The new cleaner code base is at https://github.com/Metta-AI/metta
A reinforcement learning codebase focusing on the emergence of cooperation and alignment in multi-agent AI systems.
- Discord: https://discord.gg/mQzrgwqmwy
- Talk: https://foresight.org/summary/david-bloomin-metta-learning-love-is-all-you-need/
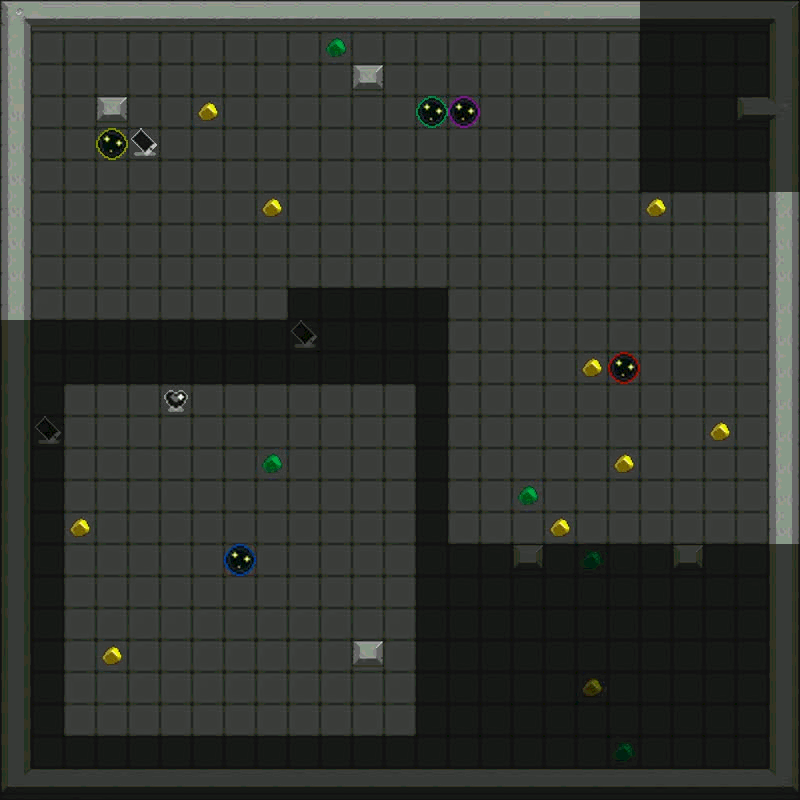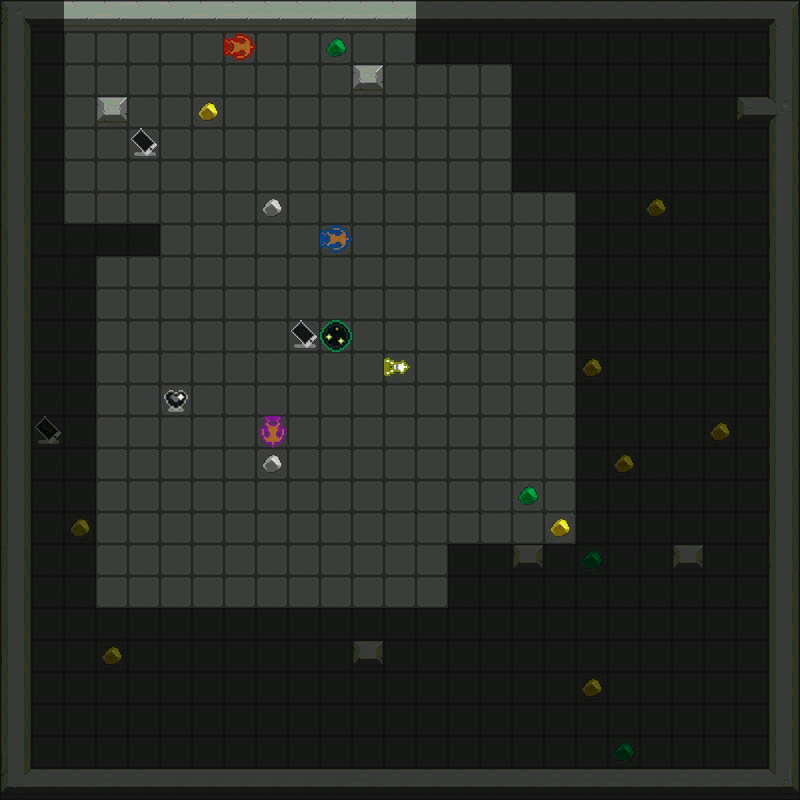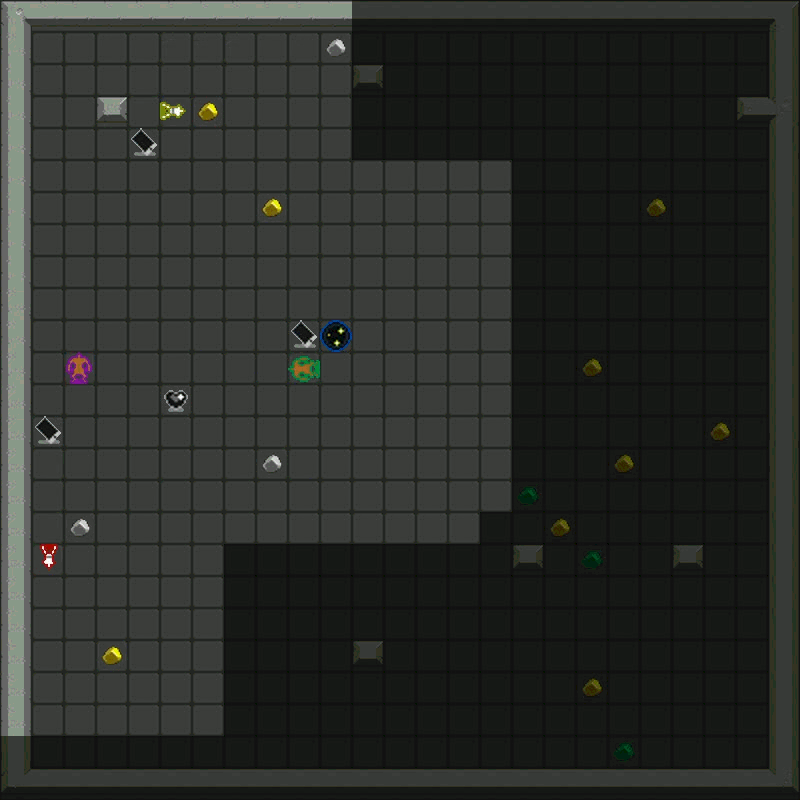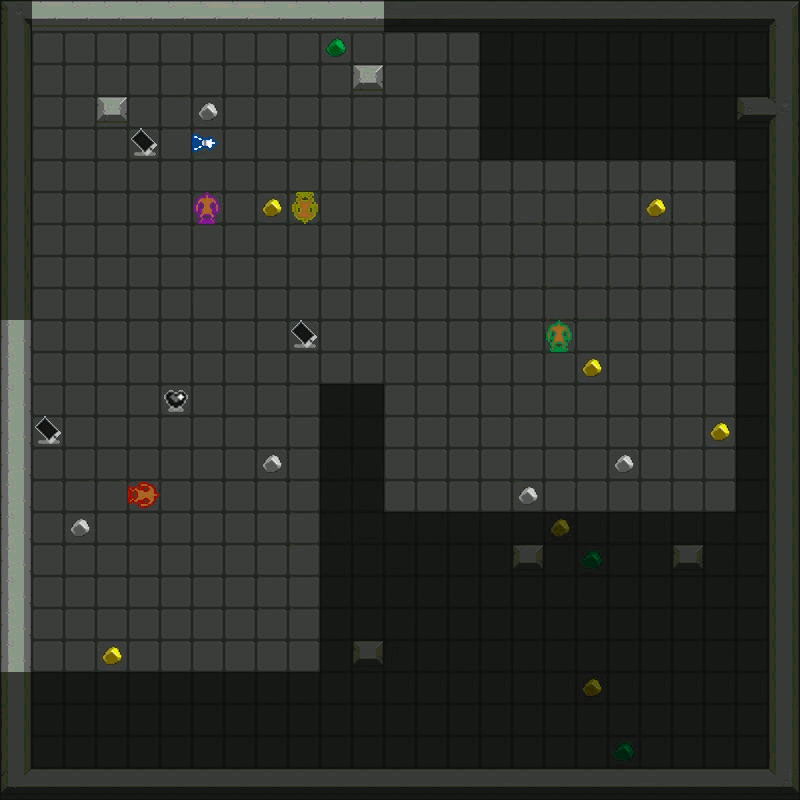
Metta AI is an open-source research project investigating the emergence of cooperation and alignment in multi-agent AI systems. By creating a model organism for complex multi-agent gridworld environments, the project aims to study the impact of social dynamics, such as kinship and mate selection, on learning and cooperative behaviors of AI agents.
Metta AI explores the hypothesis that social dynamics, akin to love in biological systems, play a crucial role in the development of cooperative AGI and AI alignment. The project introduces a novel reward-sharing mechanism mimicking familial bonds and mate selection, allowing researchers to observe the evolution of complex social behaviors and cooperation among AI agents. By investigating this concept in a controlled multi-agent setting, the project seeks to contribute to the broader discussion on the path towards safe and beneficial AGI.
Metta is a simulation environment (game) designed to train AI agents capable of meta-learning general intelligence. The core idea is to create an environment where incremental intelligence is rewarded, fostering the development of generally intelligent agents.
-
Agents and Environment: Agents are shaped by their environment, learning policies that enhance their fitness. To develop general intelligence, agents need an environment where increasing intelligence is continually rewarded.
