- Low-Grade-Glioma-Segmentation
This is a capstone project on a real dataset related to segmenting low-grade glioma. This capstone project is included in the UpSchool Machine Learning & Deep Learning Program in partnership with Google Developers.
Low-grade glioma is a type of brain tumor that is classified as a grade II and III tumor on the World Health Organization (WHO) grading scale and arises from the supporting cells of the brain called glial cells. They are generally benign but can cause significant neurological symptoms as they grow and put pressure on the surrounding brain tissue. They are most common in adults, but can also occur in children. These tumors are typically treated with surgery, radiation therapy, or a combination of both. In some cases, they may also be observed with close monitoring if the patient is asymptomatic. It is important to note that low-grade gliomas can progress over time to higher-grade tumors, so patients need to undergo regular monitoring to detect any changes in the tumor.
Low-grade glioma segmentation is the process of identifying and separating the tumor tissue from the surrounding healthy tissue in magnetic resonance imaging (MRI) scans of the brain.
Deep learning has proven to be an effective tool for this task, as it allows for the accurate identification of tumor boundaries in MRI scans. Without the use of deep learning, segmentation of low-grade gliomas can be difficult, time-consuming, and subject to inter- and intra-observer variability, as it often requires manual annotation by radiologists. However, the segmentation of low-grade glioma can be challenging due to their infiltrative nature and similarity in appearance to surrounding brain tissue. Additionally, traditional methods may not be as accurate as deep learning, leading to potential misdiagnosis and improper treatment. As a result, there is a need for accurate and efficient methods for low-grade glioma segmentation to improve patient outcomes. Deep learning-based solutions can improve the efficiency and accuracy of low-grade glioma segmentation, leading to better patient outcomes and cost savings for healthcare providers.
The Brain Magnetic Resonance Imaging (MRI) segmentation dataset is obtained from The Cancer Imaging Archive (TCIA). The dataset contains Brain MRI Images together with manual fluid-attenuated inversion recovery (FLAIR) abnormality segmentation masks. They correspond to 110 patients included in The Cancer Genome Atlas (TCGA) lower-grade glioma collection with at least fluid-attenuated inversion recovery (FLAIR) sequence and genomic cluster data available.
| Low Grade Glioma Without Segmentation | Low Grade Glioma With Segmentation |
|---|---|
 This image belongs to a 24-year-old man who developed focal seizures affecting the left side of his body. |
 This image belongs to a 24-year-old man who developed focal seizures affecting the left side of his body. The red area indicates low grade glioma. |
This dataset is a table of 110 rows and 18 columns. Each row represents a patient, and the columns contain various information about the patient such as RNASeqCluster, MethylationCluster, miRNACluster, CNCluster, RPPACluster, OncosignCluster, COCCluster and histological_type, neoplasm_histologic_grade, tumor_tissue_site, laterality, tumor_location, gender, age_at_initial_pathologic, race, ethnicity, death. Each column has a specific data type: object, float64, and int64. The first column "Patient" is of object data type, 15 columns are of float64 data type and 2 columns are of int64 data type. There are missing values in some of the columns which are represented by a "non-null" count in the Data columns section.
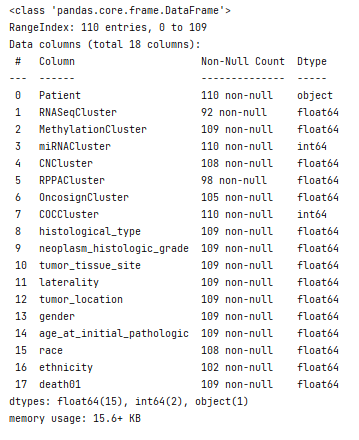
Figure 3- Information about csv dataset

Figure 4 - The head of the csv dataset

Figure 5 - The final dataframe to be used in the visualization and modeling part
The visualization part takes place in two stages. The first state involves displaying in distribution in different ways. The second stage involves the visualization of Brain MRI Images in different ways.

Figure 6 - Distribution of data grouped by diagnosis
This data shows the distribution of images grouped by diagnosis. The data is split into two groups, “positive” and “negative”. The “positive” group contains 2256 images, which represents 65.05% of the total images. The “negative” group contains 1373 images, which represents 34.95% of the total images. In total, there are 3929 images in the dataset.
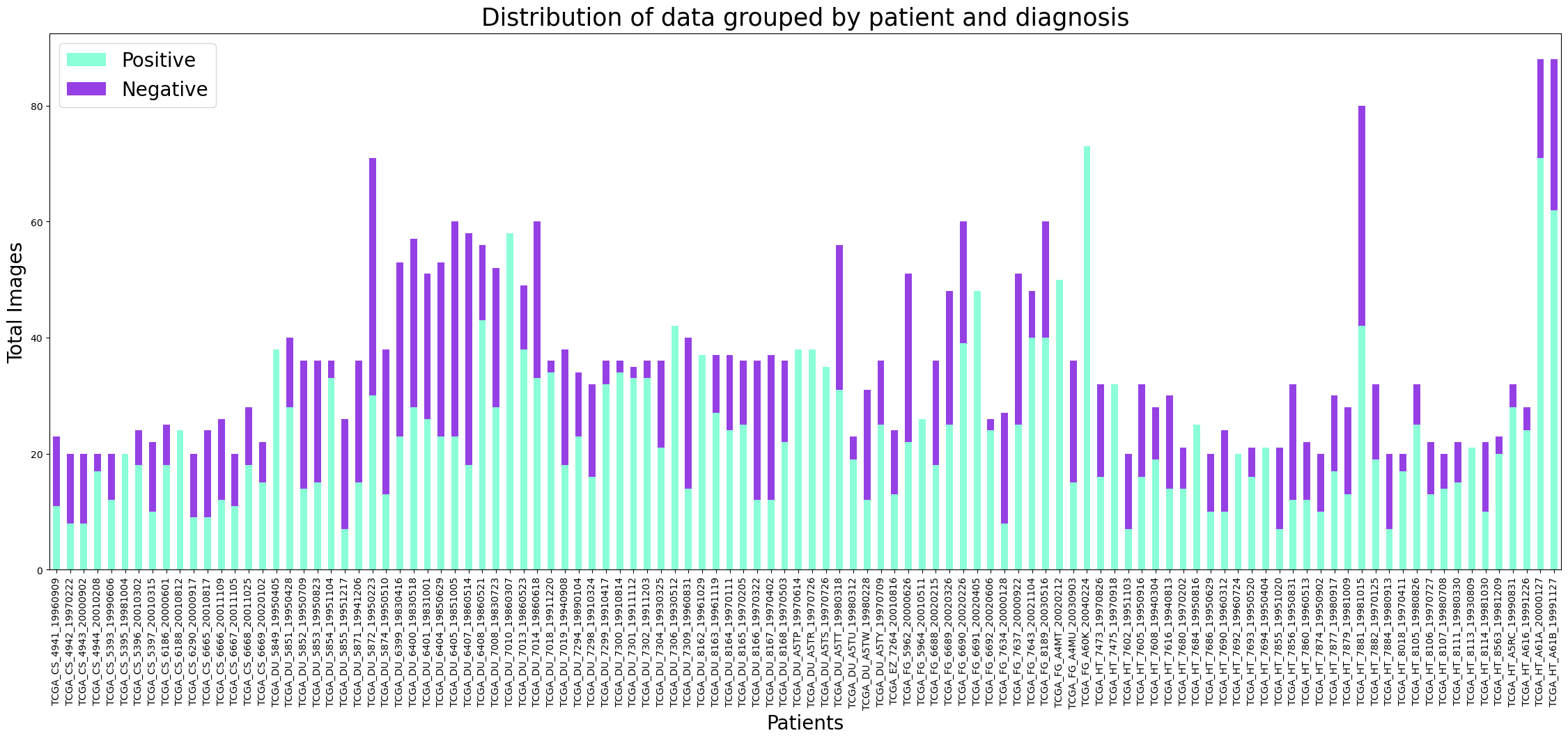
Figure 7 - Distribution of data grouped by patient and diagnosis
Both distributions indicate that there are more positive images than negative images, which could have implications for the performance of any deep learning models trained on this data. For example, if the majority of the data is positive, the model may be more likely to predict a positive diagnosis even when the image is actually negative. Therefore, data augmentation does with these distributions when analyzing or interpreting the results of any deep learning models trained on this data.
Original color and the hot color map used in the visualization of brain MRI images. The main reason why this colormap is important is that it can effectively highlight different tissue types in the brain based on their MRI intensities. The hot color maps low-intensity values to dark colors (black) and high-intensity values to bright colors (red, yellow, and white). This helps to distinguish different structures in the brain such as grey matter, white matter, and cerebrospinal fluid.
Additionally, the hot colormap is also useful in differentiating between healthy and abnormal tissue, such as tumors. Tumors often have different intensity values compared to the surrounding healthy tissue and using a colormap like hot can help to highlight these differences and make them more visible. This can be helpful for radiologists and physicians when analyzing the images and can be useful in determining the diagnosis and treatment of the patient.
It is important to note that the choice of colormap is not only important for visualizing the data but also for the analysis of the data, for example in brain tumor segmentation tasks, the choice of colormap will be important to define the threshold values for the segmentation algorithm.

Figure 8 - Low Grade Glioma Detection on Brain MRI Images wit original color and hot colormap
This diagram shows the representation of different images, positive and negative, under two different color scales. (Original color and hot colormap) Positive images using a hot colormap show where the tumor is more black or more white.

Figure 9 - Tumor location as segmented on a Brain MRI image
In the data augmentation part, the Albumentations library will be used because of its wide range of image segmentation techniques that can be applied to medical images. The library provides specialized augmentations for medical images such as elastic deformation, brightness, contrast changes, and random rotation, scaling, and flipping which are important to simulate the variability that can occur in medical images. This can help to improve the robustness and generalization of the model by providing more diverse training data.
Additionally, Albumentations allows for the easy composition of multiple augmentations together to create complex data augmentation pipelines, which can be useful for medical image segmentation tasks where multiple augmentations may be needed to account for variations in images.
In more detail, apart from normal augmentation techniques, one of the 3 different augmentation techniques are applied. These are elastic deformation, grid distortion, and optical distortion.
Elastic Deformation is a technique that used a random displacement field to deform the images. This can make the model robust to small variations in the input data.
Grid Distortion is a technique that wraps the image by applying a random grid of points. This can make the model more robust to small variations in the input data.
Optical Distortion is a technique that simulates the effects of a camera lens by applying random distortions to the image. This can make the model more robust to small variations in the input data, particularly for image classification tasks.

Figure 10 - Augmented Brain MRI Images

Figure 11 - Augmented Mask Images
Several neural network models can be used for the segmentation of low-grade glioma, each with their strengths and weakness. Some popular models that have been used for this task include:
- U-Net: It is a specific type of FCN that is designed for biomedical image segmentation. It is composed of an encoder and a decoder, which are trained to learn features from the input image and then use these features to predict a segmentation mask. It has been widely used in brain tumor segmentation tasks. The encoder is composed of a series of convolutional layers that extract features from the input image, and the decoder is composed of a series of up sampling layers that increase the spatial resolution of the features.
- Feature Pyramid Network:It is a type of deep neural network architecture that is designed for object detection and semantic segmentation tasks. FPNs are built on top of a CNN, and they are used to extract features at multiple scales. They work by creating a pyramid of feature maps, where each level of the pyramid corresponds to a different scale.
- ResUNet:ResNet is a type of CNN that uses residual connections between layers to allow the network to learn deeper and more complex representations of the input data. U-Net is a type of CNN that is designed for biomedical image segmentation. It is composed of an encoder and a decoder, which are trained to learn features from the input image and then use these features to predict a segmentation mask. ResUNet combines the encoder-decoder architecture of U-Net with the residual connections of ResNet, this allows the network to learn more robust features from the input images and improve the performance of the segmentation task.
PyTorch is used for this project instead of Keras, and TensorFlow. There are several reasons for using PyTorch:
- PyTorch has a more intuitive and flexible API, which makes it easier to work with for complex tasks such as segmentation and Albumentations library. This allows for more experimentation and iteration in the development process.
- PyTorch has built-in support for dynamic computational graphs, which can be useful for tasks such as segmentation where the model needs to adapt to different input shapes and sizes.
- PyTorch allows for easy debugging, since the forward pass is defined by a single function, and the backward pass is defined by the auto grad system.
The U-Net architecture is composed of an encoder network and a decoder network, which are connected by a set of "skip connections."
The encoder network is made up of a series of convolutional and max pooling layers that progressively reduce the spatial resolution of the input image while increasing the number of feature maps. This allows the network to extract increasingly complex and abstract features from the image.
The decoder network is made up of a series of up sampling layers and convolutional layers that restore the spatial resolution of the feature maps while decreasing the number of feature maps. The output of the decoder network is a segmentation mask that corresponds to the input image.
The "skip connections" concatenate feature maps from corresponding layers in the encoder and decoder networks, allowing the network to make use of both high- and low-level information from the input image.
The diagram of U-Net architecture would typically show the input image at the top, and the output segmentation mask at the bottom. The encoder network would be shown on the left side of the diagram, with the layers arranged vertically and labeled with the number of feature maps and the size of the kernel for the convolutional layers. The decoder network would be shown on the right side of the diagram, with the layers arranged vertically and labeled with the number of feature maps and the size of the kernel for the convolutional layers. The "skip connections" would be shown as arrows connecting corresponding layers in the encoder and decoder networks.
In this study, U-Net-35 is used, consisting of 15 convolutional, 14 rectified linear units (ReLU), three max-pooling, and three up sampling layers.

Figure 12 - U-Net Architecture from U-Net: Convolutional Networks for Biomedical Image Segmentation Article
FPN, or Feature Pyramid Network, is a type of neural network architecture for object detection in computer vision. It is built on top of a backbone CNN, such as ResNet or ResNeXt, and consists of several layers:
- The bottom-up pathway starts with the output feature maps of the last convolutional layer of the backbone CNN. These feature maps are then passed through a series of convolutional layers, known as the "lateral layers," that reduce the spatial resolution but increase the number of feature maps.
- The top-down pathway starts with the output of the lateral layers and uses a series of transposed convolutional layers, known as the "up sampling layers," to increase the spatial resolution of the feature maps.
- The final layers of the FPN combine the feature maps from the bottom-up pathway and the top-down pathway to form the final feature pyramid.
- Finally, The final feature pyramid is then passed to a head layer for classification and bounding box regression task.
The FPN architecture aims to combine the advantages of both high-level semantic information and low-level spatial information to improve object detection performance.

Figure 13 - Feature Pyramid Network Architecture

Figure 14 - Explanation of Bottom-Up- Top Down and Lateral Layers

Figure 15 - Merging the FPN last layers with UNet architecture
The architecture of the Feature Pyramid Network (FPN) architecture using the PyTorch library is divided into several parts. It takes an input image and applies the bottom-up layers to create a pyramid of feature maps with decreasing spatial resolutions. The top-down layer is then applied to the highest-resolution feature map, and the feature maps from the bottom-up layers are combined with the feature maps from the top-down layer using the lateral layers. The smooth layers are then applied to further refine the feature maps, and the segmentation block layers are applied to generate the final segmentation maps. The last layer is used to generate final predictions by converting the feature maps from the segmentation block into a single output map.
In this study FPN is used, consisting of 18 convolutional, 10 rectified linear units (ReLU), five max-pooling, five bottom-up layers, one top-down layer, three up sampling addition layers, three smooth layers, and one up sampling layer.
Özellik Piramit Ağları - Türkçe Açıklama
A U-Net with a ResNeXt50 backbone is an implementation of the U-Net architecture, where the encoder part of the network is a ResNeXt50 model. ResNeXt50 is a deep CNN architecture that was introduced in 2016 and has been shown to achieve state-of-the-art performance on various computer vision tasks, such as object detection and image classification. By using a pre-trained ResNeXt50 model as the encoder, the U-Net model can leverage the rich feature representations learned by the ResNeXt50 model, which allows it to better segment objects in the input image.
In this study, the ResNext50-32x4d model is used for the pre-trained model, and five down-sampling layers, four up-sampling layers, two convolutional layers, and one rectified linear unit (ReLU) are added to this model.
ResNeXt-50 Backbone Türkçe Açıklama
Dice Coefficient Metric is used as the segmentation quality metric. This metric measures the similarity between the predicted segmentation and the ground truth segmentation. It ranges from 0 (no overlap) to 1 (perfect overlap).
Dice Coefficient Loss is used as the segmentation loss. This is a measure of how well the output of a segmentation model matches the ground truth. The BCE (binary cross-entropy) loss function from PyTorch’ s nn module is used to calculate the binary cross-entropy loss between the input and target tensors. This loss is calculated as:
It is concluded that the mean DICE values on the validation data of both U-Net and FPN model architectures exceeded 80%. It is concluded that the architecture of the ResNext-50 model exceeded 90%.

Figure 16 - Epoch vs. DICE with U-Net Architecture

Figure 17 - Epoch vs. DICE with FPN Architecture

Figure 18 - Epoch vs. DICE with U-Net- ResNeXt50 Architecture
It was concluded that the mean DICE value of the U-Net model architecture on the test data was 83%, the mean DICE value of the FPN model architecture on the test data was 78%, and the mean DICE value of the U-Net with ResNeXt50 Backbone model architecture on the test data was 89%.
In the data augmentation part, it is mentioned that different threshold values play an important role in segmenting the tumor. Models built on this are tried to predict the segmentation of the tumor on a random test sample, both without applying a threshold and within a threshold range. As a result, the same results are obtained in both.

Figure 19 - Prediction Mask Image without Threshold and with Threshold
The results of Prediction and Ground Truth Masks on Brain MR Images are shown on different models. As can be seen from the pictures, the ResNeXt-50 model has been more successful.

Figure 20 - Prediction and Ground Truth Masks on the Brain MR Images with ResNeXt50 Backbone
- LGG-1p19qDeletion - The Cancer Imaging Archive (TCIA) Public Access - Cancer Imaging Archive Wiki. (n.d.). https://wiki.cancerimagingarchive.net/display/Public/LGG-1p19qDeletion
- Mazurowski, M. (n.d.). Deep learning based skull stripping and FLAIR abnormality segmentation in brain MRI using U-Net. GitHub. https://github.com/MaciejMazurowski/brain-segmentation
- How to change the colour of an image using a mask? (2020, July 14). Stack Overflow. https://stackoverflow.com/questions/62891917/how-to-change-the-colour-of-an-image-using-a-mask
- Bonhart. (2020, May 2). Brain MRI | Data Visualization | UNet | FPN. Kaggle. https://www.kaggle.com/code/bonhart/brain-mri-data-visualization-unet-fpn
- Ranjan, R. (2021, February 22). BrainMRI|UNet|FPN|ResNeXt50. Kaggle. https://www.kaggle.com/code/raviyadav2398/brainmri-unet-fpn-resnext50
- Gupta, A. (2021, February 6). Brain MRI Detection | Segmentation | ResUNet. Kaggle. https://www.kaggle.com/code/anantgupt/brain-mri-detection-segmentation-resunet
- Limam, M. (2021, October 18). Brain MRI Segmentation. Kaggle. https://www.kaggle.com/code/mahmoudlimam/brain-mri-segmentation
- Albumentations Documentation. (n.d.). https://albumentations.ai/docs/
- Papers with Code - U-Net Explained. (n.d.). https://paperswithcode.com/method/u-net
- Papers with Code - Brain Tumor Segmentation. (n.d.). https://paperswithcode.com/task/brain-tumor-segmentation
- Tsang, S. (2021, December 7). Review: FPN — Feature Pyramid Network (Object Detection). Medium. https://towardsdatascience.com/review-fpn-feature-pyramid-network-object-detection-262fc7482610
- A Unified Architecture for Instance and Semantic Segmentation. (n.d.). http://presentations.cocodataset.org/COCO17-Stuff-FAIR.pdf
- Hui, J. (2020, April 30). Understanding Feature Pyramid Networks for object detection (FPN). Medium. https://jonathan-hui.medium.com/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
- Team, K. (2021, December 12). Carvana Image Masking Challenge–1st Place Winner’s Interview. Medium. https://medium.com/kaggle-blog/carvana-image-masking-challenge-1st-place-winners-interview-78fcc5c887a8
- M. B. Khan, P. S. Saha and A. D. Roy, "Automatic Segmentation and Shape, Texture-based Analysis of Glioma Using Fully Convolutional Network," 2021 International Conference on Automation, Control and Mechatronics for Industry 4.0 (ACMI), Rajshahi, Bangladesh, 2021, pp. 1-6, doi: 10.1109/ACMI53878.2021.9528282.
- Forst, D. A., Nahed, B. V., Loeffler, J. S., & Batchelor, T. T. (2014). Low-grade gliomas. The oncologist, 19(4), 403–413. https://doi.org/10.1634/theoncologist.2013-03450.
- Bakshi R, Ariyaratana S, Benedict RHB, Jacobs L. Fluid-Attenuated Inversion Recovery Magnetic Resonance Imaging Detects Cortical and Juxtacortical Multiple Sclerosis Lesions. Arch Neurol. 2001;58(5):742–748. doi:10.1001/archneur.58.5.742
- Buda, M., Saha, A., & Mazurowski, M. A. (2019). Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm. Computers in Biology and Medicine, 109, 218–225. https://doi.org/10.1016/j.compbiomed.2019.05.002
- Nalepa, J., Marcinkiewicz, M., & Kawulok, M. (2019). Data Augmentation for Brain-Tumor Segmentation: A Review. Frontiers in Computational Neuroscience, 13. https://doi.org/10.3389/fncom.2019.00083
- T. R. E. Armstrong, P. Manimegalai, A. Abinath and D. Pamela, "Brain tumor image segmentation using Deep learning," 2022 6th International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 2022, pp. 48-52, doi: 10.1109/ICDCS54290.2022.9780707.
- Thada, V., & Jaglan, V. (2013). Comparison of Jaccard, Dice, Cosine Similarity Coefficient To Find Best Fitness Value for Web Retrieved Documents Using Genetic Algorithm.
- Buslaev, A., Iglovikov, V. I., Khvedchenya, E., Parinov, A., Druzhinin, M., & Kalinin, A. A. (2020). Albumentations: Fast and Flexible Image Augmentations. Information, 11(2), 125. https://doi.org/10.3390/info11020125