Many retinal diseases affect arteries and veins in different ways. Clinical observations of the retinal vasculature in diabetic retinopathy patients suggest dilation of the veins and constriction of the arteries. Therefore, the differentiation of arteries and veins can provide important information for the diagnosis and monitoring of retinopathies. To examine the retinal vasculature, optical coherence tomography angiography (OCTA) is used. Current methods for artery-vein (AV) pixel-wise classification or segmentation in OCTA require an extensive image processing procedure, which may inhibit clinical deployment.
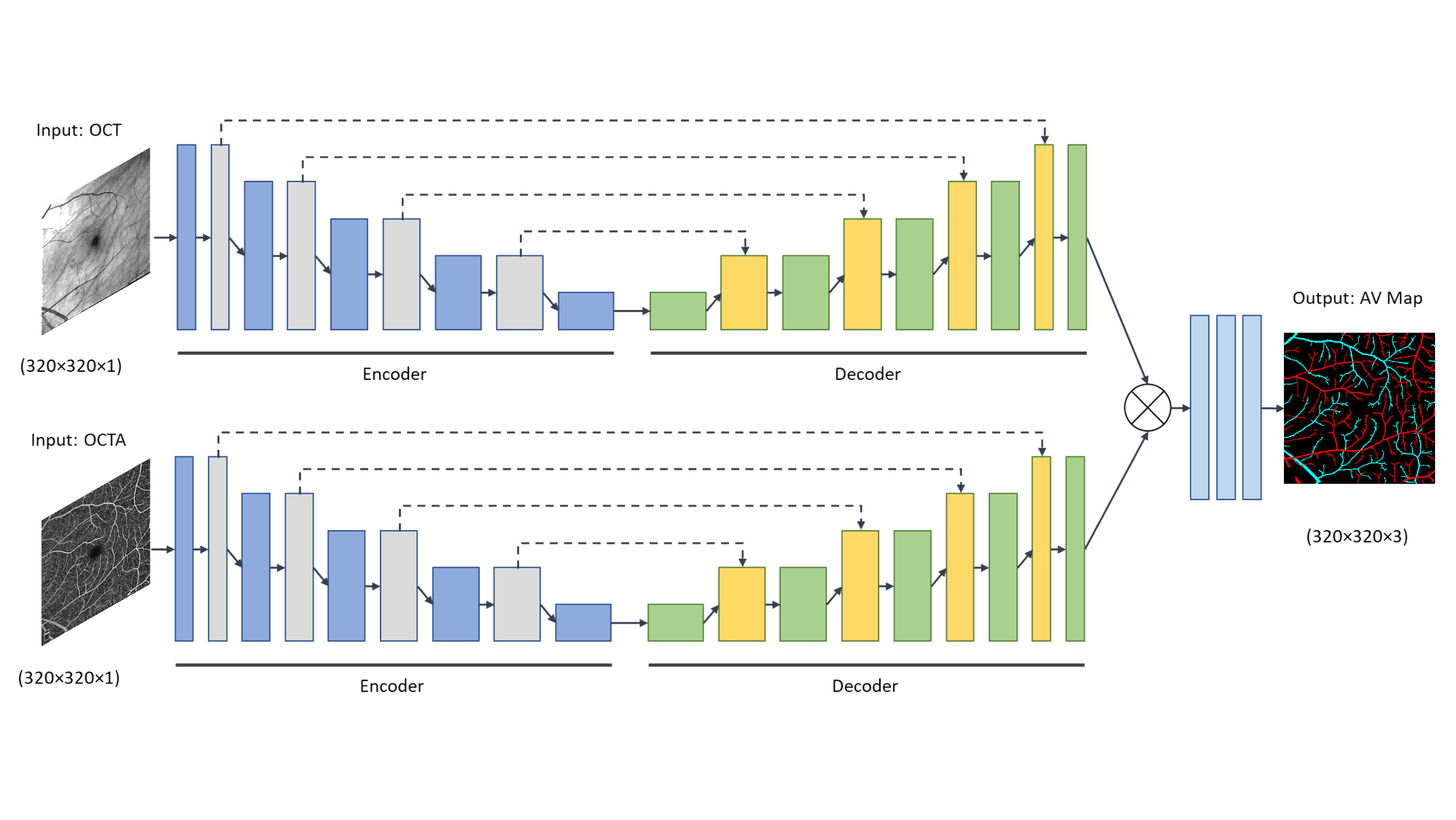
In this project, we present a fully convolutional network (FCN), MF-AV-Net, that consists of multimodal fusion options and validated it for comparative assessment of different optical coherence tomography (OCT) and OCT-angiography (OCTA) fusion strategies to improve AV segmentation performance in OCTA.
Mansour Abtahi and David Le contributed equally to this project, a similar repository can be found here.
The dataset was collected by the Biomedical Optics and Ophthalmic Imaging Laboratory at the University of Illinois at Chicago. This study has been conducted in compliance with the ethical regulations reported in the Declaration of Helsinki and has been authorized by the institutional review board of the University of Illinois at Chicago.
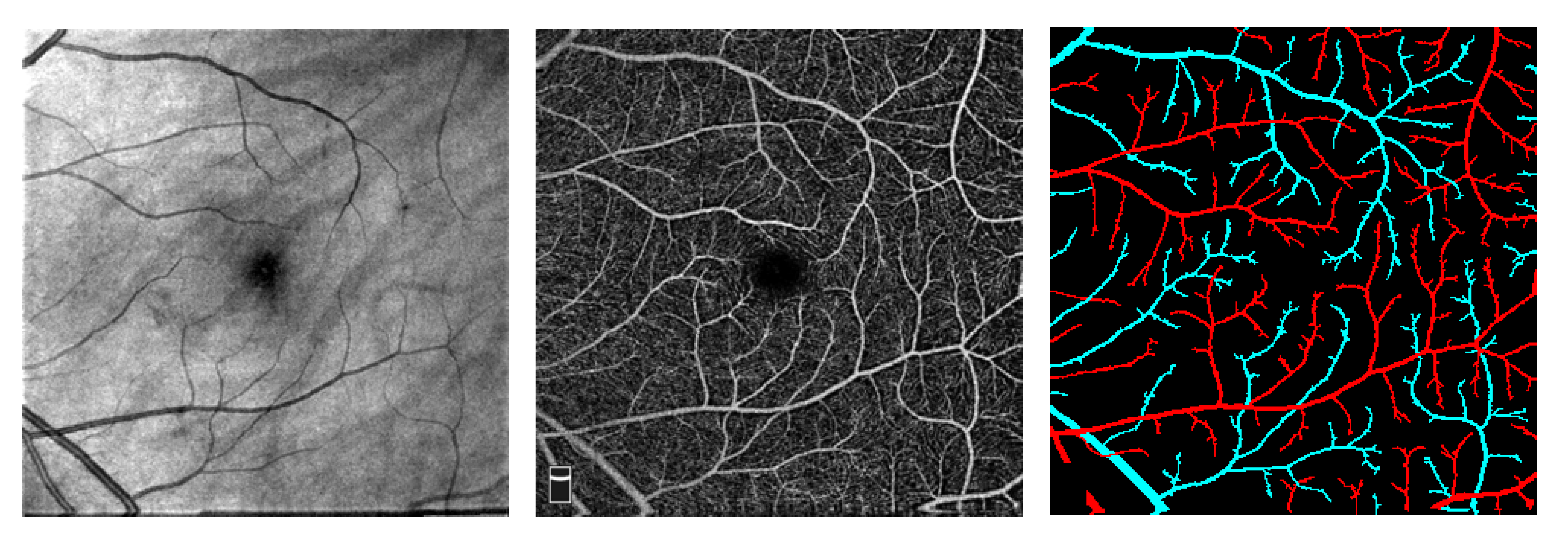
Images were acquired using the AngioVue SD-OCT device (Optovue, Fremont, CA, USA). The OCT system had a 70,000 Hz A-scan rate with ~5 μm axial and ~15 μm lateral resolutions. All en face OCT/OCTA images used for this study were 6 mm × 6 mm scans; only superficial OCTA images were used. The en face OCT was generated as a 3D projection of the retina slab. After image reconstruction, both en face OCT and OCTA were exported from ReVue software interface (Optovue) for further processing.
The MF-AV-Net is an FCN based on a modified UNet algorithm, which consists of an encoder-decoder architecture. The input to the MF-AV-Net can be of a single channel or a two-channel image. The network architecture presented below represents a late fusion approach that combines the outputs of two networks trained on different imaging modalities, OCT and OCTA, respectively.
- tensorflow >= 1.31.1
- keras >= 2.2.4
- python >= 3.7.1
Mansour Abtahi, David Le, Jennifer I. Lim, and Xincheng Yao, "MF-AV-Net: an open-source deep learning network with multimodal fusion options for artery-vein segmentation in OCT angiography," Biomed. Opt. Express 13, 4870-4888 (2022) https://doi.org/10.1364/BOE.468483