-
Notifications
You must be signed in to change notification settings - Fork 3.8k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
28594: ui: add disk ops per second graph to hardware dashboard r=vilterp a=vilterp The middle two graphs are new: 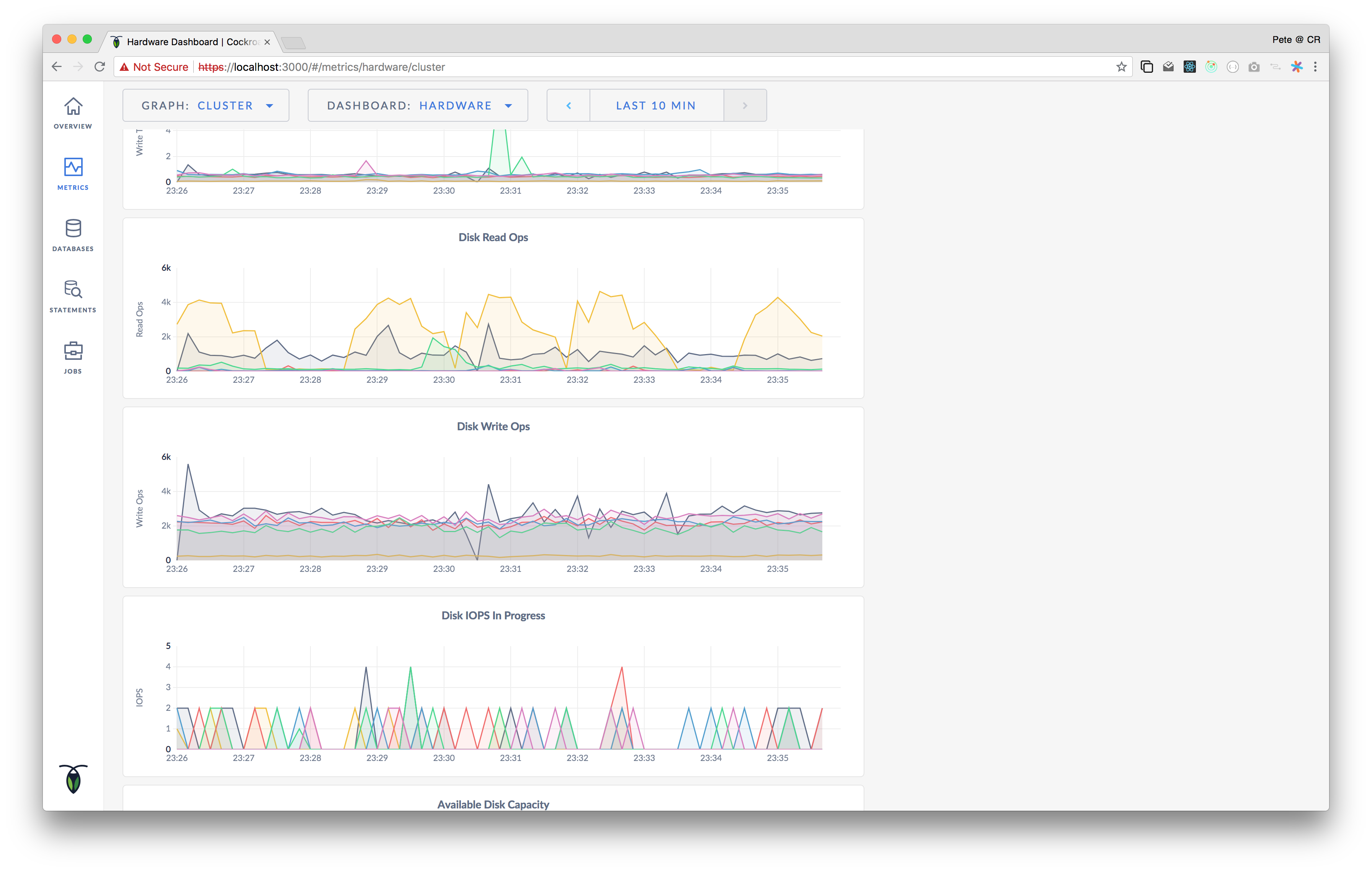 Fixes #28552 28683: storage: handle preemptive snapshots that span merges r=bdarnell,tschottdorf a=benesch Preemptive snapshots can indirectly "widen" an existing replica. Consider a replica that is removed from a range immediately before a merge, then re-added to the range immediately after the merge. If the replica is not GC'd before it is re-added to the range, the existing replica will receive a preemptive snapshot with a larger end key. This commit teaches the snapshot reception code to handle this case properly. If widening the existing replica would cause overlap other replicas, the preemptive snapshot is rejected. Otherwise, a placeholder for the new keyspace is installed and the snapshot is applied. Release note: None Fix #28369. Co-authored-by: Pete Vilter <vilterp@cockroachlabs.com> Co-authored-by: Nikhil Benesch <nikhil.benesch@gmail.com>
{kind=link}
- Loading branch information
Showing
8 changed files
with
355 additions
and
114 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.