WFS File Storage System [中文文档]
primarily designed to address the challenges of storing massive amounts of small files. The WFS storage engine exhibits highly efficient read and write performance, achieving response times at the microsecond level even under high concurrency pressures.
The WFS storage engine exhibits highly efficient read and write performance, achieving response times at the microsecond level even under high concurrency pressures.
In various hardware environments and system architectures, storing a vast number of small files can lead to a series of significant problems. Whether using traditional Hard Disk Drives (HDDs) or modern Solid State Drives (SSDs), these issues may impact system performance, efficiency, scalability, and cost:
- Low Storage Efficiency: For any type of hard drive, small files typically result in inefficient use of physical storage space. Due to the smallest storage unit (sector or page) on a hard drive, small files might occupy more space than their actual content size, especially when additional metadata storage is required for each file, such as an inode (in Unix-like systems) or other forms of metadata records, which exacerbates space wastage. Inode Exhaustion: Each file and directory consumes at least one inode, with the total number of inodes set during disk formatting and file system creation. When there's an abundance of small files in a system, it could lead to the inability to create new files despite ample disk space, solely because all inodes have been used up, even though remaining disk space would be sufficient for more data. Performance Impact: As the number of inodes increases, finding and managing the metadata associated with these inodes becomes more complex and time-consuming, particularly for traditional file systems without efficient indexing mechanisms, affecting overall file system performance. Limited Scalability: File systems usually have a fixed maximum number of inodes that cannot be dynamically increased to accommodate the growth of small files unless special measures are taken, like adjusting the file system or specifying more inodes during reformatting.
- I/O Performance Bottlenecks and Resource Consumption: In HDD environments, random reading and writing of a large number of small files can lead to frequent disk seek operations, thereby reducing overall I/O performance. In SSD environments, while seek times are almost negligible, excessively dense access to small files can still cause controller pressure to increase, exacerbate write amplification effects, and intensify strain on garbage collection mechanisms.
- Indexing and Query Efficiency Issues: The presence of Massive small files poses challenges to the file system's indexing structure. As the number of files grows, metadata operations involved in searching, updating, and deleting small files become increasingly time-consuming. In scenarios requiring rapid retrieval and analysis, traditional indexing methods struggle to deliver efficient query services.
- Backup and Recovery Complexity and Efficiency: Backing up Massive small files is a tedious and time-consuming process. Moreover, during recovery, especially when restoring individual files on-demand, locating the target file among vast backup data significantly impacts recovery speed and efficiency.
- Scalability and Availability Challenges: Storing Massive small files can present scalability issues for storage systems. As the number of files increases, effectively allocating and managing resources to maintain good performance and stability becomes a major challenge. In distributed storage systems, hot spot issues may arise, causing certain nodes to experience excessive loads, impacting the overall stability and availability of the system.
The role of WFS is to efficiently compress and archive the Massive small files being stored, providing a streamlined method for data retrieval, as well as background file management, file defragmentation, and more.
The prevalence of massive small file scenarios in the Internet is ubiquitous across multiple domains:
-
Social Media & Image Sharing:
- Facebook: Facebook handles billions of user-uploaded photos and videos daily, with an average user uploading hundreds of images. Consequently, Facebook houses tens to hundreds of billions of images, necessitating the implementation of systems like Haystack to optimize storage efficiency and access speed.
- Instagram: Another popular social platform sees the upload of hundreds of millions of photos and videos each day. Despite their small individual sizes, the sheer volume requires highly efficient storage and retrieval mechanisms.
-
E-commerce & Product Display:
- Amazon: As one of the world's largest e-commerce platforms, Amazon boasts millions of product listings, each typically accompanied by several images. It processes billions of images daily, presenting substantial challenges for its storage system due to the vast quantity of small files involved.
- Taobao: As China's leading e-commerce site, Taobao stores billions of product images, most of which are small files. To cope with this scale, Taobao has developed optimized file systems to enhance storage efficiency and access rates.
-
Online Video & Streaming Media:
- Netflix: As a premier online video service provider, Netflix possesses an extensive video library with millions of users streaming content daily. Video files are often split into smaller segments to adapt to varying network conditions, resulting in an enormous amount of small files that demand a storage system with exceptional read/write performance and scalability.
-
High-Performance Computing & Scientific Data:
- Research Laboratories: In scientific research, rapid advancements have led to an exponential increase in data generation speeds. For instance, gene sequencing laboratories may produce several terabytes to tens of terabytes of data per day, typically stored as numerous small files. Thus, there is a significant demand for storing and managing these small files efficiently.
