{kind=link}
{kind=link}
A GPU accelerated C++/CUDA C implementation of the segmented sieve of Eratosthenes
Update April 2021: The code compiles again with the latest version of CUDA on my computer. This required getting rid of some legacy GPU capability. If you have a compute capability 3.2 to 5.0 gpu, you can make the required changes in the makefile, but I have removed those architectures from the main branch. It is about six years of backwards compatibility. If this means your hardware won't work, your beef is with tech companies' embrace of planned obsolescence, friend.
CUDASieve is a high performance segmented sieve of Eratosthenes for counting and generating prime numbers on Nvidia GPUs. This work contains some optimizations found in Ben Buhrow's CUDA Sieve of Eratosthenes as well as an attempt at implementing Tomás Oliveira e Silva's Bucket algorithm on the GPU. While this code is in no way as elegant as that of Kim Walisch's primesieve, the use of GPU acceleration allows a significant speedup. For those interested in building CUDASieve from source, the makefile will require changes to CUDA_DIR. A smaller number of device architectures can be specified depending on your use case, though this has no effect on performance. A couple hints are provided at the top of the makefile. Let me know if you have any hangups.
The available binaries have been compiled for x86-64 linux and Nvidia GPUs with compute capability 3.0 or greater (everything in the past four years).
libcudasieve.a - the CUDASieve library (see below)
cudasieve - the CUDASieve command line interface (type ./cudasieve --help for commands)
cstest - a command line utility for testing the correctness of CUDASieve
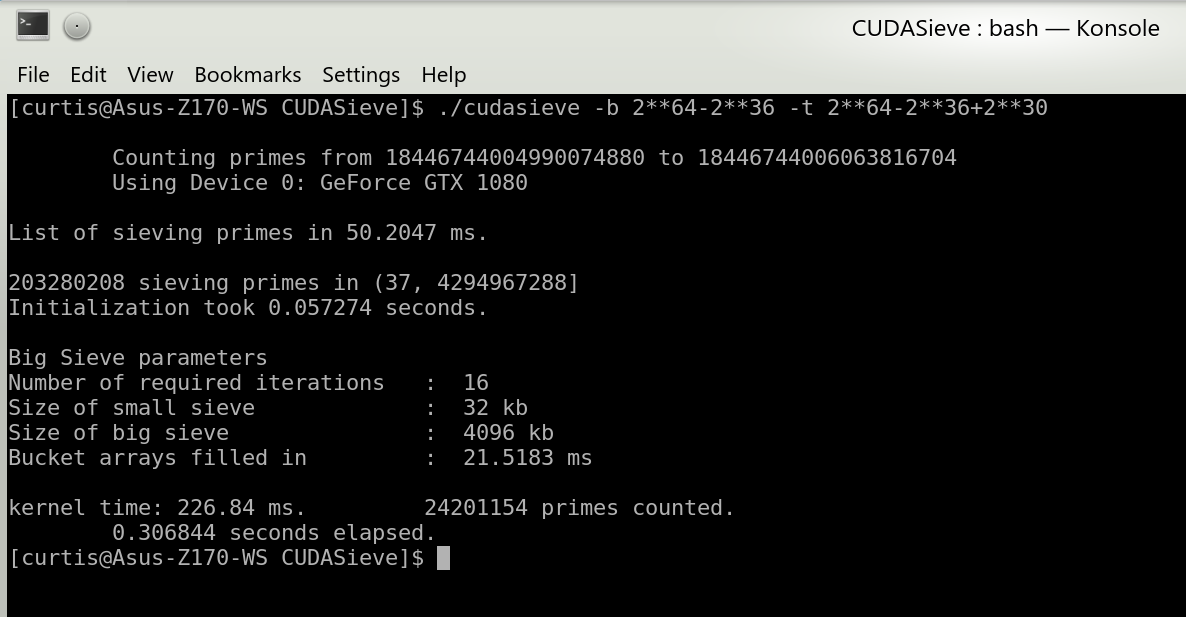
With GTX 1080:
| Range | Time to generate list of sieving primes | Time to sieve this range | Total running time | Count |
| 0 to 106 | 0.062 ms | 0.071 ms | 0.164 s | 78 498 |
| 0 to 107 | 0.063 ms | 0.198 ms | 0.127 s | 664 579 |
| 0 to 108 | 0.062 ms | 0.790 ms | 0.156 s | 5 761 455 |
| 0 to 109 | 0.063 ms | 5.65 ms | 0.161 s | 50 847 534 |
| 0 to 1010 | 0.247 ms | 63.1 ms | 0.236 s | 455 052 511 |
| 0 to 1012 | 0.258 ms | 12.3 s | 12.5 s | 37 607 912 018 |
| 0 to 250 | 0.768 ms | * | 28 653 s | 33 483 379 603 407 |
| 240 to 240 + 230 | 0.247 ms | 32.7 ms | 0.169 s | 38 726 266 |
| 250 to 250 + 230 | 0.806 ms | 34.5 ms | 0.206 s | 30 984 665 |
| 260 to 260 + 230 | 18.9 ms | 126 ms | 0.314 s | 25 818 737 |
| 264 - 236 to 264 - 236 + 230 | 49.0 ms | 225 ms | 0.446 s | 24 201 154 |
*Separate sieves for <240 and >=240
Hardware Scaling for sieving 0 to 109:
| GPU | Time to generate list of sieving primes | Time to sieve this range | Total running time |
| GTX 750 | 0.100 ms | 67.5 ms | 0.128 s |
| GTX 950 | 0.106 ms | 36.4 ms | 0.105 s |
| GTX 1070 | 0.075 ms | 8.81 ms | 0.140 s |
| GTX 1080 | 0.069 ms | 6.03 ms | 0.121 s |
Additionally, this code contains a way of generating a list of sieving primes, in order, on the device that is much faster than the bottleneck of ordering them on the host. Generating the list of 189 961 800 primes from 38 to 4e9 takes just 50 ms. This is about 15.2 GB of primes/second (about the max speed of PCIe 3.0 x16)! Primes are also prepared to be printed in the same way. For example, the kernel time for preparing an array of all the (25 818 737) primes from 260 to 260+230 and getting this array to the host is 157 ms with the GTX 1080.
