Draft PR for CoreCLR vectorized sorting #33152
Conversation
|
@damageboy, did you happen to collect any numbers on the performance of just using |
| { | ||
| fixed (int* startPtr = &Unsafe.As<T, int>(ref keys[0])) | ||
| { | ||
| var sorter = new VectorizedSort.VectorizedUnstableSortInt32(startPtr, keys.Length); |
There was a problem hiding this comment.
Reading through the paper and blog, it looks like the algorithms for different sizes are basically the same, just with different lookup tables and increment sizes. Is that correct?
There was a problem hiding this comment.
I assume that by different sizes you mean different types?
If so, then:
- unsigned sorting requires two lookup-tables (at least according to my plan), per size, but one of those tables is the one used by signed sorting.
- I can get into this when we want to dive into my "plans" for unsigned sorting.
floatwould share the table withint- and so one per type/size in bits, so:
- Two more tables to support
long/ulong - an so on per 16, 8 bits
- Two more tables to support
Does that answer your question?
There was a problem hiding this comment.
The question was more around if the primary difference between int and short was just around the lookup table and not necessarily the algorithm used for sorting (other than the number of elements processes "per iteration")?
Trying to understand if supporting the other types would result in a code explosion or if most of the algorithm could be shared, just passing in different increment sizes and lookup tables (and calling a different instruction for the permutations).
There was a problem hiding this comment.
In that case, I think all signed + floating types would:
- definitely share the exact same principle
- could potentially share one managed implementation
- Would definitely blow up in native code size
- Require a table per size (bytes and shorts are kind of annoying, TBH, but we'll get into that later)
Unsigned sorting has its own complexity, so it would definitely share 1/2 of the lookup tables and the same concepts, but perhaps different managed code.
Unfortunately, a lot of the code ends up being type-dependent because of the comparison intrinsic. The same blowup "problem" is unfortunately also true for BitonicSort.
My "issue" with code-size considerations and the potential blow-up is that there is no clear "formula" to what is acceptable. How much perf increase is worth how much blow-up in code-size? This is part of where I hope this discussion will take us...
The reality is that there are a few dozen working points in terms of various algorithm selection (for small array sorting) and unroll size tweaks that could substantially decrease the native code-size, while still providing reasonable speed-up.
It would be very helpful to try to come up with a some sort of a formula for thinking about this...
It is also probably a good time to mention that, quite surprisingly, a future AVX512 dotnet enabled runtime would lead to completely removing the look-up tables as VCOMPRESS* basically kills the need for the permutation primitive + table.
I did not test This is a slightly complicated argument, so I'll do my best not to butcher it: My (only working) mitigation to this (I tried a few...), was to unroll the code. So really, through unrolling, I'm reducing the impact of what is an almost assured 50% (ish) misprediction rate. In addition, I ended up "compressing" the look-up tables to 2KB by using |
|
Thanks for the explanation! If we don't have numbers, that is fine. We just won't be able to take it into consideration during review 😄 For reference, I was interested for a few reasons:
|
Just to be clear, a lot of sweat went into ensuring there are no unaligned loads. Almost ever. |
|
This is definitely nice use of the hardware intrinsics. Thank you for doing this! It is a lot of code and I do not think that sorting Int32s is common enough to include this amount of code in the platform. Would you consider starting a new NuGet package so that people who need fast sorting can opt-in into it? There are other types of optimizations that can be used to speed up sorting of large dataset, e.g. running it on multiple threads at the same time, etc. |
This already outside of the runtime repo as a nuget package: This isn’t about int32 per-se but more as a general approach to sorting and should be considered as a “template” for how per-type vectorized sorting could end up looking. Therefore this (or another more cut down version) would end up being generated into 10 multiple per-type implementations (for all native types). There is no native type this approach does not cover as a rule. I’m perfectly fine with keeping it as is, evolving the code outside of the runtime repo, and would completely understand if you would think this is just “too much” for the runtime to absorb and maintain. I intentionally submitted my most extreme implementation (in terms of code size blowup/speedup) as a starting point (and quite possibly an ending point ;) for discussion about what, if at all, is possible to incorporate into the runtime. If the bar is set at 0 machine code size increase no matter what the perf bump is (which I presume is not the case...) I would simply close the issue and be done with it. If on the other hand there is some acceptable trade-off that could be formulated for just how much code size increase is acceptable for how much speedup I would love to a) hear about it b) see if I can wiggle my implementation into that constraint. Regardless, the general template would remain as-is in many of the overall aspects such as memory pinning, use of unsafe, reliance on lookup tables, etc. I hope this clarifies my intention with this draft PR. I definitely agree that covering only a single type would not be very appealing. As for parallelization, I don’t see any contradictions between speeding up single threaded sorting by 11x (or likely around 25x with AVX512 in the future) and parallelizing using multiple cores. |
Perfect!
