- Certified Kubernetes Administrator(CKA)
- Useful Links
- Basic Kubernetes Architecture
- API Premitives (or) Cluster Objects
- Services & Network Primitives
- Designing a K8s Cluster
- Hardware and Underlying Infrastructure
- Securing Cluster Communications
- High Availability(HA)
- End-to-End Testing & Validation Nodes & the Cluster
- Labels & Selectors
- Taints and Tolerations
- Manually Scheduling Pods
- Monitoring Cluster and Application Components (5% of the Exam)
- Cluster Maintenance (11% of the Exam)
- Networking (11%)
- Storage(7%)
- Secuirty
- Liveness and Readiness Probes
- Troubleshooting
Infrastructure for container projects - LXC, LXD & LXCFS further reading on what are LXD and LXC container runtime technologies is highly recommended
Running Locally (non Minikube)
Monitoring Kubernetes with Prometheus

-
Master/Control Plane - cluster’s control plane with HA setup (or) single node instance
-
kube-apiserver- answers api call -
etcd- key/value store used by API Server for configuration and other persistent storage needs -
kube-scheduler- Determins which nodes are responsable forPODSand their respective containers as they are up in the cluster -
kube-controller-manager- Component on the master that runs controllers .Logically, each controller is a separate process, but to reduce complexity, they are all compiled into a single binary and run in a single process.
These controllers include:
- Node Controller: Responsible for noticing and responding when nodes go down.
- Replication Controller: Responsible for maintaining the correct number of pods for every replication controller object in the system.
- Endpoints Controller: Populates the Endpoints object (that is, joins Services & Pods).
- Service Account & Token Controllers: Create default accounts and API access tokens for new namespaces.
-
cloud-controler-manager- split out in to several containers depends on cloud platform we are running - responsible for persistatnt storage, routes for networking
-
-
Nodes/Workers - workers/minions are work force of the cluster
kublet- takes orders from master to runPODSkube-proxy- assist withContainer Network Interface(CNI)with routing traffic around the clusterPOD- one (or) more containers run as part ofPODwhich are considered disposablea and replacable
Persistent entities and represent state of the cluster like,
- What applications are running
- Which node those applications are running on
- Policies around those applications
K8s Objects are records of intent
- User provides desired state of an object
- Provided by K8s to describe the actual state of the object which is managed by control plane of K8s
- Nodes - which makes the cluster
- PODS - single instance of application containers
- Deployments - Controller for
PODSand it ensures that resources are available, such as IP address, and storage and then deploys aReplicaSet - ReplicaSet - controller which deploys and restart
PODSuntil requested number ofPODSare running. - Services - Exposes deployments to external networks by means of 3rd party LoadBalancer (or) ingress rules
- ConfigMaps - KV pair that can dynamically plugged in to other objects as needed which allows to decouple configuration from individual
PODS(or)Deploymentswhich gives lot of flexibility
Names
- lower case alphanumeric with max len 253 characters and can be resued and provided by client but must be uniq.
BTW:- and . are allowed.
UIDs
- generated by K8s
Namespaces
- multiple virtual clusters back by same physical cluster
- best for large deployments to isolate cluster resources and to define RBAC and quotas
kube-systemspecial namespace used to differenciate systemsPODSfrom userPODS
Route Controller(GCE clusters only)Service Controller- responsbile for listening to service create/update/delete events and update cloud load balancers like AWS-ELB, Google-LB,Azure-LB to reflect the state of services in K8sPersistent Volume Labels Controller- applies labels AWS-EBS,GCE-PD(persistent disk) volumes when those get created which allows to manually define by user. These lables are centeral to scheduling ofPODSas those labels are constrain to work only in the region/zone they are in.
- Assigns CIDR block to new nodes(if CIDR assignment is turned on).