This implementation of Oliveira's bucket method requires a fixed 10 bytes of DRAM per prime, which equates to just over 2 GB
for sieving up to 264. The fact that
large primes are handled in global memory, rather than on-chip, means that increasing the number of blocks working on the
task of sieving these large primes does not increase the amount of memory used since the data set is not duplicated.
CUDASieve has been checked against primesieve in counts and with Rabin-Miller primality tests of the 64k primes on each end of the output using random, exponentially-distrubuted ranges of random length. At the moment, it has passed about 400 000 consecutive tests without error. When run concurrently with some other application running on the same device (e.g. folding@home), there appears to be about a 1 in 20000 chance that the count will be off by one. These errors, however, are not repeatable when the program is running alone, even over 2 million trials. One million of those were with a device driving a display, so that does not impose a similar liability for error. These tests can be performed with the 'cstest' binary.

If the CUDASieve/cudasieve.hpp header is #included, one can make use of several public member functions of the CudaSieve class for e.g. creating host or device arrays of primes by linking the libcudasieve.a binary (with nvcc). For example:
/* main.cpp */
#include <iostream>
#include <stdint.h>
#include <math.h> // pow()
#include <cuda_runtime.h> // cudaFreeHost()
#include "CUDASieve/cudasieve.hpp" // CudaSieve::getHostPrimes()
int main()
{
uint64_t bottom = pow(2,63);
uint64_t top = pow(2,63)+pow(2,30);
size_t len;
uint64_t * primes = CudaSieve::getHostPrimes(bottom, top, len);
for(uint32_t i = 0; i < len; i++)
std::cout << primes[i] << std::endl;
cudaFreeHost(primes); // must be freed with this call b/c page-locked memory is used.
return 0;
}placed in the CUDASieve directory compiles with the command
nvcc -I include -lcudasieve -std=c++11 -arch=compute_30 main.cppand prints out the primes in the range 263 to 263+230.
/* CudaSieve static member functions */
/* Returns count from 0 to top */
uint64_t countPrimes(uint64_t top);
/* Returns count from bottom to top, caveats mentioned below apply */
uint64_t countPrimes(uint64_t bottom, uint64_t top);
/* Returns pointer to a page-locked host array of the primes in [bottom, top] of length count.
Memory must be freed with cudaFreeHost() */
uint64_t * getHostPrimes(uint64_t bottom, uint64_t top, size_t & count);
/* Returns a std::vector of the primes in the interval [bottom, top] */
std::vector<uint64_t> getHostPrimesVector(uint64_t bottom, uin64_t top, size_t count);
/* Returns pointer to a device array of primes in [bottom, top] of length count */
uint64_t * getDevicePrimes(uint64_t bottom, uint64_t top, size_t & count);
The above functions all have an optional last parameter that allows the user to specify the CUDA-enabled device used for the sieve. If this is not specified, the value defaults to 0. The thrust branch adds the ability to get a thrust::device_vector of primes at the cost of much larger binaries.
For many iterations, it is preferable to avoid some of the overhead associated with memory allocation and creating the list of sieving primes repeatedly. Fortunately, it is possible to do most of this work once by calling the CudaSieve constructor with two or three arguments (as shown below) and then calling the suitable non-static member function.
int main()
{
size_t len;
uint64_t bottom = pow(2,60);
uint64_t top = bottom + pow(2,50);
uint64_t range = pow(2,30);
CudaSieve * sieve = new CudaSieve(bottom, top, range);
for(; bottom <= top; bottom += range){
uint64_t * primes = sieve->getHostPrimesSegment(bottom, len);
/* something productive */
}
delete sieve;
return 0;
}The above code creates a CudaSieve object with an appropriate list of sieving primes for ranges up to top and with memory allocated for copying arrays of primes over range range as long as they are above bottom. However, I have been having some issues with them and depend mostly on the static member functions, which are very reliable. The relevant non-static member functions are:
CudaSieve(uint64_t bottom, uint64_t top, uint64_t range);
uint64_t * getHostPrimesSegment(uint64_t bottom, uint64_t top, size_t & count);
uint64_t * getDevicePrimesSegment(uint64_t bottom, uint64_t top, size_t & count);
// returns a pointer to an array of primes in the range [bottom, bottom+range]
// (the latter as specified when calling the constructor). Invalid bottom will
// return NULL and count = 0;There is a device memory leak of ~150 kb that can become problematic after several thousand iterations when using the functions described above, but it is of no consequence for the CLI. Strangely, it doesn't seem to be a result of cudaMalloc() / cudaFree() asymmetry, nor is it detected with cuda-memcheck... Anyways, if you need to run several thousand or more iterations of one of the above functions, it seems best to call cudaDeviceReset() after every 1000 or so. When called this infrequently, cudaDeviceReset() adds negligible time.
There is an issue with selecting the non-default GPU in the CLI that causes timing to fail and counts to sometimes be off. However, this limitation does not carry over to the API, where selecting the non-default GPU does not cause problems.
Currently working on expanding the range of available functions, specifically the non-static ones. Let me know if you have any requests for features, and I'll see what I can do.