roadmap: Support logical replication / CDC #2656
Comments
|
@maximecaron CockroachDB uses MVCC for transactions. Shadow paging, as defined by wikipedia, is a different technique. Perhaps you have a different definition of shadow paging in mind. CockroachDB has builtin replication. There are no current plans to support a logical stream of database modifications. Perhaps if you describe what you'd like to do with this stream (the high level goal) we can figure out what the equivalent in CockroachDB would be. |
|
So the goal is to have another slave system (Cache Server or ElasticSearch) consume a stream of changes. For a CacheServer this would let the cache server consume stream of key that need invalidation. There is several case where this could be useful It seem to be possible to implement something like this with a trigger mechanism but I would prefer something more like a logical replication stream. |
|
Thank you for the explanation of use cases. This isn't something we Something to keep in mind. Would you care to create an issue so we can On Thu, Sep 24, 2015 at 5:09 PM, Maxime Caron notifications@github.com
|
|
@maximecaron Thanks for the pretty diagrams. I can see the utility in exporting a logical stream to ElasticSearch for indexing. Is the purpose of the caching to offload read-only traffic from the database? If yes, the system might be simpler by repurposing the cache nodes for cockroach nodes. This would expand the cockroach capacity and remove any delays between updates to the database and the read-only caches. Such an approach isn't always possible or there might be another purpose to the caching. But given CockroachDB's native scalability it might not be necessary to use caching to workaround database scalability bottlenecks. |
|
I am mostly interested in having asynchronous index built in a consistent way. When I have a better idea of how this should be implemented I will create issue for the feature request. In the meantime feel free to close this issue. |
|
I think we're going to be supporting asynchronous indexes internally. This On Mon, Sep 28, 2015 at 2:10 PM, Maxime Caron notifications@github.com
|
|
I would prefer to connect cockroach to some external indexer. |
|
@maximecaron Do you need to lookup the data in Cockroach, or are you looking to use Cockroach purely as a write queue? As you've noticed, there are some challenges to having a queue in a distributed system. If you have multiple writers writing to a queue, you either have to have a synchronization point on the ids assigned to the queue entries (which will limit scalability) or you have to give up a nice monotonically incrementing key. If you can get away with a "mostly sorted" queue, the The challenge with this structure is that when you read from the "end" of the queue there is a small window of time where new values could be inserted before the "end". And you still have the problem with contiguous keys in the queue limiting the write throughput. The obvious fix to this problem is to make multiple queues. Not sure if that works for your system. |
