-
Notifications
You must be signed in to change notification settings - Fork 13.3k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Table output for segment size script (#8551)
* Table output for segment size script Also include maximum aka total for every segment key Re-format the file and clean-up the resulting data dict * revert to line output * used, percentage * unicodes * shorter desc, headers
- Loading branch information
Showing
1 changed file
with
141 additions
and
59 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
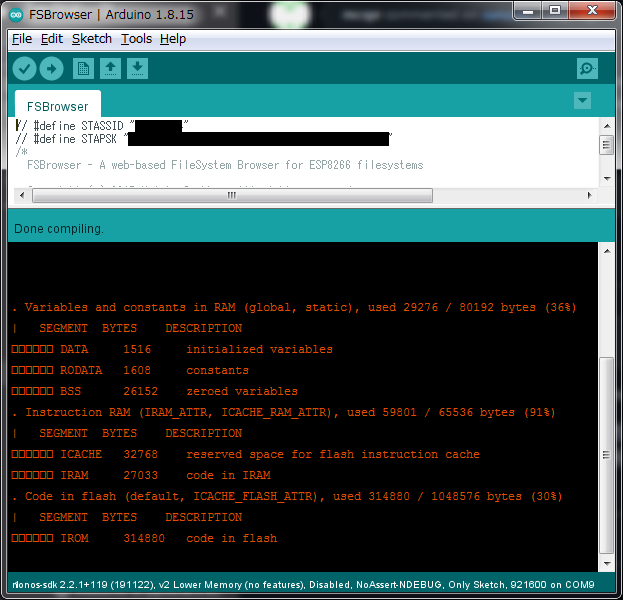
Oh, my Arduino IDE (on Win64) becomes no size output...
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
@jjsuwa-sys3175 see #8550
flash-agnostic PR erased those props, it was missed in the review since I use IDE pretty rarely.
but I do have boards.txt.py rewrite & fix, will update asap
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
ah, nvm, will check...
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Arduino IDE console log must be redirected to stderr.
print("...")->sys.stderr.write("...\n")print("...", end="")->sys.stderr.write("...")but another problem is unveil:
except UnicodeEncodeError:seem not to work as intended, because this is regarding about font system rather than text encoding i guess.(note: font for Arduino IDE editor can be configured via
preferences.txt, but console log cannot AFAIK)da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
That is weird, I wonder if there is a difference between 1.8.15 and 1.8.19?
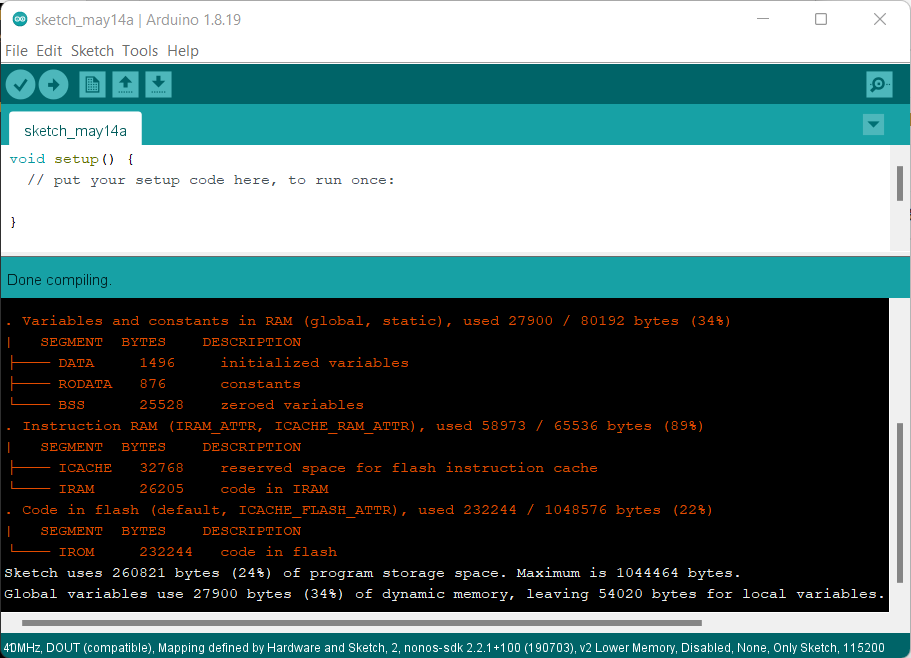
This is portable .exe running on Windows 11. Mind, there might also be differences between different Windows versions? b/c that looks like Windows 7 / 8
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
i use installer (
*.exe) version of Arduino IDE 1.8.15 or 1.8.19 on Windows7 SP1 x64 Japanase NLV.Both "English" and "System Default (Japanese)" @ prefs "Editor Language" are same result as shown above.
by the way, i don't see the last two lines, "Sketch uses N bytes..." and "Global variables use..." before i know it...(the same applies to previous ver of
sizes.py, but OK if back to 3.0.2)sorry, that's what #8550 means
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Could you check whether 2.0.0rc version display anything?
https://github.com/arduino/arduino-ide/releases
We could use dashes here, since I am not really sure how we'd check that these symbols can be rendered at all.
I have not checked anything with Win7 VM, though, and what are the rules for these box-drawing chars support (specifically
└,├, and─) and what fonts are installed(or if it is something with the Japanese language support in Windows or Java distribution of the IDE)
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
stdout (not stderr) log capture works well in 2.0.0-rc6 but box-drawing char font not.
imho it should be avoided multi-platform coding depends on the specific display font property/availability, that is ultimate act of environment-dependent behavior...
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
bummer. it is true, but also yet another reason we can't have nice things :>
at least my understanding was it is a pretty old character set, which would've been expected to be included even in Win7 time.
and the fact there's no fallback to non-unicode output? why python encoding part works at all?
Win+r,
charmap.exedoes not have box-drawing chars at all?da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
charcode encoding/decoding part and display font rendering part are independent each other.
charmap.exe, web browser (Firefox 100.1), Arduino editor pane and evennotepad.exerender such chars well... but only Arduino log output pane cannot.da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
but, that is still the point, what can we do besides not printing those characters? my expectation we would see those characters at least substituted from some font on the system
maybe we want to ask Arduino IDE guys about it, then?
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
sorry, my estimate was wrong and the true cause was found - by default, python for Windows uses ANSI code page (depends on user's locale) encoding for standard I/O via anon pipe.
fortunately, since python 3.7,
-X utf8enables UTF-8 Mode (PEP 540).let's try to modify
platform.txtline 151...bingo!
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
the remaining questions are
.windowssuffix?Sketch uses...with our output? no more red-on-black text as wellda4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Linux is OK
da4a19fThere was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Sketch uses...is by Arduino IDE's own, not ursnote:
-X utf8requires python 3.7+