-
Competitive and Cooperative Dynamics: A game with multiple agents and some competition creates an evolving environment where challenges increase with agent intelligence. Purely competitive games often reach a Nash equilibrium, where locally optimal strategies are hard to deviate from. Adding cooperative dynamics introduces more behavioral possibilities and smooths the behavioral space.
-
Kinship Structures: The game features a flexible kinship structure, simulating a range of relationships from close kin to strangers. Agents must learn to coordinate with close kin, negotiate with more distant kin, and compete with strangers. This diverse social environment encourages continuous learning and intelligence growth.
The game is designed to evolve with the agents, providing unlimited learning opportunities despite simple rules.
The current version of the game can be found here. It's a grid world with the following dynamics:
- Agents and Vision: Agents can see a limited number of squares around them.
- Resources: Agents harvest diamonds, convert them to energy at charger stations, and use energy to power the "heart altar" for rewards.
- Energy Management: All actions cost energy, so agents learn to manage their energy budgets efficiently.
- Combat: Agents can attack others, temporarily freezing the target and stealing resources.
- Defense: Agents can toggle shields, which drain energy but absorb attacks.
- Cooperation: Agents can share energy or resources and use markers to communicate.
The game offers numerous possibilities for exploration, including:
- Diverse Energy Profiles: Assigning different energy profiles to agents, essentially giving them different bodies and policies.
- Dynamic Energy Profiles: Allowing agents to change their energy profiles, reflecting different postures or emotions.
- Resource Types and Conversions: Introducing different resource types and conversion mechanisms.
- Environment Modification: Enabling agents to modify the game board by creating, destroying, or altering objects.
The game explores various kinship structures:
- Random Kinship Scores: Each pair of agents has a kinship score sampled from a distribution.
- Teams: Agents belong to teams with symmetric kinship among team members.
- Hives/Clans/Families: Structuring agents into larger kinship groups.
Future plans include incorporating mate-selection dynamics, where agents share future rewards at a cost, potentially leading to intelligence gains through a signaling arms race.
Metta aims to create a rich, evolving environment where AI agents can develop general intelligence through continuous learning and adaptation.
The project's modular design and open-source nature make it easy for researchers to adapt and extend the platform to investigate their own hypotheses in this domain. The highly performant, open-ended game rules provide a rich environment for studying these behaviors and their potential implications for AI alignment.
Some areas of research interest:
Develop rich and diverse gridworld environments with complex dynamics, such as resource systems, agent diversity, procedural terrain generation, support for various environment types, population dynamics, and kinship schemes.
Incorporate techniques like dense learning signals, surprise minimization, exploration strategies, and blending reinforcement and imitation learning.
Investigate scalable training approaches, including distributed reinforcement learning, student-teacher architectures, and blending reinforcement learning with imitation learning, to enable efficient training of large-scale multi-agent systems.
Design and implement a comprehensive suite of intelligence evaluations for gridworld agents, covering navigation tasks, maze solving, in-context learning, cooperation, and competition scenarios.
Develop tools and infrastructure for efficient management, tracking, and deployment of experiments, such as cloud cluster management, experiment tracking and visualization, and continuous integration and deployment pipelines.
This readme provides only a brief overview of research explorations. Visit the research roadmap for more details.
Windows
Linux
mkdir ~/vulkan
cd ~/vulkan
wget https://sdk.lunarg.com/sdk/download/1.3.224.1/linux/vulkansdk-linux-x86_64-1.3.224.1.tar.gz
tar -zxvf vulkansdk-linux-x86_64-1.3.224.1.tar.gz
cd 1.3.224.1
yes | ./vulkansdk
echo 'source ~/1.3.224.1/setup-env.sh' >> ~/.bashrcMetta uses griddly and sample factory repos as submodules. To fetch the latest versions of these projects use the following commands:
git submodule init
git submodule update
Start installing the requiruments:
conda create -n metta python=3.11.7
conda activate metta
pip install -e .
- Create a HuggingFace account
- Create a token in your account settings
- Run
huggingface-cli loginand paste the token
To download the model files, install git-lfs first, then run the following commands:
git lfs install
./devops/load_model.sh baseline.v0.5.4
python -m tools.run cmd=evaluate experiment=baseline.v0.5.4
python -m tools.run cmd=train experiment=my_experiment hardware=macbook
In case of an an "Invalid setting" error when running pip install, e.g., :
"ERROR: Invalid setting '15' is not a valid 'settings.compiler.version' value.
Possible values are ['5.0', ..., '14.0']
Read "http://docs.conan.io/en/latest/faq/troubleshooting.
html#error-invalid-setting"
Follow these steps (tested on MacOS):
- open ~/.conan/settings.yml
- Inside the file, go to
apple-clang->versionand add missing value ("15" in the example above) is in theversionlist - For more information: https://docs.conan.io/en/1.16/faq/troubleshooting.html