- Supercomputers: During large-scale scientific computations and simulations, supercomputers generate vast quantities of intermediate results and output files, many being small in size. Efficient storage and management of these files are critical to maintaining computational efficiency.
-
Finance & Bill Imaging:
- Major Banks: Major banking institutions process millions of financial documents daily, digitized as image files. With multiple images generated per document, a single large bank could be dealing with tens of millions of small image files daily, imposing high demands on storage system stability and performance despite their individual small sizes.
-
Online Education & Content Sharing:
- Platforms like Coursera and NetEase Cloud Classroom require the storage of copious course materials, including instructional videos, PPTs, and images, many of which are small files.
- Communities like Zhihu and Douban handle user-uploaded avatar images and pictures within posts, representing another common scenario for small file storage.
-
Messaging & Instant Messaging Services:
- In messaging and instant messaging apps (e.g., WeChat, WhatsApp), text messages, emojis, voice snippets, location data, and more are all considered small files. In group chats especially, there is a rapid proliferation of such small file data. The underlying storage systems must be adept at handling a deluge of small files while ensuring real-time responsiveness and high concurrency.
-
Web Hosting & CDN Services:
- In web hosting and Content Delivery Networks (CDNs), webpage elements such as CSS stylesheets, JavaScript scripts, icons, etc., are small files. A large website can easily contain tens of thousands of these. To provide quick loading times and high availability, providers must efficiently store and cache these small files, employing techniques like HTTP/2 server push, resource concatenation, and compression to reduce request numbers and boost transmission efficiency.
-
Genomic Sequencing Data Processing:
- In bioinformatics, genomic sequencing generates raw data composed of countless short sequence fragments, each essentially constituting a small file. Whole-genome datasets are monumental, involving millions to billions of small files. Genomic sequencing centers require high-performance storage systems capable of rapid data storage and analysis, often leveraging distributed storage systems combined with indexing structures to tackle the issue of large volumes of small files.
This overview illustrates the scale and significance of small file applications and underscores the urgent need for efficient storage and processing solutions in these sectors. With advancing technology and continuously expanding data volumes, this necessity is only set to grow.
In a large number of small file application scenarios, the key technologies of wfs implementation include the following aspects
-
Efficient Storage Layout and Aggregation Techniques: WFS consolidates multiple small files into larger ones for storage, thereby reducing metadata overhead and enhancing storage utilization. Additionally, it employs flexible indexing mechanisms to ensure that each individual small file can be quickly located and extracted as needed.
-
Distributed Storage Architecture: The wfs1.x version primarily focuses on performance enhancements tailored to specific use cases and recommends utilizing third-party load balancing distribution technologies like Nginx to scale horizontally by adding more nodes, thus addressing the storage needs of vast amounts of small files. This approach ensures system stability and performance under high concurrency scenarios.
-
Metadata Management Optimization: To tackle the challenge of managing metadata for a large number of small files, WFS adopts an efficient metadata indexing and caching strategy, reducing query time. It also uses hierarchical directory structures or hash indexes, among other methods, to simplify metadata storage complexity.
-
Cache and Prefetching Policies: An LRU (Least Recently Used) caching mechanism is introduced, caching frequently accessed data to reduce I/O operations and improve read speeds.
-
Data Deduplication and Compression Technologies: WFS implements data deduplication and compression, eliminating duplicate content and shrinking storage space consumption. Multi-level compression algorithms are employed to optimize storage efficiency further.
-
High Availability and Fault Tolerance Design: WFS supports metadata export and data import functionalities, enabling swift data recovery in case of failures, thus guaranteeing continuous system services and data integrity.
-
Massive Unstructured Data Storage:
- Social Media Content Storage: In social networking platforms where users upload millions of images, videos, logs, backup data, and static asset files every day, this solution is well-suited for the storage of a vast amount of unstructured data.
-
Efficient File Data Retrieval:
- Optimized File Access for Read-intensive Workloads: The wfs storage engine is capable of achieving a data read rate of over one million operations per second, making it particularly suitable for businesses that heavily rely on frequent file reading tasks.
-
Multifaceted Image Processing Needs:
- Built-in Image Processing Capabilities: wfs comes equipped with basic image processing functionality, making it ideal for businesses that have diverse requirements for image manipulation, such as resizing images for multiple dimensions, custom cropping, and more.
- WFS Source Code Address: https://github.com/donnie4w/wfs
- Go Client: https://github.com/donnie4w/wfs-goclient
- Rust Client: https://github.com/donnie4w/wfs-rsclient
- Java Client: https://github.com/donnie4w/wfs-jclient
- Python Client: https://github.com/donnie4w/wfs-pyclient
- Online WFS Demo: http://testwfs.tlnet.top (Username: admin, Password: 123)
- WFS User Manual: https://tlnet.top/wfsdoc
- High efficiency
- Simplicity
- Zero Dependency
- Interface Management
- Image processing
- File Handling
lease note that the following benchmark data is for the WFS data storage engine and does not take into account the impact of network factors. Under ideal conditions, estimated data is derived based on benchmark test results
Below is a screenshot of some of the pressure measurement data