- Keeps track of the nodes using health of the node and changes the status of
Not ReadytoUNKNOWNwhen node becomes unreahable with-in the heartbeat intervals(40 sec timeout). If node state is flagged as UNKNOWN and5 minafter that it evictsPODS(rate of0.1/sec[effected by cluster_size(default 50) configurable bylarge_cluster_size_threshold] means it will not effectPODSfrom more than1 node every 10 sec) from unhealthy nodes.BTW:evictions are stopped if nodes in all availablity zones are flagged asUNKNOWNbecause there could be scenario wheremaster nodecould be having problem connecting toworker nodes - Checks the status of nodes every few sec which is configurable by setting
node_monitor_period
- Servics refere to deployments and exposes particualr port via kube-proxy (or) using special IP Address for entire
PODand prefernce of this setup strictly depends on network policies, security policies, ingress rules to handle load balancing and port forwarding with-in each cluster deployment.
- Minikube - single node K8s on local workstation
- Kubeadm - multi-nodes cluster on local workstation
Ubuntu on LXD- provides nine-instance suppoted cluster on local workstation
- conjure-up - deploy the Canonical Distribution of Kubernetes with Ubuntu on AWS, Azure, Google and Oracle Cloud
- AWS EKS, Azure AKS, Google GKE, Tectonic by CoreOS, Stackpoint.io, kube2go.io as well as madcore.ai
- Container Network Interface(CNI)
- Calico - secured L3 networking and policy provider
- Canal unites Flannel & Calico - provided networking and policies
- Cilium - L3 network and policy plugin that can enforce HTTP/API/L7 policies transparently
- CNI-Genie - enables K8s to seamlessly connect to CNI of any choice such as Calico, Canal, Flannel, Romana (or) Weave
- NSX-T(NCP) provides integration between VMWare NSX-T and container orchestrator such as K8s as well as container-based platforms(CaaS,PaaS) like PCF and Openshift.
- Nuage is a SDN platform that provides policy-based networking between K8s
PODSand non-K8s environments with visibility and security monitoring - Weave Net provides networking and policy and doesn't require an external database.
- Nodes including master can be physical/virtual running K8s components and a container runtime like Docker, rocket(rkt)
- nodes should be connected by a common network where
Flannelis used as basicPODSnetworking application.
- Communication to API Server/Service, control-plane communications inside the cluster and even
POD-to-PODcommunications. - Default encryption communication is
TLS - Ensure any unsecure taffic/ports are
DISABLED - Anything that connects to API, including nodes, proxies, the scheduler, volume plugins and users should be
Authenticated - Certs for all internal communication channels are automatically creaded unless you chose to deploy K8s cluster the hardway
- Once Authenticated
Authorization checksshould be passed. RBAC Control Componentused to match users/groups to permission sets that are organized in to roles
- By default exposes HTTPS endpoints which gives access to both data and actions on the nodes, to enable Kubelet to use RBAC policies by starting it with a flag
--anonymous-auth=falseand assign an appropriate x509 client certificate in its configuration.
- Network policies restrict access to network for a particualr namespace
- Users can be assigned quotas or limit ranges to prevent over usage of node ports (or) Load Balance services
- etcd is default key/value to store for entire cluster to store configuration and secrets of the cluster so isolate its access behind FW so only it is accessed through API which should be well enforced using RBAC
- Audit logging and architect to store the audit file on to a secure server
- Rotate Infra Credentails frequently by setting short liftime and use any automated rotation methods where applicable
- Don't allow them in to kube-system namespace
- Always review integration before enabling
Join K8s announcement group for emails about security announcements.
- Create reliable nodes that forms the cluster
- Setup redundant and reliable storage service with multinode deployment of etcd
- Start replicated and load balanced API Server/Service
- Setup a master-elected scheduler and controller manager daemons.
- Ensure cluster services automatically restart if they fail and
Kubeletalready does this, but what ifKubeletgoesDOWN, so for that we need something like monit to watch the service/process.
- Clustered
etcdalready replicates the storage to all master instances in the cluster - Add additional reliability by increasing the cluster from 3 to 5 nodes and even more where applicable
- If using cloud provider then use any Block Device Persistent Storage offerings of that cloud provider to map/mount then on to your virtual machines in the cloud.
