ParsingXBRL
Some SEC filings include data in XBRL (eXtensible Business Reporting Language) format. Edgartools provides ways to extract and use this data.
XBRL can either be embedded in the filing or provided as attachments to the filing. This guide focuses on extracting XBRL from filing attachments.
Inline XBRL is also being parsed using HTMLDocument.from_html(html) and the data is available but for now this parser is not completely developed.
To list all filings that include XBRL use index="xbrl" in the get_filings function.
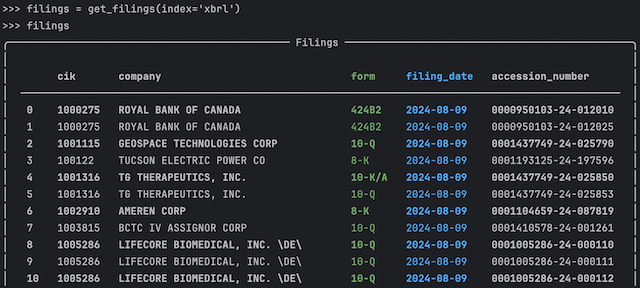
filings = get_filings(index="xbrl")Some forms like 424B2 offerings have only the XBRL instance document as an attachment. For these filings the XBRL parser will extract only an XBRLInstance class containing the data from the instance document.
XBRLDocuments(filings[0].attachments)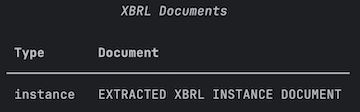
Other forms like 10-K have multiple XBRL attachments.
These will be parsed into an XBRLData class containing the XBRLInstance but also include information about the labels, the presentation, the calculations and other details that allow for precise analysis of the XBRL data.
XBRLDocuments(filings[2].attachments)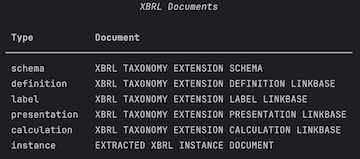
The XBRL parser is integrated within edgartools so it is as simple as calling filing.xbrl()
- If there is no attached XBRL this will return
None. - If there is only the XBRL instance document this will return an
XBRLInstanceobject. - If there are multiple XBRL attachments this will return an
XBRLDataobject.
The XBRLInstance object contains the facts extracted from the XBRL instance document in a dataframe facts.
-
facts: A pandas DataFrame containing the facts extracted from the XBRL instance document. -
query_facts(concept=None, period=None, dimensions=None): Query the facts in the dataframe -
dimensions: Show the dimensions in the XBRL instance -
get_all_dimensions: List all the dimensions in the XBRL instance -
get_dimension_values: Get the values for a specific dimension e.g.get_dimension_values("us-gaap:ProductOrServiceAxis")
The dimensions attribute shows the dimensions in the XBRL instance.
instance.dimensions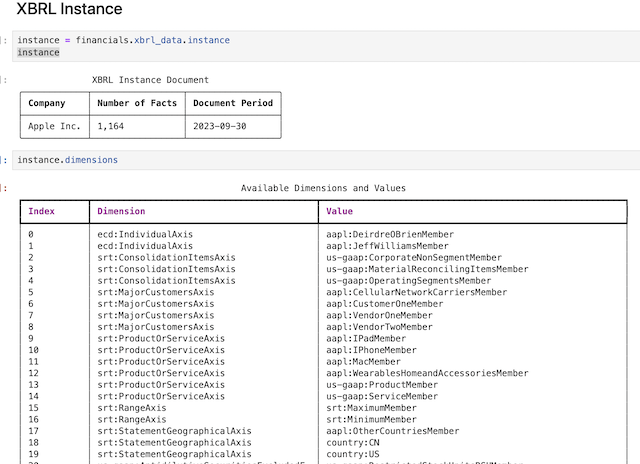
You can select a dimension by index using the bracket [] notation.
instance.dimensions[0]You can select a dimension by name using the get_dimension method. Because this can return potentially several values the object returned is
a DimensionValue
instance.dimensions["ecd:IndividualAxis"]
>>> Dimension(name='ecd:IndividualAxis', values=['aapl:DeirdreOBrienMember', 'aapl:JeffWilliamsMember'])You can again select a dimension by name and value using a tuple. Then you can get the facts for that dimension.
dimension_value = instance.dimensions[('srt:ConsolidationItemsAxis', 'us-gaap:CorporateNonSegmentMember')]
>>> DimensionValue(dimension='srt:ConsolidationItemsAxis', value='us-gaap:CorporateNonSegmentMember')
dimension_value.get_facts()
You can get the values for a specific dimension using the get_dimension_values method.
instance.get_dimension_values("us-gaap:ProductOrServiceAxis")For example, see the XBRL Instance for a 424B4. This has 8 facts in the dataframe.
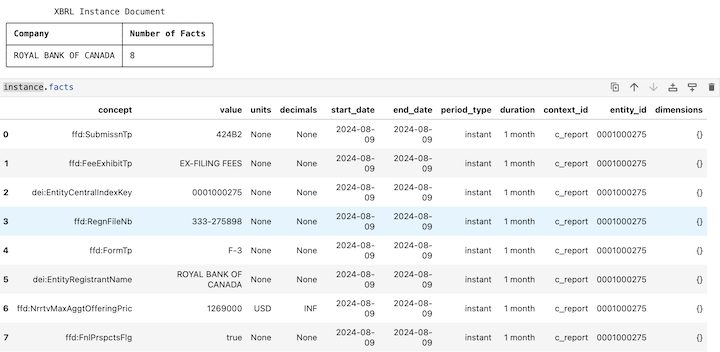
You can query the underlying facts by using the query method on the facts dataframe, using pandas syntax
instance.facts.query("concept=='ffd:FormTp'")Alternatively you can use the convenience function query_facts on the XBRLInstance object.
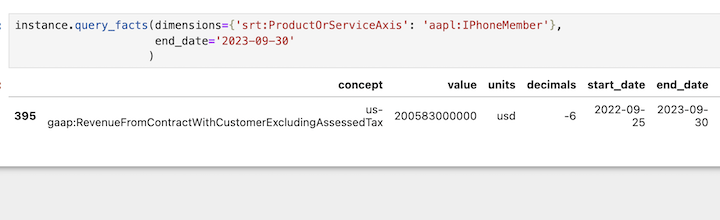
instance.query_facts(concept='ffd:FormTp')This is useful if the facts have dimensions
instance.query_facts(dimensions={'srt:ProductOrServiceAxis': 'aapl:IPhoneMember'},
end_date='2023-09-30'
)
XBRLData is the container for all the XBRL data extracted from the filing. It contains the XBRLInstance as well as the labels, presentation, calculations and other data that is extracted from the filing.
Importantly, it contains all the Statement's extracted from the filing. These are shown when displaying the XBRLData object.
-
parse(instance_xml, presentation_xml, labels, calculations): Class method to parse XBRL documents from XML strings. -
extract(filing): Class method to create anXBRLDatainstance from aFilingobject. -
get_statement(statement_name, ...): Retrieves a specific financial statement as a pandas DataFrame. -
list_statement_definitions(): Returns a list of available statement names. -
get_concept_for_label(label): Finds the concept corresponding to a given label. -
get_labels_for_concept(concept): Retrieves all labels for a given concept.
filing = filings[2]
xbrl_data = filing.xbrl()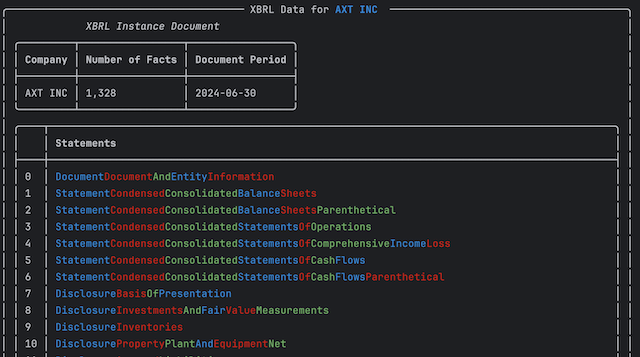
A Statement is a single table from the XBRL data. This could be the financial statements like the balance sheet, income statement, or cash flow statement, or it could be a table with text content like disclosure text.
The first few statements in the XBRLData object are usually the CoverPage (also called DocumentAndEntityInformtion, and the financial statements.
Statement names are not standard among companies, so the statements table allows you to access specific statements by name or index.
The XBRLData object contains a Statements variable which contains a list of statements.
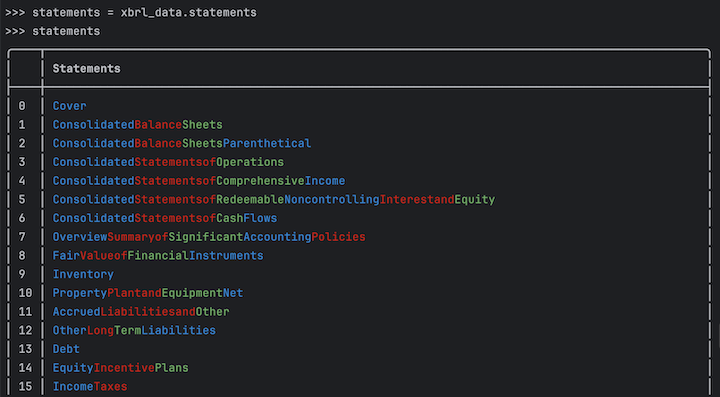
You can access these using the bracket [] notation or by name using the get_statement function.
Choose one of the statements from the list of statements in the XBRLData object using the index.
statement = xbrl_data.statements[0]Choose one of the statements from the list of statements in the XBRLData object.
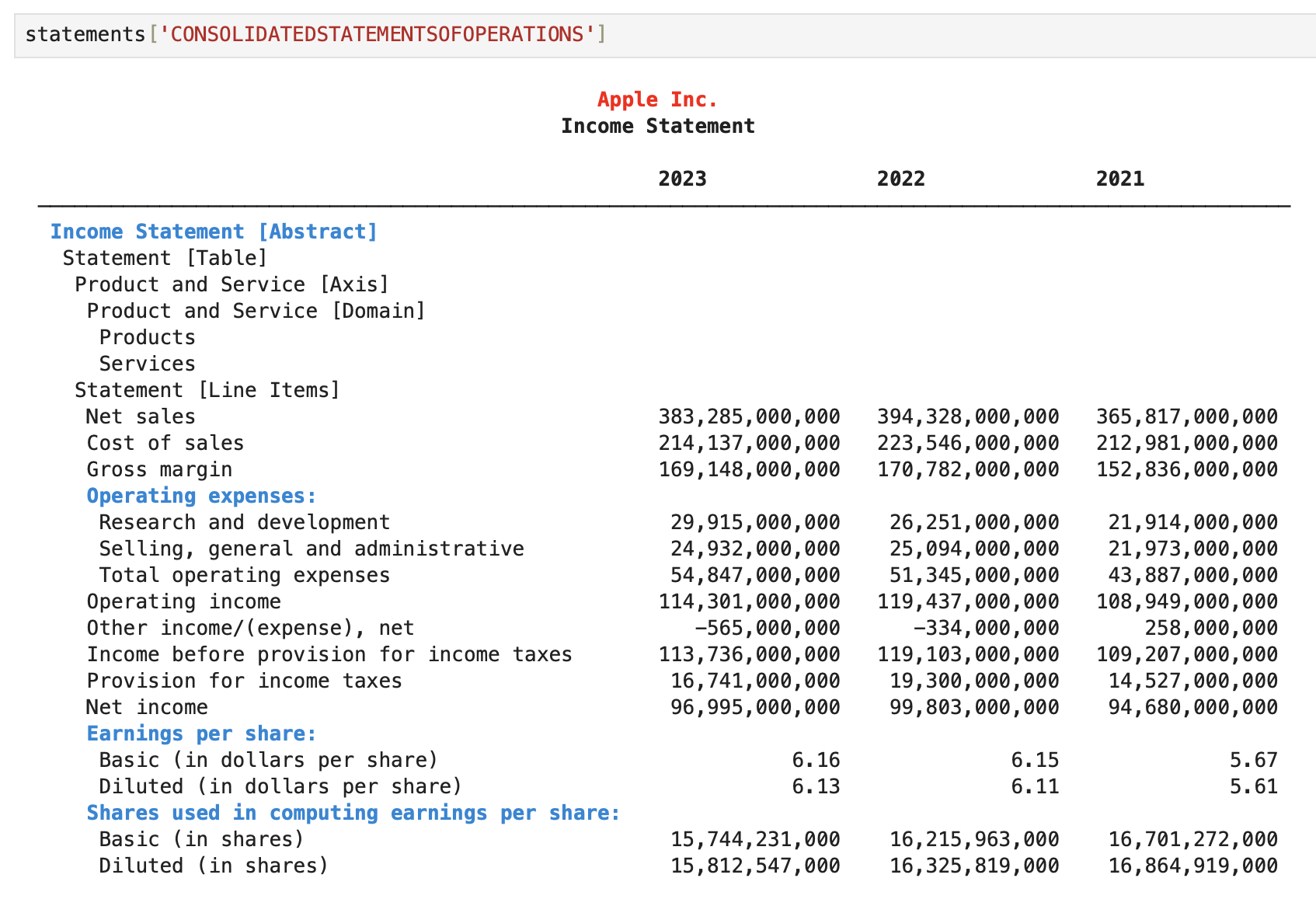
statement = xbrl_data.get_statement("CONSOLIDATEDSTATEMENTOFOPERATIONS")