|
Actually having one queue per raft cell would work as long as a consumer reading from several queue is able to merge-sort the transaction back into one sequence. Ex: If Keys A, B and C are in distinct Raft cell. A consumer reading from the 3 raft cells should be able to order the log entry for A B and C like below and create a index that contain entry for A,B and C that is consistent (have all of T1 changes but none of T2 changes) or (have all of T1 changes and all of T2 changes) A updated by T1 I think all that is needed for this is a way to write the transaction ID inside the queue. |
|
@maximecaron I might have lost the thread of this discussion. Are you proposing a general purpose mechanism for Cockroach to export a logical stream of changes? Having a queue per range (each range is a raft consensus group) would likely be unworkable. Ranges are ~64MB in size. There is an expectation that there will be hundreds of thousands or millions of ranges in a cluster. That is a lot of queues to merge-sort back into a single sequence. |
|
Yes, this is exactly what I was proposing. Is that looking more realistic to you? |
|
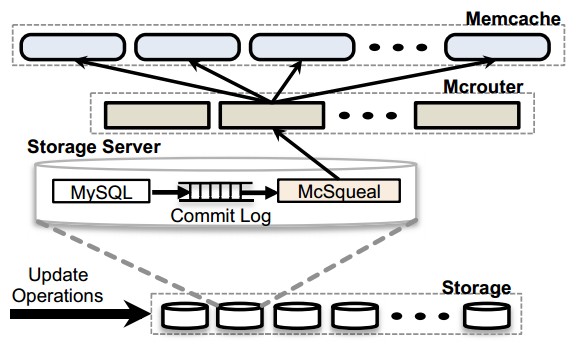
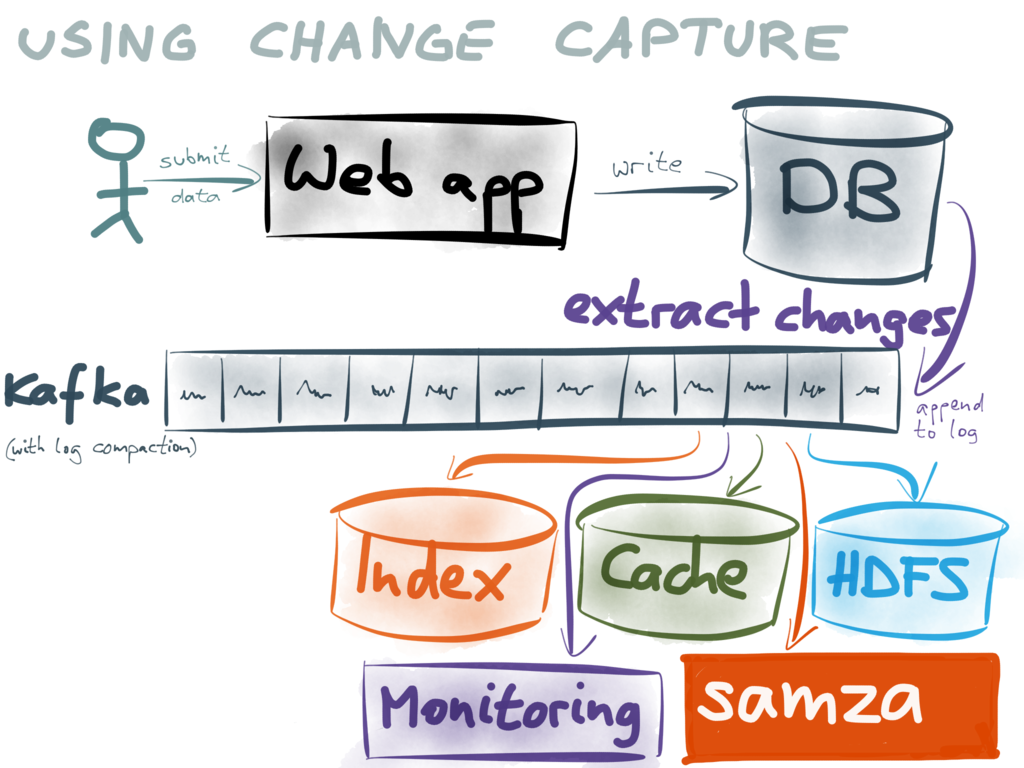
I'm not clear on how the queue per node approach would work. Note that ranges (64MB contiguous chunks of the KV space) have replicas and those replicas are spread across nodes. But take any two nodes and they will have different sets of ranges. That seems to prohibit a per node queue approach, but perhaps I just haven't thought about it enough. @spencerkimball, @bdarnell and @tschottdorf should all have better input on possibilities for supporting logical replication stream. One thought I had was that perhaps you don't need a mechanism that operates at the KV transaction layer. If you're going through the SQL layer we could possibly mark a table as supporting an update stream. Not sure if this simplifies the problem or even if it would be workable in your desired use case. Do you have a specific target application use case in mind? If yes, do you mind describing it? Your diagrams above were useful, but they don't mention doing reads out of the DB other than for sending along to indexing and other downstream services. I'm guessing that isn't the full story |
|
A queue per node isn't feasible, but when/if we start using copysets, a queue per copyset would be more manageable.