- If running on Baremetal - use options like NFS, Clustered Filesystem like Gluster (or) Ceph, Hardware level RAID
- Refere to image in
images/k8s-ha-step3-1.pngandimages/k8s-ha-step3-2.pngfiles for detail steps
- Allow our state to change, we use lease-lock on API to perform master election. So each scheduler and controller manager will be started using
--leader-electflag to ensure only 1 instance of scheduler and controller manager(CM) are running and making changes to cluster - Scheduler and CM can be configured to talk to the API Server/Service that is on the same node (or) through Loadbalancd IP(preferred).
-
Create empty log files on each node, so that Docker will mount the files and not make new directhries,
touch /var/log/kube-scheduler.log touch /var/log/kube-controller-manager.log
-
Setup the description of the scheduler and CM
PODSon each node by copying thekube-scheduler.yamlandkube-controller-manager.yamlin to the/etc/kubernetes/manifests/directory.
-
Kubetest Suite- ideal of GCE and AWS users to,- Build
- Stage
- Extract
- Bring up the Cluster
- Test
- Dump logs
- Tear Down the cluster.
-
manual validation
kubectl get nodeskubectl desribe node <node name>kubectl get pods --all-namespaces -o widekubectl get pods -n kube-system -o wideps aux | grep [k]ube- validate with kube processes are running.
-
Labels are key/value pairs that are attached to objects, such as pods
-
Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users
-
One use case of labels is to constrain the set of nodes onto which a pod can schedule
-
The API currently supports two types of selectors: equality-based and set-based
- equality-based
kubectl get pods -l environment=production,tier=frontend
- set-based
- Newer resources, such as Job, Deployment, Replica Set, and Daemon Set support set-based requirements as well.
kubectl get pods -l 'environment in (production),tier in (frontend)'
-
Node affinity, described here, is a property of pods that attracts them to a set of nodes (either as a preference or a hard requirement). Taints are the opposite – they allow a node to repel a set of pods.
-
Taints and tolerations work together to ensure that pods are not scheduled onto inappropriate nodes. One or more taints are applied to a node; this marks that the node should not accept any pods that do not tolerate the taints. Tolerations are applied to pods, and allow (but do not require) the pods to schedule onto nodes with matching taints.
-
Taint Nodes by Condition beta in v1.12
- cAdvisor exposes simple UI for local containers on port 4194(default)
- metric-server (< K8s v1.8)
- Logging
-
Good discussion on K8s issue in github - Kubernetes logging, journalD, fluentD, and Splunk, oh my!
-
- Clustet setup using
kube-up.shconfigures logrotate tool to run each hour to rotate containers logs when log file exceeds10MB (default) - Container engine/runtime can also rotate logs for example: Docker Logging Drivers
- Clustet setup using
-
- Two types of system components: those that run in a container and those that do not run in a container. For example:
- The Kubernetes scheduler and kube-proxy run in a container.
- The kubelet and container runtime, for example Docker, do not run in containers.
- On machines with
systemd, thekubeletandcontainer runtimewrite tojournald. - If
systemdis not present, they write to.logfiles in the/var/logdirectory. - System components inside containers always write to the
/var/logdirectory,bypassing the default logging mechanism. They use the glog logging library.- Conventions for logging severity for these components can be found in the development docs on logging
- Logrotations happens either daily or once the size exceeds
100MB (default).
- Two types of system components: those that run in a container and those that do not run in a container. For example:
-
-
logs should have a separate storage and lifecycle independent of nodes, pods, or containers
-
Here are some options:
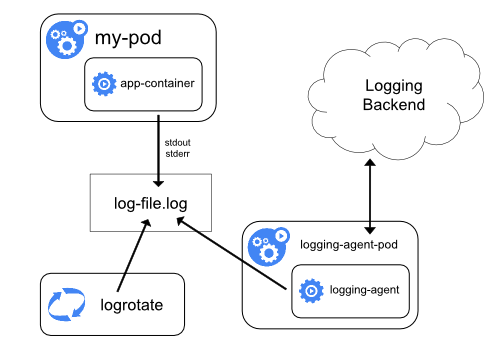
- Use a
node-level logging agentthat runs on every node. - Include a
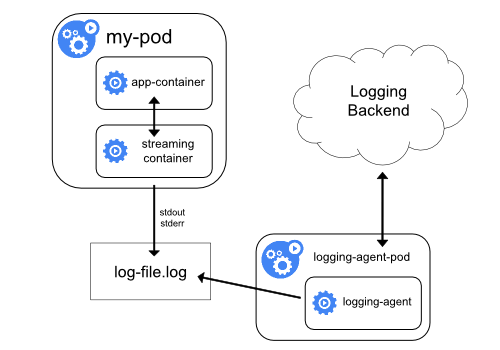
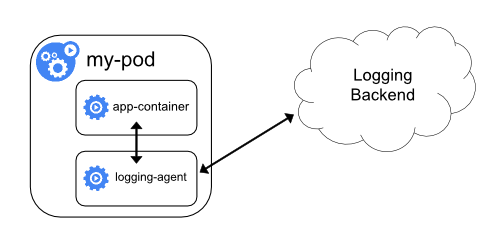
dedicated streaming sidecar container(or)dedicated sidecar container with logging agentfor logging in an application pod. Push logs directlyto a backend from within an application.
- Because the logging agent must run on every node, it's implemented as
DaemonSet replica - Best suties only for applications emitting logs to
stdoutandstderr
- The individual sidecar container streams application logs to its own
stdoutandstderr - The sidecar container runs a logging agent, which is configured to pick up logs from an application container.
- The sidecar containers read logs from a file, a socket, or the journald.
- writing logs to a file and then streaming them to stdout can double disk usage
- If you have an application that writes to a single file, it’s generally better to set
/dev/stdoutas destination rather than implementing the streamingsidecar containerapproach.
Sidecar Container with Logging Agent
- ConfigMaps are used to configure the configuration for logging-agents like - Fluend, Splunk (or) Splunkforwarder-with-DeploymentServer
- Use a
-
-
Upgrading Kubernetes Components using kubeadm
- We need to have a
kubeadmKubernetes cluster - Swap must be disabled
- The cluster should use a static control plane and etcd pods.
- Make sure you read the release notes carefully.
- Make sure to back up any important components, such as app-level state stored in a database.
- Upgrade
kubeadmpkg using the pkg manager specific to OS -yum(or)apt kubeadm upgrade does not touch your workloads, only components internal to Kubernetes, but `backups are always a best practice.All containers are restarted after upgrade,because the container spec hash value is changed.You can upgrade only from one minor version to the next minor version.That is, you cannot skip versions when you upgrade. For example, you can upgrade only from 1.10 to 1.11, not from 1.9 to 1.11.
- Drain node in prepartion for maintenace by using
kubectl drain <node-name> --ignore-daemonsets. The given node will be marked unschedulable to prevent new pods from arriving.drainevicts the pods if the APIServer supports eviction. Otherwise, it will use normal DELETE to delete the pods. - If there are
DaemonSet-managed pods, drain will not proceed without--ignore-daemonsets, and regardless it will not delete any DaemonSet-managed pods, because those pods would be immediately replaced by the DaemonSet controller, which ignores unschedulable markings - If there are any
PODSthat are neither mirror pods nor managed by ReplicationController, ReplicaSet, DaemonSet, StatefulSet or Job, then drain will not delete any pods unless you use--force. drainwaits for graceful termination. You should not operate on the machine until the command completes.- Upgrade
kubeletpkg using the pkg manager specific to OS -yum(or)apt - Verify using
systemctl status kubeletto ensure its still active upgrade the upgrade - Once Upgraded successfully finally uncordon the node so its make as schedulable
-
drainthe node -
Ensure all pods are evicted and node status is flagged as
NotReady, SchedulingDisabled -
As we are not going to bring same machine in to cluster we will delete the node from the know list of
kubeadmusingkubectl delete node <node name> -
To add new upgraded server as node to cluster, follow these steps to get cluster join command with valid token
-
get available token list
kubeadm token list -
if no tokens founds (or) expired generate a new token using
kubeadm token generate -
create token to request the join command
kubeadm token create <token-from-generate-cmd> --ttl <h> --print-join-command kubeadm join <master-ip>:6443 --token <token-provided> --discovery-token-ca-cert-hash sha256:<random-hash>
(or)
- Just use
kubeadm token create --print-join-commandto generate new token and print-join-command using one single command
-
Master Node
| Ports(over TCP) | Service |
|---|---|
| 6443 | API Server |
| 2379, 2380 | etcd server client API |
| 10250 | Kublet API |
| 10251 | kube-scheduler |
| 10252 | kube-controller-manager |
| 10255 | read-only Kublet API |
Worker Node
| Ports(over TCP) | Service |
|---|---|
| 10250 | Kublet API |
| 10255 | read-only Kublet API |
| 30000 - 32767 | NodePort Services |
-
Kubernetes ServiceTypes allow you to specify what kind of service you want [ The default is
ClusterIP]Type values and their behaviors are:
ClusterIP: Exposes the service on a cluster-internal IP. Choosing this value makes the service only reachable from within the cluster. This is the default ServiceType.NodePort: Exposes the service on each Node’s IP at a static port (the NodePort). A ClusterIP service, to which the NodePort service will route, is automatically created. You’ll be able to contact the NodePort service, from outside the cluster, by requesting <NodeIP>:<NodePort>.LoadBalancer: Exposes the service externally using a cloud provider’s load balancer. NodePort and ClusterIP services, to which the external load balancer will route, are automatically created.ExternalName: Maps the service to the contents of the externalName field (e.g. foo.bar.example.com), by returning a CNAME record with its value. No proxying of any kind is set up. This requires version 1.7 or higher of kube-dns.
-
LoadBalancer- On cloud providers which support external load balancers, setting the type field to LoadBalancer will provision a load balancer for your Service. The actual creation of the load balancer happens asynchronously, and information about the provisioned balancer will be published in the Service’s .status.loadBalancer field. For example:kind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: MyApp ports: - protocol: TCP port: 80 targetPort: 9376 clusterIP: 10.0.171.239 loadBalancerIP: 78.11.24.19 type: LoadBalancer status: ## This information is published loadBalancer: ingress: - ip: 146.148.47.155
Note: Special notes for Azure: To use user-specified public type loadBalancerIP, a static type public IP address resource needs to be created first, and it should be in the same resource group of the other automatically created resources of the cluster. For example,
MC_myResourceGroup_myAKSCluster_eastus. Specify the assigned IP address as loadBalancerIP. Ensure that you have updated the securityGroupName in the cloud provider configuration file. For information about troubleshootingCreatingLoadBalancerFailedpermission issues see, Use a static IP address with the Azure Kubernetes Service (AKS) load balancer or CreatingLoadBalancerFailed on AKS cluster with advanced networking. -
Spec for
Servicewith Selectorkind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: MyApp ports: - protocol: TCP port: 80 targetPort: 9376
-
Spec for
Servicewithout Selector- Services generally abstract access to Kubernetes Pods, but they can also abstract other kinds of backends. For example:
-
You want to have an external database cluster in production, but in test you use your own databases.
-
You want to point your service to a service in another Namespace or on another cluster.
-
You are migrating your workload to Kubernetes and some of your backends run outside of Kubernetes.
-
In any of these scenarios you can define a service without a selector:
kind: Service apiVersion: v1 metadata: name: my-service spec: ports: - protocol: TCP port: 80 targetPort: 9376
and because this service has no selector, the corresponding Endpoints object will not be created. You can manually map the service to your own specific endpoints:
kind: Endpoints apiVersion: v1 metadata: name: my-service subsets: - addresses: - ip: 1.2.3.4 ports: - port: 9376
- Services generally abstract access to Kubernetes Pods, but they can also abstract other kinds of backends. For example:
-
Multi-Port Services
kind: Service apiVersion: v1 metadata: name: my-service spec: selector: app: MyApp ports: - name: http protocol: TCP port: 80 targetPort: 9376 - name: https protocol: TCP port: 443 targetPort: 9377
Note: Port names must only contain lowercase alphanumeric characters and -, and must begin & end with an alphanumeric character. 123-abc and web are valid, but 123_abc and -web are not valid names.
- Load Balancer
-
Manages external access to the services in a cluster, typically HTTP.
-
Provide load balancing, SSL termination and name-based virtual hosting.
-
Collection of rules that allow inbound connections
-
Exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the ingress resource.
-
An ingress does not expose arbitrary ports or protocols. Exposing services other than
HTTPandHTTPSto the internet typically uses a service of typeService.Type=NodePortorService.Type=LoadBalancer.apiVersion: extensions/v1beta1 kind: Ingress metadata: name: test-ingress annotations: nginx.ingress.kubernetes.io/rewrite-target: / spec: rules: - http: paths: - path: /testpath backend: serviceName: test servicePort: 80
- Single Service Ingress:
- Lifetime of volume is same as that of
PODenclosing it - Volumes outlives any containers that run with the
POD - To use a volume, a Pod specifies what volumes to provide for the Pod (the
.spec.volumesfield) and where to mount those into Containers (the.spec.containers.volumeMountsfield). - Volumes can not mount onto other volumes or have hard links to other volumes
-
emptyDir-
volume is first created when a Pod is assigned to a Node, and exists as long as that Pod is running on that node.
-
When a
POD[not when container crashes] is removed from a node for any reason, the data in the emptyDir is deleted forever. -
Some uses for an emptyDir are:
- scratch space, such as for a disk-based merge sort
- checkpointing a long computation for recovery from crashes
- holding files that a content-manager Container fetches while a webserver Container serves the data
-
emptyDir.mediumfield in.spec.containers.volumescan be set to "Memory" to tell Kubernetes to mount atmpfs(RAM-backed filesystem) for you instead, but files you write will count against your Container’s memory limit. Beware: unlike disks, tmpfs is cleared on node rebootapiVersion: v1 kind: Pod metadata: name: test-pd spec: containers: - image: k8s.gcr.io/test-webserver name: test-container volumeMounts: - mountPath: /cache name: cache-volume volumes: - name: cache-volume emptyDir: {}
-
-
.... volumeMounts: - name: azure mountPath: /mnt/azure volumes: - name: azure azureDisk: diskName: test.vhd diskURI: https://someaccount.blob.microsoft.net/vhds/test.vhd ...
-
downwardAPI - is used to make
downward APIdata available to applications. It mounts a directory and writes the requested data in plain text files.
- Provisioned storage in the cluster
- Cluster resource
- Volume plugins has independent lifecycle from pods
- Volumes share the lifecycle of the pod, Persistent volument doesn't
- API object(YAML) details the implementation
- Request for Storage part of cluster resource
- Pods consume node resources, PVCs consumes PV resources
- Pods can request specific CPU and memory:PV's can request specific size and access mode.
Lifecycle is PV's are Provisioned and then bound to PVC's and PV's are reclaimed once PVC's are released.
-
Provisioning
- Static
- Administrator creates PV's in the K8s API and made availble for consumption
- Dynamic
- Used when one of the static PV's match the PVC and its strictly based on
StorageClasses - PVC must request a created and configured storage class
- Claims requesting for nameless classes disable Dynamic provisioning
- Used when one of the static PV's match the PVC and its strictly based on
To enable dynamic storage provisioning,
DefaultStorageClassaddmission controller on the API server must be enabled. - Static
-
The kubelet uses liveness probes to know when to restart a Container. For example, liveness probes could catch a deadlock, where an application is running, but unable to make progress. Restarting a Container in such a state can help to make the application more available despite bugs.
-
The kubelet uses readiness probes to know when a Container is ready to start accepting traffic. A Pod is considered ready when all of its Containers are ready. One use of this signal is to control which Pods are used as backends for Services. When a Pod is not ready, it is removed from Service load balancers.
- Ensure
kubeletprocess is up and running on nodes - Ensure
CNI plugin, kube-proxypods are running across the cluster nodes - Ensure if any
taintsand un-ignoredTolerationsare cause of missing core servicePODSon nodes, if so fix by updating necessary objects to unblock it - Use
kubectl describe node/pod <node-name/pod-name>to look at the events to understand more about the status - Look at log files under
/var/log/containersfor core servicePODS.