- First column test method, write Append, read Get, *-4 quad-core, *-8 octa-core
- The second list is the total number of tests performed in this round
- ns/op: indicates the time consumed per execution
- B/op: Memory consumed per execution
- allocs/op: The number of memory allocations per execution
- Storage data performance estimation
- Benchmark_Append-4 The average number of operations performed per second is approximately:1 / (36489 ns/operation) ≈ 27405times/s
- Benchmark_Append-8 The average number of operations performed per second is approximately:1 / (31303 ns/operation) ≈ 31945times/s
- Benchmark_Append-4 The average number of operations performed per second is approximately:1 / (29300 ns/operation) ≈ 34129times/s
- Benchmark_Append-8 The average number of operations performed per second is approximately:1 / (24042 ns/operation) ≈ 41593times/s
- Benchmark_Append-4 The average number of operations performed per second is approximately:1 / (30784 ns/operation) ≈ 32484times/s
- Benchmark_Append-8 The average number of operations performed per second is approximately:1 / (30966 ns/operation) ≈ 32293times/s
- Benchmark_Append-4 The average number of operations performed per second is approximately:1 / (35859 ns/operation) ≈ 27920times/s
- Benchmark_Append-8 The average number of operations performed per second is approximately:1 / (33821 ns/operation) ≈ 29550times/s
- get data performance estimates
- Benchmark_Get-4 The average number of operations performed per second is approximately:1 / (921 ns/operation) ≈ 1085776times/s
- Benchmark_Get-8 The average number of operations performed per second is approximately:1 / (636 ns/operation) ≈ 1572327times/s
- Benchmark_Get-4 The average number of operations performed per second is approximately:1 / (1558 ns/operation) ≈ 641848times/s
- Benchmark_Get-8 The average number of operations performed per second is approximately:1 / (1296 ns/operation) ≈ 771604times/s
- Benchmark_Get-4 The average number of operations performed per second is approximately:1 / (1695 ns/operation) ≈ 589970times/s
- Benchmark_Get-8 The average number of operations performed per second is approximately:1 / (1402ns/operation) ≈ 713266times/s
- Benchmark_Get-4 The average number of operations performed per second is approximately:1 / (1865 ns/operation) ≈ 536000times/s
- Benchmark_Get-8 The average number of operations performed per second is approximately:1 / (1730 ns/operation) ≈ 578034times/s
Write data performance
- Under different concurrent conditions, the WFS storage engine performs write operations on average between about 30,000 and 40,000 times per second.
Read data performance
- The WFS storage engine performs even better data read operations, with an average of 530,000 to 1.5 million reads per second.
Please note: the test results are highly dependent on the environment. The actual application performance may be affected by many factors, such as system load, network status, and disk I/O performance. Therefore, you need to verify and tune the actual deployment based on the actual environment
original image: https://tlnet.top/statics/test/wfs_test.jpg