We do look at multiple factors when evaluating performance improvements that come with non-trivial code size increase:
I think it would be hard to fit this type of change into a reasonable budget given the benefits it has for typical app. Having it in independent package seems to be the best option for me. Maybe we can help with promoting your great work (Twitter, Channel 9, …)? Send me an email if you are interested – my email address is in my github profile. |
Thanks for the input!
As for the code-size blow-up:
I think a reasonable compromise could be found here. As an anecdotal example, around this September, I was unrolling by 6x unroll with a different small-sorting algorithm and had a 6-7x speed-up but generating ~1/3 of the native code size of what I've provided in this PR. In other words: YMMV. I could obviously go back to my evil lair, do much more brute-force research, creating a 10x10 matrix of speed-ups/code-size sometime by 2022 :). But given some sort of firmer idea/guidance of the kind of budget you'd consider reasonable for this, I might be able to converge on something faster, or give-up more quickly :) P.S.: |
You can say the same thing about e.g. |
Sure, but for I don't expect to be living in a world without limitations, but would just like to get some sort of feel/guidance to what those limitations are. As a very crude example, we could come with a fictional: as a silly ratio to describe some acceptance number of even curve (over input size as a parameter). One such possible curve/number would 0, where no code-size-increase is ever allowed, no matter what the speed-up is. I am pretty sure this is not what you had in mind. Another possible one be the number 1. This is probably also pretty extreme, to the other end of the spectrum, since it might allow increasing the code size by a factor of 11x to get an 11x perf bump :) I'm also not claiming that there is a single number for all functions, but its been roughly 6 comments into this discussion and we are nowhere near to even understanding what that number might look like for Unless you are basically saying that the number you had in mind is ~ P.S.: I mean, in the end of the day if, someone bothered to call |
This is actually super interesting... Both for me, and I also think that for the community at large. Are we talking about stack traces from 1000s of cores running bing search or customer workloads? Or alternatively, are we talking about VS-intellisense-in-the-cloud like data generated from what people type in their VS? This would, on the other hand, mean something completely different, as that would be possible that code like: if (input.IndexOf('😕') ||
input.IndexOf('😢') ||
input.IndexOf('😞') ||
input.IndexOf('😒')) { ... }definitely makes it look like Array.Sort(_oneHundredMillionIntegersMuhhahahaha); |
Anecdotic I know, but I have implemented over my work time in .Net (since the early days of 1.1) at least 6 |
|
Could this be combined with TimSort? TimSort is a "practical" sorting algorithm that takes advantage of patterns that are commonly found in real-world data. I believe, it mostly takes advantage of already sorted subranges. |
Is used heavily according to API Port; though doesn't say what data type
|

|
API Port indicates it is referenced. It doesn't indicate it is hot, or even called, in those applications. |
We have data about where Azure cloud services spend time inside .NET. This telemetry is enabled only for code that is owned by Microsoft. We take privacy and confidentiality very seriously. Collecting this data for customer workloads would not be acceptable. It is aggregate over thousands of individual cloud services written by hundreds of teams running on many thousands of machines. You can think about it as attaching profiler to every machine for random 5 minutes each day. I am not able to share the raw data, but I can share answers to questions like what is relative time spent in one API vs. other API. Many of the performance improvements are motivated or influenced by insights we get from this data. For example, the recent batch of major regular expression improvements was largely motivated and influenced by this data.
