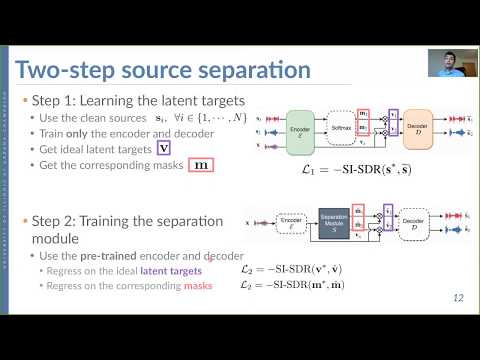
A general two-step training recipe for sound source separation. In the first step the ideal masks are learned under a front end transformation. The ideal masks or targets seve as an upper bound for source separation performance. Then we train the parameters of the separation module using SI-SDR loss on the trained latent targets. The corresponding paper has been submitted to ICASSP 2020.
University of Illinois Open Source License
Copyright © 2019, University of Illinois at Urbana Champaign. All rights reserved.
Developed by: Efthymios Tzinis 1, Shrikant Venkataramani 1, Zhepei Wang 1, Cem Subakan 2 and Paris Smaragdis 1,3
1: University of Illinois at Urbana-Champaign
2: Mila--Quebec Artificial Intelligence Institute
3: Adobe Research
This work was supported by NSF grant 1453104.
Paper link: https://arxiv.org/abs/1910.09804
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal with the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions: Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimers. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimers in the documentation and/or other materials provided with the distribution. Neither the names of Computational Audio Group, University of Illinois at Urbana-Champaign, nor the names of its contributors may be used to endorse or promote products derived from this Software without specific prior written permission. THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE CONTRIBUTORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS WITH THE SOFTWARE.