![]()













This repo contains PyTorch model definitions, pre-trained weights and inference/sampling code for our paper exploring Fast training diffusion models with transformers. You can find more visualizations on our project page.
![]() PixArt-α Community: Join our PixArt-α discord channels
PixArt-α Community: Join our PixArt-α discord channels
 for discussions. Coders are welcome to contribute.
for discussions. Coders are welcome to contribute.
PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen*, Jincheng Yu*, Chongjian Ge*, Lewei Yao*, Enze Xie†, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, Zhenguo Li
Huawei Noah’s Ark Lab, Dalian University of Technology, HKU, HKUST
PIXART-δ: Fast and Controllable Image Generation with Latent Consistency Models
Junsong Chen, Yue Wu, Simian Luo, Enze Xie†, Sayak Paul, Ping Luo, Hang Zhao, Zhenguo Li
Huawei Noah’s Ark Lab, DLUT, Tsinghua University, HKU, Hugging Face
-
(🔥 New) Apr. 12, 2024. 💥 A better version of PixArt-Σ training & inference code, checkpoints are all released!!! Welcome to collaborate and contribute. Star 🌟us if you think it is helpful!!
-
(🔥 New) Jan. 19, 2024. 💥 PixArt-δ ControlNet app_controlnet.py and Checkpoint are released!!!
-
(🔥 New) Jan. 16, 2024. 💥 Glad to announce that PixArt-α is accepted by ICLR 2024 (Spotlight).
-
(🔥 New) Dec. 17, 2023. 💥 PixArt supports ComfyUI. Thanks to @city96 with his great work.
-
(🔥 New) Nov. 30, 2023. 💥 PixArt collaborates with LCMs team to make the fastest Training & Inference Text-to-Image Generation System. Here, Training code & Inference code & Weights & HF Demo OpenXLab Demo are all released, we hope users will enjoy them. Detailed inference speed and code guidance can be found in docs. At the same time, we update the codebase for better user experience and fix some bugs in the newest version.
- ✅ Jan. 11, 2024. 💥 PixArt-δ: We are excited to announce the release of the PixArt-δ technical report!!! This report offers valuable insights into the training of LCM and ControlNet-like modules in Transformer Models. Along with the report, we have also released all the training and inference code for LCM & ControlNet in this repository. We encourage you to try them out and warmly welcome any Pull Requests from our users. Your contributions and feedback are highly appreciated!
- ✅ Feb. 07, 2024. train_diffusers.py can directly train with diffusers model and visualize during training.
- ✅ Jan. 26, 2024. 💥 All checkpoints of PixArt-α, including 256px checkpoints are all available here Download Models.
- ✅ Jan. 19, 2024. 💥 PixArt-δ ControlNet app_controlnet.py and Checkpoint is released!!!
- ✅ Jan. 12, 2024. 💥 We release the SAM-LLaVA-Captions used in PixArt-α training.
- ✅ Dec. 27, 2023. PixArt-α incorporates into ControlLLM!
- ✅ Dec. 17, 2023. PixArt-LCM-Lora & PixArt-Lora training scripts in Hugging Face style is released.
- ✅ Dec. 13, 2023. Add multi-scale vae feature extraction in tools/extract_features.py.
- ✅ Dec. 01, 2023. Add a Notebook folder to help users get started with PixArt quickly! Thanks to @kopyl for his contribution!
- ✅ Nov. 27, 2023. 💥 PixArt-α Community: Join our PixArt-α discord channels
for discussions. Coders are welcome to contribute.
- ✅ Nov. 21, 2023. 💥 SA-Sovler official code first release here.
- ✅ Nov. 19, 2023. Release
PixArt + Dreamboothtraining scripts. - ✅ Nov. 16, 2023. Diffusers support
random resolutionandbatch imagesgeneration now. Besides, runningPixartin under 8GB GPU VRAM is available in 🧨 diffusers. - ✅ Nov. 10, 2023. Support DALL-E 3 Consistency Decoder in 🧨 diffusers.
- ✅ Nov. 06, 2023. Release pretrained weights with 🧨 diffusers integration, Hugging Face demo, and Google Colab example.
- ✅ Nov. 03, 2023. Release the LLaVA-captioning inference code.
- ✅ Oct. 27, 2023. Release the training & feature extraction code.
- ✅ Oct. 20, 2023. Collaborate with Hugging Face & Diffusers team to co-release the code and weights. (plz stay tuned.)
- ✅ Oct. 15, 2023. Release the inference code.
TL; DR: PixArt-α is a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), and the training speed markedly surpasses existing large-scale T2I models, e.g., PixArt-α only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days).
CLICK for the full abstract
The most advanced text-to-image (T2I) models require significant training costs (e.g., millions of GPU hours), seriously hindering the fundamental innovation for the AIGC community while increasing CO2 emissions. This paper introduces PixArt-α, a Transformer-based T2I diffusion model whose image generation quality is competitive with state-of-the-art image generators (e.g., Imagen, SDXL, and even Midjourney), reaching near-commercial application standards. Additionally, it supports high-resolution image synthesis up to 1024px resolution with low training cost. To achieve this goal, three core designs are proposed: (1) Training strategy decomposition: We devise three distinct training steps that separately optimize pixel dependency, text-image alignment, and image aesthetic quality; (2) Efficient T2I Transformer: We incorporate cross-attention modules into Diffusion Transformer (DiT) to inject text conditions and streamline the computation-intensive class-condition branch; (3) High-informative data: We emphasize the significance of concept density in text-image pairs and leverage a large Vision-Language model to auto-label dense pseudo-captions to assist text-image alignment learning. As a result, PixArt-α's training speed markedly surpasses existing large-scale T2I models, e.g., PixArt-α only takes 10.8% of Stable Diffusion v1.5's training time (675 vs. 6,250 A100 GPU days), saving nearly $300,000 ($26,000 vs. $320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%. Extensive experiments demonstrate that PixArt-α excels in image quality, artistry, and semantic control. We hope PixArt-α will provide new insights to the AIGC community and startups to accelerate building their own high-quality yet low-cost generative models from scratch.
PixArt-α only takes 12% of Stable Diffusion v1.5's training time (753 vs. 6,250 A100 GPU days), saving nearly $300,000 ($28,000 vs. $320,000) and reducing 90% CO2 emissions. Moreover, compared with a larger SOTA model, RAPHAEL, our training cost is merely 1%.

| Method | Type | #Params | #Images | FID-30K ↓ | A100 GPU days |
|---|---|---|---|---|---|
| DALL·E | Diff | 12.0B | 250M | 27.50 | |
| GLIDE | Diff | 5.0B | 250M | 12.24 | |
| LDM | Diff | 1.4B | 400M | 12.64 | |
| DALL·E 2 | Diff | 6.5B | 650M | 10.39 | 41,66 |
| SDv1.5 | Diff | 0.9B | 2000M | 9.62 | 6,250 |
| GigaGAN | GAN | 0.9B | 2700M | 9.09 | 4,783 |
| Imagen | Diff | 3.0B | 860M | 7.27 | 7,132 |
| RAPHAEL | Diff | 3.0B | 5000M+ | 6.61 | 60,000 |
| PixArt-α | Diff | 0.6B | 25M | 7.32 (zero-shot) | 753 |
| PixArt-α | Diff | 0.6B | 25M | 5.51 (COCO FT) | 753 |
PIXART-δ successfully generates 1024x1024 high resolution images within 0.5 seconds on an A100. With the implementation of 8-bit inference technology, PIXART-δ requires less than 8GB of GPU VRAM.
Let us stress again how liberating it is to explore image generation so easily with PixArt-LCM.
| Hardware | PIXART-δ (4 steps) | SDXL LoRA LCM (4 steps) | PixArt-α (14 steps) | SDXL standard (25 steps) |
|---|---|---|---|---|
| T4 (Google Colab Free Tier) | 3.3s | 8.4s | 16.0s | 26.5s |
| V100 (32 GB) | 0.8s | 1.2s | 5.5s | 7.7s |
| A100 (80 GB) | 0.51s | 1.2s | 2.2s | 3.8s |
These tests were run with a batch size of 1 in all cases.
For cards with a lot of capacity, such as A100, performance increases significantly when generating multiple images at once, which is usually the case for production workloads.
- More samples


- PixArt + Dreambooth


- PixArt + ControlNet


- Python >= 3.9 (Recommend to use Anaconda or Miniconda)
- PyTorch >= 1.13.0+cu11.7
conda create -n pixart python=3.9
conda activate pixart
pip install torch==2.1.1 torchvision==0.16.1 torchaudio==2.1.1 --index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/PixArt-alpha/PixArt-alpha.git
cd PixArt-alpha
pip install -r requirements.txtAll models will be automatically downloaded. You can also choose to download manually from this url.
| Model | #Params | url | Download in OpenXLab |
|---|---|---|---|
| T5 | 4.3B | T5 | T5 |
| VAE | 80M | VAE | VAE |
| PixArt-α-SAM-256 | 0.6B | PixArt-XL-2-SAM-256x256.pth or diffusers version | 256-SAM |
| PixArt-α-256 | 0.6B | PixArt-XL-2-256x256.pth or diffusers version | 256 |
| PixArt-α-256-MSCOCO-FID7.32 | 0.6B | PixArt-XL-2-256x256.pth | 256 |
| PixArt-α-512 | 0.6B | PixArt-XL-2-512x512.pth or diffusers version | 512 |
| PixArt-α-1024 | 0.6B | PixArt-XL-2-1024-MS.pth or diffusers version | 1024 |
| PixArt-δ-1024-LCM | 0.6B | diffusers version | |
| ControlNet-HED-Encoder | 30M | ControlNetHED.pth | |
| PixArt-δ-512-ControlNet | 0.9B | PixArt-XL-2-512-ControlNet.pth | 512 |
| PixArt-δ-1024-ControlNet | 0.9B | PixArt-XL-2-1024-ControlNet.pth | 1024 |
ALSO find all models in OpenXLab_PixArt-alpha
First of all.
Thanks to @kopyl, you can reproduce the full fine-tune training flow on Pokemon dataset from HugginFace with notebooks:
- Train with notebooks/train.ipynb.
- Convert to Diffusers with notebooks/convert-checkpoint-to-diffusers.ipynb.
- Run the inference with converted checkpoint in step 2 with notebooks/infer.ipynb.
Then, for more details.
Here we take SAM dataset training config as an example, but of course, you can also prepare your own dataset following this method.
You ONLY need to change the config file in config and dataloader in dataset.
python -m torch.distributed.launch --nproc_per_node=2 --master_port=12345 train_scripts/train.py configs/pixart_config/PixArt_xl2_img256_SAM.py --work-dir output/train_SAM_256The directory structure for SAM dataset is:
cd ./data
SA1B
├──images/ (images are saved here)
│ ├──sa_xxxxx.jpg
│ ├──sa_xxxxx.jpg
│ ├──......
├──captions/ (corresponding captions are saved here, same name as images)
│ ├──sa_xxxxx.txt
│ ├──sa_xxxxx.txt
├──partition/ (all image names are stored txt file where each line is a image name)
│ ├──part0.txt
│ ├──part1.txt
│ ├──......
├──caption_feature_wmask/ (run tools/extract_caption_feature.py to generate caption T5 features, same name as images except .npz extension)
│ ├──sa_xxxxx.npz
│ ├──sa_xxxxx.npz
│ ├──......
├──img_vae_feature/ (run tools/extract_img_vae_feature.py to generate image VAE features, same name as images except .npy extension)
│ ├──train_vae_256/
│ │ ├──noflip/
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──sa_xxxxx.npy
│ │ │ ├──......
Here we prepare data_toy for better understanding
cd ./data
git lfs install
git clone https://huggingface.co/datasets/PixArt-alpha/data_toyThen, Here is an example of partition/part0.txt file.
Besides, for json file guided training, here is a toy json file for better understand.
Following the Pixart + DreamBooth training guidance
Following the PixArt + LCM training guidance
Following the PixArt + ControlNet training guidance
pip install peft==0.6.2
accelerate launch --num_processes=1 --main_process_port=36667 train_scripts/train_pixart_lora_hf.py --mixed_precision="fp16" \
--pretrained_model_name_or_path=PixArt-alpha/PixArt-XL-2-1024-MS \
--dataset_name=lambdalabs/pokemon-blip-captions --caption_column="text" \
--resolution=1024 --random_flip \
--train_batch_size=16 \
--num_train_epochs=200 --checkpointing_steps=100 \
--learning_rate=1e-06 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="pixart-pokemon-model" \
--validation_prompt="cute dragon creature" --report_to="tensorboard" \
--gradient_checkpointing --checkpoints_total_limit=10 --validation_epochs=5 \
--rank=16Inference requires at least 23GB of GPU memory using this repo, while 11GB and 8GB using in 🧨 diffusers.
Currently support:
1. Quick start with Gradio
To get started, first install the required dependencies. Make sure you've downloaded the models to the output/pretrained_models folder, and then run on your local machine:
DEMO_PORT=12345 python app/app.pyAs an alternative, a sample Dockerfile is provided to make a runtime container that starts the Gradio app.
docker build . -t pixart
docker run --gpus all -it -p 12345:12345 -v <path_to_huggingface_cache>:/root/.cache/huggingface pixartOr use docker-compose. Note, if you want to change context from the 1024 to 512 or LCM version of the app just change the APP_CONTEXT env variable in the docker-compose.yml file. The default is 1024
docker compose build
docker compose upLet's have a look at a simple example using the http://your-server-ip:12345.
Make sure you have the updated versions of the following libraries:
pip install -U transformers accelerate diffusers SentencePiece ftfy beautifulsoup4And then:
import torch
from diffusers import PixArtAlphaPipeline, ConsistencyDecoderVAE, AutoencoderKL
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# You can replace the checkpoint id with "PixArt-alpha/PixArt-XL-2-512x512" too.
pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-XL-2-1024-MS", torch_dtype=torch.float16, use_safetensors=True)
# If use DALL-E 3 Consistency Decoder
# pipe.vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder", torch_dtype=torch.float16)
# If use SA-Solver sampler
# from diffusion.sa_solver_diffusers import SASolverScheduler
# pipe.scheduler = SASolverScheduler.from_config(pipe.scheduler.config, algorithm_type='data_prediction')
# If loading a LoRA model
# transformer = Transformer2DModel.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", subfolder="transformer", torch_dtype=torch.float16)
# transformer = PeftModel.from_pretrained(transformer, "Your-LoRA-Model-Path")
# pipe = PixArtAlphaPipeline.from_pretrained("PixArt-alpha/PixArt-LCM-XL-2-1024-MS", transformer=transformer, torch_dtype=torch.float16, use_safetensors=True)
# del transformer
# Enable memory optimizations.
# pipe.enable_model_cpu_offload()
pipe.to(device)
prompt = "A small cactus with a happy face in the Sahara desert."
image = pipe(prompt).images[0]
image.save("./catcus.png")Check out the documentation for more information about SA-Solver Sampler.
This integration allows running the pipeline with a batch size of 4 under 11 GBs of GPU VRAM. Check out the documentation to learn more.
GPU VRAM consumption under 8 GB is supported now, please refer to documentation for more information.
To get started, first install the required dependencies, then run on your local machine:
# diffusers version
DEMO_PORT=12345 python app/app.pyLet's have a look at a simple example using the http://your-server-ip:12345.
You can also click here to have a free trial on Google Colab.
python tools/convert_pixart_alpha_to_diffusers.py --image_size your_img_size --multi_scale_train (True if you use PixArtMS else False) --orig_ckpt_path path/to/pth --dump_path path/to/diffusers --only_transformer=True

Thanks to the code base of LLaVA-Lightning-MPT, we can caption the LAION and SAM dataset with the following launching code:
python tools/VLM_caption_lightning.py --output output/dir/ --data-root data/root/path --index path/to/data.jsonWe present auto-labeling with custom prompts for LAION (left) and SAM (right). The words highlighted in green represent the original caption in LAION, while those marked in red indicate the detailed captions labeled by LLaVA.

Prepare T5 text feature and VAE image feature in advance will speed up the training process and save GPU memory.
python tools/extract_features.py --img_size=1024 \
--json_path "data/data_info.json" \
--t5_save_root "data/SA1B/caption_feature_wmask" \
--vae_save_root "data/SA1B/img_vae_features" \
--pretrained_models_dir "output/pretrained_models" \
--dataset_root "data/SA1B/Images/"- Inference code
- Training code
- T5 & VAE feature extraction code
- LLaVA captioning code
- Model zoo
- Diffusers version & Hugging Face demo
- Google Colab example
- DALLE3 VAE integration
- Inference under 8GB GPU VRAM with diffusers
- Dreambooth Training code
- SA-Solver code
- PixArt-α-LCM will release soon
- Multi-scale vae feature extraction code
- PixArt-α-LCM-LoRA scripts will release soon
- PixArt-α-LoRA training scripts will release soon
- ControlNet code will be released
- SAM-LLaVA caption dataset
- ControlNet checkpoint
- 256px pre-trained models
- PixArt-Σ: Next version model with much better ability is training!
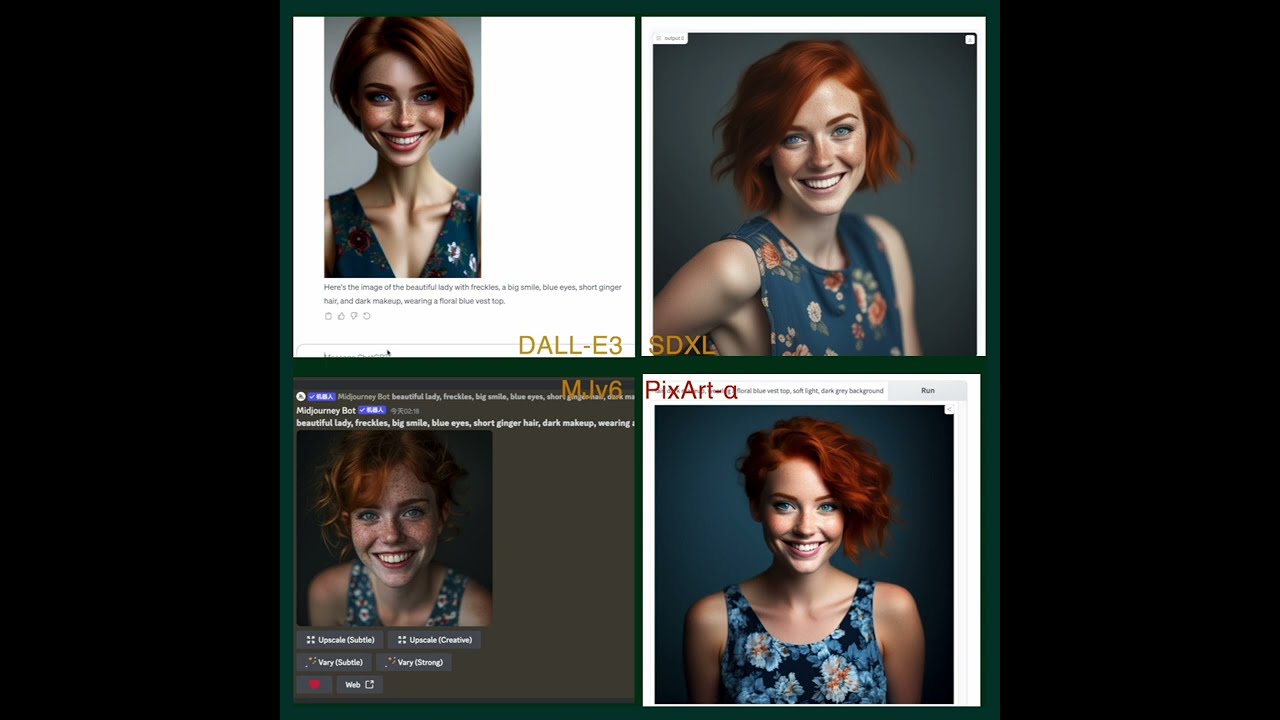
We make a video comparing PixArt with current most powerful Text-to-Image models.
@misc{chen2023pixartalpha,
title={PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis},
author={Junsong Chen and Jincheng Yu and Chongjian Ge and Lewei Yao and Enze Xie and Yue Wu and Zhongdao Wang and James Kwok and Ping Luo and Huchuan Lu and Zhenguo Li},
year={2023},
eprint={2310.00426},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{chen2024pixartdelta,
title={PIXART-{\delta}: Fast and Controllable Image Generation with Latent Consistency Models},
author={Junsong Chen and Yue Wu and Simian Luo and Enze Xie and Sayak Paul and Ping Luo and Hang Zhao and Zhenguo Li},
year={2024},
eprint={2401.05252},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
- Thanks to Diffusers for their wonderful technical support and awesome collaboration!
- Thanks to Hugging Face for sponsoring the nicely demo!
- Thanks to DiT for their wonderful work and codebase!