If you find these without a good workaround, we would like to know. |
Don't worry, you will ;) .. that doesn't change the fact that I would seriously want to avoid having to rebuild something as foundational as |
|
If the code size increase is too big, perhaps we should consider introducing a As of today, there is plenty of libraries that implement it on their own, a good example is ML.NET: https://github.com/dotnet/machinelearning/tree/master/src/Microsoft.ML.CpuMath If we had all of these in one place, our customers would no longer need to implement it on their own. This would decrease the number of bugs and improve the time to market (as an app|system developer you want to reuse existing blocks and put them together to solve the business problem, not reimplement well know algos on your own). It would be also a clear tradeoff for the users: you get improved performance for the price of the bigger size of your app. @tannergooding @jkotas @danmosemsft what do you think? |
Where do you set the bar that the operations are popular enough to be included in this library? As I have said, sorting of primitive types does not have enough use across .NET apps. I believe that focused independent packages like VxSort are the best way to address the general need for alternative implementations with different trade-offs. |
|
I guess one drawback of making this a separate package is that the benefits would not be available to built in collections which call Array.Sort internally: SortedSet, SortedList, List, ImmutableArray, ImmutableList, or ArraySortHelper for Span with its own sort. Shouldn't a good linker do tree pruning and remove the sort implementation entirely from the output binary if it is not used by the user program? On a more general note though, as interesting as this is, sorting by primitives (at least in my use cases) is not useful with in-place sorting. The more general use case is for indexing into another collection. If we would have Arrays of Structs (i.e. like DataFrame), perhaps we could use a fast vectorized sort to maintain e.g. ordering by useful primitives, such as int/long/float/doubleDateTime. So, rather than sorting values in-place, it would be preferable to instead have an output array that gives indices into the original array in a sorted order. This index array would be pre-allocated and probably overwritten on each re-sort. This would allow it to work with column-based storage, like in DataFrame where primitives are arranged in a vectorization friendly way. Effectively, replacing/improving IntrospectiveSort in DataFrameColumn.cs: Perhaps this belongs inside Microsoft.Data.Analysis? |
Sorting is referenced by typical program so it cannot be removed. But typical program spends minuscule amount of time in it. |
That was essentially my point when I pointed out that |
|
FWIW, I have looked at everything with "sort" in the name, including unmanaged sort implementations like qsort from C-runtime, and filtering out false positives like "ProcessorThread". It did not add up to anything significant for primitive types even when all taken together. Another interesting bit of data is that there are more cycles spent in |
|
Great work by @damageboy indeed 👍. Related to this I have a question and concern I also voiced in damageboy/VxSort#12, is "unsafe" code acceptable in the sorting code? When I tried getting my version of managed sort rewrite for If it isn't at least at that time there were things that could be done to speed up |
Yes, it is still valid. Somebody would need to do detailed security review of this and it would probably need additional security focused testing (fuzzing, etc.). |
|
Commenting here due to the twitter thread: https://twitter.com/damageboy/status/1236660790112985090?s=20 The term "code size" has been thrown around a bit up above but my understanding is that this (and most other) PR(s) going in has little to do with the code size increase. Instead it has to do with the increased complexity of the code being submitted and therefore the increased maintenance cost on that code moving forward. That is, a PR which reduced the size of the code but made it more complex (such as using magic numbers or specialized tricks, etc) might likewise be rejected, even if it made it faster. Code size does have some impact, as bigger code can be (and is typically) harder to rationalize overall, but that isn't always the case. We are then looking at how widely used a given method is and how frequently it is used in hot paths to determine whether the increased cost of the new code makes it "worthwhile" and that isn't easily quantified. Based on the current metrics we have, In the terms of this PR:
So based on the metrics we have, it is difficult to justify the increased maintenance cost of the code due to the perceived limited usage of Array.Sort in perf critical scenarios and it is difficult to concretely specify what amount of change would be acceptable. Is that about right @jkotas, @damageboy ? |
|
@tannergooding: I personally agree with everything you said in the comment above. My only "objection" is to the "metrics" theme. I do find it very weird to talk about sorting numbers as something even requiring metrics. |
Could a form; in addition, be done for Sse (or whatever the R2R baseline is) and would that be desirable? |
Just looking at https://source.dot.net/#q=Sort, most of the core .NET Libraries go through |
@tannergooding Yes, thank you for writing a great summary.
Among the different arguments, not being able to precompile AVX code with R2R today is less important to me. I expect that we are going to be able to do that eventually.
+1 ML.NET and DataFrame have its own copy of sort because of they need to sort Spans, but still need to target netstandard2.0. WPF has insertion sort optimized for small number of elements in C++. |
|
@tannergooding Thanks again for helping to calrify where everyone stands. The only argument I would never even plan on having is about telling other people what complexity they should pile on their side on their repo, be it Microsoft or anyone else. I think it would be helpful, in the future, to communicate more clearly about when the issue at hand is about code-size/bloat, which at least for me, and I suspect for many others, is/was a technical metric that can be discussed, measured and reasoned about and is not to be conflated with code-complexity which can often grow even as code-size is reduced... I'll close the issue now, continue my work on the blog series and then on generalizing VxSort. |
|
This thread and comments from people more knowledgeable than me, made me think that best approach would be to have plug-in able sorting strategy in core libraries and it's collections. Then 3rd party sorting algorithms could be 1st class citizens. |
Hi everyone.
This is the culmination of lots of lonely nights of research and what has become (also) a separate nuget packge for sorting primitives with Avx2 intrinsitcs.
I'm submitting this for high-level discussion about the approach and if this sort of code even fits inside something like the dotnet runtime, rather than discussion on the code style and the little duplicated code that still exists between this PR and the current Span based
Array.Sortimplementation.The current PR only deals with the
Int32case, although there is no reason why other, very similar versions would not handle all the rest of the native types supported by .NET/C#.The entire concept and optimization journey is depicted in quite a lot of detail and even with animations in my blog post series "This goes to 11". Some of the more convoluted pieces of optimized code+approach will be described in parts 4,5 or this series which I intend to release this weekend.
In general, this provides a 11x-ish speedup for the
Int32sorting in pure unsafe, intrinsics + AVX2 C# code. To be clear, this means that a 10M integer sort that usually takes around 800ms on most modern machines becomes a 70ish ms ordeal. I'll immediately cut to the chase and describe what I perceive to be the potential pain points of this approach as a default implementation inside of CoreCLR:Int32versionInt32, (additional tables will be required for per word-size)int/uint/floatcan all share one lookup-table and so on...On the other hand, there are also pros:
The current code employs a hybrid approach, much like introspective sort does, that is combined of:
112-152elements using a special vectorized partitioning function>= 152elements with an uber-optimized and unrolled versionHere is a teaser for my results when running on a modern AMD 3950x machine although my blog posts do a much better job in providing the various results:
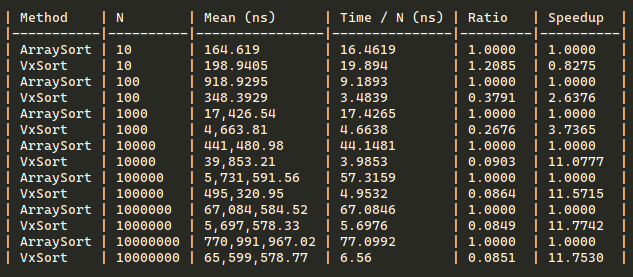
I obviously expect a lot of discussion about what, if any of this, should ever go into CoreCLR, and am happy to change my approach to provide some (even if lower) speed-up for all CoreCLR users rather than users of my niche library.
I really don't know where to start with a review like this, so... here goes?
/cc: @jkotas @stephentoub @tannergooding @adamsitnik @GrabYourPitchforks @benaadams
I should mention that there is still one (1) outstanding caveat within the
Int32sorting space that I need to take care of: this has to do with accepting memory/pointers that are not natively aligned toInt32size (4 bytes). There is a single (substantial) optimization that would have to be skipped in the beginning of each partitioning call, but that is a rather minor issue to deal with in general, and would actually make reviewing the code+approach harder at this point, so I actively precluded myself from handling that caveat in this draft PR.