Cockroach specifically avoids gathering information about all the keys touched in a transaction in one place, so I don't think there's any way to provide this level of consistency without creating a separate log at the application level. In the long run, Cockroach will support more kinds of indexing including full-text and geospatial. When that functionality exists, would there still be a need to provide a replication stream to external indexers? It may be easier to push forward on alternate indexing schemes than to support a general-purpose external mutation log (at least when consistency is needed. A relaxed-consistency log would be much easier to support). |
|
This is my main usecase. We have a graph of friend that follow each other. If we do a full refresh of the materialized view inside a transaction this would work but refresh wont be real time. I was trying to apply the update to the materialized view in an incremental way and in the background. My current solution is to have a queue of changes per user at the application layer and this is working well so far. |
|
Any plan to add trigger at the KV or SQL layer? |
|
There are no near term plans to add support for triggers. Are you thinking you could use triggers to implement logical replication? Can you describe in more detail how you would like triggers to work? |
|
I'm also very interested in being able to capture committed changes to rows. Basically, the scenario is this: a "monitor" (see below) connects to the database, performs a consistent snapshot at some known point in time, and when the snapshot is complete it then starts capturing the committed changes starting with the same point in time the snapshot was performed. The monitor continues to monitor the stream of changes. Using asynchronous change data capture (CDC) allows multiple downstream apps and services to consume the continuous and never-ending stream(s) of changes to databases. Each stream must be consistent and totally ordered, and could be used for replication, updating derived data sources (perhaps optimized for different domains and scenarios), caches, metrics, analytics, multi-system integration, etc. Every database exposes their changes differently -- and some not at all. So it's usually very complicated to just read a consistent stream of changes from a DBMS server/cluster. And, doing this while never losing events is even more difficult. The Debezium project is a relatively new open source project whose goal is to capture these changes into durable, totally-ordered, persistent streams so that apps and services can easily consume them (or replay them from the beginning) without having to know how or where the streams originate. We have a connector for MySQL, are working on a MongoDB connector, and plan connectors for PostgreSQL, Oracle, SQL Server, and many others. Would love to be able to create a connector for CockroachDB. Cockroach has the ability to obtain consistent snapshots, but appears to be missing the ability to expose a log/stream of committed changes. |
|
While it would be very convenient and hopefully a long term goal, it certainly isn't necessary to start out by providing a simple way for clients to consume a single change log of events for a distributed database. It'd be a start, for example, to provide access to multiple logs (e.g., perhaps one on each node in the cluster) -- clients could at least work with that, though they may have to resolve the different logs into a single serializable stream, if that's what they require. Whether there are one logical log that contains all events, or multiple logs that together contain all of the information about the changes, the system would still need to retain logs for a period of time or until the log reaches a maximum size. At that point, older entries can be dropped. A client could then connect and request that it receive the log starting at some position. As long as each event includes its position, the client can consume the events and keep track of the position of the last event it has completely processed. If the client disconnects, stops consuming for any reason (e.g., garbage collection), is taken down for maintenance, then when it reconnects it can start reading the log where it last left off. Because the logs contain only recent history, a change data capture system would likely need to start out with a database by performing a consistent snapshot, and when complete start reading the log(s) starting with the first event after the snapshot time. Thus there needs to be a way to correlate the log position with the time travel snapshot time. (Contrast this with a listener-based approach, where the database is expected to send a notification to one or more remote listeners. What happens in this case when a remote listener is not available? The database might enqueue the event, but then for how long? The database could drop the event, although that defeats the purpose of this feature. The database could use it as back pressure, although that's a horrible thought. Maintaining total order requires the remote listener return an acknowledgement, but what happens if that is not received? Should the database resend the event? How many times? You can see that this approach quickly becomes intractable.) |
|
@rhauch Thanks for your thoughts. A complexity with providing some sort of feed or log of changes in a CockroachDB is that not only is there not a single log, there are an unbounded number of logs. Specifically, transactions are allowed to span arbitrary "ranges" where each range is ~64MB in size. Each range has a log of KV operations performed upon it and as the ranges grow they split. Ignoring the complication that the range logs are GC'd fairly aggressively right now, how would a client keep track of the range logs it needs to poll given the dynamic splitting of ranges and their automatic movement around a cluster? Providing some sort of logical replication, change feed or change log mechanism seems desirable, but I don't have a solid idea for how to achieve it yet. Putting aside the implementation problem, at what level would you want to receive events? Notification of any change to a particular table? Notification of a change to any table? Would you want the lower-level KV data or the SQL rows that were modified? |
This is a bit easier to address. If a logical change stream mechanism is targeted for clients, then it's likely to be more easily used if the mechanism expose the events at the SQL row level, since that's also the level at which they are logically/conceptually operating. (There may be value in composing events at the lower-level KV changes, such as providing continual updates for backups, etc. Given the current replication capability, maybe this isn't too big a deal.) And, unless the implementation needs to, it shouldn't filter for the client. Instead, give the client a firehose and expect the client to find what is interesting in the stream. (DBMS log consumers typically require specific privileges to read the log.) It's also reasonable to expect a small number of clients, since each client will almost certainly induces a load on the system.
Might it make sense for each node to have it's own log, perhaps including the changes for transactions spanning multiple ranges? The log would include whatever changes for each transaction processed by that node. IIUC, as ranges are GC'd and moved around, the log might simply stop including the changes for any ranges that are no longer on that node. If that makes sense, then a client (or some imaginary Cockroach service) needs to be able to monitor all the logs and coalesce them into a cohesive logical log. That might be less complicated and more stable than tracking the range dynamics. An alternative approach would be to have each node have a thread (or separate process) that scans that node's (append-only) log and sends the events to an external distributed log, such as Kafka. All events related to a single database might go to a single Kafka topic, or all events for the entire map might go to a single topic. I'd have to learn more about how CockroachDB captures the work associated with its transactions to figure out if there is sufficient info in the events for consumers to reconstruct the whole transactions (and know they have everything associated with a transaction, despite various failures). The nice thing about this approach is that each node is responsible for sending its log to the external distributed log (i.e., Cockroach makes the information available), but aggregation of that distributed log could be left for future work or simply left to the consumers. I know this is a lot of hand waiving, but perhaps it helps. |
|
Each node does maintain a log of KV operations, but this log is also GC'd fairly aggressively. We also need to be aware of the complexity that replication causes. Replication is performed at the range level, not the node level, so a naive stream of KV operations from each node would contain 3 copies of each operation. Translating the KV operations back to SQL operations is possible, though a bit of a headache. I feel a bit pessimistic thinking about this, but it is worth brainstorming about. Here's a more concrete proposal: when a transaction is perform KV mutations it has the node performing the mutation send a Kafka topic tagged by the transaction ID. When the transaction commits or aborts, we send that event to the Kafka topic. A consumer of the topic would see a series of operations for the transaction (interleaved with operations for other transactions) and then a commit or abort. If using a single Kafka topic is a bottleneck, we could shard the topics based on the transaction ID. It's probably also possible to do this only for committed transactions by piggy-backing on intent resolution. Either way, I'm not sure this would guarantee that the Kafka log would contain transactions in commit order. That is, transaction A could commit before transaction B by end up in the Kafka log after transaction B. That seems undesirable. |
|
@petermattis, I understand other features have priority, so thanks for spending the time to think about and discuss this. Are the KV changes applied by each node committed, or might they also include some intents? If committed, then capturing the KV changes is interesting. First, having 3 copies of each operation is actually not a bad thing, since it always can be filtered out later. Secondly, with this approach the KV operations map very nicely to Kafka messages (the message key is K, the message value includes K,V, and transaction metadata) written to a single topic that can be partitioned by K. (In Kafka, every topic partition is actually a separate totally ordered log, and you can have large numbers of partitions in each topic. But it would also be possible to shard across multiple topics, too.) Also, the topic partitions can be set up with log compaction, whereby Kafka can remove old entries from the log when newer entries exist with the same key. (This is another reason why having 3 copies with the same K but different values is okay, since log compaction can remove all but the last one.) Even if the topics use log retention (keep messages for a max duration), just take the extra copies into account when configuring retention. Order would be maintained on the topics since the messages are partitioned by K. Translation from KV into SQL operations could be done by a downstream service, but IIUC may even be a stateless conversion which means it could be partitioned across n service instances. However, if the translation from KV operations into SQL operations is difficult or might change, then I could understand avoiding this approach. I guess it comes down to weighing that difficulty vs the apparent operational simplicity of this approach. Recording the transaction operations in a Kafka topic should be possible as well. Using the transaction ID as a key would work, though that means that multiple messages would have the same key, and so Kafka logs must use retention rather than log compaction. This is okay, but it now requires that a downstream service/consumer has to be running to translate these into some other form (e.g., using SQL primary keys as the message key). Also, the topic could be partitioned by transaction ID, meaning that all events for a single transaction go to the same partition. IIUC, transaction ID is primarily based upon time (with a random priority), special partitioning logic would be required to ensure continual distribution across all partitions over time. Doable, but something to consider. Kafka will not maintain order across partitions, so that would also have to be handled by the downstream service and would require a fair amount of state. |
|
The KV changes applied by each node are "intents". Those "intents" do not become visible until the transaction is committed, which can occur on a different node. Yes, the replicas of each operation can be filtered, but sending 3 times as much data will be a performance hit. Transaction IDs are random (v4 UUIDs). |
|
We wrote our own program that interfaces with Postgres using logical replication to process changes (to feed into Elasticsearch). We use the included test_decoding plugin to encode rows sent to us, and we have configured the tables to send us complete rows, not just the changed columns. It would be great to have a simple interface to CDB to do something similar. The kafka protocol strikes me as very complicated, and it would be a challenge to implement something on top of that. |
|
@ligustah et al - completely agree, using KSQL Transactions to write to multiple partitions for the CRDB CDC is a very tightly coupled solution. Who wants to stand up 3+ Kafka brokers and 5 Zookeeper nodes if you're not already invested in Kafka. The Pg 10 logical replication protocol and subscription mgmt support SQL would be an ideal implementation from my perspective, and have a nice symmetry with the already supported Pg driver protocol and SQL dialect. Someone could then use that to drive a Kafka Connect Source. |
|
thanks for the feedback! we'll look into the different alternatives everyone has proposed here. i'll ping this issue again as we synthesize things / if we need more specific feedback. |
|
Supporting PostgreSQL's logical decoding would also allow the use of debezium for CDC: https://github.com/debezium/debezium. I'm not opposed to Kafka, though - it's open source, and Kafka Connect supports many tools. |
|
@dianasaur323 will cdc only be part of the enterprise edition? |
|
@stellanhaglund there will likely be a non-enterprise version of CDC but it won't have the same performance characteristics as the enterprise version. We haven't figured out the precise details of what this will look like yet. Stay tuned. |
|
@kannanlakshmi Oh ok, that's kind of sad. I've been waiting for that feature hoping I could use it as a replacement for other realtime setups and possibly get better performance. |
|
@stellanhaglund (and others on this thread), please feel free to email me at lakshmi@cockroachlabs.com if you're interested in testing out our early prototype that will be released July 2nd. While CDC is an enterprise feature, we will have a core version and we also have start up pricing for smaller companies who can't afford an enterprise license. |
|
The v2.1.0-alpha.20180702 binary released today contains our first CDC prototype. You can find the docs for CDC and the latest binary under testing releases with today's date (Jul 2) below. As always, please let us know of any issues or questions here on Github, or Forum or emailing me directly lakshmi@cockroachlabs.com Docs: https://www.cockroachlabs.com/docs/v2.1/change-data-capture.html |
|
Hi @kannanlakshmi, We're trialling the beta version of CDC (thanks!), unfortunately we have not had great experience with using Kafka in production.. Do you know when there will be other message queuing systems supported? Which one will you be targeting next? (RabbitMQ is our preferred one) Thanks, |
|
Hi @andrew-bickerton, we will be adding other message queuing systems in the next release, though we are yet to have made a final decision on which ones. Thanks for letting us know your preference for RabbitMQ - it is noted and will influence our roadmap. Would you be willing to share your experience with the beta CDC with us offline? This feedback is very valuable as we go into the next release. I can email to set up a quick call - thanks! |
|
@kannanlakshmi Hi there! I'd like to add a vote for NATS (https://nats.io). It's distributed, lightweight and hosted by the CNCF (https://www.cncf.io/blog/2018/03/15/cncf-to-host-nats/). |
|
With the upcoming release of core and fully-supported enterprise changefeeds in CockroachDB 19.1, I think we can close this out. See #33279 for specific features. |
|
Also NATS streaming as a connector would be great. It's a pity grpc was not used as the primary way to receive the stream from CR, because then everyone would be free to use whatever message queue tack they wanted. Kafka or NATs or cloud systems from AWS or Google , etc |
|
@gedw99 thanks for the feedback. We welcome external contributions - if you're interested in adding something like that, we'll be happy to support you along the way. |
|
@gedw99 There are a couple of options for connecting CockroachDB CDC to alternative sinks that wouldn't require changes to CockroachDB itself:
|
My understanding is that CockroachDB is currently using Shadow paging for transaction.
Postgresql have a feature called Logical Decoding http://www.postgresql.org/docs/9.4/static/logicaldecoding.html .
But this feature is using the write-ahead log. Would it be possible for CockroachDB to also support logical replication without using a write-ahead log?
The text was updated successfully, but these errors were encountered: