Dask: Stalling Tasks? #5879
Comments
|
I reduced the number of Dask workers from 600 --> 350, and I don't encounter this issue anymore. Maybe this is some networking issue? Bandwidth? I have no clue. |
|
@rileyhun just to confirm the problem is actually Dask, and not the code you're running: when your cluster gets into a stuck state like this, could you use Basically, if Here's a script I have lying around to check on this (not tested, can't promise it works)"Run `python check-deadlock.py <scheduler-address>` to check for deadlocks related to https://github.com/dask/distributed/issues/5481"
import sys
import itertools
from time import time
import distributed
if __name__ == "__main__":
if len(sys.argv) != 2:
raise ValueError("Supply scheduler address as the first CLI argument")
client = distributed.Client(sys.argv[1])
processing = client.processing()
call_stacks = client.call_stack(
keys=list(set(itertools.chain(*processing.values())))
)
readys = client.run(
lambda dask_worker: [key for priority, key in dask_worker.ready]
)
problem_addrs = set()
for addr, keys_processing in processing.items():
if not keys_processing:
continue
ready = readys[addr]
try:
call_stack = call_stacks[addr]
except KeyError:
print(f"{addr} processing {keys_processing} but has no call stack")
problem_addrs.add(addr)
continue
all_tasks_on_worker = set(itertools.chain(call_stack.keys(), ready))
if set(keys_processing) != all_tasks_on_worker:
print(
f"*** {addr} should be have {len(keys_processing)} tasks, but has {len(all_tasks_on_worker)} ***",
f" Scheduler expects: {keys_processing}",
f" Worker executing: {list(call_stack)}",
f" Worker ready: {ready}",
f" Missing: {set(keys_processing) - all_tasks_on_worker}",
f" Extra: {all_tasks_on_worker - set(keys_processing)}",
sep="\n",
)
problem_addrs.add(addr)
batched_send_state = client.run(
lambda dask_worker: (
f"Batched stream buffer length: {len(dask_worker.batched_stream.buffer)}\n"
f"please_stop = {dask_worker.batched_stream.please_stop}\n"
f"waker.is_set() = {dask_worker.batched_stream.waker.is_set()}\n"
f"time remaining = {nd - time() if (nd := dask_worker.batched_stream.next_deadline) else None}\n"
)
)
print("BatchedSend info:")
for addr, bs in batched_send_state.items():
print(("*** PROBLEMATIC: " if addr in problem_addrs else "") + addr)
print(bs)
if problem_addrs:
print(f"Inconsistency detected involving workers {problem_addrs}")
else:
print("No inconsistency detected")One other note about your code: if you're having any issues with memory, you might want remove |
|
Thanks for the REALLY helpful advice @gjoseph92. I can confirm that memory is not the issue. I think I know what the problem is. It's that on the EMR cluster, I am using spot units to cut down on costs. What that means though is that workers die every so often, since there aren't enough resources available for the Dask workers. I have switched to on-demand for the time being, and so far, things seem to be more stable. I am guessing Dask workers aren't quite fault tolerant as I initially though. |
|
@rileyhun glad to hear things are working better. Dask should be able to handle workers coming and going like that, though it's a somewhat common trigger for bugs. Did you end up running that script? I'd be curious to see the output if so. These are the sorts of issues we want to track down and fix. |
|
Hi @gjoseph92 - Thanks for your response. Apologies if this is a dumb question - I wanted to run your script - but how does one do that whilst in the midst of running the Dask job. I'm using a Jupyter Notebook as part of |
|
Ah yes, you'd do that and just pass the address of the cluster. Or if there's some other way you connect to the cluster, you can modify the script accordingly. |
|
I unfortunately get an error when I try running your script: |
|
Are you sure you ran it from the right Python environment? Same one your Jupyter notebook is running in that's connected to the cluster? |
|
Oh my bad - I do think your script is incompatible with my python environment though. My Jupyter notebook that's connected to the cluster is using |
|
Ah, that's because the latest versions of dask and distributed only support Python 3.8 now. Change it to f"time remaining = {dask_worker.batched_stream.next_deadline - time() if dask_worker.batched_stream.next_deadline else None}\n" |
|
Thanks @gjoseph92. command: Here is the return of that script: |
|
Just wanted to reaffirm that after switching to on-demand nodes, I have not encountered the bug again. Ideally though, would be nice if it could work on spot units because we are essentially wasting a lot of money. |
|
Agreed that this should work with spot instances @rileyhun. Thanks again for reporting, and sorry about the bug. There are a few issues we’re aware of that could be causing this. Unfortunately, finding a root cause of these deadlocks is a very slow process right now, and we already have a few others to work on (and it's quite likely that yours is caused by one of the same underlying issues). Once #5736 gets in, issues like this will be much easier to debug, so if you want to try it again in the future, we'll follow up when we could use more information or have a potential fix. |
|
Hi @gjoseph92 - Wanted to report that this issue has started occurring again even after using on-demand instances. It's infrequent but does happen and the delay is a bit unwelcome because if it stalls while leaving a dask job overnight, it potentially costing my employer a lot of $.
|

|
@rileyhun can you confirm then that no workers left the cluster while it was running? Also, is work stealing disabled on this cluster like it was in your original post? I recommend making a cluster dump for further debugging. However, I'm looking at some other deadlocks right now that will take my attention for a bit, so I can't give you a timeline on when I would be able to look into it. To mitigate the overnight cost problem, you could consider writing a Scheduler plugin (or just run a script on the client) to try to detect the deadlocks and shut down, or restart all workers, when they happen. You'd want to do something similar to the script I linked: every few minutes, if there are |
|
Unfortunately, I re-ran the batch after restarting the cluster, so can't confirm that anymore, but I somewhat recall that when I looked at the number of workers from the dashboard, there were 400+ which is consistent with the number of workers I set. I can also confirm that I disabled work stealing. I re-enabled it and (as indicated above) I re-ran the batch, and it was successful. Thanks for the suggestion - that's a great idea. I will look into that. |
|
Looking at this, it would be highly valuable to try to reduce this down to a reproducible example. I suspect that if that is possible then it will be very easy to resolve whatever issue exists. No worries if you don't have time for that though @rileyhun |
|
We are running on 2022.12.1, with work_stealing disabled. This same issue occurs for our smaller clusters too(with 60 workers). These workers are running on spot instances, but in our case the instances/workers weren't replaced during task execution, yet they get stuck infrequently. I verified with dask client as mentioned in one of the above comments. In [7]: client.processing()
Out[7]:
{
...
'tcp://10.10.1.205:37161': (),
'tcp://10.10.1.205:41993': ("('repartition-300-7159aacfd17ad37fc0fb840597119420', 129)",
"('repartition-300-7159aacfd17ad37fc0fb840597119420', 190)"),
'tcp://10.10.1.205:42537': (),
...
}
In [15]: client.call_stack()
Out[15]: {}The output of 2 don't match, scheduler thinks a worker is executing tasks whereas the call_stack is empty. As a quick fix, I've written a small script to restart workers which don't show up in call_stack. Is there any other configuration that can help me avoid this inconsistent state between scheduler and worker altogether? |
|
@n3rV3 a lot of things changed since this issue was first opened and I doubt you are running into the exact same issue. In fact, I hope that the original report was fixed by now since the effort around #5736 concluded. The most critical stability fixes were merged and released already in If you are still seeing your computation to be stuck, this is very troubling. To debug this we'll need a bit more information. Can I ask you to open a new ticket to track your problem? It would be perfect if you could reproduce the issue with some minimal code. If that's not possible, please provide a dashboard screenshot as a starting point and describe the computation with some pseudo code. The diff between processing and call_stack is unfortunately not sufficient.
There is only one configuration option that can sometimes help diagnose inconsistent state which is called |
|
@fjetter give me a few days, I don't have a sample dag, which i'll be able to share. Thanks |
|
Should this issue be closed if it is fixed? |
I'm inclined to close since I assume it should be fixed but don't have any confirmation. @rileyhun did you encounter this issue again with a reasonably recent version? (>=2022.6.0) |
|
@fjetter We've also just experienced issues with tasks that got stuck ( The error we're seeing is that out of ~170_000 tasks (which are submitted in batches of 50_000), one task in the second to last batch gets stuck. I ran the above script (with a slight adaption to work with the newest We know that all tasks would pass when running them in smaller batches, each batch on a dedicated cluster. |
|
cc @crusaderky There is a way to produce a snapshot of the running cluster, see If anybody is able to create a minimal reproducer we will have a much easier time fixing this. |
|
Thanks @fjetter! I will try another run today to see if I can reproduce and dump the state 👍 |
|
Hi, I encounter a similar deadlock issue. I use dask distributed on an HPC cluster. I have 500 single threaded workers. A run millions of tasks by batches of 90 000 tasks. As some point, after a couple of batches (4 to 6), one the last tasks in a given batch blocks the code, and the cluster never finishes his work. Here are the versions I am using for dask and python: I have tried to dump the cluster state with client.dump_cluster_state(filename), yet the code is running for 1 hour and I still cannot access the dump file. I cannot copy past the dashboard screenshots I have prepared, github says it can process the file. Kind regards, |
|
@Victor-Le-Coz sorry to hear that. Without more information there is only little we can do. The one thing I can recommend is to upgrade to a more recent dask version. |
|
Ok thank you a lot, I will update the Dask version and keep you informed! |
|
Hi @fjetter, Is the version 2022.12.0 of dask available on conda forge ? I could not find it unfortunately The issue persist, and I observed that it appends generally when some worker died unexpectedly, here is an example of error log: _The above exception was the direct cause of the following exception: Traceback (most recent call last): |
yes, it should be one conda-forge. It's not important to pick this particular version. anything more recent should do. In fact, in such a situation, please also try the latest version first. FWIW We are currently working on #6790 which fixes a problem that lets computations stall when workers are leaving/dying and the user configured too large timeouts. |
What happened:
This is an issue I posted on StackOverflow but received feedback that I should post this as
dask.distributedissue. I have a production dask batch inferencing work load that's applying machine learning predictions against 300K rows of features and am desperately seeking some guidance for an issue I'm facing. I'm usingdask-yarnon an EMR instance on AWS. It happens on a random occurrence. - that is, there seems to be some stragglers that are holding up Dask and I am not sure how to deal with them. For the assign task, it's been stuck at 9994/10000, and it just gets stuck and doesn't process the remaining tasks for some reason. There have been other times when I've used Dask and it sometimes gets "stuck" on bigger datasets. I am using relatively small batches - 300K rows of data at a time.P.S. Sometimes I'll stop the Dask processing and then retry running on the same batch it got stuck on, and then it will finally process. Then it gets stuck on the next batch, and then I'll have stop Dask again, retry and then that batch will work. It's quite annoying.
What you expected to happen:
I expected the jobs to run smoothly without any tasks getting stuck
Example Code (non-reproducible):
Anything else we need to know?:
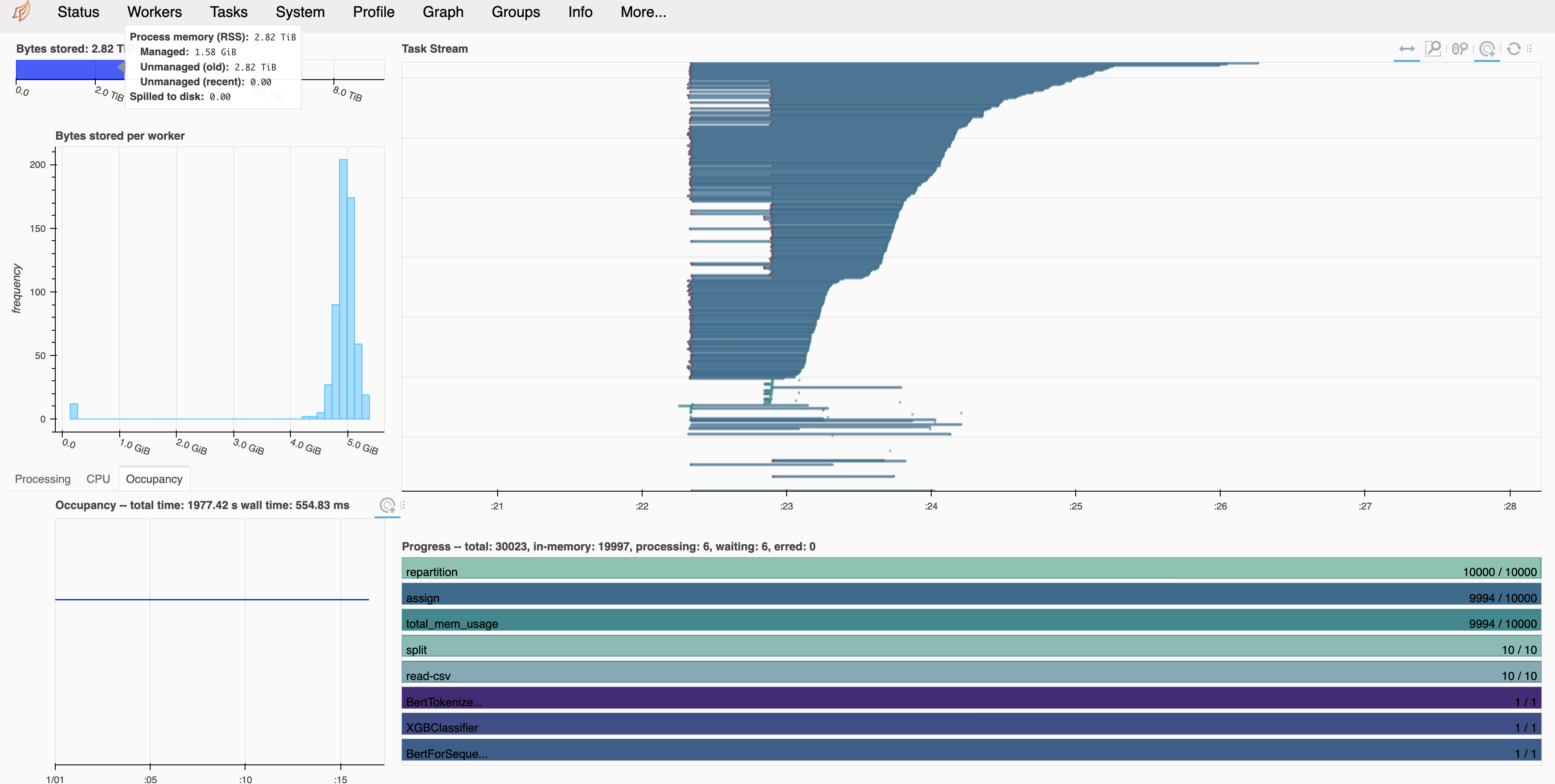
Environment:
dask-yarn 0.9Cluster Dump State:
The text was updated successfully, but these errors were encountered: