Improve performance of Span.Clear #51534
Conversation
|
Tagging subscribers to this area: @GrabYourPitchforks, @carlossanlop Issue DetailsFollowup to #51365, this time focusing on Also clarified a comment in /cc @carlossanlop @jozkee
|
|
Perf results below for clearing a
Codegen (x64) and some brief inspection: 00007ffa`4b76cec0 c5f877 vzeroupper
00007ffa`4b76cec3 4883fa04 cmp rdx, 4
00007ffa`4b76cec7 726a jb System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x73 (00007ffa`4b76cf33)
00007ffa`4b76cec9 c4e17c57c0 vxorps ymm0, ymm0, ymm0
00007ffa`4b76cece c4e17d1101 vmovupd ymmword ptr [rcx], ymm0
00007ffa`4b76ced3 488bc1 mov rax, rcx
00007ffa`4b76ced6 4883e01f and rax, 1Fh
00007ffa`4b76ceda 488d54d0e0 lea rdx, [rax+rdx*8-20h]
00007ffa`4b76cedf 4883c120 add rcx, 20h
00007ffa`4b76cee3 482bc8 sub rcx, rax
00007ffa`4b76cee6 33c0 xor eax, eax
00007ffa`4b76cee8 4883fa40 cmp rdx, 40h
00007ffa`4b76ceec 722a jb System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x58 (00007ffa`4b76cf18)
00007ffa`4b76ceee 4c8bc2 mov r8, rdx
00007ffa`4b76cef1 4983e0c0 and r8, 0FFFFFFFFFFFFFFC0h
00007ffa`4b76cef5 6666660f1f840000000000 nop word ptr [rax+rax]
; body of "write 2" loop
00007ffa`4b76cf00 c5fd110401 vmovupd ymmword ptr [rcx+rax], ymm0
00007ffa`4b76cf05 4c8d4820 lea r9, [rax+20h] ; this really should be folded into the instruction below, Span<T>.Fill exhibits same behavior
00007ffa`4b76cf09 c4a17d110409 vmovupd ymmword ptr [rcx+r9], ymm0
00007ffa`4b76cf0f 4883c040 add rax, 40h
00007ffa`4b76cf13 493bc0 cmp rax, r8
00007ffa`4b76cf16 72e8 jb System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x40 (00007ffa`4b76cf00)
00007ffa`4b76cf18 448bc2 mov r8d, edx ; unnecessary mov, but cheap, so whatever
00007ffa`4b76cf1b 41f6c020 test r8b, 20h
00007ffa`4b76cf1f 7405 je System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x66 (00007ffa`4b76cf26)
00007ffa`4b76cf21 c5fd110401 vmovupd ymmword ptr [rcx+rax], ymm0
00007ffa`4b76cf26 4883c2e0 add rdx, 0FFFFFFFFFFFFFFE0h ; this really should be folded into the instruction below, Span<T>.Fill exhibits same behavior
00007ffa`4b76cf2a c5fd110411 vmovupd ymmword ptr [rcx+rdx], ymm0
00007ffa`4b76cf2f c5f877 vzeroupper
00007ffa`4b76cf32 c3 ret
;; start of "can't vectorize" logic
00007ffa`4b76cf33 33c0 xor eax, eax
00007ffa`4b76cf35 448bc2 mov r8d, edx
00007ffa`4b76cf38 41f6c002 test r8b, 2
00007ffa`4b76cf3c 740e je System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x8c (00007ffa`4b76cf4c)
00007ffa`4b76cf3e 33c0 xor eax, eax ; this is redundant but cheap
00007ffa`4b76cf40 488901 mov qword ptr [rcx], rax
00007ffa`4b76cf43 48894108 mov qword ptr [rcx+8], rax
00007ffa`4b76cf47 b802000000 mov eax, 2
00007ffa`4b76cf4c f6c201 test dl, 1
00007ffa`4b76cf4f 7406 je System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x97 (00007ffa`4b76cf57)
00007ffa`4b76cf51 33d2 xor edx, edx
00007ffa`4b76cf53 488914c1 mov qword ptr [rcx+rax*8], rdx
00007ffa`4b76cf57 c5f877 vzeroupper
00007ffa`4b76cf5a c3 ret |
| Unsafe.Add(ref ip, 3) = default; | ||
| Unsafe.Add(ref Unsafe.Add(ref ip, (nint)pointerSizeLength), -3) = default; | ||
| Unsafe.Add(ref Unsafe.Add(ref ip, (nint)pointerSizeLength), -2) = default; | ||
| if (!Vector.IsHardwareAccelerated || Vector<byte>.Count / sizeof(IntPtr) > 8) // JIT turns this into constant true or false |
There was a problem hiding this comment.