- Crop the center portion and scale down to produce a 200x200 thumbnail https://tlnet.top/statics/test/wfs_test.jpg?imageView2/1/w/200/h/200

- The width is fixed at 200px and the height is reduced in equal proportion to create a wide 200 thumbnail https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200

- The height is fixed at 200px and the width is reduced in equal proportions to produce a thumbnail with a height of 200 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/h/200

- Gaussian blur generates a picture with a blur level of Sigma 5 and a width of 200 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/blur/5

- Gray image, generate a gray, 200 wide image https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/grey/1

- Colors are reversed to produce a 200 wide image with opposite colors https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/invert/1

- Horizontal inversion, generate horizontal inversion, 200 width image https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/fliph/1

- Vertical inversion, generate vertical inversion, width 200 image https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/flipv/1

- The image is rotated to generate an image that is rotated 45 degrees to the left and 200 width https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/rotate/45

- Format conversion to generate a 200 width png image rotated to the left by 45 https://tlnet.top/statics/test/wfs_test.jpg?imageView2/2/w/200/rotate/45/format/png

Image processing methods are outlined in the wfs usage documentation
-
Execute file download address:https://tlnet.top/download
-
start wfs: ./linux101_wfs -c wfs.json
-
wfs.json configuration instruction
{
"listen": 4660,
"opaddr": ":6802",
"webaddr": ":6801",
"memLimit": 128,
"data.maxsize": 10000,
"filesize": 100,
}Attribute description
- listen the listening port of the http/https resource obtaining service
- opaddr thrift Address of the back-end resource operation
- webaddr Specifies the address of the management background service
- memLimit Maximum wfs memory allocation (unit: MB)
- data.maxsize Upper limit of wfs image size to be uploaded (unit: KB)
- filesize Upper limit of wfs back-end archive filesize (unit: MB)
Please refer to the wfs usage documentation for detailed instructions on wfs usage documentation
- http/https
curl -F "file=@1.jpg" "http://127.0.0.1:6801/append/test/1.jpg" -H "username:admin" -H "password:123"curl -X DELETE "http://127.0.0.1:6801/delete/test/1.jpg" -H "username:admin" -H "password:123"- using the client
public void append() throws WfsException, IOException {
String dir = System.getProperty("user.dir") + "/src/test/java/io/github/donnie4w/wfs/test/";
WfsClient wc = newClient();
WfsFile wf = new WfsFile();
wf.setName("test/java/1.jpeg");
wf.setData(Files.readAllBytes(Paths.get(dir + "1.jpeg")));
wc.append(wf);
}- The following is a java client example
Default search
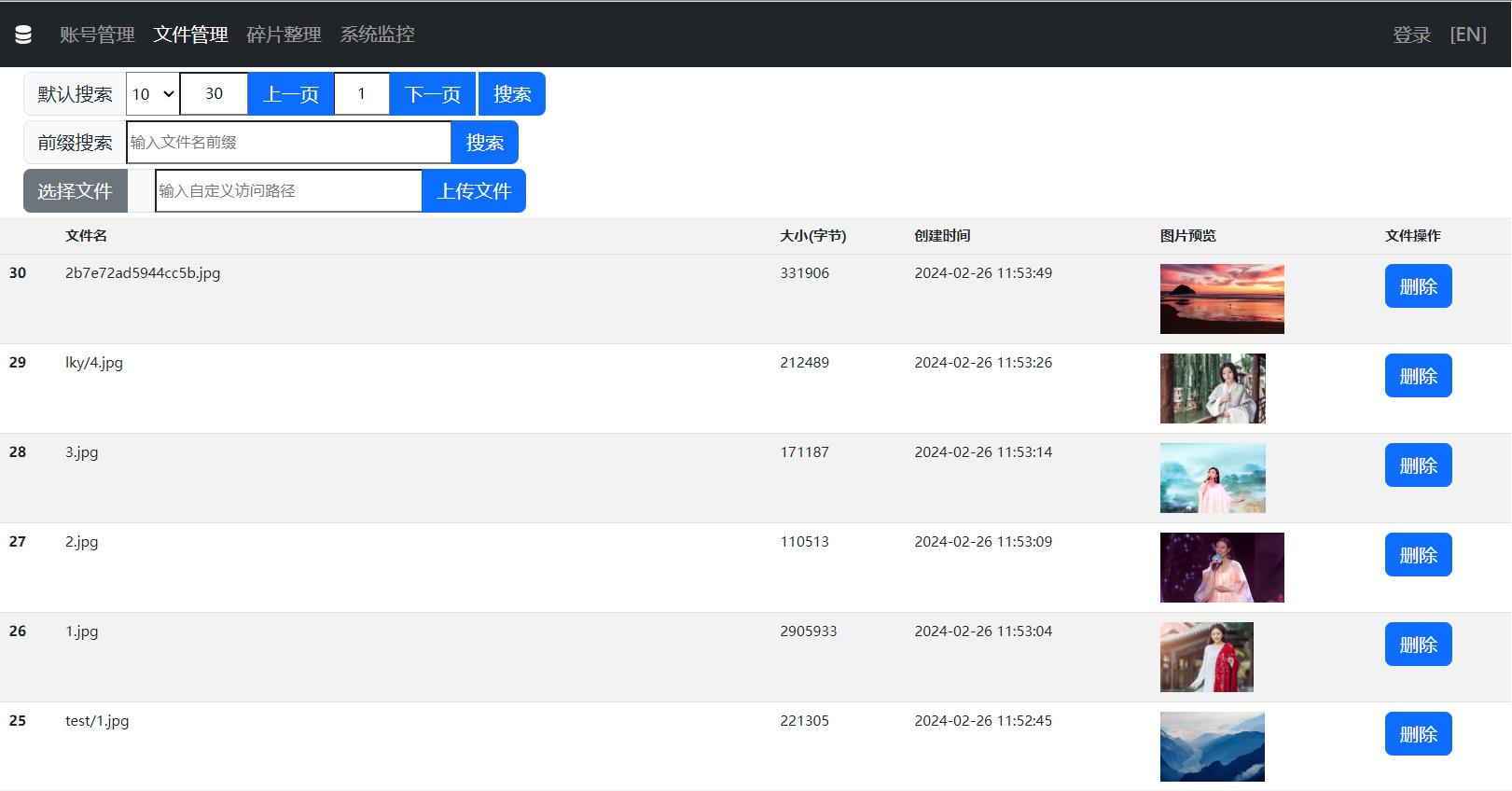
Prefix search

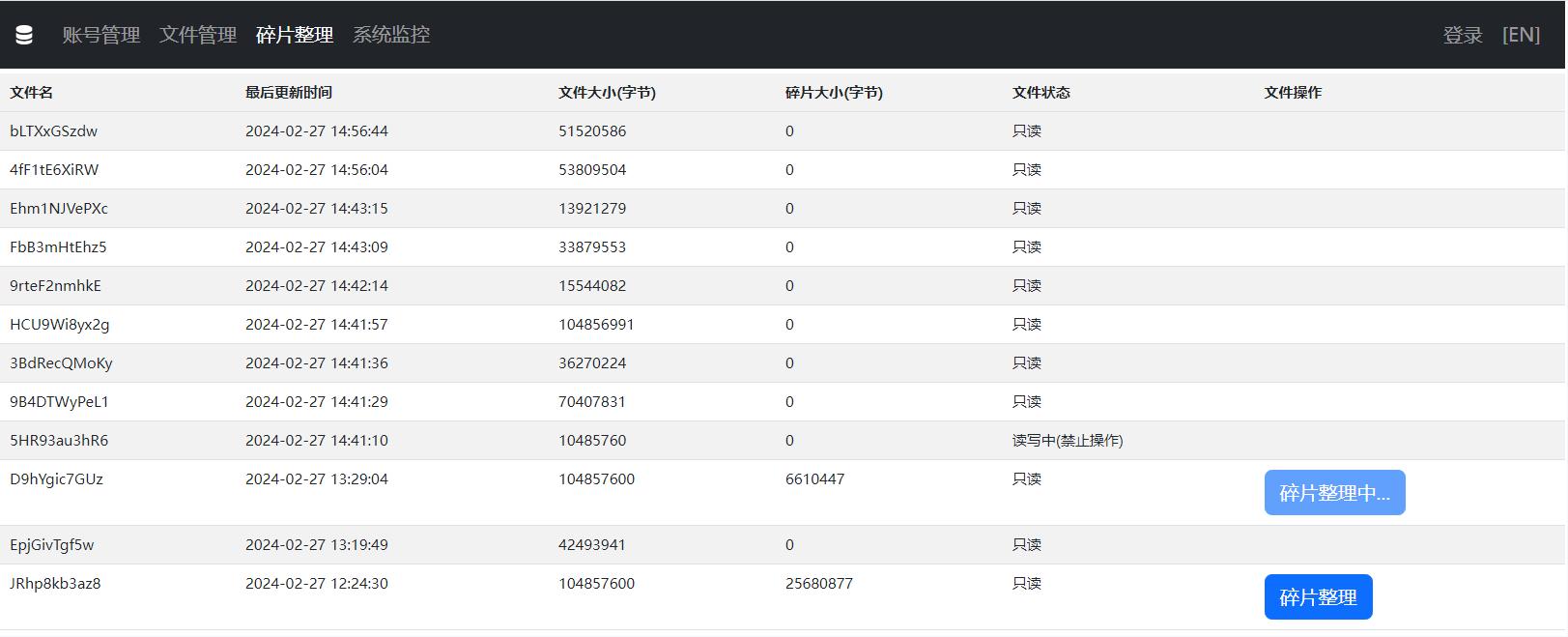
defragment
Explanation of Design Changes from WFS 0.x to WFS 1.x: The WFS 0.x version implemented distributed storage, enabling the system to disperse and process data across multiple servers, thereby possessing horizontal scalability and data backup redundancy capabilities. However, practical applications exposed certain issues, such as low space utilization due to duplicated metadata storage and inefficiency in handling small files due to frequent forwarding and transmission between nodes, which increased system resource consumption.
The goal of WFS 1.x is to meet specific application scenario requirements through streamlined architecture and a focus on performance improvement. As for considerations regarding distributed deployment, users are entrusted to leverage third-party tools and services to achieve this functionality.
- WFS 1.x does not directly support distributed storage; however, to address large-scale deployment and high-availability needs, it recommends using load balancing services like Nginx. By configuring resources and positioning strategies appropriately, a logically similar distributed effect can be emulated. Each WFS instance stores data independently, but external services can distribute requests among multiple WFS instances, achieving a "distributed deployment" at the business level. For guidance on how to implement the "distributed deployment" of WFS, refer to the article 'The Distributed Deployment Solution for WFS'
- It must be emphasized that distributed systems have significant advantages in ultra-large scale data storage operations, including dynamic resource allocation, block-level data storage, and multi-node backups. Nonetheless, with WFS 1.x adopting a load balancing strategy, users need to take measures to ensure data security and high availability themselves. This includes regular data backups, setting up a load balancing cluster, and configuring and designing routing rules within applications to guarantee that data is correctly routed to the intended nodes.
- The strength of WFS lies in its simplicity and efficiency. Not every file storage service requires a complex distributed file system. In fact, most businesses have not yet reached an ultra-large scale, and using a sophisticated distributed file system may introduce disproportionately high additional costs and operational complexity. Currently, WFS and its corresponding distributed deployment strategies adequately satisfy various business demands.