{kind=link}
Our SQL compiler implementation consists of three files:
This is the main file that handles command line arguments and initializes the lexer and parser.
This file is our lexer implementation. It is responsible for translating the characters and words into tokens (aka lexemes) where each token has a specific token type. A few examples of a token type are:
- Identifier
- Keyword
- Left Parenthesis
It reads character by character and tries to understand what kind of token each word or character is. Then it feeds thos tokens to the parser.
This file is our parser implementation. It receives the tokens from the lexer and tries to figure out if the comply to the SQL grammar rules. It reads the first token to understand the kind of statement and then reads and the rest of the tokens and checks the different grammar rules. If a statement or query is complies to the grammar rules the parser is also responsible for calling the according miniDB function.
- The compiler also supports comments (starting with '--').
- It assumes that every keyword is written in capital.
- It assumes that every query ends with a semicolon.
- We have included a setUp() function if you want to avoid writing CREATE and INSERT queries and just test a few SELECT queris. To do that just uncomment the second line inside the query() function in parse.py.
To use the compiler just type a few SQL commands in a .txt or .sql file and run the following command:
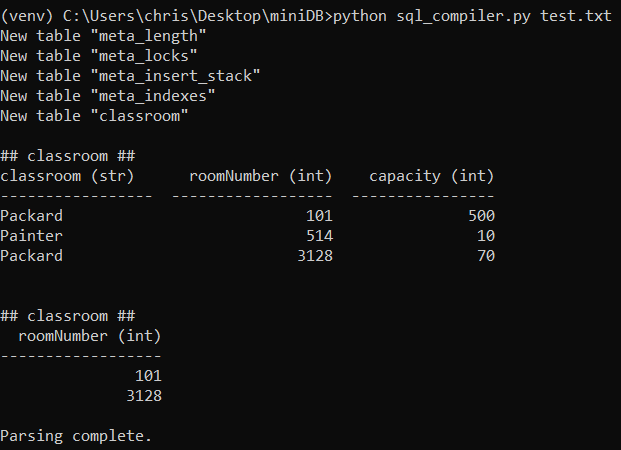
python sql_compiler.py test.txt
Let's say we have a file called test.txt with the following SQL queries:
CREATE DATABASE test;
CREATE TABLE classroom(classroom TEXT, roomNumber INT, capacity INT);
INSERT INTO classroom VALUES('Packard', 101, 500);
INSERT INTO classroom VALUES('Painter', 514, 10);
INSERT INTO classroom VALUES('Packard', 3128, 70);
SELECT * FROM classroom;
SELECT roomNumber FROM classroom WHERE capacity>60;To run the compiler we would do:
The miniDB project is a minimal and easy to expand and develop for RMDBS tool, written excusivelly in Python 3. MiniDB's main goal is to provide the user with as much functionality as posssible while being easy to understand and even easier to expand. Thus, miniDB's primary market are students and researchers that want to work with a tool that they can understand through and through, while being able to implement additional features as quickly as possible.
Python 3.7 or newer is needed. To download and build the project run:
git clone https://github.com/DataStories-UniPi/miniDB.git
cd miniDB
pip install -r requirements.txtThe last command will install the packages found in requirements.txt. MiniDB is based on the following dependencies:
tabulate(for text formatting)graphviz(for graph visualizations; optional)matplotlib(for plotting; optional)
Alternatively, the above dependencies can be installed with the following command:
pip install tabulate graphviz matplotlibLinux users can optionally install the Graphviz package to visualize graphs:
sudo apt-get install graphvizInstallation instructions for non-Linux users can be found here.
The file documentation.pdf contains a detailed description of the miniDB library (in Greek).
Loading the smallRelations database
To create a database containing the smallRelations tables and get an interactive shell, run
python -i smallRelationsInsertFile.pyYou can the access the database through the db object that will be available. For example, you can show the contents of the student table by running the following command:
>> db.show_table('student')The database wil be save with the name smdb. You can load the database in a separate Python shell by running the following commands:
>> from database import Database
>> db = Database("smdb", load=True)George S. Theodoropoulos, Yannis Kontoulis, Yannis Theodoridis; Data Science Lab., University of Piraeus.