I'm missing it... why is this check necessary?
There was a problem hiding this comment.
JIT won't properly elide the following if without this check. Here's the codegen if this and the similar check a few lines down are removed. The fallback logic becomes much larger. But note that blocks d07b - d0ba and blocks d0c1 - d0e2 will never be executed. The explicit if in the code above is hinting to JIT that it shouldn't worry about this scenario. (That's also the crux behind the "skip this check if..." comments above these lines, but I can wordsmith if necessary.)
00007ffa`30eed000 c5f877 vzeroupper
00007ffa`30eed003 4883fa04 cmp rdx, 4
00007ffa`30eed007 726a jb System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x73 (00007ffa`30eed073)
;; BEGIN MAIN VECTOR LOGIC
00007ffa`30eed009 c4e17c57c0 vxorps ymm0, ymm0, ymm0
00007ffa`30eed00e c4e17d1101 vmovupd ymmword ptr [rcx], ymm0
; <snip>
00007ffa`30eed06f c5f877 vzeroupper
00007ffa`30eed072 c3 ret
;; END MAIN VECTOR LOGIC
;; BEGIN FALLBACK LOGIC
00007ffa`30eed073 33c0 xor eax, eax
00007ffa`30eed075 4883fa08 cmp rdx, 8 ; rdx can never be < 8 (see lines d003 - d007 earlier)
00007ffa`30eed079 7241 jb System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0xbc (00007ffa`30eed0bc)
00007ffa`30eed07b 4c8bc2 mov r8, rdx
00007ffa`30eed07e 4983e0f8 and r8, 0FFFFFFFFFFFFFFF8h
00007ffa`30eed082 4c8bc8 mov r9, rax
00007ffa`30eed085 49c1e103 shl r9, 3
00007ffa`30eed089 4533d2 xor r10d, r10d
00007ffa`30eed08c 4e891409 mov qword ptr [rcx+r9], r10
00007ffa`30eed090 4e89540908 mov qword ptr [rcx+r9+8], r10
00007ffa`30eed095 4e89540910 mov qword ptr [rcx+r9+10h], r10
00007ffa`30eed09a 4e89540918 mov qword ptr [rcx+r9+18h], r10
00007ffa`30eed09f 4e89540920 mov qword ptr [rcx+r9+20h], r10
00007ffa`30eed0a4 4e89540928 mov qword ptr [rcx+r9+28h], r10
00007ffa`30eed0a9 4e89540930 mov qword ptr [rcx+r9+30h], r10
00007ffa`30eed0ae 4e89540938 mov qword ptr [rcx+r9+38h], r10
00007ffa`30eed0b3 4883c008 add rax, 8
00007ffa`30eed0b7 493bc0 cmp rax, r8
00007ffa`30eed0ba 72c6 jb System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x82 (00007ffa`30eed082)
00007ffa`30eed0bc f6c204 test dl, 4 ; rdx & 4 will always result in 0 (see lines d003 - d007 earlier)
