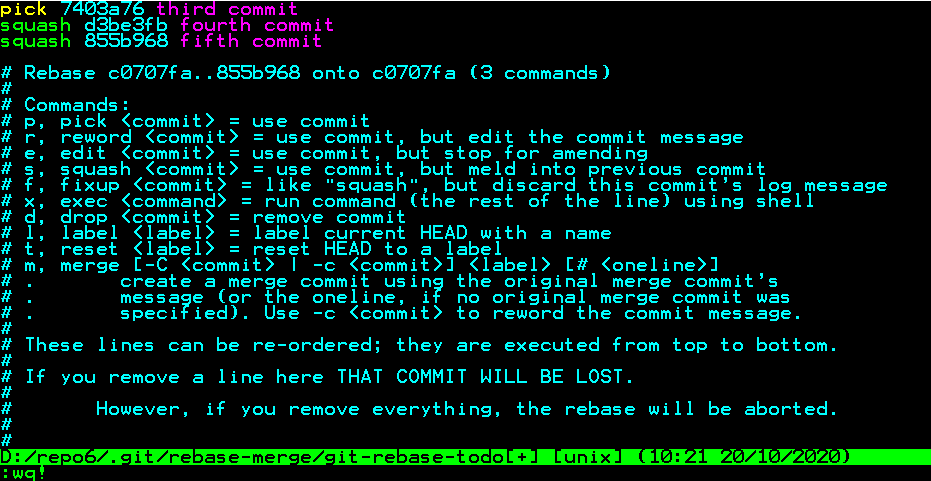
Then a second screen comes, this one is our commit message, well, it's self explanatory, so I'll just save and quit;
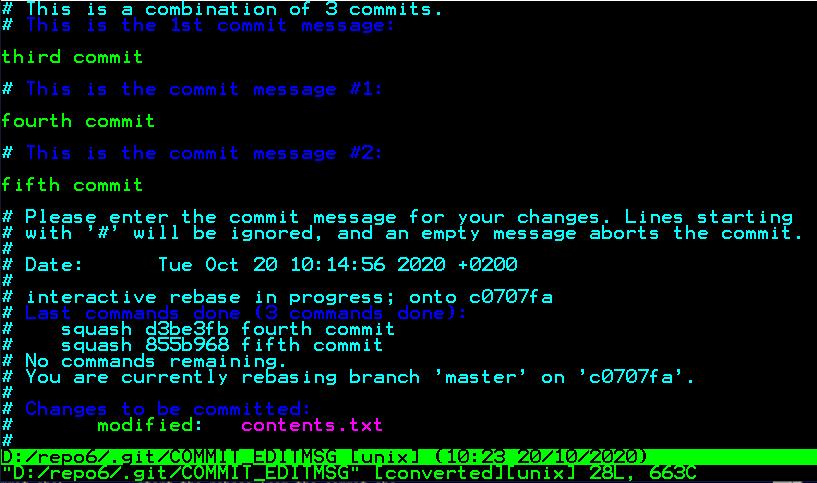
If everything goes well (should be, if not, try again), then the console will look like this;
D:\repo6>git log --oneline
855b968 (HEAD -> master) fifth commit
d3be3fb fourth commit
7403a76 third commit
c0707fa second commit
59f5769 first commit D:\repo6>git rebase -i c0707fa
[detached HEAD 044ec11] third commit
Date: Tue Oct 20 10:14:56 2020 +0200
1 file changed, 4 insertions(+), 1 deletion(-)
Successfully rebased and updated refs/heads/master.
Let's git-log and see what has been committed;
D:\repo6>git log --oneline
044ec11 (HEAD -> master) third commit
c0707fa second commit
59f5769 first commit
Hey, it seems that our commits are lost!, But no, we have unified it in the third commit, you can check it with git show HEAD command, which shows the last commit;
D:\repo6>git show HEAD
commit 044ec11045aa4acfd5acd362b523636334339138 (HEAD -> master)
Author: bzdgn <levent.divilioglu@divilioglu.com>
Date: Tue Oct 20 10:14:56 2020 +0200
third commit
fourth commit
fifth commit
diff --git a/contents.txt b/contents.txt
index a3672e6..d7e3835 100644
--- a/contents.txt
+++ b/contents.txt
@@ -1,2 +1,5 @@
Go to the station Eindhoven
-Find the yellow machine to load your OV chipkaart
\ No newline at end of file
+Find the yellow machine to load your OV chipkaart
+ Put your kaart in the machine
+ Load money on the machine
+ Use your bank card to and enter your pin to finish
\ No newline at end of file
Congratulations, you've just squashed your last 3 commits which makes life easier!
Assuming you are working on a branch, and you are messy. But one of the commits need to be injected on master, from a working messy branch. This can be done with "cherry pick" functionality of git which, in my opinion, saves hours and lives very oftenly. Learn "cherry picking" it's your friend and guardian angel!
Here is our use case, we have a master branch, and a feature branch
Master Branch: A (HEAD)
Feature Branch: B -> C -> D (HEAD)
A, B, C and D are the commits. What I want to do is, just only take the commit C and apply it, put it on the top of the stack of the master branch. So at the end, this is what I want on master branch;
Master Branch: A -> C(HEAD)
Let's learn it by making practice again;
-- WORK-IN-PROGRESS-