通过用户自定义词典来增强歧义纠错能力 #14
Comments
目前这个方面的确还比较弱。 通过在自定义词典里提高“江大桥”的词频可以做到,但是设置多少还没有公式,词频越高则成词概率越大,不宜过大。 我是这样设置的: ==user.dict== 江大桥 20000 ===test1.py====== #encoding=utf-8 ==结果=== |
|
请问,在提供自定义词的时候,为什么还需要指定词频?这里的词频有什么作用? |
|
@hitalex, 频率越高,成词的概率就越大。 比如"江州市长江大桥",既可以是”江州/市长/江大桥“,也可以是”江州/市/长江大桥“。 |
|
注意 自定义词典不要用Windows记事本保存,这样会加入BOM标志,导致第一行的词被误读。 |
|
通过在自定义词典里提高“江大桥”的词频可以做到,但是设置多少还没有公式,词频越高则成词概率越大,不宜过大。这里的“不宜过大”到底不宜大到什么程度,我看前面的词频也就2,3,4,怎么到“江大桥”的词频就要大到了20000??这个难道不是过大?? |
|
@macknight , 这个例子比较极端,因为”长江大桥“、”市长“这些词的频率都很高,为了纠正,才把”江大桥“的词频设置的很高。而对于一般的词典中没有的新词,大多数情况下不会处于有歧义的语境中,故词频也就2,3,4就够了。 |
|
看到词库格式是: {word:frequency},总样本字数是多少?添加新词的频率怎么设定? |
|
默认词库在这里:https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt?raw=true 总样本字数??你说的是词数吧? wc -l 就好了。 一个词的举例:“一一列举 34 i”,这个词中,freq 就是 34 嘛,i 是词性。照着加进去就好。 |
|
@while,不用设置那么高。 |
|
频率设个 4 就好了。 fxsjy comment: 2013/4/10 Sun Junyi notifications@github.com
|
|
我想有陆续添加新词功能。 看源码里把freq取了log。 所以直接用了词频。 但是以后新的文本词频怎么整合,还想不明白? |
|
我觉得你的 comment 里,标点符号用得特别传神。 在 2013年4月10日下午3:39,whille notifications@github.com写道:
|
|
@whille, 如果你添加的词语特别多的话(因为会对分母造成影响),建议直接加到dict.txt里面,否则就用jieba.load_userdict好了(这里的分母还是用的dict.txt中的总词频和,为了性能并没有重新计算一遍)。 |
|
看来dict.txt里面的词频只是为解决歧义而设置的,词典中的词频数值跟计算tf-idf时没有必然联系吧? |
|
@metalhammer666 ,没有必然联系。 |
|
在自定义词典中,明明把词性标为nr,print出来的却是x。请问怎么解决?是格式不对么? |
|
@heloowird , 按说不会啊,把你的词典发我看看? |
|
|

|
@fxsjy “在自定义词典中,明明把词性标为nr,print出来的却是x“ |


|
我发现一个问题:我已经将某个词加入用户自定义词典,且设置了很高的词频(例如,5),但是jieba在分词或POS时,还是没有将其作为一个词。 |
|
还有一个问题,在中文中含有英文,如何把一个词语分到一起来? |
|
请问自定义字典的存放路径@fxsjy |
1 similar comment
|
请问自定义字典的存放路径@fxsjy |
|
请问自定义的字典里面可以有正则表达式吗? |
|
我在添加自定义字典时,出现这个错误UnboundLocalError: local variable 'line' referenced before assignment,请问该如何解决? |
|
@fxsjy 我想问,我在使用自定义词典的时候,分词“藏宝阁太贵”,我成功把“藏宝阁”分成一起了,但是“太贵”却不能分成“太”和“贵”。 |
|
@codywsy 个人认为有两种方式:1)你可以在字典dict.txt中先找出“太贵”的词频,然后在后面加上“太” ,“贵”,但是词频要比“太贵”高; |
|
怎么结合其他输入法之类的词库?? |
|
@zxqchat 请问你搞清楚了么?我想把“二手手机” 分为“二手” 和 “手机”,自定义词典后, 我用load_userdict 没有任何作用,但是用set_dictionary 就能分开了。。。 |
|
@Azusamio 看起来确实是只能用一个词典,但是我看到文档里说:
这样来看
@fxsjy 能否解释下?谢谢啦 😄 |
|
你好, 我修改了 dict.txt 中的詞頻, 希望輸出結果為 [失|明天] 而非 [失明|天]。 詞頻修改為: 但結果還是[失明|天], 請問除了載入自定義辭典, 還可以怎麼解決這個問題呢? |
|
遇到了同樣的問題,如同 @zxqchat 和 @secsilm 所说的,set_dictionary 和 load_userdict 的區別是什麽?我使用 load_userdict 加載也是不管用,分詞的時候仍然顯示的是默認詞典。 目前的解法是直接 def handler_jieba_suggest_freq(term):
jieba.suggest_freq(term, tune=True)
# loading userdict
loading_lst = ['夏裝','原宿風','EASY SHOP','酒紅色','冷萃蘆薈'... ... ]
result = map(handler_jieba_suggest_freq,loading_lst)
for ele in result:
pass |
|
@JimCurryWang @mali-nuist 已经很久没弄了,回忆了这个问题,我记得是由于词频影响的。 |
这个可以修改jieba源码中的正则表达式即可,你可以google一下 |
|
你好, 这句话 "有时候线上线下的活动需要请客户来" |
|
@randyliu61 修改词频,它是按词频来决定切分的 |
|
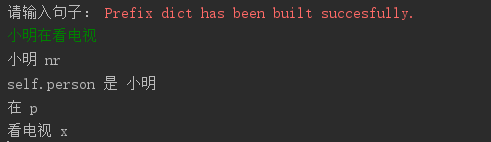
我不想用动态调整,动态调整后也不会保存下来,每次测试都要添加一个suggest_freq太可笑了,如果要调整上千个每次弄都会死人 |
|
@fxsjy 您好,我在使用您的自定义词典功能后,程序分词的速度大幅提升,但是分词的结果其实变化并不大,变化率大概在3%左右,但是程序运行时间减到了一半,您觉得这个现象出现的原因是什么呢?希望您能解答,谢谢! |
|
请问我用load_userdict加载了自定义词典后,还是吃 鸡,没有合并起来,如何处理呢 |
您好,怎么成功了? |
貌似还是不行 |
set_dictionary怎么使用啊 |
|
@stephen-song
(我也是刚学,不保证正确:) ) >>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台/中/」/正确/应该/不会/被/切开此时使用 >>> jieba.suggest_freq('台中', True)
69为了检验,使用 |
分词是以词频为中心的,不论用什么方法,最终都会归到词频。
先举个我的例子: >>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台/中/」/正确/应该/不会/被/切开但是,是不是只要'台'和'中'的词频大于'台中'就可以分出'台/中': >>> jieba.add_word('台中', 69) # 此时FREQ('台中')=69
>>> print('/'.join(jieba.cut('「台中」正确应该不会被切开')))
「/台中/」/正确/应该/不会/被/切开可见不是。这是因为刚刚说过,首先,单字词频大于双字属正常现象,故此时虽然'台'和'中'的词频大于'台中',还是可以分出‘台中’。刚才又说过,词频相对越大越能分出词,故FREQ('台中')=69可以分出词,但FREQ('台中')=3时就无法分出词。 不过,对于我们使用者来说,有一种办法可以获得正好能/不能分出词的词频界限,即suggest_freq的返回值: 现在回到你的问题,有以下办法解决:
或 或
|