00007ffa`30eed0bf 7421 je System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0xe2 (00007ffa`30eed0e2)
00007ffa`30eed0c1 4c8bc0 mov r8, rax
00007ffa`30eed0c4 49c1e003 shl r8, 3
00007ffa`30eed0c8 4533c9 xor r9d, r9d
00007ffa`30eed0cb 4e890c01 mov qword ptr [rcx+r8], r9
00007ffa`30eed0cf 4e894c0108 mov qword ptr [rcx+r8+8], r9
00007ffa`30eed0d4 4e894c0110 mov qword ptr [rcx+r8+10h], r9
00007ffa`30eed0d9 4e894c0118 mov qword ptr [rcx+r8+18h], r9
00007ffa`30eed0de 4883c004 add rax, 4
00007ffa`30eed0e2 f6c202 test dl, 2
00007ffa`30eed0e5 7417 je System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0xfe (00007ffa`30eed0fe)
00007ffa`30eed0e7 4c8bc0 mov r8, rax
00007ffa`30eed0ea 49c1e003 shl r8, 3
00007ffa`30eed0ee 4533c9 xor r9d, r9d
00007ffa`30eed0f1 4e890c01 mov qword ptr [rcx+r8], r9
00007ffa`30eed0f5 4e894c0108 mov qword ptr [rcx+r8+8], r9
00007ffa`30eed0fa 4883c002 add rax, 2
00007ffa`30eed0fe f6c201 test dl, 1
00007ffa`30eed101 7406 je System_Private_CoreLib!System.SpanHelpers.ClearWithReferences(IntPtr ByRef, UIntPtr)+0x109 (00007ffa`30eed109)
00007ffa`30eed103 33d2 xor edx, edx
00007ffa`30eed105 488914c1 mov qword ptr [rcx+rax*8], rdx
00007ffa`30eed109 c5f877 vzeroupper
00007ffa`30eed10c c3 ret|
Is it necessary to check generated code for ARM64 too? That's arguably as important as x64 these days and I'm guessing codegen is still a bit less mature (?) |
I'm not yet skilled in reading arm64 code, so I wouldn't be able to pass judgment on it. Figured that the benchmarks repo would pick up any regressions. |
| goto Write1; | ||
| Vector<byte> zero = default; | ||
| ref byte refDataAsBytes = ref Unsafe.As<IntPtr, byte>(ref ip); | ||
| Unsafe.WriteUnaligned(ref refDataAsBytes, zero); |
There was a problem hiding this comment.
This assumes that Unsafe.WriteUnaligned is atomic for hardware accelerated vectors. It is not a safe assumption to make in general. It may the reason for the failing Mono tests.
There was a problem hiding this comment.
It doesn't need to be atomic across the entire vector. It only needs to be atomic at a native word granularity. @tannergooding might know more, but I believe every retail or microprocessor in the market provides this guarantee.
There was a problem hiding this comment.
You are making assumption about the instruction that this is going to compile into.
The compiler (LLVM in this case) is free to compile this into byte-at-a-time copy, especially with optimizations off.
There was a problem hiding this comment.
Also, IL interpretter is unlikely to execute this atomically either.
There was a problem hiding this comment.
If you would like to keep this, I think you may need #define ATOMIC_UNALIGNED_VECTOR_OPERATIONS that won't be set for MONO.
There was a problem hiding this comment.
Does the ARM spec actually guarantee this?
Yes for ARM64. 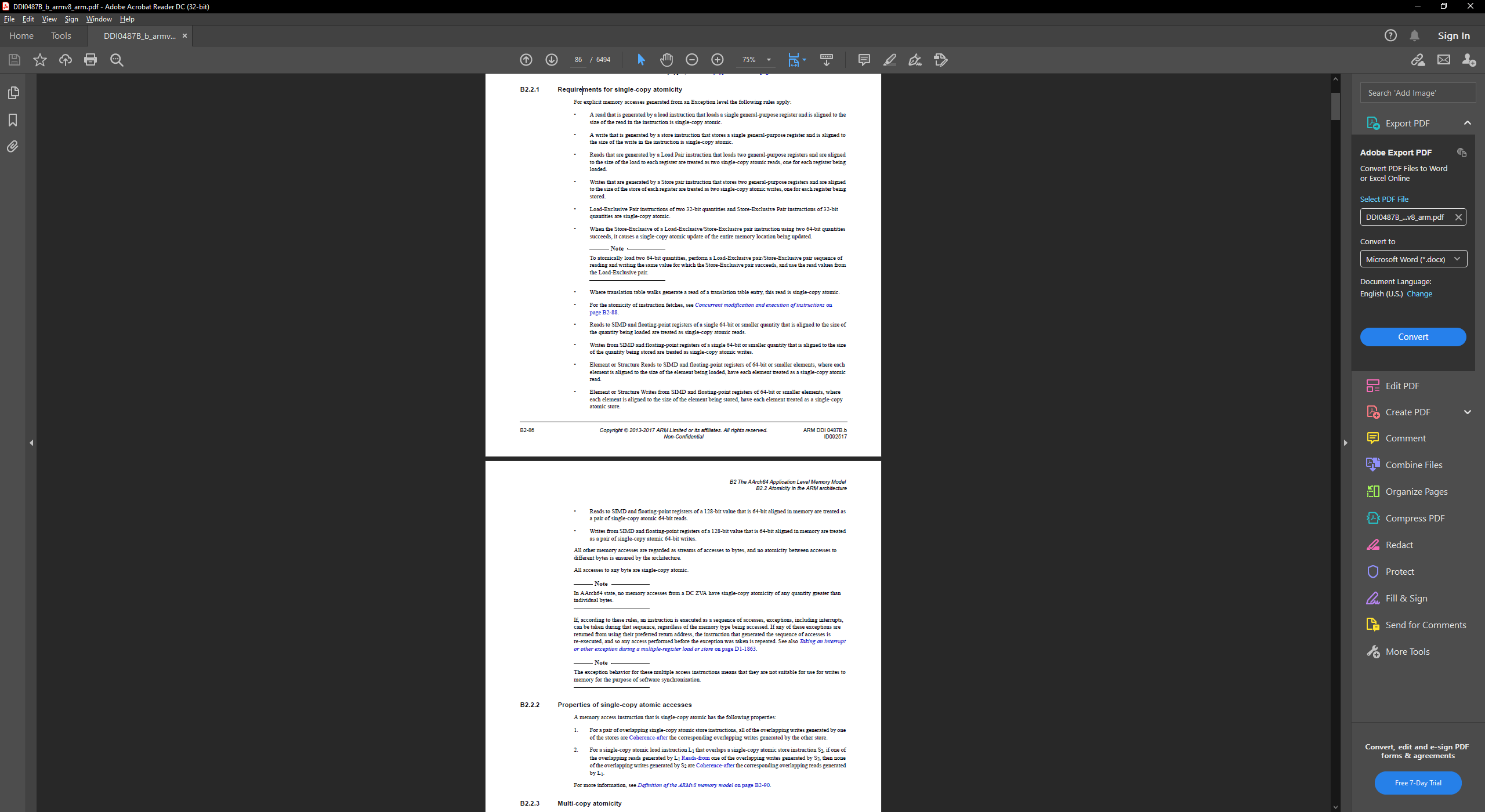
I'm not 100% on how it handles ARM32 given that would be 4x 32-bit reads/writes. Probably need to dig further into the spec and the ARM32 specific sections.
There was a problem hiding this comment.
In particular:
- Reads to SIMD and floating-point registers of a 128-bit value that is 64-bit aligned in memory are treated as a pair of single-copy atomic 64-bit reads.
- Writes from SIMD and floating-point registers of a 128-bit value that is 64-bit aligned in memory are treated as a pair of single-copy atomic 64-bit writes.
There was a problem hiding this comment.
Also noting, I don't think this guarantees that something like LLVM won't rewrite the copy loop to be "more efficient". I'd imagine Mono is explicitly marking certain loops to prevent LLVM from doing such optimizations.
There was a problem hiding this comment.
What if we scrapped the Vector.IsHardwareAccelerated check and dropped down to raw SSE2 / ARM64 intrinsics instead? Presumably that wouldn't provide the opportunity for anybody to rewrite these methods in a non-compliant manner? Though I wonder if that would hurt perf since it'd require pinning (and the associated stack spill) to use the intrinsics.
Could also use Jan's suggestion of wrapping the vectorized code in #if CORECLR, bypassing the whole issue.
There was a problem hiding this comment.
I imagine that depends on which instructions are being used and what optimizations LLVM is doing. It is conceivably "correct" in C/C++ code for it to recognize __mm_load_si128 and __mm_store_si128 as a "trivial copy loop" and to replace it with ERMSB.
(and https://godbolt.org/z/hsfE4nKnr shows that it does recognize and replace with memcpy
|
@SamMonoRT @imhameed Can you comment on the discussion going on above? A brief summary: The original code, when calling The new code, given this same scenario, tries to perform vectorized writes if possible. If vectorization is not hardware accelerated, it falls back to a In all cases, the The new code does not rely on vector writes being atomic. However, it does rely on that if a vector is written to a natural word-aligned address, each individual natural word-sized write will be atomic, even if the operation as a whole is not atomic. In other words, if Thread A is writing a vector to a natural-word aligned address, then some other Thread B which is reading natural word-sized values from natural word-aligned addresses will never observe that any individual natural word-sized value is itself torn. Is this assumption valid given the way that Mono and LLVM operate? Is there ever a scenario where, given the example above, Thread B might read a "torn" natural word-sized value from a natural word-aligned address? Furthermore, is there potentially a problem with the way the code was originally written? Is it possible for the compiler to say "oh, you're just doing a bunch of writes to a |
|
mono only supports Vector on platforms where there is hw support for it, so I believe Vector code is going to be compiled to hw SIMD instructions, there is no emulation on our side, llvm might do some emulation but only if the optimization/arch flags we pass to it are messed up, so that would be a bug. |
The non-LLVM Mono lane is also failing. Right now, Mono's non-LLVM code generator emits unrolled bytewise stores for unaligned stores: The Mono LLVM IR generator just emits We could also use volatile LLVM loads/stores unconditionally for The Intel SDM doesn't guarantee that larger-than-64-bit stores that are simd-width-aligned or natural-word-aligned are atomic or are decomposed into individual atomic natural-word-sized stores, although I'd be surprised if any relevant hardware does something weird here.
Yes, I think that is possible. (An old, related issue: mono/mono#16716) I think for now I'd suggest making this new code CoreCLR-only, so that Mono-specific issues can be figured out later. |
|
Some quick experimentation shows that the C++ compiler does recognize a difference when optimizing looped writes to #include <stdint.h>
#include <cstddef>
#include <atomic>
void WriteLongs(uint64_t* a, size_t len)
{
// compiler replaces this loop with a call to memset
for (size_t i = 0; i < len; i++)
{
a[i] = 0;
}
}
void WriteAtomicLongs(std::atomic_uint64_t* a, size_t len)
{
// compiler unrolls loop as a series of QWORD writes
for (size_t i = 0; i < len; i++)
{
a[i].store(0, std::memory_order_relaxed);
}
} |
| if ((pointerSizeLength & 1) != 0) | ||
| { | ||
| Unsafe.Add(ref ip, (nint)i) = default; | ||
| } |
There was a problem hiding this comment.
| if ((pointerSizeLength & 1) != 0) | |
| { | |
| Unsafe.Add(ref ip, (nint)i) = default; | |
| } | |
| Unsafe.Add(ref ip, (nint)(pointerSizeLength - 1) = default; |
Can be written at the end directly. Same as #51365 (comment) applies here.
-test dl,1
-je short M01_L04
-mov [rcx+rax],0x0
+mov [rcx+rdx+0FFFF],0x0Unfortunately in the other PR I forgot to look at the scalar path 😢
runtime/src/libraries/System.Private.CoreLib/src/System/SpanHelpers.T.cs
Lines 182 to 185 in ccc25a9
Can you please update this? (I don't want to submit a PR for this mini change when you're on it.)
|
Here's another interesting discovery: JIT will emit vectorized zeroing code when clearing multiple reference fields at once. So it looks like JIT is implicitly relying on this "the processor will never tear native words" behavior? using System;
using System.Runtime.CompilerServices;
namespace MyApp
{
class Program
{
public static void Main() { }
[SkipLocalsInit]
static void WriteRefStruct(ref MyStruct s)
{
s = default;
}
}
internal struct MyStruct
{
object o0;
object o1;
object o2;
object o3;
object o4;
object o5;
object o6;
object o7;
}
}; Method MyApp.Program:WriteRefStruct(byref)
G_M3391_IG01:
vzeroupper
;; bbWeight=1 PerfScore 1.00
G_M3391_IG02:
vxorps xmm0, xmm0
vmovdqu xmmword ptr [rcx], xmm0
vmovdqu xmmword ptr [rcx+16], xmm0
vmovdqu xmmword ptr [rcx+32], xmm0
vmovdqu xmmword ptr [rcx+48], xmm0
;; bbWeight=1 PerfScore 4.33
G_M3391_IG03:
ret
;; bbWeight=1 PerfScore 1.00
; Total bytes of code: 27 |
| { | ||
| if (pointerSizeLength >= 8) | ||
| { | ||
| nuint stopLoopAtOffset = pointerSizeLength & ~(nuint)7; |
There was a problem hiding this comment.
Although I like this pattern I'm not sure if
nuint stopLoopAt = pointerSizeLength - 8;
do
{
// ...
} while ((i += 8) <= stopLoopAt);is a "bit better".
-mov r9,rdx
-and r9,0FFFFFFFFFFFFFFF8
+lea r9,[rdx+0FFF8]I doubt it will make a measurable difference in either side.
My thinking is:
The mov r9,rdx likely won't reach the cpu's backend, but the and needs to be executed.
For the lea this can be handled in the AGU.
And it's 3 bytes less code (hooray).
It's a bit more readable, though I assume anyone reading code like this is aware of these tricks.
Out of interest: did you have a reason to choose the bit-hack?
The same applies to other places too (for the record 😉).
There was a problem hiding this comment.
Bit twiddling hack is muscle memory, since it allows this pattern to work:
nuint i = 0;
nuint lastOffset = (whatever) & ~(nuint)7;
for (; i != lastOffset; i += 8)
{
/* do work */
}JIT will use the and from the preceding line as the input into the jcc at the start of the loop. Allows repurposing the bit-twiddling as the "are you even large enough?" comparison in the first place.
Though to your point, I agree that if we already do the comparison upfront, this twiddling isn't needed. Or we could skip the earlier comparison, eagerly perform the bit-twiddling, and use the result of the twiddling as the comparison.
|
@jkotas @tannergooding What do you make of the following pattern? if (Vector.IsHardwareAccelerated && pointerSizeLength >= 8)
{
// We have enough data for at least one bulk (vectorized) write.
nuint currentByteOffset = 0;
nuint byteOffsetWhereCanPerformFinalLoopIteration = (pointerSizeLength - 8) * (nuint)IntPtr.Size;
// Write 8 refs, which is 256 - 512 bits, which is 1 - 4 SIMD vectors.
do
{
Unsafe.AddByteOffset(ref Unsafe.As<IntPtr, EightRefs>(ref ip), currentByteOffset) = default;
} while ((currentByteOffset += (nuint)Unsafe.SizeOf<EightRefs>()) <= byteOffsetWhereCanPerformFinalLoopIteration);
// Write 4 refs, which is 128 - 256 bits, which is 1 - 2 SIMD vectors.
if ((pointerSizeLength & 4) != 0)
{
Unsafe.AddByteOffset(ref Unsafe.As<IntPtr, FourRefs>(ref ip), currentByteOffset) = default;
currentByteOffset += (nuint)Unsafe.SizeOf<FourRefs>();
}
// etc.
private readonly struct EightRefs
{
private readonly object? _data0;
private readonly object? _data1;
// snip
private readonly object? _data7;
}
private readonly struct FourRefs
{
private readonly object? _data0;
private readonly object? _data1;
private readonly object? _data2;
private readonly object? _data3;
}
// etc.One positive attribute it offloads the concern from us to the JIT. The JIT becomes wholly responsible for ensuring that writes to object fields are atomic. If it wants to continue to use the pattern identified at #51534 (comment) it's free to do so, but at that point it becomes wholly a JIT concern and this method has no say in the matter. However, I'm nervous about saying "hey, ip can be treated as an |
This method makes assumptions about how the GC and JIT work. There is no way to write it in a fully future proof way. For example, if we were to switch to a different GC contract (e.g. require write barriers for any object reference changes, not just non-null object reference changes), it may need to be rewritten. I think it is ok to have this method conditionalized or ifdefed as necessary to make it work well for different configurations we care about. |
|
I've split off the "is the current JIT behavior even legal?" question into #51638. |
|
I'm closing this PR for now because there are too many open questions with respect to what behavior is legal and what isn't. I've opened another thread so that JIT & processor experts can chime in. But TBH I suspect that investigation will be low priority. Once those questions are answered we can loop back here and see if there's anything worth salvaging. Clarification: I think this work is still worth doing if we can get consensus on what's safe vs. what's not safe. But I don't expect us to be able to make progress on this in the immediate future. Hence closing for now so it doesn't go stale. |
Followup to #51365, this time focusing on
Span<T>.Clear. The code comments explain why it's legal to use SIMD operations here and to have a mix of aligned + unaligned writes, even though we're potentially stomping on references.Also clarified a comment in
Span<T>.Fill./cc @carlossanlop @jozkee