It's simple question generator based on visual content written in Tensorflow. The model is quite similar to GRNN in Generating Natural Questions About an Image but I use LSTM instead of GRU. It's quite similar to Google's new AI assistant Allo which can ask question based on image content. Since Mostafazadeh et al. does not released VQG dataset yet, we will use VQA dataset temporarily.
- Tensorflow, follow the official installation
- python 2.7
- OpenCV
- VQA dataset, go to the dataset website
We will use VQA dataset which contains over 760K questions. We simply follow the steps in original repo to download the data and do some preprocessing. After running their code you
should acquire three files: data_prepro.h5, data_prepro.json and data_img.h5, put them in the root directory.
Train the VQG model:
python main.py --model_path=[where_to_save]
Demo VQG with single image: (you need to download pre-trained VGG19 here)
python main.py --is_train=False --test_image_path=[path_to_image] --test_model_path=[path_to_model]

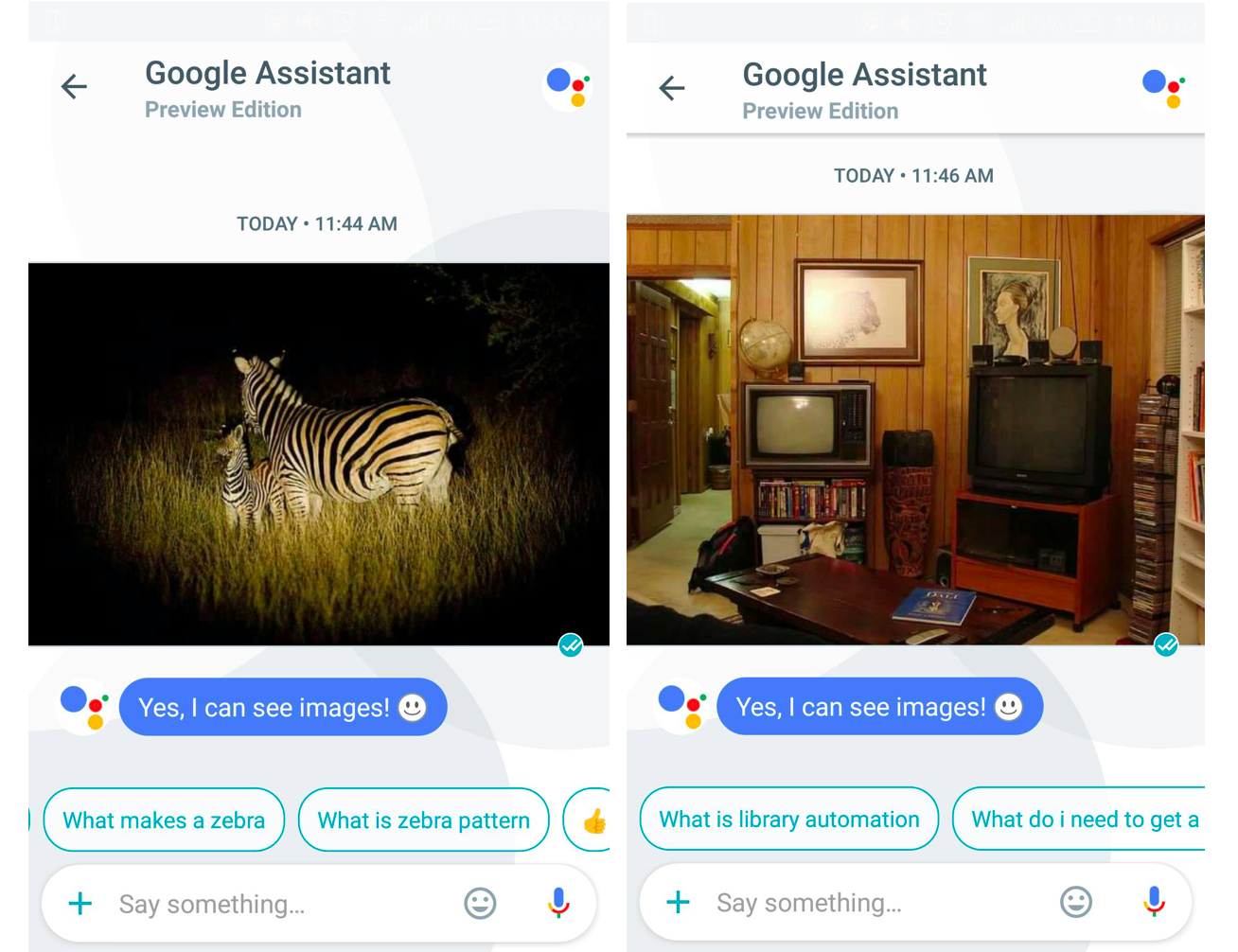
Model: How many zebras are in the picture ?

Model: Where is the chair ?
Problem: Since we use VQA dataset which is designed for challenge so its question must be relevant to image content. No wonder the model train from VQA can not ask natural questions like human. We will adapt VQG dataset once it release to ask more meaningful question.
We also let Allo reply to these images. Here's the result.
Apply VQG dataset instead of VQA to ask more useful question.