不太同意您的观点,我测试了一下,只load_userdict一个含有很少词的自定义字典,同时禁用HMM,依旧可以完成文章分词。说明load_userdict是和源字典共同起作用的。 说明set_dictionary是设置唯一的字典。 在此印证和感谢PlayDeep的观点:
|

|
不知道能不能添加正则表达式作为新词呢?例如第1科室,第2科室,第x科室这些不想每一个都加入到自定义词典中。 |
|
@fxsjy 你好~我在词典里添加了自定义词,jieba.add_word("分°"),但是最后结果里面还是并没有把‘分’和‘°’判定为一个词,这个是为什么呢?是不支持符号和文字的为一个词的自定义分词嘛? |
|
@aileen0823 jieba.re_han_default = re.compile("([\u4E00-\u9FD5a-zA-Z0-9+#&\._%\-°]+)", re.U) |
|
有个小小的问题,添加词典后,并没有起作用,有小伙伴遇到这样的情况吗? |
import jieba
|
同意@LinuxerAlan 的观点,如果要使用自定义词典,为了避免麻烦,可以直接set_dictionary合适的词典以及修改其中的频数 |
@nelsonair 可以设置一下频数,如 |
|
jieba 自定义词语 不一定生效.. 最后的 招商银行 一定会被分为一个词,除非 jieba.del_word('招商银行') |
|
使用自定义词典,导入词条报错,词条是法语的。支持法语分词? |

RE:
"大连美容美发学校中君意是你值得信赖的选择" 这句话首先会按照概率连乘最大路径来切割,因为单字有一定概率,而“中君意是”这四个字中不含词典中有的词,所以会被切割成单字:
即:大连/ 美容美发/ 学校/ 中/ 君/ 意/ 是/ 你/ 值得/ 信赖/ 的/ 选择/
然后我们认为“中/ 君/ 意/ 是/ 你/ ”这几个连续的单字 中可能有词典中没有的新词,所以再用finalseg来切一遍“中君意是你 ”,finalseg是通过HMM模型来做的,简单来说就是给单字大上B,M,E,S四种标签以使得概率最大。
很遗憾,由于训练数据的问题,finalseg最终得到的标签是:
中君 意是 你
B E B E S
即认为P(B)_P(中|B)_P(E|B)_P(君|E)_P(B|E)_P(意|B)_P(E|B)_P(是|E)_P(S|E)*P(你|S) 是所有可能的标签组合中概率最大的。
B: 开头
E:结尾
M:中间
S: 独立成词的单字
解决方案是在词典中补充“君意”这个词,并给予一个词频,不用太大,比如3即可。
==user.dict===
君意 3
==test.py==
encoding=utf-8
import sys
import jieba
jieba.load_userdict("user.dict")
print ", ".join(jieba.cut("大连美容美发学校中君意是你值得信赖的选择"))
==结果===
大连, 美容美发, 学校, 中, 君意, 是, 你, 值得, 信赖, 的, 选择
The text was updated successfully, but these errors were encountered: